](https://deep-paper.org/en/paper/2403.02966/images/cover.png)
让 LLM 更诚实: 总结知识图谱如何提升问答效果
像 GPT-4 和 Llama 这样的大型语言模型 (LLM) 彻底改变了我们与信息交互的方式。它们能写诗、写代码,并回答复杂的问题。然而,它们遭受着一个众所周知的缺陷: 幻觉 (Hallucinations) 。 由于它们的知识被“冻结”在训练时的参数中,它们经常弄错事实,尤其是关于那些冷门或不断演变的信息。
为了解决这个问题,研究人员和工程师通常使用 RAG (检索增强生成) 。 其核心思想很简单: 从外部来源查找相关信息并将其提供给 LLM。而 知识图谱 (Knowledge Graph, KG) 是这类外部数据中最结构化、最可靠的来源之一。
但这也带来了一个问题。知识图谱使用的是“三元组”语言 (例如 (斯蒂芬·金, 受教育于, 缅因大学)) ,而 LLM 使用的是自然语言。弥合这一鸿沟比看起来要难得多。简单地将一堆原始事实丢给 LLM 往往会通过混淆模型或浪费宝贵的上下文窗口空间,从而适得其反。
在这篇文章中,我们将深入探讨一篇名为 “Evidence-Focused Fact Summarization for Knowledge-Augmented Zero-Shot Question Answering” (面向知识增强零样本问答的聚焦证据事实总结) 的论文。研究人员提出了 EFSUM , 这是一个新颖的框架,它不仅仅是列出事实,而是专门针对用户的提问对事实进行总结,从而确保高准确率并减少幻觉。
问题所在: 图与文本之间的鸿沟
在了解解决方案之前,我们需要理解为什么将知识图谱 (KG) 与 LLM 结合使用会很困难。
KG 由实体和关系组成。当用户提出一个问题,比如 “《宠物公墓》的作者是在哪里上的大学?” 时,检索系统会从图谱中提取相关事实。传统上,将这些信息输入 LLM 有两种方式:
- 线性化 (拼接) : 简单地将三元组列为文本字符串 (例如:
(宠物公墓, 作者, 斯蒂芬·金), (斯蒂芬·金, 受教育于, 缅因大学)) 。 - 通用语言化: 使用模型将这些三元组转换为完整的句子。
这两种方法在 密度 (Density) 和 清晰度 (Clarity) 方面都存在重大缺陷。
1. 低密度
原始三元组是重复的。如果你有 10 个关于斯蒂芬·金的事实,他的名字就会出现 10 次。这浪费了“Token” (LLM 的货币) 。如果你的上下文窗口有限,你可能会为了给冗余文本腾出空间而挤掉相关信息。
2. 低清晰度
当你从图谱中检索事实时,通常会得到“噪声”——即那些虽然真实但与具体问题无关的事实。如果你给 LLM 提供 50 个关于斯蒂芬·金的事实,但其中只有一个是关于他的大学教育的,模型可能会被干扰。
研究人员分析了现有的方法 (如 KAPING 和 KG2Text) ,发现了显著的问题。
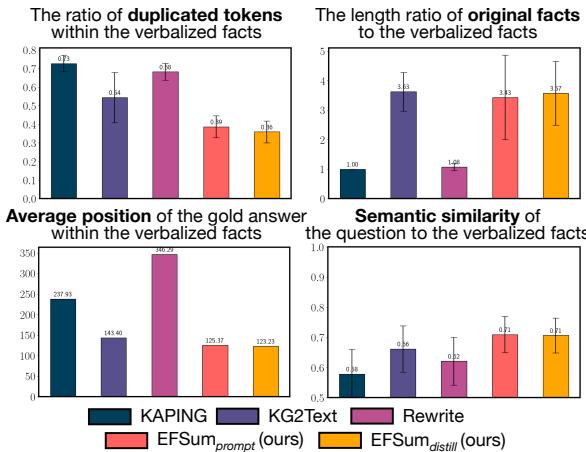
如上方的 图 2 所示:
- 左上角: 像 KAPING 和 Rewrite 这样的方法具有很高比例的重复 Token (低密度) 。
- 右下角: 生成文本与问题之间的语义相似度通常较低,这意味着上下文并没有聚焦于用户实际提出的问题。
解决方案: EFSUM
研究人员提出了 EFSUM (聚焦证据的事实总结,Evidence-focused Fact SUMmarization) 。EFSUM 不是盲目地将图数据转换为文本,而是充当一个智能中间人。它接收检索到的事实和用户的问题,然后生成一个简明、连贯的摘要,只突出回答该特定问题所需的证据。
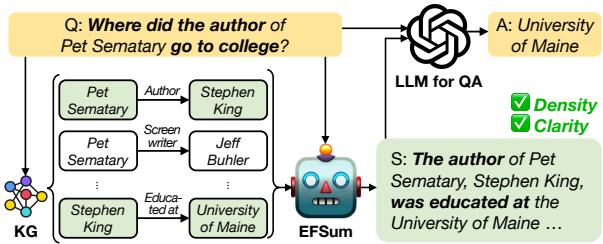
图 1 展示了这个工作流程:
- 问题: “《宠物公墓》的作者是在哪里上的大学?”
- KG 检索: 系统提取原始节点和边 (斯蒂芬·金,《宠物公墓》,缅因大学等) 。
- EFSUM: 模型基于问题处理这些事实。
- 摘要: 它输出: “《宠物公墓》的作者斯蒂芬·金受教育于缅因大学……”
- LLM: 最终的问答模型看到这个清晰的摘要,并轻松回答“缅因大学”。
核心方法: 蒸馏与对齐
你可能会想,“为什么不直接提示 GPT-4 来总结事实呢?”你可以这样做 (论文中也作为 EFSUM_prompt 进行了测试) ,但在生产流水线中依赖庞大的闭源 API 既昂贵又缓慢。
真正的创新在于 EFSUM_distill 。 作者微调了一个较小的开源模型 (Llama-2-7B) ,使其成为事实总结专家。他们通过两步过程实现了这一点: 蒸馏 (Distillation) 和 偏好对齐 (Preference Alignment) 。
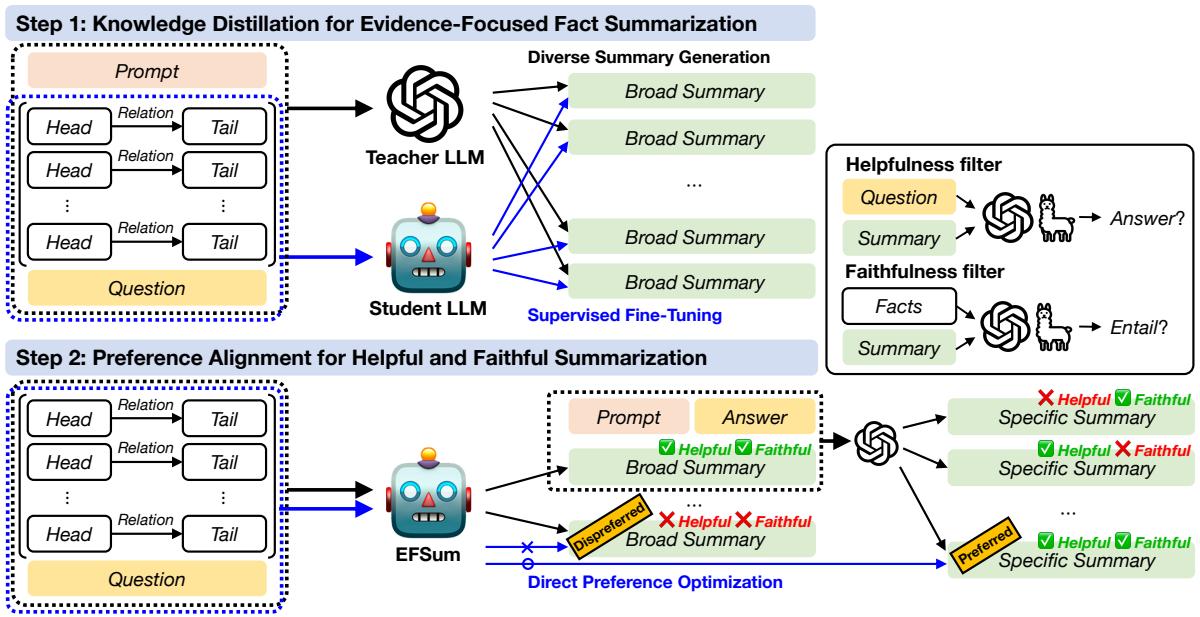
步骤 1: 蒸馏 (教导学生)
首先,研究人员需要一个训练数据集。他们使用了一个强大的“教师”模型 (GPT-3.5-turbo) ,并提供了数千对 (问题, 事实三元组),要求它生成高质量的摘要。
然后,他们使用这些生成的摘要,通过 监督微调 (SFT) 来训练他们较小的“学生”模型。目标函数是标准的因果语言建模:
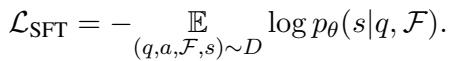
简单来说,模型 \(\theta\) 学习在给定问题 \(q\) 和事实 \(\mathcal{F}\) 的情况下,最大化生成正确摘要 \(s\) 的概率。
步骤 2: 偏好对齐 (打磨技能)
步骤 1 之后,模型可以进行总结,但并不完美。有时它会产生幻觉 (编造内容) 或写出对回答问题实际上没有帮助的摘要。
为了解决这个问题,作者使用了 直接偏好优化 (DPO) 。 这种技术使模型与特定的人类定义 (或在本例中为系统定义) 的偏好保持一致。他们为“好”的摘要建立了两个关键标准:
- 有用性 (Helpfulness) : 如果 LLM 阅读了这个摘要,它能答对问题吗?
- 忠实度 (Faithfulness) : 摘要是否严格遵循图谱中提供的事实,而不进行编造?
筛选过程
他们生成了多个摘要候选,并通过两个过滤器进行筛选:
- 有用性过滤器: 运行 QA 检查。如果摘要导致错误的答案,则将其标记为“非首选”。
- 忠实度过滤器: 使用单独的模型 (G-Eval) 检查幻觉。如果摘要包含源图谱中没有的信息,则将其标记为“非首选”。
他们还使用了一种“从宽泛到具体”的重写技术来创建“首选”示例——即那些简明扼要并准确击中所需证据的摘要。
DPO 训练
然后,模型被训练为倾向于“有用且忠实”的摘要 (\(s^+\)) ,而不是糟糕的摘要 (\(s^-\)) 。DPO 的损失函数如下所示:
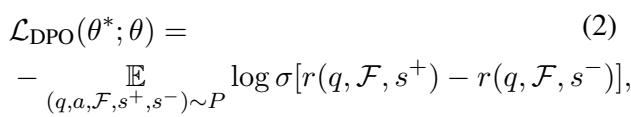
该公式推动模型的概率分布倾向于好的摘要 (\(s^+\)) ,同时惩罚坏的摘要 (\(s^-\)) ,从而有效地“引导”模型的行为,而无需复杂的强化学习设置。
实验结果
这个复杂的训练流程真的有效吗?研究人员在两个主要的知识图谱问答数据集上测试了 EFSUM: WebQSP 和 Mintaka 。
准确率提升
主要指标是准确率: 在给定上下文的情况下,LLM 是否正确回答了问题?
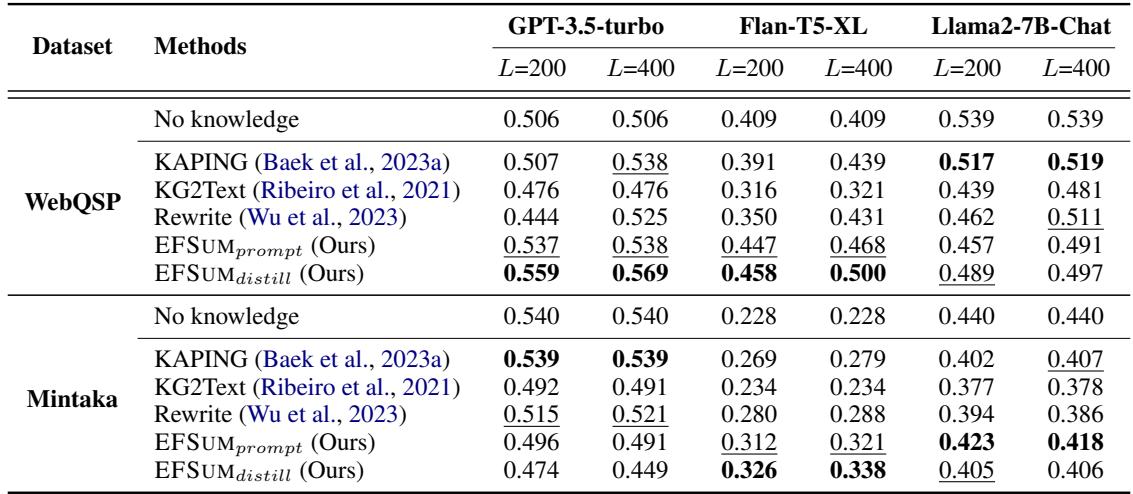
表 1 显示了三种不同 LLM (GPT-3.5、Flan-T5 和 Llama-2) 的结果。
- L=200 vs L=400: 这代表 Token 限制。请注意,当上下文窗口较紧 (\(L=200\)) 时,EFSUM (Ours) 显著优于 KAPING 和 Rewrite 等方法。
- 效率: 由于 EFSUM 密度高 (信息量大,废话少) ,它能在相同的空间内放入更多证据,从而带来更好的答案。
对噪声的鲁棒性
一个好的总结器应该能很好地处理“噪声”。如果检索系统提取了 100 个事实,但只有 2 个是相关的,总结器需要忽略其他 98 个。
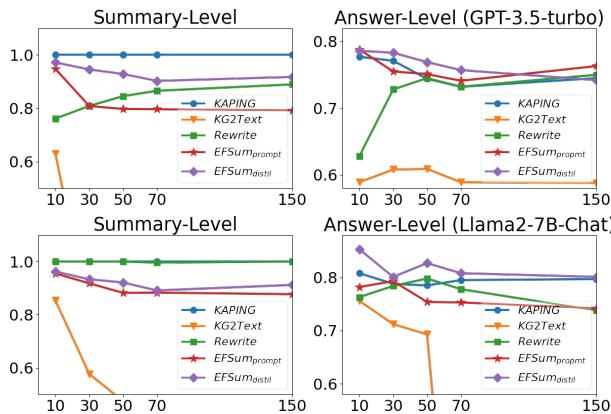
图 4 展示了这种鲁棒性。X 轴代表 \(K\) (检索到的事实数量) 。
- 看左上角图表中的 KG2Text (橙色线) 。一旦添加更多事实,其性能就会崩溃,因为它试图将所有内容语言化,从而混淆了模型。
- EFSUM (紫色线) 即使在 \(K\) 增加时也能保持高准确率。它成功过滤了噪声并保持信号清晰。
有用性 vs. 忠实度
最终目标是生成既有用 (对 QA 有帮助) 又忠实 (事实准确) 的摘要。
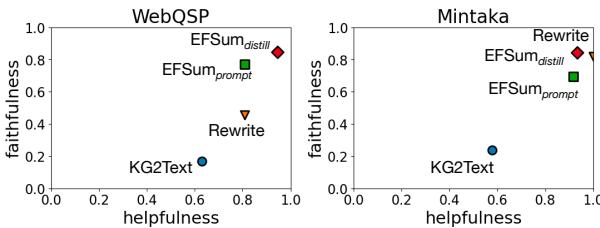
图 5 绘制了这两个指标的对比:
- 理想情况下,你希望处于右上角。
- Rewrite (绿色) : 忠实度不错,但有用性较低。
- KG2Text (蓝色) : 在两方面都很差。
- EFSUM (橙色) : 始终实现了最佳平衡,在两个数据集中都位于右上象限的最高位置。
定性比较
为了真正看到差异,让我们看看这些方法生成的实际文本。

在 表 6 中,系统试图回答: “谁是 Emilio Estevez 的父亲?”
- KAPING 创造了一面乱糟糟的文本墙:
(Emilio Estevez's, father, Martin Sheen), (Ramón Estévez, father, Martin Sheen)... - KG2Text 生成了支离破碎的句子,并且奇怪地重复“children”和“children”。
- EFSUM 生成了一个干净、可读的段落: “Emilio Estevez 的父亲是 Martin Sheen……Martin Sheen 是 Emilio Estevez 和 Ramón Estévez 的父亲。”
EFSUM 的输出读起来就像是人类专门为了帮你找到答案而写的。
结论与启示
EFSUM 框架突出了现代 AI 开发中的一个关键教训: 上下文内容的策展与模型规模同等重要。
通过简单地将检索到的知识图谱数据视为需要提炼的原材料,而不是直接倾倒进提示词中,研究人员实现了:
- 更高的准确率: 即使使用较小的开源模型也能获得更好的答案。
- 更高的效率: 摘要占用更少的 Token,节省了成本和延迟。
- 减少幻觉: 通过明确地训练忠实度,模型学会了坚持提供的事实。
对于致力于 RAG 系统的学生和工程师来说,这篇论文表明,在数据库和 LLM 之间投入一个专门的“总结器”模块是一种强大的架构模式。它允许你将结构化、杂乱的数据转换为 LLM 可以有效处理的清晰、叙述性的证据。