](https://deep-paper.org/en/paper/2403.05020/images/cover.png)
想象一个完全由 AI 智能体 (Agent) 居住的虚拟小镇。它们起床、上班、在咖啡店聊八卦、在市场上讨价还价。这听起来像科幻小说——具体来说,像是由超级计算机驱动的《西部世界》 (Westworld) 或《模拟人生》 (The Sims) ——但大型语言模型 (LLM) 的最新进展让我们离这个现实近在咫尺。
研究人员和开发人员正越来越多地使用 LLM 来模拟复杂的社交互动。这些模拟被用于从训练客服机器人到构建经济模型、测试社会科学假设的方方面面。其假设很简单: 如果一个 LLM 能够编写出两个人之间令人信服的对话,它就能模拟一个社会。
但是,一篇名为 “Is this the real life? Is this just fantasy? The Misleading Success of Simulating Social Interactions With LLMs” 的新研究论文给这种热情泼了一盆冷水。研究人员认为,我们目前模拟社会的方法存在根本缺陷。它们依赖一种“全知”视角,创造了一种社交能力的假象——当我们强迫 AI 智能体像真人一样在信息有限的情况下行动时,这种假象就会破灭。
在这篇深度文章中,我们将拆解这篇论文,了解为什么模拟社交互动比看起来更难,为什么“上帝模式”是在作弊,以及当 AI 智能体被迫应对信息不对称 (Information Asymmetry) 的混乱现实时会发生什么。
核心问题: 信息不对称
要理解论文的核心论点,我们首先需要理解一个叫做信息不对称的概念。
在现实世界中,社交互动的定义在于我们不知道什么。当你协商薪水时,你不知道老板愿意支付的绝对上限。当你第一次约会时,你不知道对方是喜欢还是讨厌《星球大战》。你有你的私密想法、目标和秘密;他们也有他们的。对话是我们为了揭示这些信息而搭建的桥梁。
这就是“非全知” (Non-Omniscient) 设定。它需要心智理论 (Theory of Mind) ——即能够将心理状态归因于他人,并理解他们的信念和知识与你自己的不同。
然而,目前大多数 LLM 模拟都在作弊。它们使用研究人员所说的 SCRIPT (剧本) 模式。在这种模式下,一个单一的、强大的 LLM 同时为对话的双方生成对话。因为一个模型控制着一切,它能瞬间知道每个人的秘密、目标和约束条件。它实际上是在扮演角色的“上帝”。
研究人员试图回答一个关键问题: 这些全知 SCRIPT 模拟的成功,是否能转化为现实的、基于智能体的互动?
框架: SCRIPT vs. AGENTS
为了测试这一点,作者基于 Sotopia (一个旨在评估社交智能的环境) 开发了一个统一的模拟框架。他们设置了三种不同的模拟模式来比较性能。
1. SCRIPT 模式 (剧本模式/幻想)
在这个设定中,一个单一的 LLM 扮演剧作家的角色。它被赋予了两个角色 (我们称之为 Sally 和 Jack) 的完整档案、目标和秘密,并被要求编写他们互动的剧本。模型是全知的;它不存在信息不对称的问题。
2. AGENTS 模式 (智能体模式/现实生活)
这是现实的设定。两个独立的 LLM 实例被实例化。
- 智能体 A 扮演 Sally。它只知道 Sally 的目标和背景。
- 智能体 B 扮演 Jack。它只知道 Jack 的目标和背景。 它们必须轮流沟通以实现各自的目标,而不知道对方在想什么。这模仿了真实的人类互动。
3. MINDREADERS 模式 (读心者模式/对照组)
这是一个混合消融研究。设置与 AGENTS 相同 (两个独立的模型) ,但研究人员人为地消除了信息不对称。他们让 Sally 的模型完全访问 Jack 的秘密和目标,反之亦然。它们是独立的智能体,但它们拥有心灵感应能力。
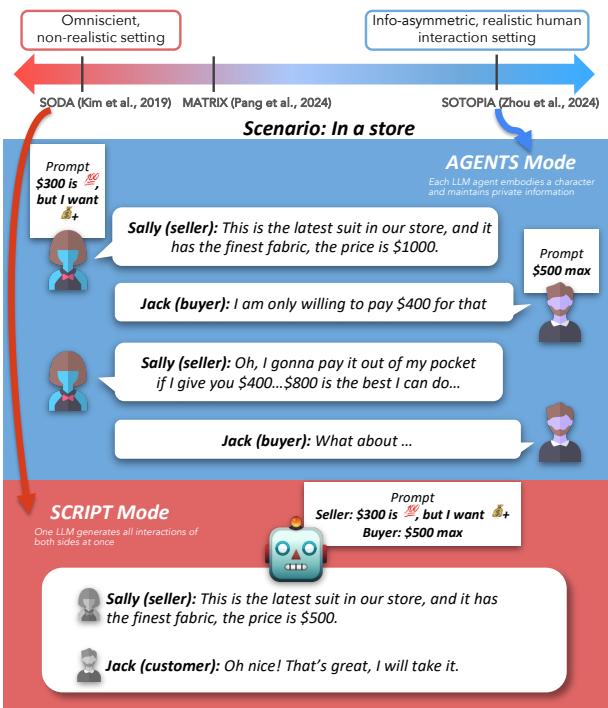
如图 1 所示,差异是巨大的。在 AGENTS 模式 (蓝色) 中,买方和卖方有私人的价格限制 (300 美元 vs 500 美元) 。他们必须讨价还价,谈判过程很混乱。在 SCRIPT 模式 (红色) 中,单一模型立即看到了两个限制,并简单地生成了一段对话,让他们在 500 美元达成一致,避开了谈判的挣扎。
实验 1: 能力差距
论文的第一个主要发现是,当 LLM 没有全知知识时,它们实现社交目标的能力会显著下降。
研究人员使用 目标完成评分 (Goal Completion Score,范围 0-10) 来评估模拟。他们观察了各种场景,特别是关注:
- 合作场景: 例如,“共同好友”,两个陌生人试图找出他们是否认识同一个人。
- 竞争场景: 例如,“Craigslist”,买方和卖方就价格进行讨价还价。
结果
数据显示,SCRIPT 的幻想与 AGENTS 的现实之间存在巨大差异。
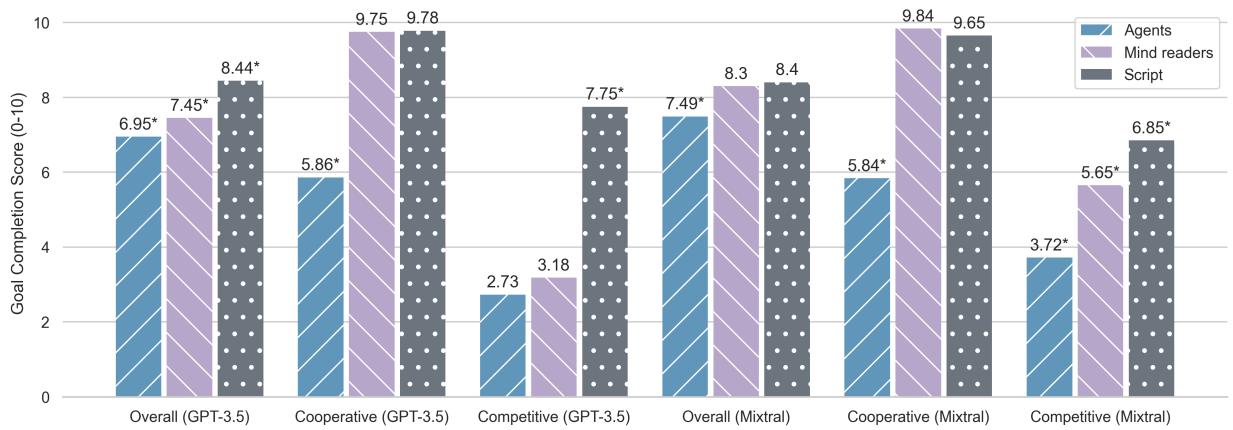
观察 图 2 , 我们可以得出几个结论:
- SCRIPT 是简单模式: 灰色条 (Script) 始终显示很高的目标完成分 (超过 8/10) 。当一个模型控制宇宙时,它能确保角色成功。
- AGENTS 陷入挣扎: 蓝色条 (Agents) 显示性能显著下降 (总体降至 6.95 左右) 。对于 GPT-3.5 来说,在竞争场景中的下降是灾难性的,暴跌至 2.73 分。
- 读心有帮助: 有趣的是,MINDREADERS 模式 (紫色) 的表现更接近 SCRIPT 模式。这证实了问题不仅仅在于拥有两个模型;问题在于信息不对称 。 当你拿走智能体的心灵感应时,它们就崩溃了。
在合作场景 (中间的柱状图组) 中,MINDREADERS 和 SCRIPT 模式几乎相同。这是合理的——如果我确切知道你的朋友是谁,找到共同好友就轻而易举。但对于必须提问并推断答案的 AGENTS 来说,这项任务要难得多。
在竞争场景 (右侧的柱状图组) 中,AGENTS 模式崩溃了。在不知道对手保留价格的情况下,LLM 很难达成交易,通常根本无法达成协议,而 SCRIPT 模式本质上是“操纵”了谈判以确保交易发生。
实验 2: 自然度差距
能力并不是唯一的指标。社交互动还需要感觉自然。如果一个智能体实现了目标,但听起来像是一个在念法律免责声明的机器人,那么模拟就失败了。
研究人员收集了人工评估,以判断哪些对话听起来更像真实的人类互动。他们还测量了冗长程度 (verbosity,即每轮多少个单词) 。
啰嗦问题
AGENTS 模拟失败的最直接迹象之一是对话的长度。

如 图 3 所示, AGENTS 模式 (绿色框) 倾向于重复和过度正式。智能体在“我理解”和“这有道理”之间循环,对着彼此说话 (talking at each other) ,而不是与彼此交谈 (talking with each other) 。
相比之下, SCRIPT 模式 (红色框) 生成的对话包含非语言线索 (如打哈欠) 和简洁自然的来回对话。因为单一模型在其上下文窗口中同时生成整个对话历史,所以它保持了一致的流畅度和风格。
人类偏好
当人类被要求选择更自然的对话时,结果压倒性地支持全知模拟。
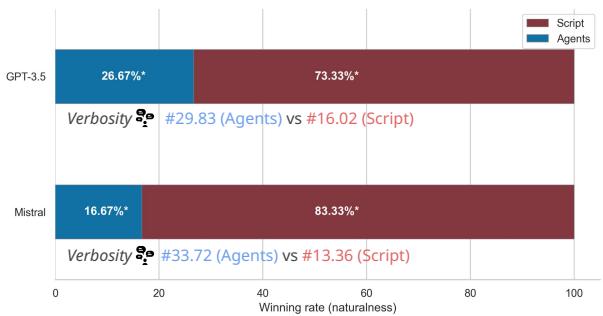
图 4 显示,对于 GPT-3.5,SCRIPT 模式在 73.33% 的情况下被判定为更自然。AGENTS 模式也受到极端冗长的困扰 (每轮近 30 个单词,而 Script 只有 16 个) 。
这对研究人员来说是一个危险的悖论。SCRIPT 模式产生的数据看起来更好——它更自然,更成功,读起来更顺畅。但它是人造的 。 它没有反映真实社交互动的认知挣扎。如果我们依赖 SCRIPT 模拟来判断 LLM 的能力,我们就是在极大地高估它们的社交智能。
我们能教智能体作弊吗? (微调实验)
所以,我们面临一个问题: 智能体虽然设定现实,但互动得很糟糕。剧本虽然设定不现实,但互动得很好。
研究人员提出了一个合乎逻辑的后续问题: 我们能否利用来自 SCRIPT 模拟的高质量数据来训练更好的 AGENTS?
他们在 SCRIPT 生成的对话数据集上微调了 GPT-3.5。目标是教模型像智能体一样行动,但说话时具有剧作家的自然度和成功率。他们称这个模型为 AGENTS-ft (微调版) 。
“纸老虎”结果
乍一看,微调似乎奏效了。自然度显著提高,冗长程度下降。智能体开始听起来更像人类了。
然而,在观察目标完成情况时,出现了一个有趣而令人不安的模式。
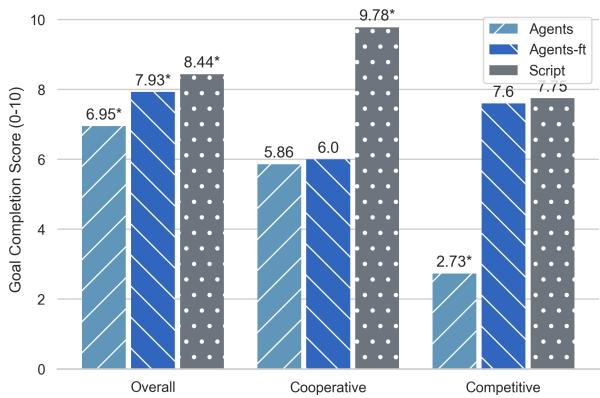
在 图 5 中,请看合作 (Cooperative) 部分。微调后的智能体 (深蓝色) 几乎没有比基础智能体 (浅蓝色) 有什么提升,而且仍然远远落后于 Script (灰色) 。
为什么在“完美”对话上进行训练却未能提高合作任务的表现?
信息泄露偏差
答案在于 SCRIPT 模式是如何取得成功的。它作弊了。
在像“共同好友”这样的场景中,两个人需要找到一个他们都认识的人。
- 人类/智能体方法: “你认识芝加哥大学的人吗?” -> “不认识。” -> “那打网球的人呢?” -> “是的,我认识 Bob。”
- SCRIPT 方法: 因为模型知道双方的好友列表,它跳过了搜索过程。“嘿,你认识 Bob 吗?” -> “认识!”
当研究人员在 SCRIPT 数据上微调智能体时,智能体学习了剧本的风格 , 但无法复制全知能力 。 微调后的智能体会学到“正确”的互动方式是立即猜出一个名字。但因为它实际上不知道另一个智能体的好友列表,它只是随机猜测或产生幻觉。
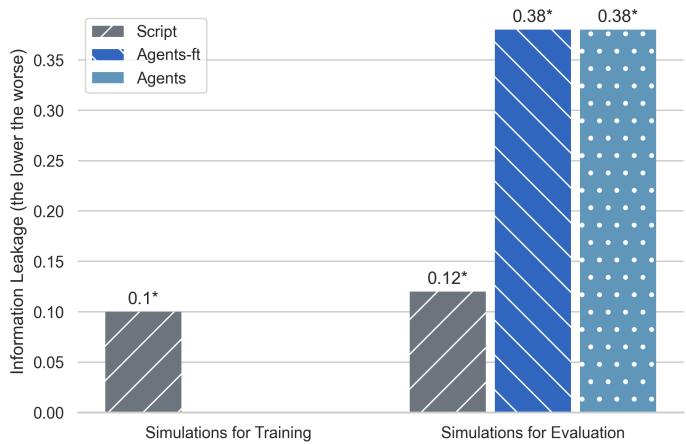
图 10 展示了这种“信息泄露”。条形图代表共同好友在对话中被提及的相对位置 (越低意味着越早) 。
- Script (灰色) : 几乎立即提及名字 (0.1) 。
- Agents (蓝色/条纹) : 必须进行搜索,所以名字出现得较晚 (0.38) 。
SCRIPT 模拟偏向于利用本不应获得的信息。在这个数据上训练智能体就像通过给学生答案来教他们通过考试。当你拿走答案 (把他们放入 AGENTS 模式) 时,他们就会失败,因为他们从未学会如何解决问题——他们只学会了写下答案。
顺从偏差
在竞争场景中,微调实际上确实提高了目标完成分数 (见图 5 中的“竞争”部分) 。但这同样具有误导性。
SCRIPT 模拟存在巨大的顺从性 (Agreeableness) 偏差。单一模型想要解决故事,所以它强迫角色达成交易。
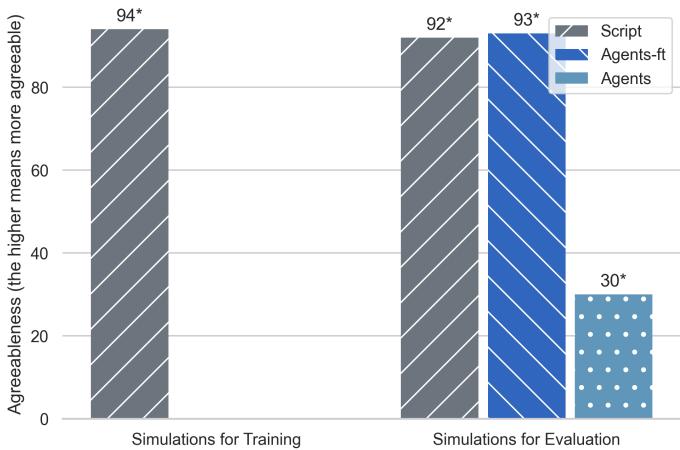
图 11 显示了最终达成交易的互动百分比。
- Agents (蓝色) : 只有约 30% 的时间达成交易。这是现实的;买家和卖家有时就是无法达成一致。
- Script (灰色) : 94% 的时间达成交易。
- Agents-ft (条纹) : 93% 的时间达成交易。
微调后的模型并没有学会成为一个更好的谈判者;它学会了做一个软柿子。它学到了“正确”的社交互动总是以“是”结束,模仿了全知剧作家的偏见。
“猜谜游戏”可视化
为了可视化这些模型在处理信息方面的行为有多么不同,研究人员绘制了共同好友在对话中被发现的时间分布图。
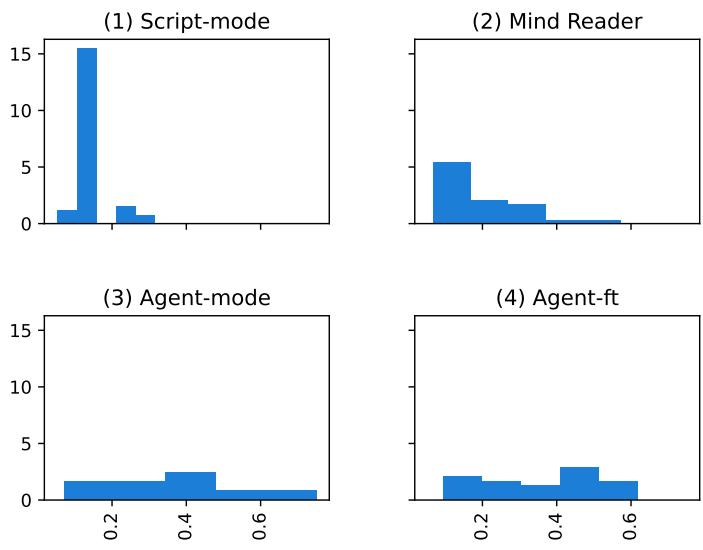
图 12 很有说服力:
- Script-mode (左上) : 在最开始 (x=0) 有一个巨大的尖峰。模型瞬间猜出了名字。
- Agent-mode (左下) : 分布很分散。智能体必须为此付出努力。
- Agent-ft (右下) : 它看起来像是一个困惑的混合体。它试图尽早猜测 (模仿剧本) ,但经常失败,导致出现一个奇怪的分布,既不匹配剧本的效率,也不匹配智能体的有机搜索过程。
结论: 幻想的危险
这篇论文对 AI 社区来说是一个至关重要的现实检验。它强调, 模拟社交互动不仅仅是生成流畅的文本;它是关于模拟不确定的、信息不对称的沟通过程中的认知过程。
主要结论如下:
- 全知是一个陷阱: 使用单一的“上帝模式”LLM (SCRIPT) 进行模拟会产生不切实际、过于成功和有偏差的数据。它高估了 LLM 的能力。
- 现实很难: 当置于现实设定 (AGENTS) 中时,LLM 在冗长程度和策略推理 (心智理论) 方面举步维艰。
- 你无法伪造它: 在全知剧本上微调智能体并不能教会它们社交技能;这教会了它们坏习惯 (幻觉知识和过度顺从) 。
模拟卡片
作者提出了一个解决方案: 透明度。他们建议未来的研究应包含一张 “模拟卡片” (类似于模型卡片) ,明确说明:
- 这是单智能体还是多智能体模拟?
- 每个智能体拥有什么信息?
- 我们是在测试现实性还是仅仅在生成故事?
通过承认剧本编写的“幻想”与智能体互动的“现实生活”之间的差距,我们可以停止追逐误导性的指标,并开始构建真正理解人类社会动态复杂性的 AI。在 LLM 能够驾驭“我知道你不知道的事情”这一混乱、不确定的世界之前,它们仍然是高效的剧作家,却是蹩脚的演员。