](https://deep-paper.org/en/paper/2403.09073/images/cover.png)
多语言剪枝: 并行多语言输入如何模拟生物大脑
如果你尝试过学习第二语言,你会知道你的大脑经常在寻找联系。你可能会通过将法语中的新概念与英语 (或者如果你懂西班牙语的话) 中的概念联系起来,从而锚定这个新概念。这种三角定位有助于巩固理解。
有趣的是,新的研究表明大型语言模型 (LLM) 的运作方式与之颇为相似。虽然 GPT-4 或 Qwen 等模型是在海量多语言数据集上训练的,但我们通常在一个“单语”隧道中与它们交互——用英语提问并期望得到英语回答,或者请求从德语翻译成英语。
但是,如果我们不再把模型仅仅当作一本词典,而是把它当作一场多语言会议,会发生什么呢?
在一篇题为 “Revealing the Parallel Multilingual Learning within Large Language Models” 的精彩论文中,研究人员展示了向 LLM 同时输入多种语言的内容——一种被称为 并行多语言输入 (Parallel Multilingual Input, PMI) 的技术——可以极大地提高性能。但性能提升的原因更令人惊讶: 这样做实际上“让神经网络安静了下来”,抑制了多余的神经元并使模型的注意力更加集中,这非常像人类大脑中的 突触剪枝 (synaptic pruning) 过程。
在这篇深度文章中,我们将剖析 PMI 的工作原理、背后的神经机制,以及为什么“更多语言”可能实际上意味着“更少噪音”。
1. 单行道的局限性
在理解解决方案之前,我们必须先看看现状。使用 LLM 完成任务 (比如翻译句子或解数学题) 的标准方法是 上下文学习 (In-Context Learning, ICL) 。 你提供指令,也许还有几个示例 (shots) ,以及输入文本。
即使我们使用花哨的“跨语言”提示 (例如,要求模型用英语思考来解决中文问题) ,我们通常也依赖于 枢轴 (pivot) 策略。我们将输入翻译成主导语言 (通常是英语) ,进行处理,然后再翻译回来。
研究人员认为这种方法浪费了大量的智能。LLM 在其大规模训练期间已经学习了跨语言概念的“通用表征”。通过将输入限制为单一语言,本质上就像是强迫模型通过锁孔来观察 3D 物体。
进入并行多语言输入 (PMI)
本文的核心贡献是一种新的提示策略,称为 并行多语言输入 (PMI) 。
这个概念简单而强大: 不仅仅给模型源文本,而是给它源文本加上其在几种其他语言中的翻译。这些翻译充当了平行的上下文锚点。
让我们看看数学上的差异。在传统的 ICL 中,模型基于单一输入 \(\mathbf{X}\) 的函数来预测输出 \(\mathbf{Y}\):
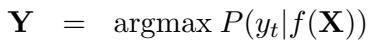
在 PMI 中,模型基于输入 \(\mathbf{X}\) 和一组平行翻译 \(\mathbf{M}\) 来预测 \(\mathbf{Y}\):
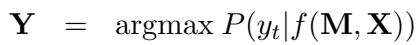
这里,\(\mathbf{M} = \{m_1, m_2, ..., m_k\}\) 代表同一个句子被翻译成了 \(k\) 种不同的语言。
可视化差异
为了理解这在实践中是什么样子的,请看下图。在顶部区域 (传统 ICL) ,模型看到一个德语句子。在底部区域 (PMI) ,模型看到德语句子,外加俄语、法语、乌克兰语、意大利语和西班牙语版本。
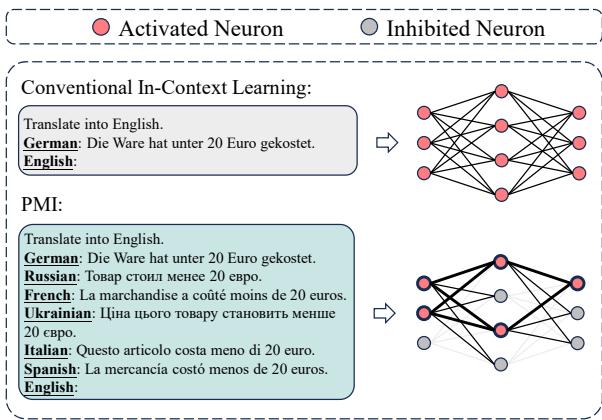
正如 图 2 所示,提示提供了一个丰富的、多视角的上下文。但请仔细观察图像右侧的“网络 (Network) ”可视化。在传统方法中,许多神经元被点亮 (红圈) 。在 PMI 方法中,许多神经元变成了灰色 (被抑制) ,而活跃的路径更粗、更清晰。
这种可视化暗示了论文最重要的发现: PMI 改变了模型的神经激活模式。
2. 神经机制: 通过抑制实现效率
为什么向输入添加更多文本会导致更好的输出?人们可能会假设更多的数据意味着更多的处理和更多的神经元激活。研究人员发现情况恰恰相反。
要理解这一点,我们需要快速回顾一下 Transformer 模型 (如 LLM) 中的神经元是如何工作的。
神经元的生与死
在 Transformer 的前馈网络 (FFN) 层内部,神经元使用 激活函数 处理信息。这些函数决定神经元是应该“激发” (向前传递信息) 还是保持沉默。常见的函数包括 ReLU (线性整流单元) ,以及它更平滑的近亲 GELU 和 SiLU 。
关键是,这些函数具有门控机制。如果输入值为负,它们通常输出零 (或接近零) 。
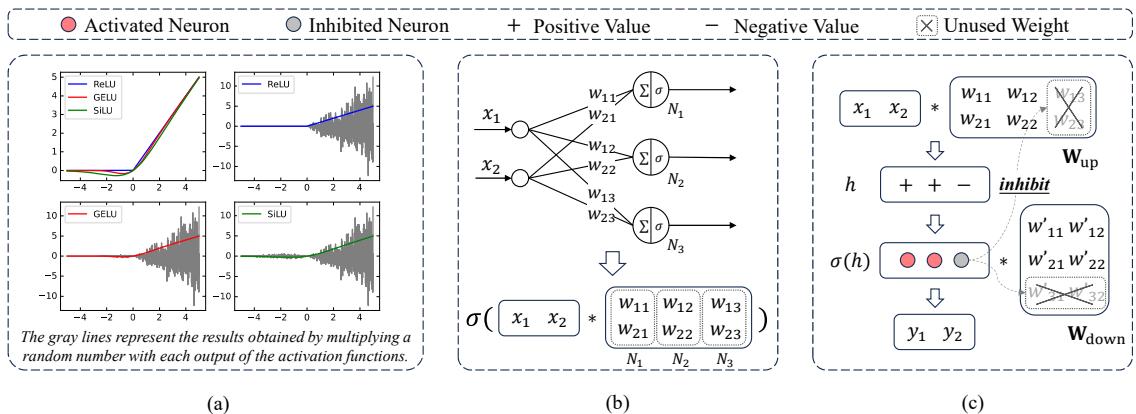
上面的 图 3 阐释了这个概念:
- 面板 (a) 显示了这些函数的曲线。注意当输入为负时,它们是如何变平或下降到接近零的。
- 面板 (c) 显示当激活函数输出零时,该神经元实际上被“抑制”了,或者说在针对该特定 token 的计算中被移除了。
“安静”的教室
研究人员测量了使用标准提示与 PMI 提示时激活神经元的比例。他们发现了一个一致的相关性: 随着输入中添加的语言越多,激活神经元的百分比就会下降。
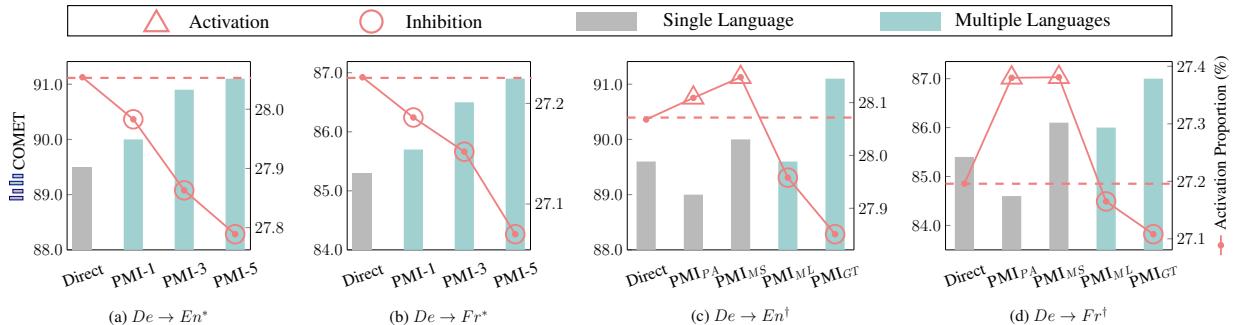
请看 图 4 中的图表。
- 红色三角形 (Activation) 代表性能 (COMET 分数) 。
- 蓝色/青色柱状条代表激活比例。
在图 (a) 和 (b) 中,随着并行语言数量的增加 (在 x 轴上向右移动) ,性能上升 (红线由低走高) ,但活跃神经元的数量下降 (青色柱条收缩) 。
这表明单语输入是“嘈杂的”。它激活了大量的神经元,可能是因为模型正在寻找正确的上下文或消除歧义。多语言输入通过提供三角定位点,允许模型抑制不相关的神经元,专注于核心语义。
模拟突触剪枝
作者与神经科学建立了一个令人信服的类比。在人脑中,当我们成熟时会发生一个称为 突触剪枝 的过程。大脑消除较弱或不必要的突触连接,使剩余的神经通路更高效、更强大。儿童大脑的连接比成人的多,但成人的大脑在处理复杂任务时效率更高。
PMI 似乎在推理过程中诱导了一种“一次性突触剪枝”。它不会永久改变模型 (那是训练做的事) ,但在任务持续期间,它迫使模型进入一种更成熟、更高效的状态。
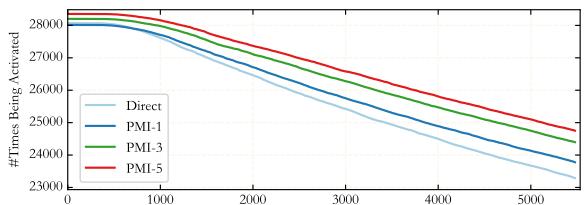
图 5 可视化了这种“锐化”效应。曲线显示了前 1% 神经元的激活频率。PMI 曲线 (彩色线) 在左侧起点更高,并且比直接提示 (Direct prompt) 下降得更快。这意味着 最重要 的神经元被使用得 更 强烈,而不太重要的神经元则被忽略了。
3. 剖析改进的来源
怀疑论者可能会问: “真的是 语言 在起作用吗?还是仅仅因为我们给了模型更多的信息?”
为了回答这个问题,研究人员进行了消融研究,使用了不同的提示策略,如下图所示:
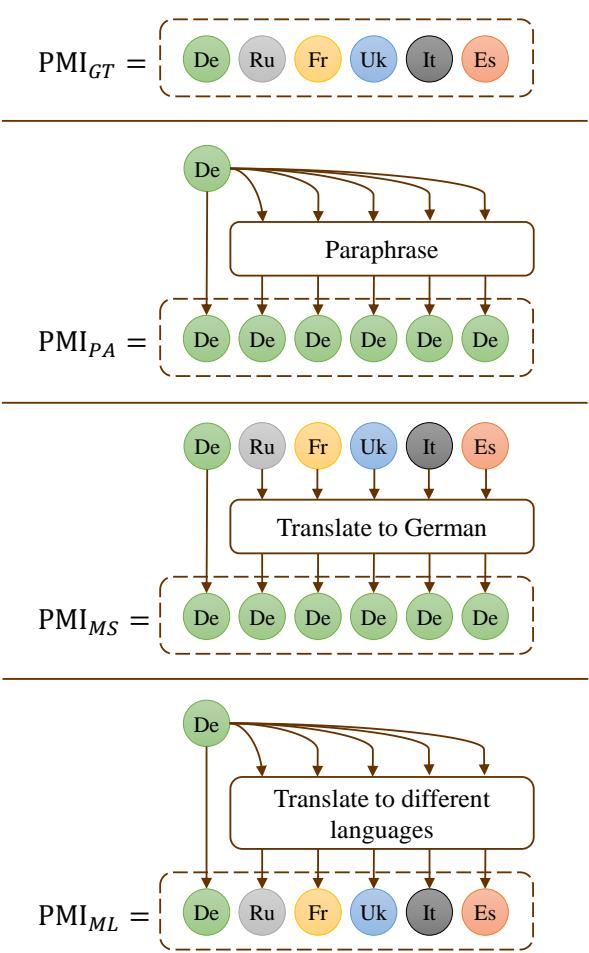
他们比较了四种方法 (如 图 8 所示) :
- PMI_GT: 地面真值翻译 (人类专家) 。
- PMI_PA: 释义源句子 (单源,单语) 。
- PMI_MS: 由不同专家回译成源语言 (多源,单语) 。
- PMI_ML: 机器翻译成不同语言 (单源,多语) 。
结果: 多语言提示 (\(PMI_{ML}\)) 的表现始终优于单语释义 (\(PMI_{PA}\)) 。即使信息源相同 (只是由机器翻译的原始句子) ,以多种语言呈现它比用同一种语言重述它能释放出更好的性能。
这证实了语言视角的差异性——即“多语言性”本身——是触发模型高效表征的关键因素。
4. 性能: 它真的有效吗?
理论听起来很有道理,但结果如何呢?研究人员在各种任务中测试了 PMI,主要是机器翻译,但也包括自然语言推理 (NLI) 和数学推理。
翻译质量
在 FLORES-200 基准测试中,结果令人震惊。
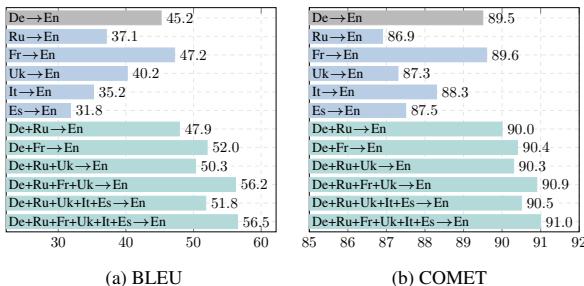
图 1 展示了 BLEU 和 COMET 分数 (翻译质量的指标) 。每张图表最右边的柱状条——代表 5 或 6 种语言的组合——远远高于单语言的柱状条。
- BLEU 分数: 提高了多达 11.3 分。
- COMET 分数: 提高了 1.52 分 (在这个指标中这是一个显著的幅度) 。
关键是,下面的 表 1 显示,PMI (特别是 PMI-3 和 PMI-5,意味着 3 或 5 种并行语言) 始终击败直接翻译 (Direct) 和枢轴翻译 (Pivot,即通过英语翻译) 。
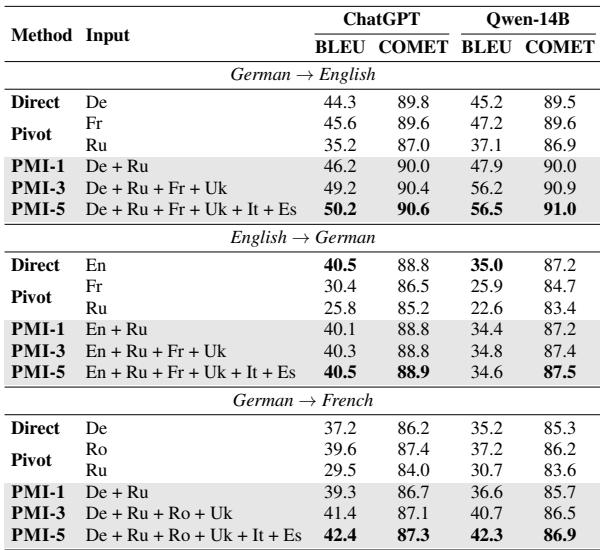
超越翻译: 数学和推理
PMI 的好处不仅限于语言任务。研究人员将这项技术应用于 GSM8K 数据集 (数学应用题) 。他们使用 GPT-4 将数学问题翻译成其他语言,然后将它们作为并行输入反馈给模型。
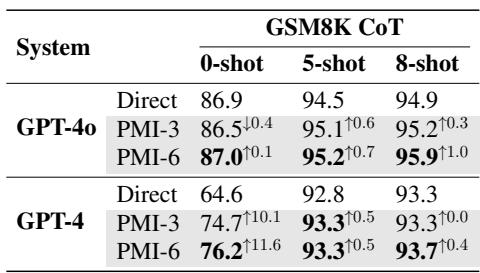
如 表 6 所示,使用 PMI 将 GPT-4 的准确率从 64.6% (直接 0-shot) 提升到了 76.2% (PMI-6 0-shot) 。这是一个巨大的飞跃,表明看到用英语、法语、德语等陈述的数学问题,比仅用英语更能帮助模型“理解”数学逻辑。
5. 实际实施与局限性
如果你是学生或开发者,想使用这个方法,你可能会问: “我的提示需要人类翻译吗?”
答案是 不需要 。 研究人员发现,你可以使用 LLM 本身 (或其他机器翻译系统) 来动态生成并行输入。
工作流程:
- 获取你的输入查询 (例如,英文) 。
- 要求 LLM 将其翻译成法语、德语和西班牙语。
- 构建一个包含英文原文 + 3 个生成的翻译的新提示。
- 要求 LLM 基于这个组合输入执行最终任务 (推理、回答、翻译) 。
权衡
虽然有效,但 PMI 也有成本:
- 推理成本: 你向模型输入了更多的 token (翻译) ,这增加了计算成本和时间。
- 延迟: 生成中间翻译需要时间。
然而,作者指出,性能的提升往往超过了成本,特别是对于准确性至关重要的复杂任务。
结论: 通用的思维语言
论文 “Revealing the Parallel Multilingual Learning within Large Language Models” 对人工智能的本质提供了深刻的见解。它表明 LLM 拥有一种潜在的、与语言无关的“思维”过程。
当我们用一种语言与模型交谈时,我们激活了特定语言和特定概念神经元的嘈杂混合体。当我们用多种语言的合唱与它们交谈时,特定语言的噪音被相互抵消,留下了潜在概念的纯粹、高效且高度准确的表征。
通过提示工程模拟一种“突触剪枝”,PMI 使我们能够挖掘这些模型的全部通用潜力。对于学生和研究人员来说,这开启了提示工程的新前沿: 不仅要思考我们对模型说了 什么,还要思考我们用 多少种方式 去说。