](https://deep-paper.org/en/paper/2403.19647/images/cover.png)
像 GPT-4 这样的语言模型可以写诗、编程和撰写有说服力的文章。但它们究竟是如何做到的呢?如果你问一位人工智能研究员,你可能会看到一张充满“神经元”和“注意力头”的复杂图表。这就像试图通过检查字母来理解小说的情节——它能告诉你一些信息,但对故事内容却几乎不了解。每个神经元都是多义的 (polysemantic) , 同时扮演着多种角色。这使得我们难以将模型的行为与其内部机制对应起来,从而在安全性、可靠性和偏见控制方面面临重大挑战。
如果我们能在这些模型内部找到类似于词语或句子的东西——一些可以命名的离散概念,比如“检测复数名词”或“识别日期”,那会怎样?又如果我们能追踪这些概念之间的交互,并看到它们如何组合成驱动模型预测的推理过程呢?
一篇新的研究论文 《稀疏特征回路: 发现并编辑语言模型中可解释的因果图》 (Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models) 介绍了一种实现这一目标的方法。作者提出了一种强大的技术,可以自动发现稀疏特征回路——一种通过人类可理解的语义单元而非不透明的神经元来解释模型行为的因果图。
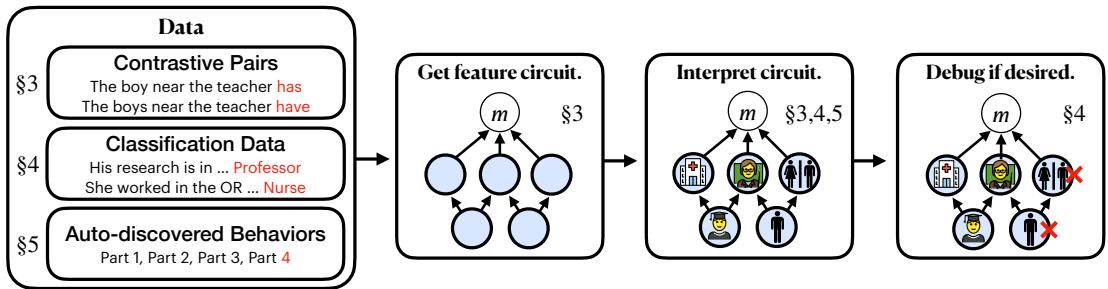
图 1: 稀疏特征回路方法概览——从数据到可解释的因果图。
这一突破不仅在于窥探语言模型内部——更在于负责任地改变它们 。 作者展示了如何利用这些回路精准地编辑模型行为,例如在没有特殊去偏数据的情况下,消除分类器中的性别偏见。本文将拆解这些回路的构建过程,以及它们的重要意义。
概览
我们将探讨论文中的五个核心思想:
- 基础要素: 用于发现概念的 稀疏自编码器 (SAE) , 以及用于衡量其影响的 因果追踪 (Causal Tracing) 。
- 作者如何利用这些工具组装稀疏特征回路。
- 这些回路揭示了语言推理的内部机制。
- SHIFT 技术如何编辑模型以移除虚假信号。
- 整个过程如何扩展以自动解释数千种行为。
构建模块: 概念与因果性
要建立可解释的回路,我们首先需要从模型中提取有意义的特征,并衡量这些特征对预测的因果影响。论文将两种互补思想结合起来,实现这两个目标。
使用稀疏自编码器 (SAE) 寻找可解释特征
在语言模型内部,每个激活值都是高维空间中的一个向量。单个神经元对应于这个空间中的一个方向——通常是各种不相关模式的混合。 稀疏自编码器 (SAE) 以可解释的方向取代这些神经元。
SAE 学习一个特征字典,可以高效地重构模型激活值,同时施加稀疏性约束,使得每个输入只有少数特征被激活。这通常会产生单义 (monosemantic) 特征——对特定概念的清晰表示,例如“女性代词”、“数字词元”或“名词短语边界”。
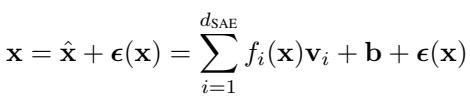
公式 1: 激活值的稀疏自编码器分解。
形式上,SAE 将一个激活向量 \( \mathbf{x} \) 重构为特征激活 \( f_i(\mathbf{x}) \) 与特征向量 \( \mathbf{v}_i \) 的稀疏和,外加一个小的误差项 \( \epsilon(\mathbf{x}) \)。作者保留了这个误差项,将其视作未解释部分的占位符。通过在 Pythia-70M 和 Gemma-2-2B 等模型的主要组件上训练 SAE,他们构建了大型、可解释的模型特征字典——这是构建回路的原始材料。
使用因果追踪寻找关键因素
知道特征代表什么只是开始。要理解它们如何影响模型输出,作者使用了因果中介分析 (causal mediation analysis) , 它用来度量模型内部组成部分的间接效应 (IE)。

公式 2: 间接因果效应的计算。
例如,考虑以下句子:
- *干净输入: * “The teacher is…”
- *补丁输入: * “The teachers are…”
通过将复数示例的激活“补丁”到干净示例中,我们可以观察某个特定特征 (比如检测复数性的特征) 在驱动模型从“is”到“are”之间做出判断的作用强度。
由于精确计算每个组件的代价太高,论文提出了快速线性近似方法。最简单的一种,称为归因补丁 (attribution patching),使用输出相对于每个激活值的梯度:
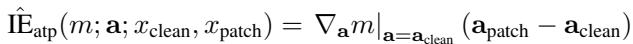
公式 3: 用于因果效应估计的归因补丁。
更准确的方法是 积分梯度 (integrated gradients) , 它对“干净”和“补丁”激活之间路径上的梯度进行平均:
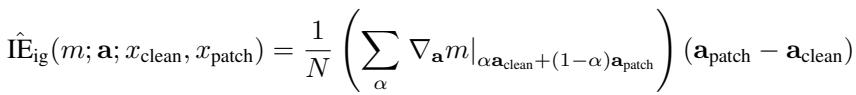
公式 4: 积分梯度提高了复杂组件的估计精度。
有了可解释特征 (是什么) 和因果影响 (影响大小) ,我们就能开始绘制整个因果回路。
核心方法: 发现稀疏特征回路
作者不再把模型视为由神经元组成的网络,而是将其看作由特征构成的图。每个节点表示某个词元位置上的一个 SAE 特征或误差项。通过因果追踪,他们识别出哪些节点和连接在输出中起关键作用。
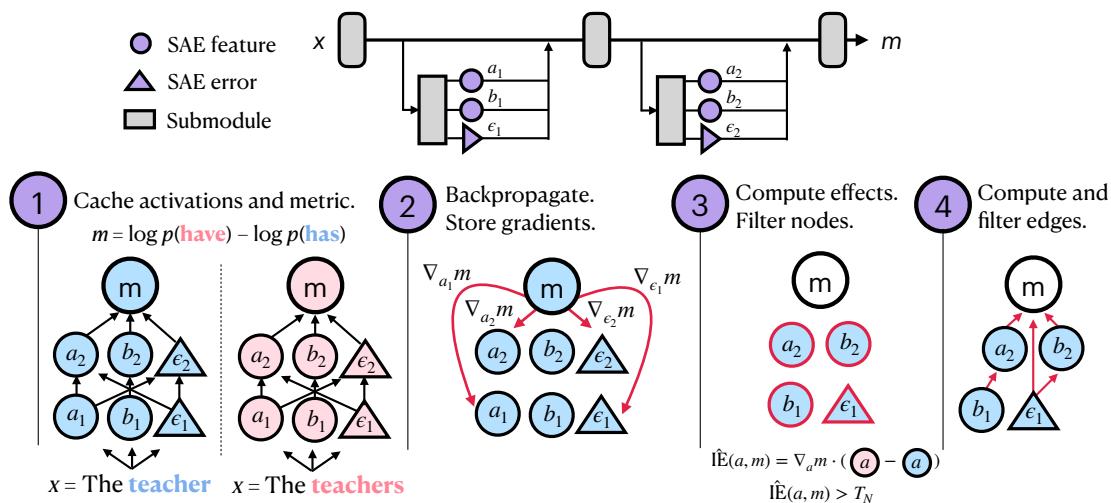
图 2: 利用因果追踪发现回路的四步流程。
整个过程包括:
- 缓存激活和梯度: 在相关数据 (如对比输入对) 上运行模型,收集所有特征激活和梯度。
- 反向传播效应: 计算选定度量 (例如 “has” 与 “have” 的对数概率差) 的梯度。
- 筛选节点: 使用线性近似估计每个节点的间接效应,丢弃影响微弱的节点以获得更稀疏的集合。
- 筛选边: 计算节点之间的因果效应,识别真正重要的连接。
最终形成一个简洁的有向图——即一个稀疏特征回路 , 它揭示了离散、可解释概念如何协同驱动模型的行为。
测试回路: 主谓一致
为了验证该方法,作者在主谓一致这一经典语言现象上进行了实验测试,该现象具有不同层次的结构复杂度。

表 1: 用于回路发现的主谓一致结构。
评估包含三个方面:
- 可解释性 (Interpretability): 人类标注者认为来自回路的 SAE 特征远比随机特征或原始神经元更易理解。
- 忠实性 (Faithfulness): 如果模型的非回路部分被消融,回路能多大程度上重现原始结果?
- 完整性 (Completeness): 若仅消融回路本身,是否会破坏模型的性能?
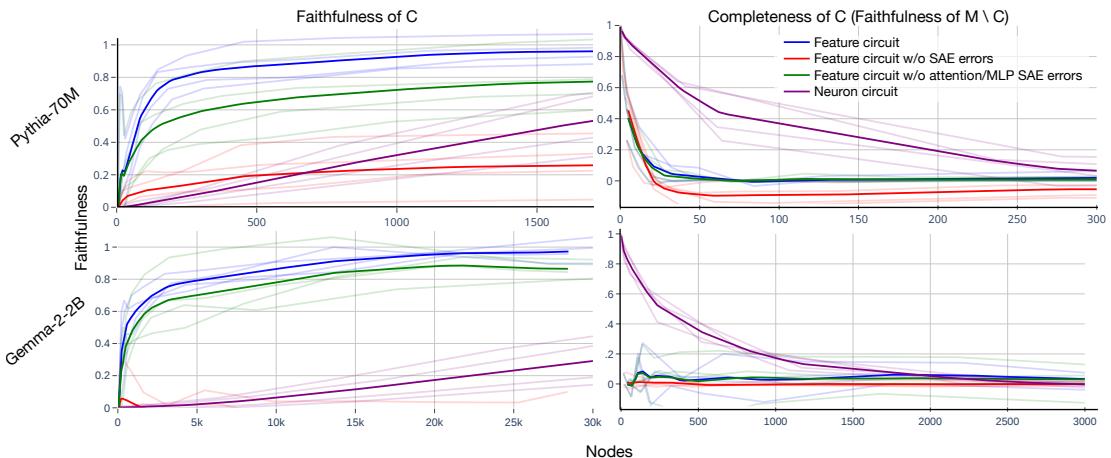
图 3: 特征回路比神经元回路更高效、更完整地解释模型行为。
结果显示: 小规模的特征回路就能捕捉模型的大部分推理过程。对于 Pythia-70M,少于 100 个特征 就能复现与 1500 个神经元 相当的行为。而仅消融这些特征便会彻底破坏模型的语法能力——证明回路既忠实又完整。
案例研究: 跨关系从句的一致性
考虑以下挑战: “The girl that the teacher sees has” 与 “The girls that the teacher sees have.” 模型必须忽略干扰项“teacher”,正确地将“girls”与“have”关联。
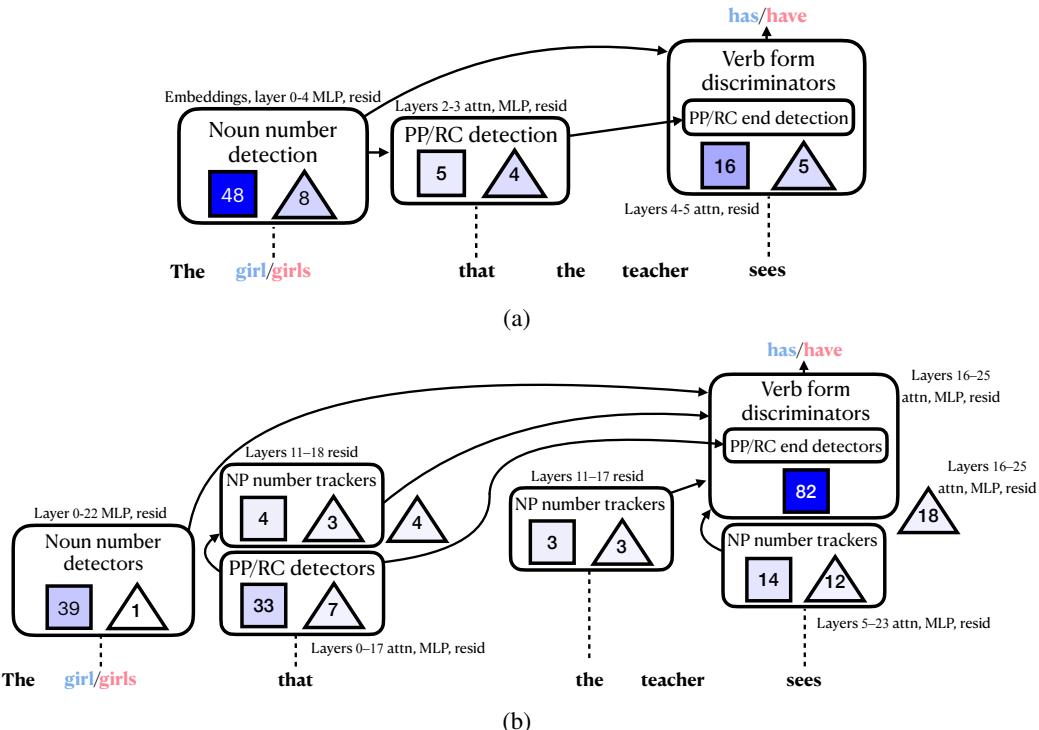
图 4: Pythia 和 Gemma 中跨关系从句主谓一致的回路。
回路揭示出清晰且可解释的推理过程:
- 名词数检测: 早期特征在主语 (“girl”/“girls”) 处激活,用于判断单复数。
- 边界检测: 特征识别像 “that” 这样的关系从句标记,提示干扰短语的开始。
- 信息传播: 主语单复数信息沿层向前传递。Gemma-2-2B 保持专门的名词短语数值追踪器,在整个短语中持续激活。
- 动词形式选择: 靠近输出层时,动词变位特征利用捕获的数值信息选择 “has” 或 “have”。
这些步骤勾勒出模型内部的人类可读语言理解“算法”。
使用 SHIFT 编辑偏见
当可解释性可以被用来改进模型时,它的价值最大。作者展示了稀疏人类可解释特征修剪 (SHIFT) 技术,用于从分类器中移除非预期信号。
问题
训练好的分类器常会依赖虚假线索——例如性别与职业相关。以往去偏方法需要专门标注的数据来识别这些信号。SHIFT 无需任何消歧数据 , 仅依赖可解释性和人工判断。
方法
- 使用稀疏特征方法发现分类器的特征回路。
- 检查每个特征,将其标记为任务相关或虚假。
- 消融虚假特征 (如在性别词上激活的特征) 。
- (可选) 使用相同的有偏数据重新训练最终分类层。
测试: 个人简介偏见
作者使用 Bias in Bios (BiB) 数据集——包含职业与性别标签的个人简介。棘手的模糊集仅包括男性教授和女性护士,因此性别完美预测职业。SHIFT 需要在无法访问性别信息的前提下重建能正确识别职业的分类器。
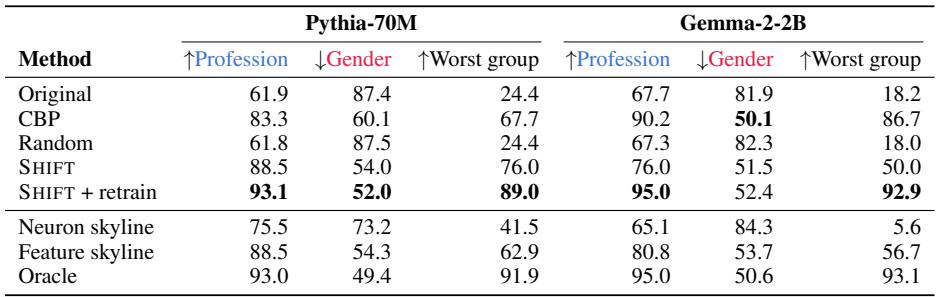
表 2: SHIFT 能在移除性别偏见的同时保持或提升模型性能。
结果十分显著。在 Pythia-70M 上:
- 原始职业预测准确率: 61.9%
- SHIFT + 重新训练后: 93.1% , 几乎与基于无偏数据训练的“神谕”模型相当。
- 性别预测准确率从 87.4% 降至 52.0%——偏见几乎被消除。
当将该方法应用于神经元而非 SAE 特征时,效果消失: 神经元混合多重含义,消融会破坏有用信息。SHIFT 有效的原因是稀疏特征是解耦的,使因果编辑精确且有意义。
扩展规模: 自动化回路发现
到目前为止,我们手动选择了任务。但语言模型拥有成千上万种涌现的细微行为。为了探索它们,研究者搭建了一个全自动的无监督行为发现流水线 。
- 发现行为: 在大型语料 (The Pile) 上运行模型,提取内部表示或梯度并聚类——将触发类似机制的上下文分组。
- 发现回路: 自动将稀疏特征回路方法应用到每个簇。

图 5: 自动发现的用于数字连续与不定式“to”的回路。
案例包括:
- 序列递增: 模型将广义“连续”特征与识别模式
A3 ... A → 4的“归纳”特征结合。 - 不定式宾语: 不同机制检测带 “to” 补语的动词以及位于其前的直接宾语。
该自动化系统可生成数千个可解释回路。你可以在 feature-circuits.xyz 上交互式探索它们。
结论
稀疏特征回路 是机械可解释性领域的重要里程碑。通过将焦点从不透明的神经元转向清晰的人类可解释稀疏特征,作者实现了:
- 可解释性: 以有意义的概念构成清晰因果图。
- 忠实性: 回路能够准确复现模型行为。
- 可操作性: SHIFT 等方法支持精确且合乎伦理的模型编辑。
- 可扩展性: 自动化流水线揭示数千种内部机制。
这一方法让可解释性从被动观察工具变为主动干预工具——使我们不仅能了解模型如何思考,还能负责任地塑造其思考方式。未来的进步将依赖于更优的稀疏自编码器和系统化评估方法。但愿景已然清晰: 一个透明、可编辑且对齐的人工智能世界——因为我们终于理解了它的回路。