](https://deep-paper.org/en/paper/2404.03868/images/cover.png)
知识图谱 (Knowledge Graphs, KGs) 是现代人工智能的幕后英雄。它们为推荐引擎背后的决策提供支持,提高了问答系统的准确性,并提供了非结构化文本所缺乏的结构化“世界知识”。
但在构建知识图谱时,困难重重。传统上,这需要大量的人力来定义模式 (Schema,即图谱的规则) 并将数据映射到这些模式上。最近,像 GPT-4 这样的大型语言模型 (LLM) 在自动化这一过程中显示出了前景。你只需给 LLM 一段文本和一个允许的关系列表 (即模式) ,然后要求它提取数据即可。
但这有一个陷阱。 现实世界中的模式非常庞大。例如,Wikidata 有数千种关系类型。你无法将一个巨大的模式塞进 LLM 提示词 (Prompt) 的上下文窗口中。即使你能做到,模型也很可能会“迷失在中间 (lost in the middle) ”,忽略掉埋藏在大量文本中的指令。
那么,如何在不触碰这些限制的情况下扩展自动化知识图谱构建 (KGC) 呢?
在这篇文章中,我们将深入探讨 Bowen Zhang 和 Harold Soh 最近发表的一篇题为 “Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction” (抽取、定义、规范化: 一种基于 LLM 的知识图谱构建框架) 的论文。他们提出了一个名为 EDC 的巧妙的三阶段框架,将信息抽取与模式映射分离开来,从而即使在面对大规模模式或不存在模式的情况下,也能构建高质量的图谱。
核心问题: 模式瓶颈
要理解这里的创新点,我们需要先看看标准方法,通常称为封闭式信息抽取 (Closed Information Extraction) 。
在封闭式 IE 中,你有一组预定义的关系,例如 bornIn (出生于) 、worksFor (就职于) 或 invented (发明了) 。你将一个句子连同这个列表提供给 LLM,并说: “提取符合这些特定关系的三元组。”
这对小型的、特定领域的任务很有效。但在现实场景中,这种方法会崩溃:
- 上下文窗口溢出: 大型模式超出了 Token 限制。
- 僵化: 如果文本描述了一种不在你预定义列表中的关系,这些信息就会丢失。
- 未知模式: 有时,你甚至不知道自己在寻找什么——你希望数据来告诉你模式应该是什么样的。
研究人员提出了视角的转变: 不要在抽取时强行套用模式。留到后面再修复。
EDC 框架
研究人员介绍了 EDC , 即 抽取 (Extract) 、定义 (Define) 和规范化 (Canonicalize) 。 他们不再试图在一个提示词中完成所有工作,而是将任务分解为三个利用 LLM 优势的独特阶段。
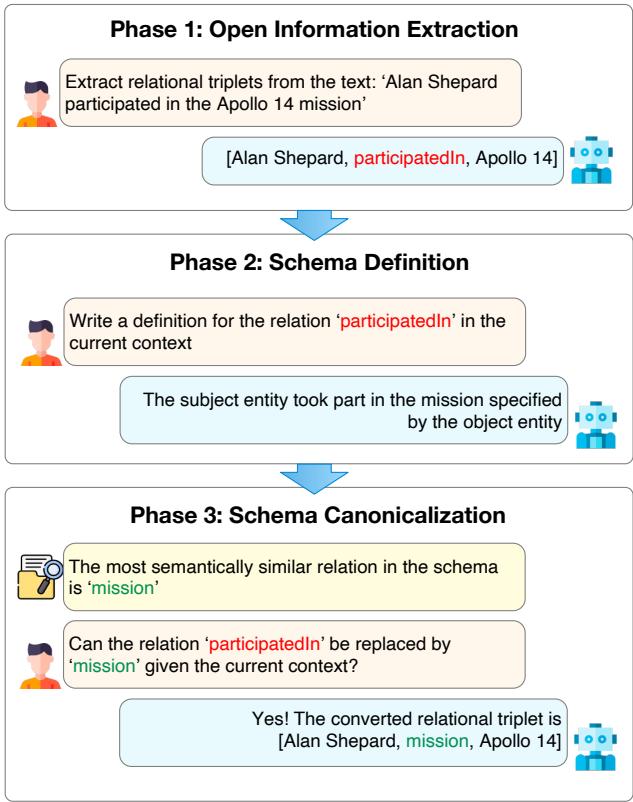
如上图 1 所示,该过程将原始文本转换为结构化的、标准化的三元组。让我们通过论文中使用的例子来演示: *“Alan Shepard participated in the Apollo 14 mission.” (阿兰·谢泼德参与了阿波罗 14 号任务。) *
第一阶段: 开放信息抽取 (Extract)
在这个阶段,目标很简单: 把信息提取出来。我们不给 LLM 增加复杂模式列表的负担。我们使用开放信息抽取 (Open Information Extraction, OIE) 。
我们要 LLM 自由地识别实体及其关系。
- 输入: “Alan Shepard participated in the Apollo 14 mission.”
- 输出:
[Alan Shepard, participatedIn, Apollo 14]
LLM 可以自由使用文本中出现的任何词汇或自然合理的词汇。虽然这捕捉到了语义,但它很杂乱。一段文本可能说 “participatedIn” (参与) ,另一段可能说 “took part in” (参加) ,第三段可能说 “was a crew member of” (是…的机组成员) 。对于计算机来说,这是三种不同的关系,这会创建一个冗余且混乱的图谱。
第二阶段: 模式定义 (Define)
这是框架中最具创造性的一步。为了修复 OIE 的混乱,我们首先需要确切理解 LLM 在提取这些三元组时的含义。
歧义是结构化的敌人。“run”这个词在 “run a company” (经营公司) 和 “run a marathon” (跑马拉松) 中的含义截然不同。
EDC 框架要求 LLM 根据句子的具体上下文, 为它刚刚提取的关系编写定义 。
- 提示词: Write a definition for the relation ‘participatedIn’ in the current context. (为当前上下文中的关系 ‘participatedIn’ 编写定义。)
- LLM 输出: “The subject entity took part in the mission specified by the object entity.” (主体实体参加了由客体实体指定的任务。)
现在,我们要的不仅仅是一个标签;我们要的是对关系的语义理解。
第三阶段: 模式规范化 (Canonicalize)
现在我们需要标准化 (规范化) 这个三元组。我们要将自由文本关系 participatedIn 映射到我们目标模式 (如果有的话) 中的标准化关系。
该系统使用向量相似度搜索 (Vector Similarity Search) 。 它获取第二阶段生成的定义,并将其与目标模式中关系的定义进行比较。
- 嵌入 (Embedding) : 定义 “The subject entity took part in the mission…” 被转换为向量嵌入。
- 搜索 (Search) : 它在目标模式中搜索语义最相似的关系。假设目标模式包含一个名为
mission的关系。 - 验证 (Verification) : 为了防止错误 (过度泛化) ,系统会向 LLM 展示候选者 (
mission) 并询问: “考虑到上下文,‘participatedIn’ 可以被 ‘mission’ 替换吗?” - 结果: 如果 LLM 回答是,三元组就会被转换。
- 最终输出:
[Alan Shepard, mission, Apollo 14]
这种方法允许系统处理包含数千种关系的模式,因为你永远不需要将完整的模式放入提示词中。你只需检索最相关的候选者进行验证。
两种运行模式
EDC 的优势之一是其灵活性。它可以在两种不同的设置下工作:
- 目标对齐 (Target Alignment) : 这就是我们上面描述的情况。你有一个巨大的现有模式 (如 Wikidata) ,并且你希望提取的数据符合该模式。
- 自规范化 (Self-Canonicalization) : 你根本没有模式。你想从零开始构建知识图谱。在这种模式下,EDC 从一个空模式开始。随着它处理文本,它会动态地构建模式。如果根据定义,一个新的关系看起来与列表中已有的关系相似,它就会合并它们。如果是新的,它就会添加进去。这产生了一个简洁的、自动生成的模式,无需人工干预。
提升性能: EDC+R (优化)
这三个阶段的过程是有效的,但有时初始抽取 (第一阶段) 会遗漏微妙的细节,因为它是“盲目”操作的,不知道哪些关系是有效的。
为了解决这个问题,作者引入了一个优化步骤,创建了 EDC+R 。
这个想法借鉴了 检索增强生成 (RAG) 。 在第一遍抽取之后,系统暂停。它使用经过训练的模式检索器 (Schema Retriever) 扫描目标模式,寻找可能与输入文本相关的关系,即使 LLM 第一次没有捕捉到它们。
模式检索器
模式检索器是一个关键组件。它不仅仅是一个标准的关键词搜索。它是一个经过微调的嵌入模型 (基于 E5-mistral-7b) ,经过训练可以理解原始句子和关系类型之间的相关性。
训练使用了对比损失函数 (InfoNCE) 。如果这听起来很复杂,别担心。其逻辑体现在下面的公式中:
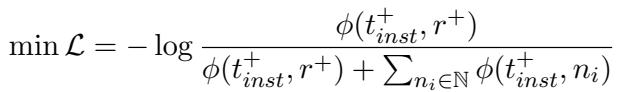
这个公式告诉我们: 我们希望最大化输入文本 (\(t_{inst}^+\)) 与正确关系 (\(r^+\)) 之间的相似度分数 (\(\phi\)) ,同时最小化与所有其他负面 (不正确) 关系 (\(n_i\)) 的相似度。
通过这种方式训练模型,检索器学会了看到像 “She leads the engineering department” 这样的句子时,预测关系 headOfDepartment 是高度相关的,即使单词 “head” 从未出现在文本中。
反馈循环
在优化阶段,系统再次运行抽取,但这次它在提示词中提供了一个“提示 (Hint) ”: “以下是你可能需要注意的一些潜在关系及其定义: [由模式检索器检索到的列表]。”
这种“引导 (bootstrapping) ”允许 LLM 捕捉最初遗漏的关系,从而显著提高召回率。
实验与结果
这真的有效吗?研究人员在三个主要的知识图谱基准测试上测试了 EDC: WebNLG、REBEL 和 Wiki-NRE 。 这些数据集在规模和复杂性上各不相同,提供了严格的测试场所。
他们将自己的框架与 REGEN 和 GenIE 等最先进的基线模型进行了比较。
目标对齐结果
主要结果总结在下图中。使用的指标是 F1 分数 (精确率和召回率的平衡) 。
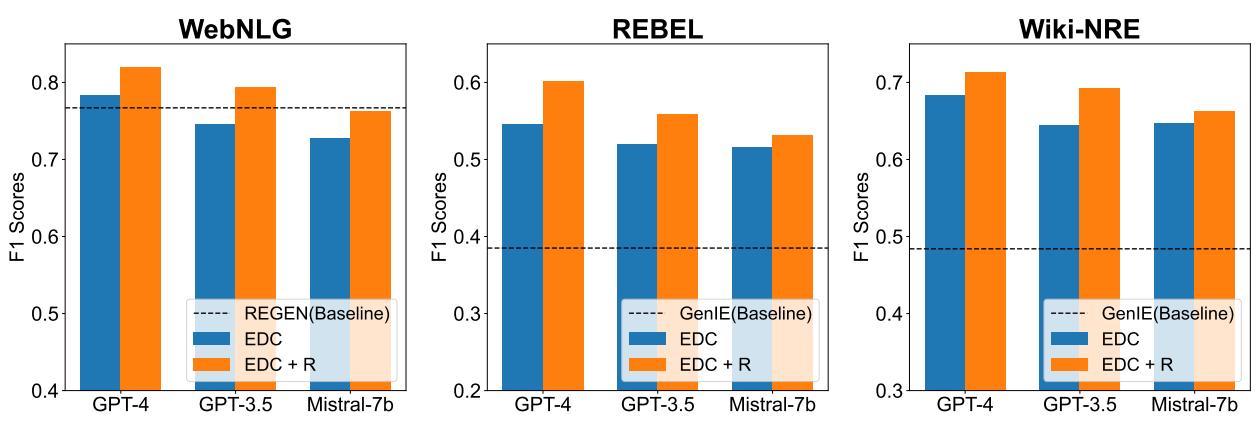
数据中的关键结论:
- EDC 击败基线: 在几乎所有指标上,EDC 框架 (蓝色柱状图) 都优于专门的、经过全面训练的基线模型 (虚线) 。
- 优化功能强大: 橙色柱状图 (EDC+R) 始终高于蓝色柱状图。添加模式检索器和优化循环提供了显著的提升。
- 模型无关性: 该框架在不同的 LLM 上都表现良好,包括 GPT-4、GPT-3.5 和开源的 Mistral-7b,尽管像 GPT-4 这样更强的模型显然表现最好。
检索器真的重要吗?
你可能会想,EDC+R 的提升是否仅仅来自于要求模型再试一次,还是检索到的提示真的起了作用。研究人员进行了一项消融实验 (Ablation study) 来找出答案。
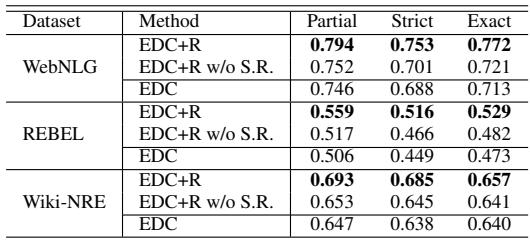
表 1 证实了检索器的价值。当研究人员运行 EDC+R 但移除检索到的模式提示 (行 “EDC+R w/o S.R.”) 时,所有数据集的性能都显著下降。这证明了经过训练的检索器所提供的语义提示对于引导 LLM 找到正确关系至关重要。
自规范化性能
如果我们没有目标模式怎么办?研究人员评估了 EDC 从零开始构建图谱的能力。他们测量了:
- 精确率 (Precision) : 提取的三元组正确吗?
- 简洁性 (Conciseness) : 模型是否创建了太多重复的关系? (关系数量通常越少越好) 。
- 冗余度 (Redundancy) : 关系之间是否截然不同?
他们将 EDC 与 CESI 进行了比较,后者是一种用于规范化开放知识图谱的标准聚类方法。
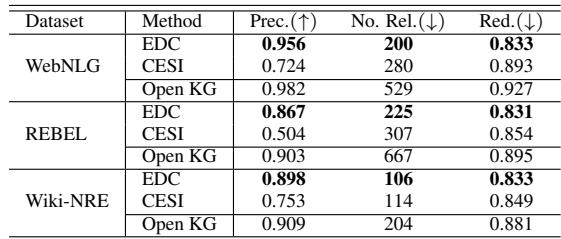
如表 2 所示,EDC 占据主导地位。它实现了更高的精确率,同时生成了一个更简洁 (关系更少) 的模式。例如,在 WebNLG 数据集上,原始的开放 KG 有 529 个关系。CESI 将其减少到 280 个,但 EDC 设法将其浓缩为 200 个冗余度更低的高质量关系。
这表明 EDC 比传统的聚类方法更能理解关系的语义,避免了将不相关的概念归为一类 (过度泛化) 或未能合并相似概念 (泛化不足) 的陷阱。
结论与未来影响
Extract-Define-Canonicalize (抽取-定义-规范化) 框架代表了自动化知识图谱构建向前迈出的重要一步。通过将抽取与模式验证解耦,它解决了困扰基于 LLM 方法的上下文窗口瓶颈问题。
这对学生和从业者意味着什么:
- 可扩展性: 你现在可以将 LLM 应用于具有大规模模式的数据集 (如医疗或法律本体) ,而无需微调专门的模型。
- 灵活性: 能够在目标对齐和自规范化之间切换,意味着一个工具既可以处理严格的数据库录入,也可以处理开放式的探索性数据分析。
- 可解释性: 因为系统为其提取的每个关系生成自然语言定义 (第二阶段) ,所以生成的图谱更加透明。你可以检查 LLM 为什么要这样分类一种关系。
随着我们迈向需要处理海量非结构化文本的系统——从为机器人构建记忆到组织科学文献——像 EDC 这样的框架将成为弥合语言的流动性与结构化数据的刚性之间鸿沟的重要工具。