](https://deep-paper.org/en/paper/2404.06809/images/cover.png)
引言
检索增强生成 (Retrieval-Augmented Generation, RAG) 已成为构建知识型 AI 系统的事实标准。通过将大型语言模型 (LLM) 连接到外部数据库,我们承诺解决幻觉和知识截止这两大难题。其逻辑很简单: 如果模型不知道答案,就让它去查。
但这个逻辑中存在一个缺陷。RAG 系统的运行基于一个危险的假设: 即检索到的一切都是真实的。
在现实世界中,LLM 检索到的“上下文”往往很混乱。它可能充满噪声 (不相关) 、过时 (旧新闻) 或被虚假信息 (假新闻) 污染。当标准的 RAG 系统检索到这些有缺陷的信息时,它会将其视为基本事实,从而导致所谓的“幻觉”,而这实际上只是模型忠实地复述了它被投喂的错误数据。
我们要如何修复这个问题?我们需要教会模型具备怀疑精神。我们需要可信度感知生成 (Credibility-aware Generation, CAG) 。
在最近一篇题为 “Not All Contexts Are Equal” (并非所有上下文都是平等的) 的论文中,研究人员提出了一个新的框架,教导 LLM 在使用信息之前明确评估其可信度。
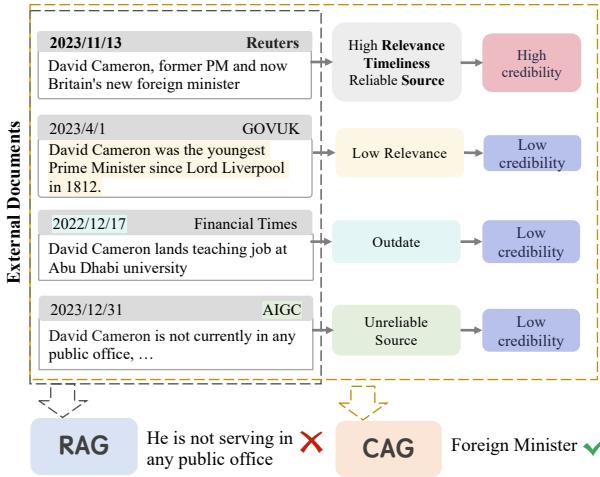
如图 图 1 所示,考虑一个关于大卫·卡梅伦 (David Cameron) 当前职位的提问。标准的 RAG 系统检索到了四份文档: 一篇旧文章说他是教师,一条 AI 生成的谣言说他没有任何公职,以及一篇最近的路透社报道说他是外交大臣。标准的 RAG 模型被这些相互冲突的噪声搞糊涂了,给出了错误的回答。然而,CAG 模型查看了元数据——时效性、来源可靠性——并正确识别出了外交大臣这一职位。
核心问题: 有缺陷的信息
在深入探讨解决方案之前,我们必须了解破坏标准 RAG 系统的三种具体类型的“有缺陷信息”:
- 噪声 (Noise) : 检索器抓取的文档与查询共享关键词,但实际上并没有回答问题。先前的研究表明,LLM 对此非常敏感,经常会被不相关的细节分散注意力。
- 过时信息 (Outdated Information) : 互联网是旧事实的坟墓。LLM 遭受“时间不敏感性”的困扰——它们很难仅凭文本区分 2015 年的事实和 2024 年的事实。
- 虚假信息 (Misinformation) : 随着 AI 生成内容和假新闻的兴起,检索数据库受到的污染日益严重。LLM 通常缺乏内部知识来针对现实情况核实检索到的文档。
人类通过评估可信度 (Credibility) 来处理这个问题。当我们阅读医疗声明时,我们会检查它是来自同行评审的期刊还是随便一个博客。CAG 的目标就是在 LLM 中复制这种认知过程。
解决方案: 可信度感知生成 (CAG)
研究人员提出了一个通用框架,使模型具备基于可信度辨别信息的能力。
在标准的 RAG 设置中,模型基于输入 \(x\) 和检索到的文档 \(D_x\) 生成答案 \(y\):
\[y = \text{LM}([x, D_{x}])\]在 CAG 框架中,输入得到了增强。每个文档 \(d_i\) 都配对了一个可信度分数 \(c_i\):
\[y = \mathrm{LM}\big([x, [c_i, d_i]_{i=1}^{ | D_x | } ]\big)\]这在数学上看起来很简单,但现有的 LLM (如 GPT-4 或 Llama-2) 天生不擅长关注这些可信度标签。如果你只是在段落旁边粘贴“可信度: 低”,模型往往会忽略它。为了解决这个问题,研究人员开发了一种新颖的数据转换框架 (Data Transformation Framework) 。
训练流程
为了教模型关注可信度,你必须在可信度至关重要的数据上对其进行训练。作者设计了一个巧妙的两步流程来创建这种训练数据,如下图所示。
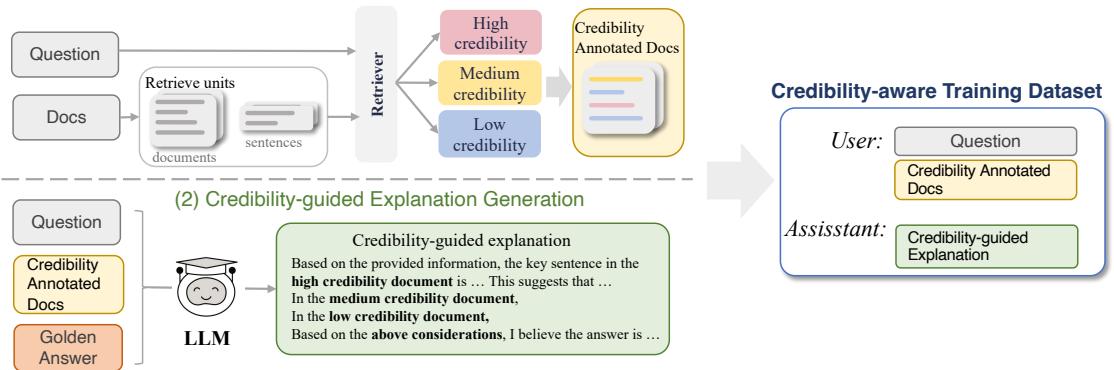
第一步: 多粒度可信度标注
首先,系统获取现有的数据集并对文档进行标注。研究人员不仅仅看一个因素;他们基于三个维度计算可信度:
- 相关性 (Relevance) : 文档与查询的匹配程度如何?
- 时效性 (Timeliness) : 文档日期与当前上下文的一致程度如何?
- 可靠性 (Reliability) : 来源是否权威?
他们将其形式化为一个计算公式,其中可信度是这些因素中的最低有效得分:
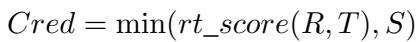
在这里,\(R\) 是相关性,\(T\) 是时间差,\(S\) 是来源可靠性。这种“短板效应”的方法确保了一个文档必须同时具备相关、及时且可靠的特征,才能被视为高可信度。
第二步: 可信度引导的解释生成
仅仅标注输入是不够的。模型需要学习如何利用这些标签进行推理。研究人员使用教师模型 (GPT-3.5) 重写了训练集中的答案。
教师模型不再只是输出“大卫·卡梅伦是外交大臣”,而是被提示生成可信度引导的解释 。 例如: “虽然文档 B 声称他是一名教师,但由于其已过时,被标记为低可信度。文档 A 被标记为高可信度,指出他是外交大臣。因此……”
这将标准的问答数据集转换成了明确提及可信度的“推理轨迹”。
第三步: 指令微调
最后,目标模型 (例如 Llama-2-7B) 在这个新数据集上进行微调。使用的损失函数是标准的语言建模损失函数,但应用于这个富含可信度的上下文中:
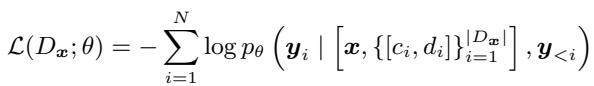
这个公式本质上是说: 优化模型参数 \(\theta\),以便在给定问题 \(\mathbf{x}\) 以及配对了可信度分数的文档集 \([c_i, d_i]\) 的情况下,最大化生成正确解释 \(\mathbf{y}\) 的概率。
实验: 可信度感知生成基准测试 (CAGB)
为了证明这种方法的有效性,作者不能依赖像 SQuAD 这样假设上下文正确的标准基准测试。他们构建了一个名为 CAGB 的新基准测试,涵盖了三个现实场景:
- 开放域问答 (Open-domain QA) : 标准问题,检索通常会引入嘈杂、干扰性的段落 (使用 HotpotQA 和 MuSiQue 等数据集) 。
- 时间敏感问答 (Time-sensitive QA) : 答案会随时间变化的问题 (例如,“英国首相是谁?”) 。
- 虚假信息污染问答 (Misinformation Polluted QA) : 一个专门注入了由其他 LLM 生成的假新闻的数据集,用于测试模型能否过滤掉谎言。
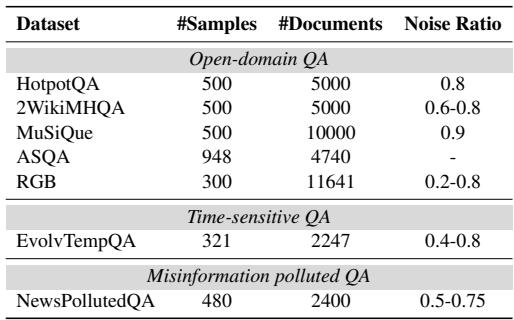
如 表 1 所示,这些数据集中的噪声比例很高,从 20% 到 90% 不等。这对于任何 RAG 系统来说都是一次残酷的考验。
关键结果
性能对比非常鲜明。研究人员测试了他们经过 CAG 训练的模型 (基于 Llama-2 和 Mistral) ,并与标准的基于检索的模型 (如 ChatGPT 和 Llama-2-70B) 以及使用“重排序 (Reranking) ” (一种按相关性对文档进行排序的常用技术) 的模型进行了比较。
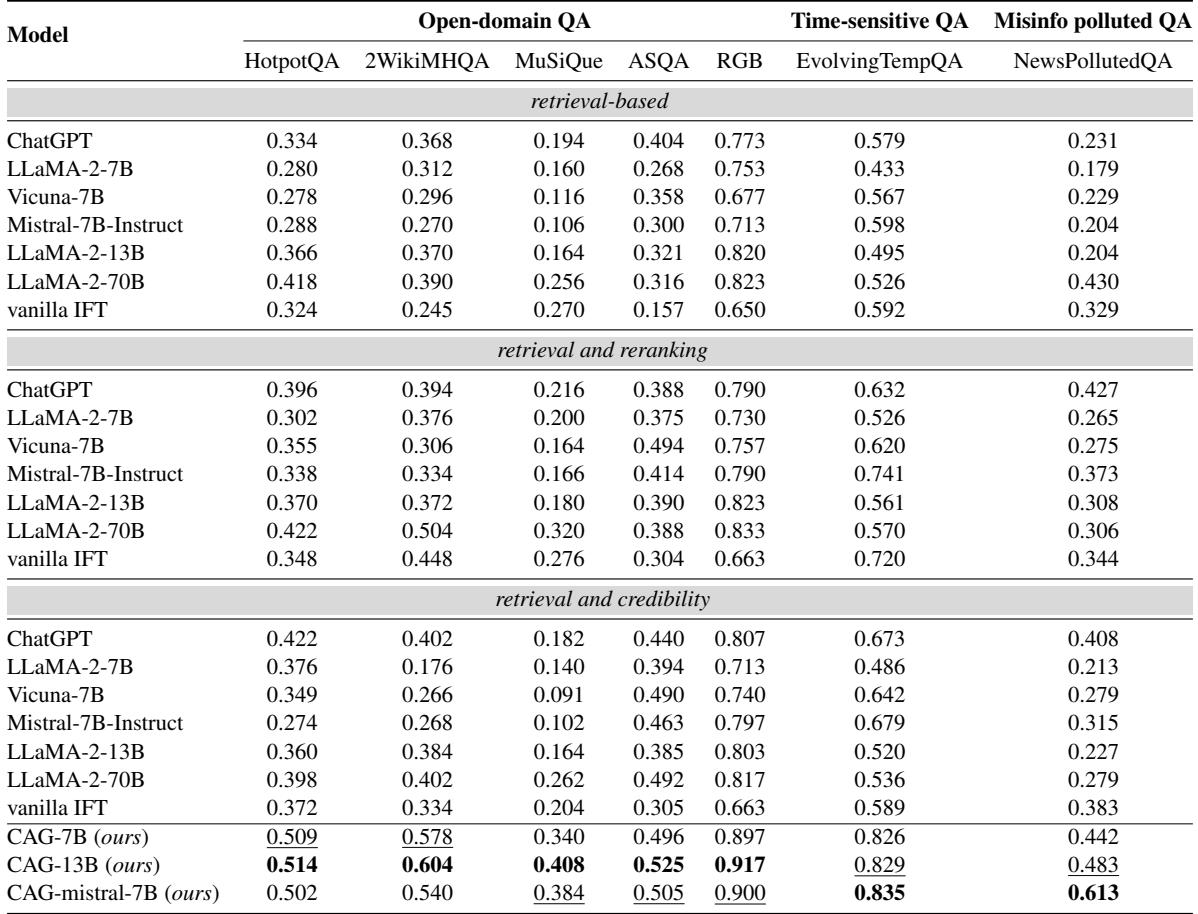
查看 表 2 , 结果令人印象深刻:
- 战胜巨头: 微调后的 CAG-7B 模型 (一个相对较小的模型) 在几乎所有数据集上都显着优于 LLaMA-2-70B (一个体量大 10 倍的模型) 。
- 击败重排序: 即使标准模型得到了重排序器 (将最好的文档放在前面) 的帮助,CAG 模型仍然获胜。例如,在
2WikiMHQA数据集上,CAG-7B 得分为 0.578 , 而带有重排序的 LLaMA-2-70B 仅得分 0.504 。 - 虚假信息: 在假新闻盛行的
NewsPollutedQA数据集上,CAG-Mistral-7B 取得了 0.613 的分数,实际上是标准 LLaMA-2-13B( 0.308 )性能的两倍。
抗噪鲁棒性
最重要的发现之一是模型在上下文中增加更多垃圾信息时的表现。通常,随着“噪声比例”的增加,模型性能会直线下降。
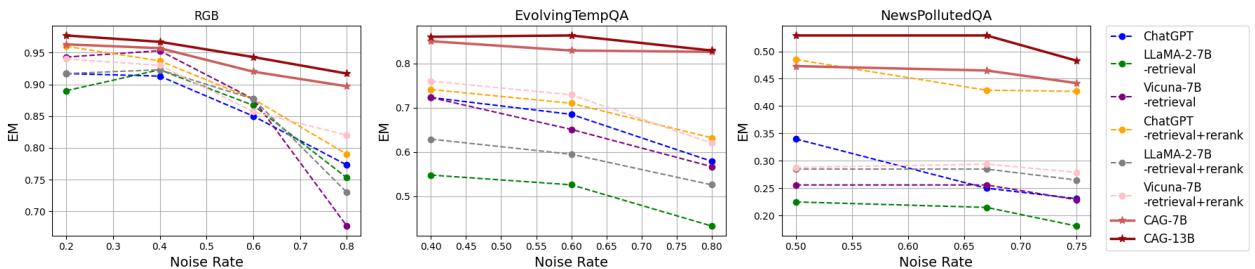
图 3 展示了这种鲁棒性。
- 趋势: 以此看标准模型的线条 (如虚线) 。随着噪声增加 (x 轴向右移动) ,它们急剧下降。
- CAG 的优势: 红色实线 (CAG 模型) 保持得非常平稳。在 NewsPollutedQA 图表 (最右侧) 上,当噪声达到 80% 时,其他模型的准确率跌破 0.3,而 CAG 模型依然稳健。这证明了模型不仅仅是“猜”得更准了;它学会了主动忽略低可信度的信息。
为什么不直接删除低可信度文档?
一个常见的反驳观点是: “如果你知道可信度分数,为什么不在发送给 LLM 之前直接过滤掉糟糕的文档呢?”
研究人员将这种“硬过滤”方法与他们的“软性”CAG 方法进行了测试。
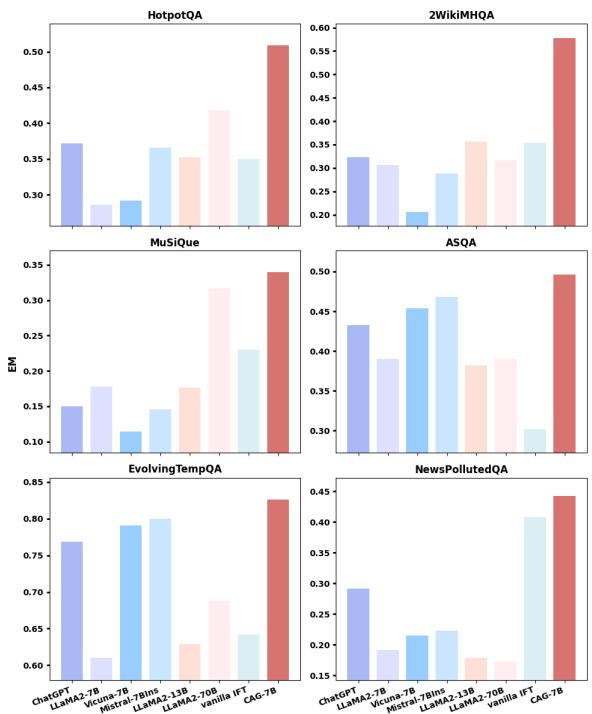
图 4 显示,简单地丢弃低可信度文档 (非红色的柱状图) 通常比 CAG 方法 (红色柱状图) 效果更差。
为什么?因为可信度评估并不完美。一个“低可信度”的文档可能仍然包含一小段有用的上下文或必要的实体定义。如果你硬过滤掉它,那些信息就永远丢失了。CAG 允许模型看到所有内容,但会动态地权衡信息的可信度。
更广泛的影响
可信度感知生成的效用不仅限于回答琐事问题。它为个性化和冲突消解开辟了新的可能性。

如 图 5 所示:
- 个性化 (左图) : 可信度可以是主观的。对于一个对“自然”感兴趣的用户来说,关于湖泊的旅游指南对该特定用户而言可能比关于城市的指南具有更高的可信度。CAG 允许模型根据用户画像优先考虑结果。
- 冲突消解 (右图) : 当两个文档截然相反 (例如,“蜜蜂最重要”与“飞蛾最重要”) 时,CAG 利用来源可靠性来解决冲突,而不是仅仅幻觉出两者的混合体。
结论
盲目信任检索的时代已经结束。随着 RAG 系统从原型走向生产环境,上下文的质量成为了瓶颈。“Not All Contexts Are Equal”这篇论文表明,我们不能仅仅依靠更好的检索器来解决这个问题。我们必须改变生成器本身。
通过教导 LLM 明确理解可信度的概念——通过标注数据和基于解释的微调——我们可以构建出不仅仅是阅读,而且会评估的 AI。其结果是一个对噪声具有弹性、对假新闻持怀疑态度、并且能够处理开放互联网混乱现实的系统。
对于学生和从业者来说,结论很明确: 元数据至关重要。 不要只给你的模型投喂文本;要投喂关于文本的上下文信息。