](https://deep-paper.org/en/paper/2404.07461/images/cover.png)
如果你曾大量使用过 ChatGPT、Gemini 或任何现代大型语言模型 (LLM) ,你很可能遇到过这种情况: 机器自信地断言某些实际上不真实的事情。它可能会编造一个从未发生过的法庭案件,将名言归因于错误的历史人物,或者生成一个无法访问的网址。
我们将这种现象称为“幻觉” (Hallucination) 。这被广泛认为是现代人工智能的阿喀琉斯之踵。
然而,宾夕法尼亚州立大学、Adobe Research 和佐治亚理工学院的研究人员最近进行的一项全面研究表明,我们最大的问题可能不仅仅是幻觉本身,而是自然语言处理 (NLP) 社区无法就该术语的实际含义达成一致。
在他们的论文 《An Audit on the Perspectives and Challenges of Hallucinations in NLP》 (NLP 幻觉的观点与挑战审计) 中,作者指出该领域正遭受缺乏共识的困扰。通过对 103 篇同行评审论文的严格审查和对 171 名从业者的调查,他们揭示了一个支离破碎的现状: 定义模糊、指标不一致,且往往忽视了“社会技术”影响——即这些错误如何影响真实的人类。
在这篇深度文章中,我们将剖析他们的发现,探索该术语的历史,并分析为什么解决“幻觉”问题需要我们首先修正我们的词汇。
第一部分: “H 词”的爆发
要理解目前的混乱局面,我们必须回顾研究的发展轨迹。“幻觉”在计算机科学中并不是一个新词,但随着面向消费者的 LLM 的发布,其在文本生成领域的应用呈爆炸式增长。
作者追踪了 SCOPUS 索引的同行评审文献中该术语的使用情况。如下图所示,近十年来,对该主题的兴趣一直相对平淡。然后,在 2022 年和 2023 年左右——与 GPT-3 和 ChatGPT 的兴起相吻合——研究产出呈爆炸式增长。
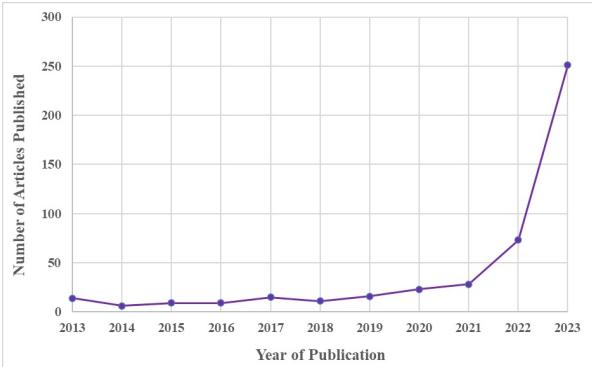
虽然这张图表代表了进步,但作者指出了一个严重的缺陷: 数量并不等同于清晰度。成千上万的研究人员涌入研究这一现象,却带来了不同的定义、方法论和测量工具。
机器幻觉简史
论文提供了该术语在计算机科学中一段迷人的词源史:
- 计算机视觉 (2000 年代) : 该术语最初用于图像处理。“幻觉人脸” (Hallucinating faces) 指的是通过推断 (或“幻想”) 原始低分辨率输入中不存在的新像素值来提高图像分辨率。在这种语境下,它是一个被期望的功能。
- RNN (2015 年) : Andrej Karpathy 在一篇关于循环神经网络 (RNN) 的博客文章中将该术语引入了 NLP。他描述了一个模型如何生成不存在的 URL,实际上是在“幻觉”数据。
- LLM 时代: 今天,它几乎专门指一种负面行为——即生成不忠实或非事实的文本。
作者指出的问题在于,虽然这个术语留存了下来,但一个统一的框架却没有。
第二部分: 审计文献
为了诊断该领域的现状,研究人员对来自 ACL 文集的 103 篇同行评审论文进行了系统审计。他们专门筛选了那些将幻觉作为主要关注点,而不仅仅是顺带提及的文章。
幻觉发生在哪里?
审计试图回答的第一个问题是: 研究人员在什么背景下研究幻觉?
分析显示,幻觉研究不是铁板一块;它分裂在不同的 NLP 任务中。如下表所示,大部分研究集中在对话式 AI (聊天机器人) ,其次是生成式摘要和数据到文本生成 。
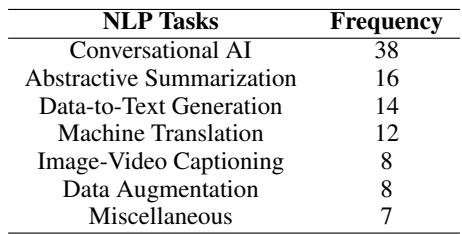
这种区分很重要,因为“幻觉”在每种语境下的含义都不同:
- 在翻译中,幻觉可能是彻底改变源文本含义的句子。
- 在摘要中,它可能是包含了原文中未提及的细节。
- 在对话中,它可能是聊天机器人编造了一个听起来合理但虚假的世界事实。
定义的缺失
这里有着论文最令人震惊的发现: 在 103 篇关于幻觉的论文中,只有 44 篇 (42.7%) 实际提供了该术语的定义。
大多数研究人员 (57.3%) 假设读者知道他们的意思,或者根本没有定义他们的术语。在那些确实定义了它的论文中,作者发现了 31 种独特的框架 。 这表明极其缺乏标准化。
通过主题分析,作者将这些不同的定义提炼为一组核心属性:
- 流畅性 (Fluency) : 文本在语法上是否正确?
- 合理性 (Plausibility) : 它听起来可信吗?
- 置信度 (Confidence) : 模型听起来是否确信?
- 内在与外在 (Intrinsic vs. Extrinsic) : 这是早期作品中提出的一个关键区别。
- *内在 (Intrinsic) : * 输出与输入相矛盾 (例如,文章说“下雨了”,摘要说“天气晴朗”) 。
- *外在 (Extrinsic) : * 输出包含输入中未找到的信息 (例如,文章说“下雨了”,摘要说“伦敦下雨了”,而实际上并未提及伦敦) 。
作者汇编了这些属性,以展示不同的论文如何混合和匹配它们来创建自己定制的定义。

测量危机
如果我们无法在定义上达成一致,我们要如何衡量这个问题?审计发现,社区在指标上也存在分歧。
研究人员将评估方法分为四类:
- 统计指标: 使用 BLEU 或 ROUGE 等公式计算词语重叠。
- 数据驱动指标: 使用其他模型 (如自然语言推理模型) 来检查矛盾。
- 人工评估: 请人对输出进行评分。
- 混合方法: 结合上述方法。
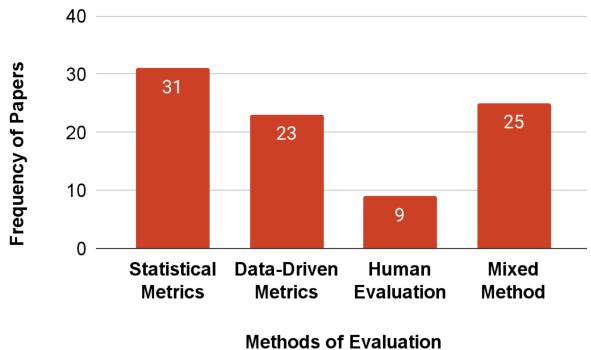
挑战: 作者指出,统计指标 (超过 35% 的作品使用) 通常不适合衡量幻觉。一个句子可能与事实有很高的词语重叠 (高 BLEU 分数) ,但仍然包含致命的事实错误。相反,人工评估则昂贵且主观。
第三部分: 从业者的视角
除了理论层面,研究人员还想了解实际构建和使用这些系统的人是如何看待“幻觉”的。他们对 171 名从业者 (博士生、教授和行业专业人士) 进行了调查。
人人都知道,没几个人懂
调查结果显示,社区对这个问题有着高度的认识。超过 57% 的受访者声称对该概念“非常”或“极其”熟悉。
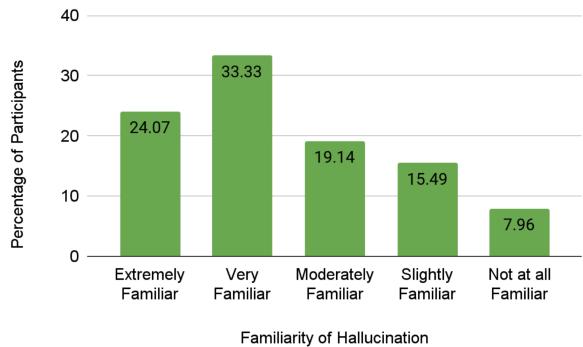
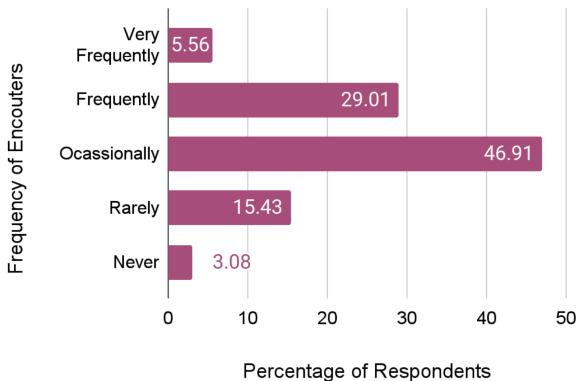
此外,从业者报告说经常遇到这些错误。如下图所示,近 30% 的人“经常”遇到幻觉,近 47% 的人“偶尔”遇到。这是 AI 工作流程中普遍存在的一部分。
“幻觉”是个错误的词吗?
调查中最有趣的定性发现之一是关于术语的争论。
虽然 92% 的受访者认为幻觉是 LLM 的一个弱点,但对这个词本身存在显著的反对意见。术语“幻觉”暗示了一种心理过程——一个感知到不存在事物的头脑。但 LLM 没有头脑;它们只有统计概率。
受访者建议了替代术语:
- Fabrication (捏造) : 暗示构建虚假数据。
- Confabulation (虚构) : 暗示在没有欺骗意图的情况下创造虚假记忆。
- Misinformation (错误信息) : 侧重于结果而不是过程。
一位受访者指出: “‘捏造’更有道理。‘幻觉’让人感觉 AI 是人类,具有可能导致幻觉的感官知觉……”
“创造力”论点
令人惊讶的是, 12% 的受访者并不认为幻觉纯粹是负面的。在创意写作或图像生成中,模型偏离现实的能力是一种特性,而不是漏洞。如果你让 LLM 写一部科幻小说,你会希望它“幻觉”出一个不存在的世界。
这种双重性——同样的行为在医疗聊天机器人中是致命的失败,但在创意写作工具中却是辉煌的功能——使得为“幻觉”定义一个通用框架变得更加困难。
第四部分: 分歧的影响
为什么要对定义的学术细节如此纠结?作者认为,缺乏清晰度会带来现实世界的后果,特别是当这些系统被部署在社会技术环境 (医疗保健、法律、教育) 中时。
论文细分了特定子领域使用的不同框架,以突出这种不一致性。

- (注: 虽然图片中的标题提到了“情感分析”,但表格内容清楚地详细说明了幻觉在对话式 AI 和机器翻译等各种 NLP 任务中是如何定义的。) *
例如:
- 对话式 AI 侧重于“流畅性”和“非事实性”。
- 机器翻译 几乎完全侧重于“外在”错误 (添加了源文中没有的内容) 。
- 图像描述 强调“物体幻觉” (在没有猫的地方看到了猫) 。
因为这些领域互不通气,一项为解决翻译中的幻觉而发明的技术可能会被从事摘要工作的研究人员完全忽略,仅仅是因为他们使用了不同的定义和指标。
信任鸿沟
调查还强调,这种不可预测性侵蚀了信任。受访者指出,如果没有强有力的监督,他们无法依赖 LLM 进行学术工作或编码。
一位受访者分享道: “我让 AI 给我生成一段代码。结果它从一个网站摘取了一些代码,又从另一个网站摘取了一些……导致生成的代码根本无法执行。”
这些工具的普及意味着“幻觉”不再仅仅是一个研究问题;它是一个用户体验危机。
结论: 标准化的呼吁
研究论文最后传达了一个明确的信息: 我们无法解决我们无法定义的问题。
作者提出了一套“以作者为中心”和“以社区为中心”的建议,以推动该领域向前发展:
- 明确的文档记录: 论文必须明确定义他们所说的“幻觉”是什么意思。不要假设读者知道。
- 标准化命名法: 社区需要决定何时使用“幻觉”,何时使用“虚构”或“捏造”。这些术语不应互换使用。
- 社会技术意识: 我们必须承认这些模型在社会世界中运行。诗歌中的幻觉是无害的;医疗诊断中的幻觉是危险的。我们的框架必须考虑到错误的语境。
- 透明度: 开发人员需要创建让用户看到模型为何可能产生幻觉的方法,从而建立更好的信任。
LLM 的迅速崛起已经超出了我们严格分类其故障的能力。这次审计是一个必要的停顿——该领域需要停下来,审视混乱的定义图景,并在冲向下一个突破之前就共同语言达成一致。
只有标准化我们对“幻觉”的理解,我们才有希望有效地缓解它。