](https://deep-paper.org/en/paper/2404.08760/images/cover.png)
引言
人工智能正迅速成为信息、建议和陪伴的无处不在的接口。随着我们将 ChatGPT 和 Llama 等大型语言模型 (LLM) 融入日常生活,一个关键问题随之而来: 这些模型到底反映了谁的价值观?
我们经常从种族、性别或政治倾向的角度讨论偏见。然而,有一个人口统计学因素经常被忽视,但其统计规模巨大: 年龄 。 到 2030 年,近 45% 的美国人口将超过 45 岁,而在全球范围内,每六个人中就有一个超过 60 岁。如果 LLM 主要使用年轻、精通技术的用户生成的互联网数据进行训练,我们就有可能构建出根本上误解或偏离很大一部分人类的系统。
本文将深入探讨论文*“The Generation Gap: Exploring Age Bias in the Value Systems of Large Language Models”*,该论文调查了流行的 LLM 是否存在“代际偏见”。研究人员将 LLM 的输出与世界价值观调查 (WVS) 的人类数据进行比对,以确定 AI 的“思维方式”是更像 Z 世代的数字原住民,还是更像婴儿潮一代。
结果揭示了一个严峻的现实: LLM 普遍表现出对年轻人群的强烈倾向。也许更令人惊讶的是,仅仅告诉 AI “像老年人一样行事”往往无法弥合这一鸿沟。
背景: 定义人类价值观
要衡量偏见,我们首先需要一个基本事实 (ground truth)。如果不严格定义不同群体的价值观,就无法衡量模型的价值观有多“像人”。
研究人员利用了世界价值观调查 (WVS) 。 这是一个完善的全球研究项目,探索人们的价值观和信仰、它们如何随时间变化,以及它们产生了什么社会和政治影响。该调查在社会价值观、宗教信仰、对腐败和技术的看法等类别上对个人进行了探讨。

如上所示,WVS 要求受访者对家庭、工作和宗教的重要性进行评分,或者衡量他们对不同群体的信任度。通过按年龄和国家对这些人类回答进行分组,研究人员为不同世代创建了“价值观指纹”。然后,他们让 LLM 回答相同的问题,看看 AI 的指纹与谁的最匹配。
核心方法
这篇论文的方法论是社会学与向量数学的迷人结合。研究人员需要将定性的调查问卷回答转化为可以进行数学比较的定量数据。
1. 稳健的提示 (Robust Prompting)
评估 LLM 的一个众所周知的困难是它们对提示词措辞的敏感性。措辞上的细微变化可能会导致截然不同的答案。为了应对这一点,作者不仅仅问每个调查问题一次。他们为每个询问设计了八种不同的提示变体 。
这些变体打乱了选项的顺序,稍微改变了上下文,或更改了输出格式要求。他们发现,虽然 LLM 可能不稳定,但对这八个提示的回答取平均值可以为模型提供一个收敛的、可靠的“观点”。
2. 数学表示
一旦研究人员收集了 LLM 的答案和人类数据 (按 18-24、25-34 直至 65+ 等年龄组分层) ,他们就需要衡量它们之间的距离。
首先,他们将特定类别 \(c\) (例如,“宗教价值观”) 的价值观表示为一个向量。如果一个类别有 \(n\) 个问题,向量如下所示:
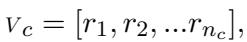
这里,\(r_i\) 代表对第 \(i\) 个问题的数值回答。
由于具有数十个维度的向量难以分析,团队使用了主成分分析 (PCA) 。 PCA 是一种降维技术,可以将信息压缩到更小的空间中,同时保留最重要的方差。他们将高维调查数据转换为 3D 坐标系:
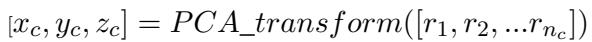
现在,每个年龄组和每个 LLM 都以这个 3D “价值观空间”中的一个点的形式存在。
3. 衡量差距
为了量化 LLM 的价值观与特定年龄组的距离,研究人员计算了 LLM 的点 (\(M\)) 与人类年龄组的点 (\(i\)) 之间的欧几里得距离 。
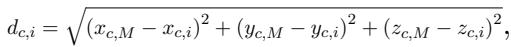
距离 (\(d\)) 越小,意味着 LLM 的价值观与该人类年龄组越相似。
最后,为了可视化 AI 更偏好哪个群体,他们使用了对齐排名 (Alignment Rank) 。 对于每个问题类别,他们计算了与所有六个年龄组的距离并进行了排名。如果 18-24 岁组排名第一 (#1),则该模型与最年轻的一代最对齐。
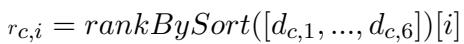
4. 趋势系数
引入的最具创新性的指标是趋势系数 (Trend Coefficient) 。 这衡量了差距的斜率。如果随着人类年龄的增长,LLM 与人类之间的差距变大,则趋势为正 (表明偏向年轻人) 。

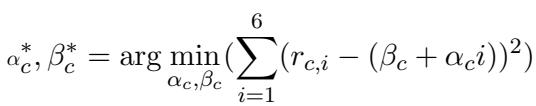
简单来说: 正的 \(\alpha\) (alpha) 意味着你年龄越大,模型离你越远。
实验与结果
该研究测试了六个主要模型: ChatGPT (GPT-3.5-turbo)、InstructGPT、Mistral-7B、Vicuna-7B、FLAN-T5 和 FLAN-UL2。
对年轻人的普遍倾向
最主要的发现可以在下面的散点图中看到。该图表显示了各种价值观类别的趋势系数 。
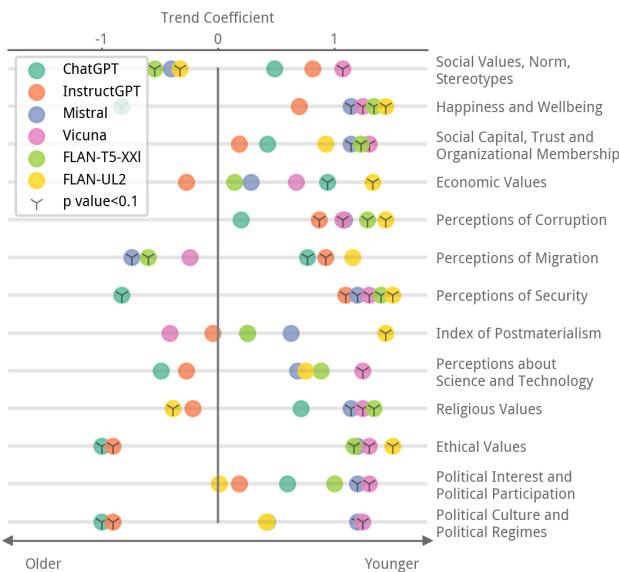
注意图表右侧 (正趋势系数) 的点群。这表明,对于社会价值观、经济价值观和宗教价值观等类别,模型与老年人群的差距正在扩大。实际上,这些模型的观点更“年轻”。
例如,美国的年轻人倾向于更加重视经济价值观,而老年人群则优先考虑宗教价值观。LLM 始终更接近年轻人群的优先事项。
可视化对齐排名
为了更清楚地看到这一点,我们可以看看“对齐排名”图表。在这些图表中,排名越低 (1) 越好——这意味着该年龄组与 LLM 最匹配。
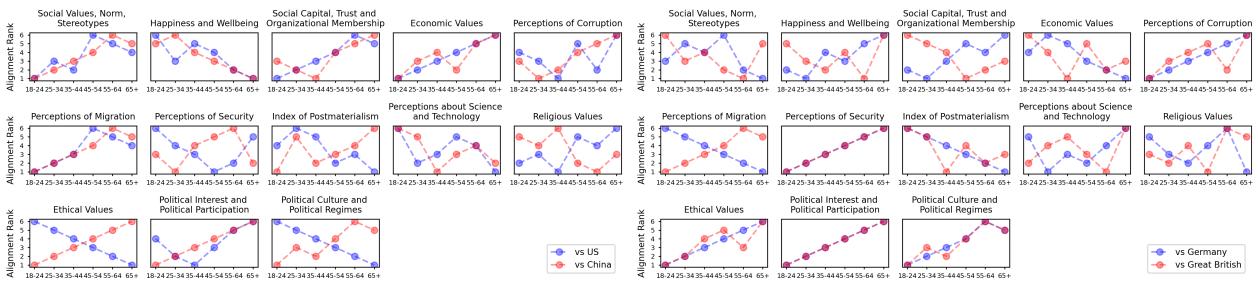
看标记为 (a) 的 ChatGPT 在美国的面板 (红圈) 。在许多类别中,红线随着年龄的增长呈上升趋势。
- 排名 1 (最接近的匹配) 通常落在 18-24 或 25-34 岁组。
- 排名 6 (最远的匹配) 通常落在 65+ 岁组。
这种单调性证实了 ChatGPT 的“价值观”并非年龄中立;随着用户年龄的增长,其对齐程度会下降。
案例研究: 广播 vs. 社交媒体
为了使这种抽象的数学具体化,研究人员强调了差异明显的具体问题。
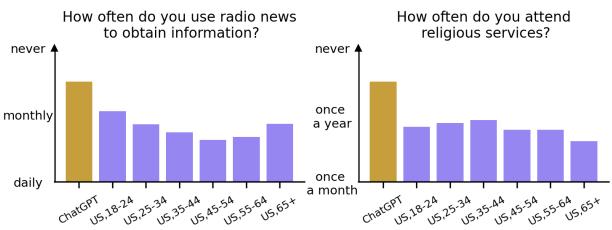
在上面的左图中,提示词询问使用广播新闻的频率。
- ChatGPT 的回答: “从不” (Never) (最低的柱状条) 。
- 人类数据: 虽然年轻人听广播较少,但老年人群仍大量使用广播。模型的默认“个性”假设了一种数字优先的生活方式,忽略了老年人群的习惯。
同样,在关于宗教活动出席率的右图中,ChatGPT 选择了“从不”,这与世俗的年轻趋势一致,而不是老年美国人群中较高的出席率。
看看社交媒体使用的人类基本事实,可以进一步说明这一点:
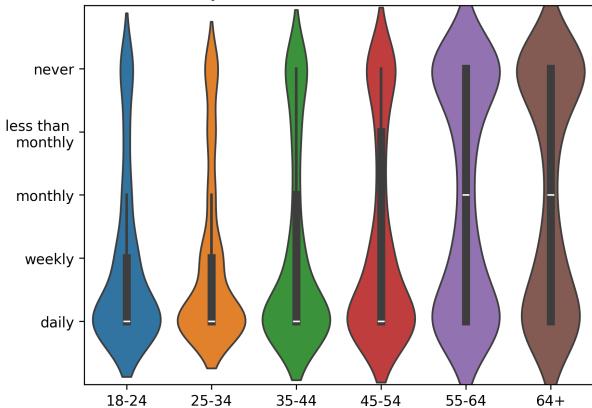
正如预期的那样,年轻人 (左侧) 每天都使用社交媒体。老年人 (右侧) 的分布要广泛得多,许多人从不使用。假设“每个人都在线”的 LLM 根本上歪曲了 65 岁以上人群的现实生活。
“角色扮演”的失败
提示工程中的一种常用技术是角色扮演 (Persona Adoption) 。 如果我们希望 LLM 与老年用户对齐,我们通常假设只需说: “假设你是一名来自美国的 65 岁老人……”
研究人员测试了这一假设。他们在提示中注入了身份信息,并重新运行了价值观对齐测试。结果违反直觉且令人担忧。
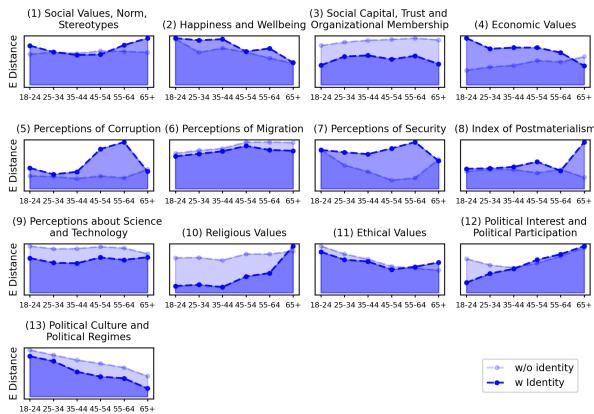
在上图中, 虚线代表标准提示, 实心蓝线代表添加了年龄身份的提示。
如果身份提示起作用,实心蓝线应该明显低于虚线,特别是对于老年组 (X 轴右侧) 。
- 现实: 在 13 个类别中的 8 个 (包括社会价值观、经济价值观和宗教价值观) 中,添加身份信息未能消除价值观差异 。 线条经常重叠或保持在高位。
模型很难“跳出”其训练偏见。它知道它应该像老年人一样行事,但其潜在的价值观权重仍然受限于它所训练的、以年轻人为主的互联网数据集。
例外: 具体的习惯
有一个领域角色扮演是有效的: 具体的、刻板的习惯。
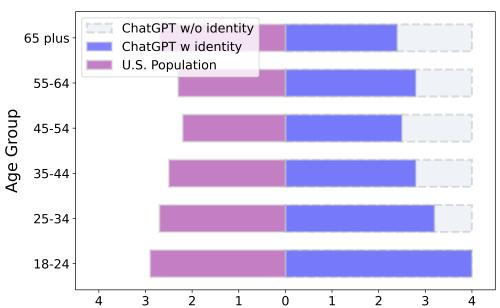
当在采用角色时被具体问及广播使用情况 (图 5) 时,ChatGPT 成功地改变了其分布。“ChatGPT w/ identity” (蓝色条) 与“美国人口” (紫色条) 的匹配度要好得多,它承认 65 岁以上的人比 18 岁的人更可能听广播。
这表明 LLM 可以模仿刻板印象或行为 (如听广播) ,但很难从根本上转变其价值体系 (如深层的伦理或宗教观点) 来匹配年龄身份。
结论与启示
这项研究凸显了 AI 中的“代沟”。LLM 不是中立的观察者;它们是反映其消费数据的镜子,而这些数据绝大多数是年轻的。
为什么这很重要?
- 信任与安全: 老年人通常对既定机构给予更高的信任。如果他们与一个看起来权威但提供的信息与其背景不符 (或产生幻觉) 的 LLM 互动,他们可能比怀疑论者的数字原住民更容易受到错误信息的影响。
- 共情缺失: 如果一个充当老年人伴侣的 LLM 在家庭结构、技术或传统方面持有根本上“年轻”的价值观,它可能无法提供富有同情心的回应。
- 疏离感: 如果 LLM 假设用户精通技术且世俗,这会给非此类用户造成摩擦,可能将老年人拒之于 AI 技术的好处之外。
前进的道路
作者反对“暴力”对齐,即我们简单地强迫 LLM 模仿老年人的平均统计数据。这会导致刻板印象 (例如,假设每个老年人都不擅长技术) 。
相反,目标应该是具有年龄意识的对齐 。 未来的工作需要开发能够理解不同世代价值观差异的模型。AI 应该能够检测用户的背景,并相应地调整其有用性和无害性约束,而不是简单地默认 25 岁互联网用户的世界观。
当我们构建智能的未来时,我们必须确保它足够明智,能够尊重过去的价值观。