](https://deep-paper.org/en/paper/2404.09682/images/cover.png)
引言: “垃圾进,垃圾出”的困境
在机器学习领域,有一句每个学生在第一学期都会学到的老话: “垃圾进,垃圾出” (Garbage In, Garbage Out) 。 无论你的神经网络架构多么复杂——无论是极其先进的 Transformer 还是庞大的大型语言模型 (LLM) ——如果喂给它的数据是有缺陷的,它就无法有效地学习。
多年来,解决这个问题的黄金标准是人工标注。如果数据集很混乱,你就雇人去阅读、标记并清理它。但随着数据集规模爆炸式增长,达到数百万个样本,依赖人工劳动变得极其昂贵且缓慢。这让研究人员陷入了两难境地: 我们要么接受噪声数据和较低的性能,要么烧光预算去清理它?
最近一篇题为 “MULTI-NEWS+: Cost-efficient Dataset Cleansing via LLM-based Data Annotation” 的论文提出了第三种选择。研究人员展示了我们可以扭转局面,不仅将大型语言模型作为训练的产物,更将其作为数据的守护者。
在这篇深度解读中,我们将探讨作者如何使用 LLM 自动“清理”流行的 Multi-News 数据集。我们将拆解他们包含思维链 (Chain-of-Thought) 提示和多数投票 (Majority Voting) 的新颖框架,并看看去除“噪声”是如何显著提升模型性能的。
网络抓取数据的问题
要理解解决方案,我们首先需要了解混乱的来源。该论文关注的是 多文档摘要 (Multi-Document Summarization) , 这是一项要求模型阅读多篇关于同一主题的文章并写出一个连贯摘要的任务。
该任务的标准基准是 Multi-News 数据集。它是通过抓取 newser.com 引用的新闻文章构建的。虽然这听起来很直接,但自动网络爬虫容易出错。当机器人抓取网页时,它并不“理解”页面;它只是抓取文本。
通常,爬虫会抓取页面上存在但在技术上与故事无关的内容。这包括:
- 标准网站免责声明 (“本副本仅供个人使用……”) 。
- 系统消息 (“请启用 Cookie……”) 。
- 完全无关的推文或侧边栏链接。
- 档案元数据 (Wayback Machine 横幅) 。
可视化噪声
作者指出,Multi-News 数据集中有很大一部分包含这种“噪声”。如果摘要模型在这个数据集上进行训练,它可能会学会产生幻觉或包含无关的细节。
看看下面的表格。这是论文中展示“噪声”实际样子的直接示例。

在 表1 中,请看 Source 1 (来源 1) 和 Source 3 (来源 3) 。 来源 1 是关于 Alexa Internet 向互联网档案馆捐赠数据的通用描述。来源 3 定义了什么是“聚焦抓取”。这两个都与讨论疟疾疫苗的 Summary (摘要) 毫无关系。只有 Source 2 (来源 2) 是真正相关的。然而,在原始数据集中,这三个都被视为模型学习的有效输入文档。
错误的根源
为什么会发生这种情况?有时是爬虫逻辑的失败。作者强调了一个有趣的技术故障,即爬虫瞄准了错误的 HTML 容器。
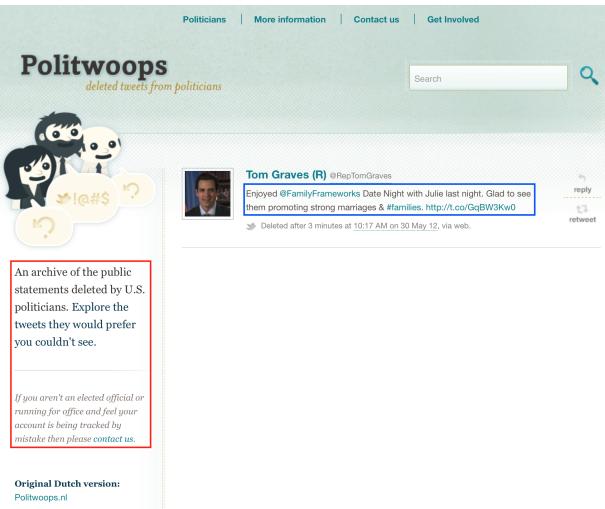
如 图3 所示,爬虫本意是抓取政治人物的推文 (蓝框) 。相反,它抓取了侧边栏文本 (红框) ,其中解释了“Politwoops”网站的功能。因为该网站的每个页面上的侧边栏都是相同的,所以数据集中最终出现了数百个包含完全相同的无关侧边栏文本的文档,而不是实际的新闻。
解决方案: 基于 LLM 的清理框架
这篇论文的核心贡献是一个无需人工介入即可修复这些问题的框架。研究人员假设现代 LLM (特别是 GPT-3.5-turbo) 拥有足够的语义理解能力,可以区分相关新闻故事和样板免责声明。
然而,你不能仅仅问 LLM“这相关吗?”并期望得到完美的结果。LLM 可能会产生幻觉、不一致,或者误解“相关性”的细微差别。为了缓解这个问题,作者设计了一个结合了 思维链 (Chain-of-Thought, CoT) 提示和 多数投票 (Majority Voting) 的稳健四步框架。
让我们拆解下图中展示的架构。
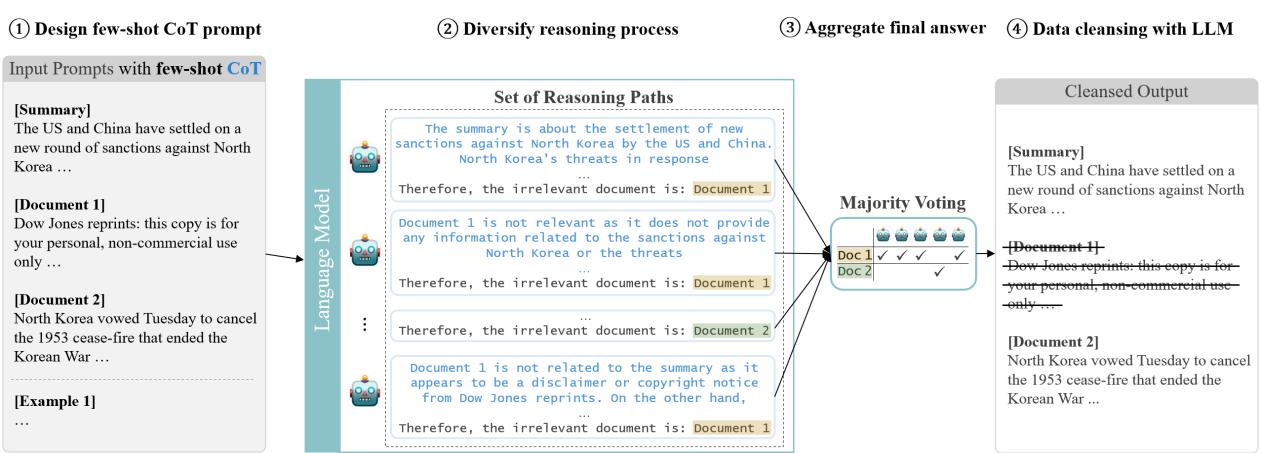
第一步: 设计少样本 CoT 提示
第一步 (图1,Step 1) 涉及提示工程。作者不仅仅提供指令;他们使用了 少样本学习 (Few-Shot Learning) 。 他们给模型提供了输入 (文档和摘要) 和期望输出 (相关性分类) 的示例。
至关重要的是,他们使用了 思维链 (Chain-of-Thought, CoT) 。 他们没有要求模型给出一个简单的“是/否”标签,而是要求模型生成一个理由。模型必须在给出最终裁决之前解释为什么一个文档是不相关的 (例如,“该文档是一个版权免责声明,不包含与摘要相关的事实”) 。这迫使模型对内容进行推理,从而显著提高了准确性。
第二步: 多样化推理过程
LLM 是概率性的。如果你问同一个模型同一个问题两次,你可能会得到不同的答案。为了将这个缺陷转化为特性,研究人员实例化了 五个不同的 LLM 智能体 (图1 中的 Step 2) 。
每个智能体独立阅读摘要和源文档。它们各自生成自己的思维链推理。一个智能体可能关注共享关键词的缺失,而另一个可能关注语义上的不匹配。
第三步: 汇总最终答案 (多数投票)
一旦五个智能体做出了决定,系统就会汇总结果 (Step 3) 。他们使用了 多数投票 机制 (自洽性) 。
- 如果智能体 1 说“相关”
- 如果智能体 2 说“不相关”
- 如果智能体 3、4 和 5 说“相关”
系统得出结论: 该文档是 相关 的 (4 对 1) 。这模仿了人工标注的工作方式,即多名标注员审查数据以确保共识,从而平滑个人错误或偏见。
第四步: 数据清理
最后,基于共识,系统创建了新的数据集 MULTI-NEWS+ 。 被大多数智能体视为不相关的文档将从输入集中被物理移除。
转变: 创建 MULTI-NEWS+
研究人员将此框架应用于整个 Multi-News 数据集,其中包含超过 56,000 组摘要和文档。
这里的成本效率非常显著。用人工标注如此规模的数据将花费数万美元并耗时数月。使用 GPT-3.5 API,总成本约为 550 美元 。
移除了什么?
清理过程非常激进。模型识别出原始数据集中有很大一部分是噪声。
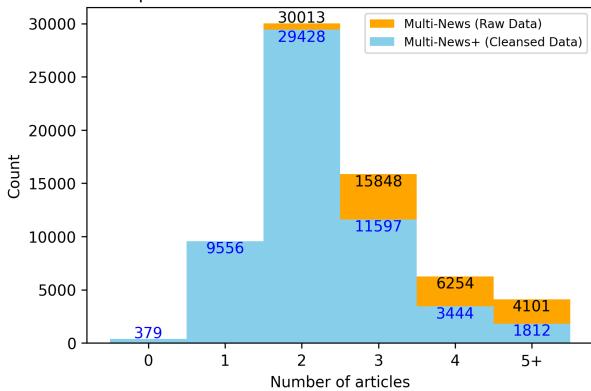
图2 显示了每个摘要的文章分布。
- 橙色条 代表原始数据。
- 蓝色条 代表清理后的 MULTI-NEWS+ 数据。
注意向左的偏移。蓝色条在较低数字 (2、3、4 篇文章) 处较高,而在较高数字 (5+ 篇文章) 处较低。这表明许多“5 篇文章”的集合实际上是“2 篇有效文章 + 3 个垃圾文件”。
也许最令人震惊的统计数据是, 379 个集合 被发现包含 零 篇相关源文章。在这些情况下,摘要是根据所提供的源文档中根本不存在的信息编写的 (可能是由于前面提到的抓取错误) 。在这些集合上训练模型会迫使它产生幻觉,这对学习是有害的。
最终数据集结构
清理工作并没有改变训练/测试/验证的划分比例,但显著减少了字数和噪声。
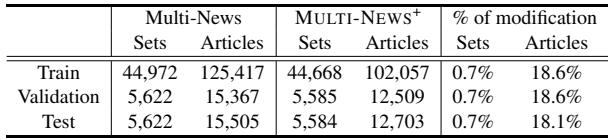
如 表3 所示,虽然 集合 (摘要+文档簇) 的数量基本保持不变,但 文章 的数量全面下降了约 18%。这意味着近 五分之一 的数据集被识别为垃圾。
实验结果: 它有效吗?
移除 18% 的数据集是一个大胆的举动。总是有风险会移除有用的信息。为了证明 MULTI-NEWS+ 的价值,作者在原始数据集和清理后的数据集上训练了两个标准的摘要模型——BART 和 T5 。
他们使用标准的 NLP 指标评估模型:
- ROUGE: 衡量生成摘要与人工参考摘要之间的单词重叠。
- BERTScore: 使用嵌入衡量语义相似度。
- BARTScore: 衡量在给定参考的情况下生成文本的可能性。
裁决
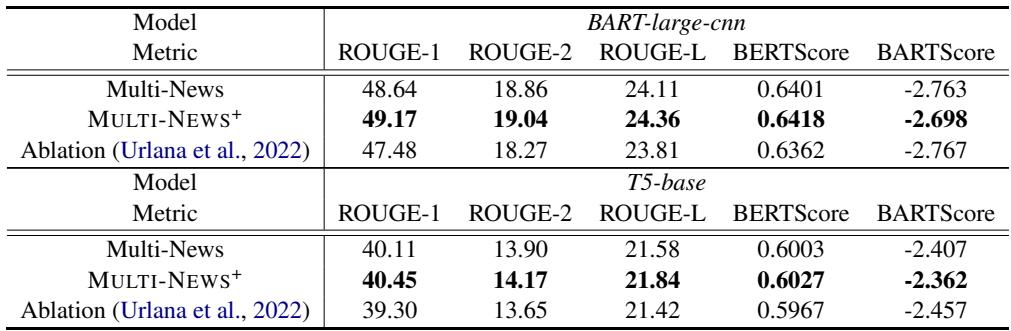
表2 展示了结果。 MULTI-NEWS+ 的行显示,与原始 Multi-News 行相比,BART 和 T5 在几乎每个指标上都有一致的改进。
虽然数值的增加 (例如 ROUGE-1 从 48.64 增加到 49.17) 对外行来说可能看起来很小,但在既定的 NLP 基准背景下,这是一致且显著的收益。这意味着模型在试图解释噪声上浪费的能力更少,而更多地专注于综合相关事实。
与基于规则的方法比较
你可能会问: “我们真的需要 LLM 来做这件事吗?我们就不能直接过滤掉短文档吗?”
作者预料到了这个问题。他们使用 Urlana 等人 (2022) 的先前方法进行了一项消融研究 (在表2中显示为 “Ablation” 行) ,该方法使用了基于规则的过滤 (例如,移除压缩率低或长度不足的文档) 。
令人惊讶的是,基于规则的清理实际上在某些情况下 损害 了性能,或者提供的收益微乎其微。这证实了 Multi-News 中的“噪声”是语义上的 (例如,一篇关于错误主题的完整文章) ,而不仅仅是结构上的 (例如,空文件) 。只有具备阅读理解能力的 LLM 才能检测到这些语义不匹配。
为了进一步证明为什么基于规则的方法失败了,请看下面的分析:
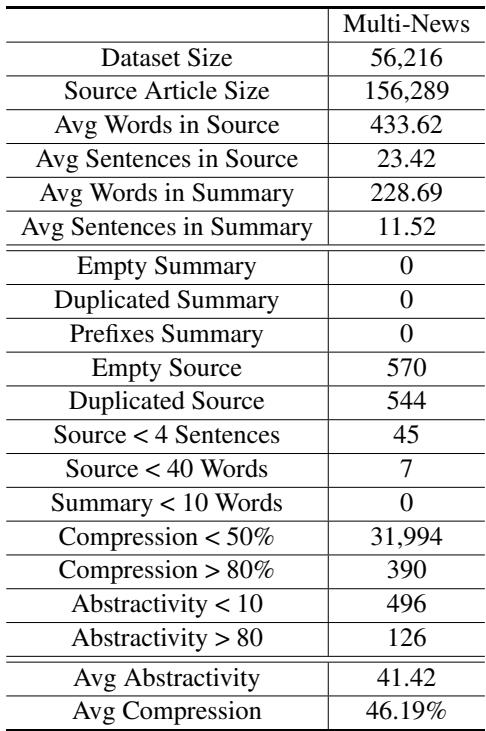
表5 显示,像“空摘要”或“重复摘要”这样的标准规则几乎没有发现任何错误。传统的启发式方法根本无法捕捉到 LLM 智能体识别出的微妙噪声。
讨论与未来启示
MULTI-NEWS+ 的成功对数据科学和自然语言处理领域具有更广泛的意义。
“AI 标注员”的兴起
这篇论文作为数据集策展民主化的概念验证。以前,高质量的数据集是拥有人工标注工厂预算的大型科技公司的特权。这种方法表明,大学实验室或小型初创公司只需花费几百美元,就可以将杂乱的、网络抓取的数据集“打磨”到专业标准。
对少样本学习的影响
作者还调查了这种噪声如何在“少样本”设置 (给模型几个例子并要求它执行任务) 中影响模型。
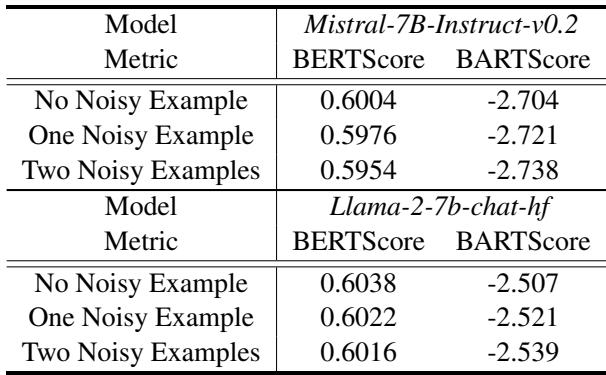
表4 显示,当用噪声示例 (“一个噪声示例”或“两个噪声示例”) 提示 LLM (如 Llama-2 或 Mistral) 时,它们的性能比展示干净示例时有所下降。这进一步证实了干净的数据不仅对 微调 (更新权重) 很重要;它对 提示 也至关重要。
未来方向
作者提出了几个令人兴奋的未来工作方向:
- 加权投票: 与其给每个智能体平等的投票权,我们可以使用一个更小、更聪明的模型 (如 GPT-4) 作为“法官”,或者赋予它的投票比小模型更大的权重。
- 预筛选: 不在每个文档上运行昂贵的 LLM,我们可以使用更便宜的启发式方法来标记“可疑”文档,只将那些发送给 LLM 进行验证。
- 主动爬取: 集成可以浏览实时网络的智能体,如果原始抓取内容糟糕,则获取 正确 的内容。
结论
MULTI-NEWS+ 论文提醒我们,在 AI 时代,数据质量依然为王。虽然构建更大模型的竞赛仍在继续,但这项研究强调,我们只需清理现有的数据即可释放显著的性能提升。
通过结合思维链提示的推理能力和多数投票的稳健性,作者为数据集卫生创建了一个可扩展、具有成本效益的管道。他们将 550 美元的投资转化为了研究社区的永久资源,为未来的摘要模型提供了一个更清洁、更可靠的基准。
对于学生和从业者来说,结论很明确: 在你花费数周时间调整模型的超参数之前,先看看你的数据。你可能会发现,改进 AI 的最佳方法是先让另一个 AI 来清理混乱。