](https://deep-paper.org/en/paper/2404.10774/images/cover.png)
引言
大型语言模型 (LLMs) 彻底改变了我们要交互信息的方式,从总结复杂的报告到回答开放式问题。然而,它们存在一个持久且众所周知的缺陷: 幻觉 (hallucination) 。 LLM 能够自信地生成听起来合理但在事实上错误的陈述。
为了缓解这一问题,业界主要采用了检索增强生成 (Retrieval-Augmented Generation, RAG) 技术。在 RAG 设置中,模型会获得“参考文档 (grounding documents)”——即可信的证据来源——并被要求仅依据这些证据生成答案。虽然这有所帮助,但并不能完全解决问题。模型仍然可能误解文档、错误地融合信息,或编造文本中未提及的细节。
这就产生了一个对自动化事实查核的关键需求。我们需要一种方法来验证: LLM 生成的输出是否确实与提供的参考文档一致?
目前,开发者面临着两难的选择。他们可以使用像 GPT-4 这样强大的模型来验证事实,这种方法准确率高,但极其昂贵且速度缓慢。或者,他们可以使用小型的专用模型 (如 NLI 模型) ,这些模型便宜,但往往无法捕捉细微的错误或进行跨句子的推理。
在这篇文章中,我们将探讨论文 “MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents” 中提出的一种新解决方案。作者介绍了一种构建小型、高效事实查核模型 (小至 7.7 亿参数) 的方法,该模型能以 400 倍更低的成本 达到 GPT-4 级别的准确率。其秘诀不在于巨大的新架构,而在于一种生成合成训练数据的巧妙方法。
问题: 基于参考文档的事实查核
在深入解决方案之前,我们必须定义要解决的具体问题。作者将该任务定义为 基于参考文档的事实查核 (fact-checking on grounding documents) 。
无论系统是在总结新闻文章、使用检索到的维基百科页面回答问题,还是根据会议记录生成对话回复,其核心原语 (primitive) 都是相同的。我们拥有:
- 一个文档 (\(D\)): 证据 (例如,检索到的片段) 。
- 一个声明 (\(c\)): 由 LLM 生成的句子。
- 一个标签: 二元分类。该声明是被文档支持 (1) 还是不支持 (0)?
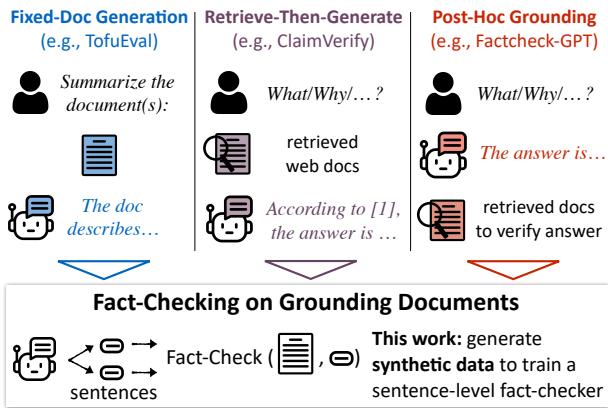
如上图 1 所示,此原语适用于各种工作流程:
- 固定文档生成: 总结特定文档。
- 检索后生成 (Retrieve-Then-Generate): 在生成之前获取证据的 RAG 系统。
- 事后依据 (Post-Hoc Grounding): 在生成之后获取证据以验证声明。
在数学上,目标是构建一个判别器 \(M\):
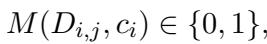
理想情况下,如果生成的回复包含多个句子,我们会针对可用文档 (\(D_{i,j}\)) 单独验证每个句子 (\(c_i\))。
为什么这很难?
检查一个句子听起来很简单,但 LLM 生成的句子通常很复杂。单个句子可能包含多个原子事实 (atomic facts)。此外,支持这些事实的证据可能分散在参考文档的不同部分。
来看看下面这个来自 TofuEval 数据集的例子。LLM 生成了一个关于航空公司对天气和劳工问题的控制权的总结。

在图 2 中,总结句包含了截然不同的事实:
- 航空公司认为天气是不可控的。
- 航空公司认为劳工问题是不可控的。
- 专家对于天气问题表示不同意。
- 专家对于劳工问题表示不同意。
为了验证这单个句子,模型必须理解“专家”(Trippler) 同意关于天气的观点,但不同意关于劳工问题的观点。这需要多跳推理 (multi-hop reasoning)——结合对话不同部分的信息来得出结论。大多数小型、专用的事实查核器在这里都会失败,因为它们通常是在简单的蕴含数据集 (如 MNLI) 上训练的,这些数据集无法反映这种复杂性。
解决方案: 合成数据生成
作者验证了在现有数据集上进行标准微调是不够的。 MiniCheck 的真正突破在于创建了一个专门的合成训练数据集,强制模型学习复杂的多句子推理。
由于为这种特定类型的高复杂度错误收集人工标注数据的成本高昂且难以扩展,研究人员使用 GPT-4 来生成合成数据。他们开发了两个不同的流程: 声明到文档 (Claim-to-Doc, C2D) 和 文档到声明 (Doc-to-Claim, D2C) 。
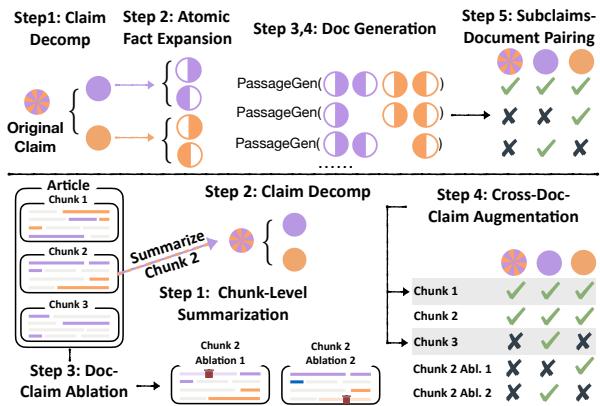
方法 1: 声明到文档 (C2D)
C2D 方法 (图 3 上部) 从一个声明开始,反向生成文档。这种方法确保模型学会识别一个声明何时 几乎 被支持但缺少关键证据。
第 1 步: 声明分解 过程始于一个人工编写的声明 \(c\)。GPT-3.5 将此声明分解为一组原子事实。
第 2 步: 原子事实扩展 这是一个关键步骤。对于每个原子事实,GPT-4 生成一对句子 (\(s_{i,1}, s_{i,2}\))。提示词强制执行一条严格规则: 只有当两个句子的信息结合在一起时,原子事实才被支持。

这迫使模型执行多句子推理。仅凭一个句子是不够的。
第 3 步: 文档生成 然后,GPT-4 编写一个连贯的文档 \(D\),其中包含这些句子对。这创建了一个正向训练样本: \((D, c, \text{Label}=1)\)。
第 4 步: 生成不支持的样本 (技巧所在) 为了创建负向样本 (即声明不受支持的情况) ,系统通过从必要的句子对中移除 一个 句子来生成新文档 \(D'\)。
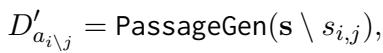
因为原子事实需要 两个 句子才能成立,移除一个使得文档不足以支持该声明。这教会模型寻找 完整的 证据。
第 5 步: 子声明匹配 最后,系统混合搭配原子事实的不同子集,以创建各种“子声明”。
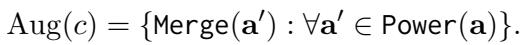
这产生了一个丰富的数据集,同一个文档可能支持某个版本的声明,但不支持另一个版本,具体取决于包含哪些原子事实。
方法 2: 文档到声明 (D2C)
虽然 C2D 非常适合教学推理,但文档是合成的。为了确保模型适应现实世界的写作风格,作者引入了 文档到声明 (D2C) 方法 (图 3 下部) 。
第 1 步: 块级摘要 该流程获取真实的人工编写文档 (例如新闻文章) 并将其拆分为块。GPT-4 为每个块生成摘要。我们假设这些摘要在事实是包含一致性的 (Label = 1) 。
第 2 步: 消融 (移除证据) 为了创建负向样本,系统迭代地从原始文档块中移除句子。

然后,系统 (使用 GPT-4 作为预言机) 检查摘要中的原子事实是否仍然受此消融文档的支持。
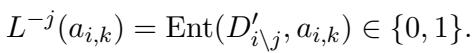
如果移除一个句子导致事实失去支持,这就创建了一个困难的负向样本: 摘要看起来与文本相关,但具体的证据消失了。
第 3 步: 跨文档增强 系统还针对同一文档的 其他 块测试该摘要。这很有挑战性,因为第 1 段的摘要可能部分被第 2 段支持,或者完全不支持。这有助于模型区分“主题相关”和“事实支持”。
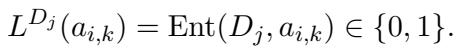
结果数据
通过结合这两种方法,作者创建了一个高质量的合成数据集。
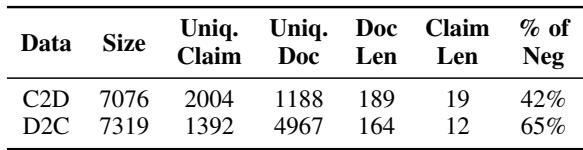
如表 1 所示,数据集是平衡的,包含大约 14,000 个样本。与大规模 NLI 数据集相比,这相对较小,但所需的推理 密度 使其非常有效。
模型: MiniCheck
作者使用这种合成数据微调了三种不同的基础模型:
- MiniCheck-RBTA: RoBERTa-Large (3.55 亿参数)。
- MiniCheck-DBTA: DeBERTa-v3-Large (4.35 亿参数)。
- MiniCheck-FT5: Flan-T5-Large (7.7 亿参数)。
他们还将合成数据与 ANLI 数据集的一小部分 (2.1 万个样本) 结合使用,ANLI 是自然语言推理的标准基准。
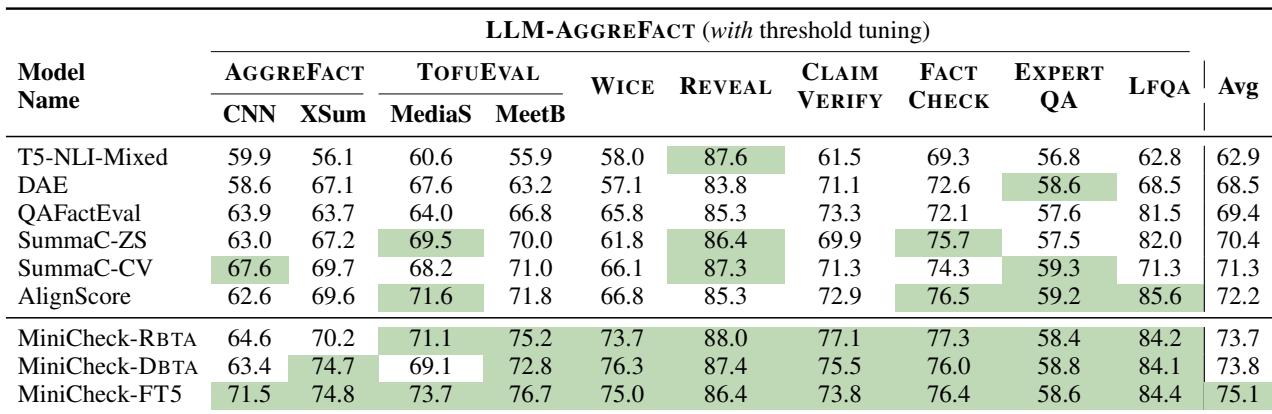
LLM-AGGREFACT: 统一基准测试
为了严格测试他们的模型,作者需要一个涵盖 LLM 多种使用方式的基准。他们引入了 LLM-AGGREFACT , 这是 10 个现有数据集的统一集合。
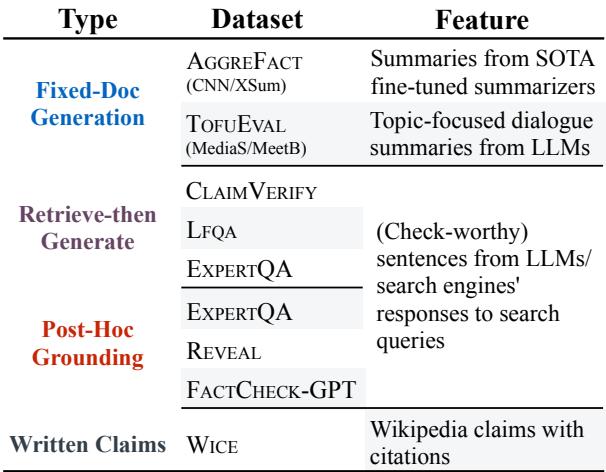
该基准测试非常全面。它包括:
- 摘要检查 (CNN/DM, XSum)。
- 对话摘要 (TofuEval)。
- RAG 正确性 (ClaimVerify, ExpertQA)。
- 幻觉检测 (Reveal, FactCheck-GPT)。
这种多样性确保了在 LLM-AGGREFACT 上表现良好的模型不仅仅是记住了某种特定的提示词模式,而是真正学会了验证事实。
实验与结果
结果令人瞩目。作者将 MiniCheck 与最先进的专用模型 (如 AlignScore 和 SummaC) 以及大型 LLM (GPT-4, Claude 3, Gemini) 进行了比较。
准确率
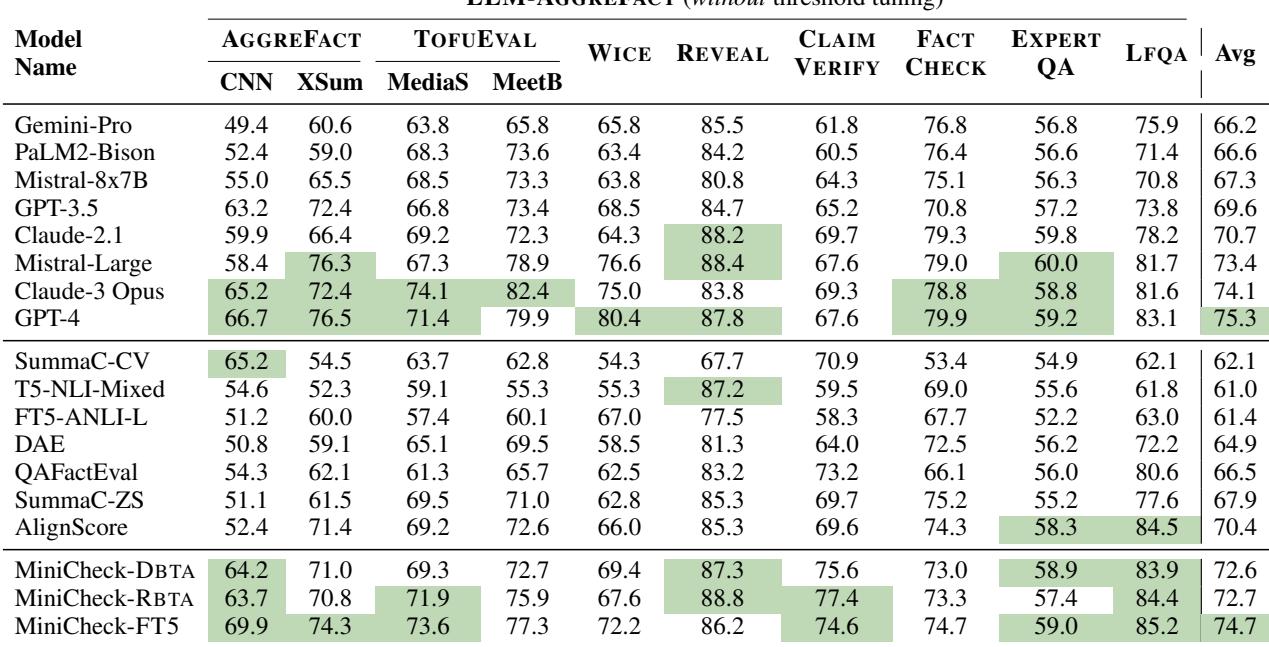
表 2 突出了主要发现:
- MiniCheck-FT5 (74.7%) 匹敌 GPT-4 (75.3%)。 差异在统计上可以忽略不计。
- MiniCheck 优于其他专用模型。 它比 AlignScore (之前的专用模型 SOTA) 高出超过 4 个百分点。
- 模型大小并不代表一切。 注意
T5-NLI-Mixed(一个 110 亿参数的模型) 的得分 (61.0%) 显著低于 MiniCheck-FT5 (7.7 亿参数) 。这证明了合成训练数据的 质量 比原始参数数量更重要。
成本因素
MiniCheck 最具说服力的理由是经济性。
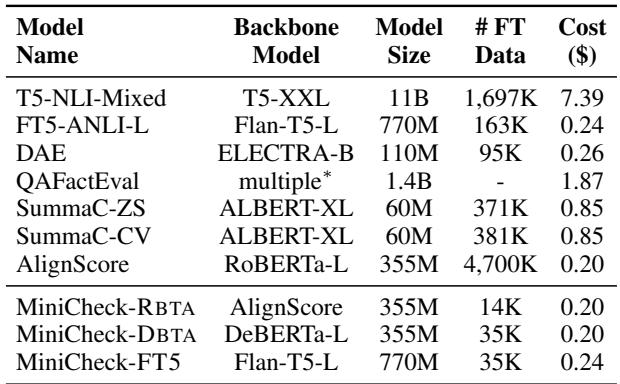
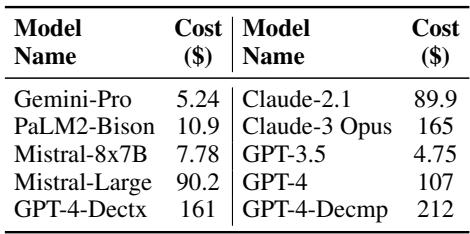
对比表 3 和表 4 揭示了一个巨大的差距:
- GPT-4 成本: 约 107.00 美元来评估该基准。
- MiniCheck-FT5 成本: 约 0.24 美元来评估该基准。
这意味着 成本降低了 400 倍 。 对于一家部署每天处理数千个查询的 RAG 系统的公司来说,从基于 GPT-4 的验证转向 MiniCheck-FT5 可能意味着每年节省数十万美元。
合成数据是否具有泛化能力?
对合成数据的一个合理担忧是过拟合——模型可能非常擅长检查合成声明,但在真实声明上失败。
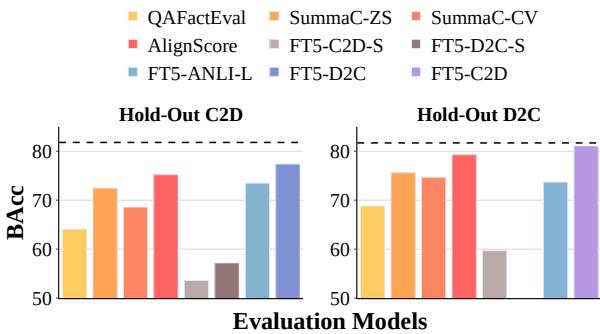
图 5 显示了在留出测试集上的结果。至关重要的是,在 C2D 数据上训练的模型在 D2C 数据上表现出色,反之亦然。这种“交叉授粉”的成功表明,模型学会了事实验证的底层技能,而不仅仅是记住了合成模式。
一项消融研究进一步证实了这一点的重要性:
如表 6 所示,如果没有新的合成数据,模型的性能从约 75% 崩溃到约 60%,证明仅靠 ANLI 数据不足以完成此任务。
重新思考事实查核流程
该论文还挑战了该领域的一些常见假设,特别是关于 声明分解 (Claim Decomposition) 和 去语境化 (Decontextualization) 的假设。
分解是必要的吗?
先前的研究表明,要检查一个复杂的句子,必须先将其分解为原子事实 (分解) ,然后分别检查每一个事实。
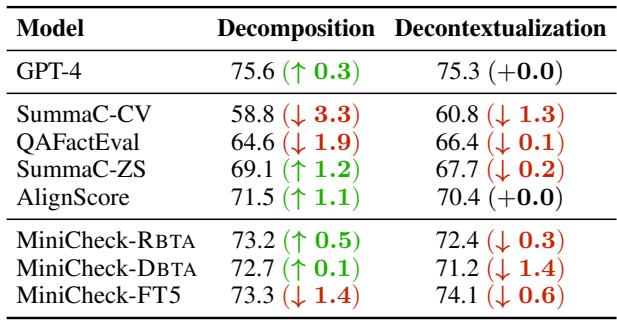
表 5 揭示了一个令人惊讶的结果: 对于有能力的模型来说,分解基本上是不必要的。
- GPT-4 几乎没有获得任何收益 (+0.3%)。
- MiniCheck-FT5 在分解后表现实际上略差 (-1.4%)。
分解的详细结果如下所示:

这对于效率来说是个好消息。分解需要额外的 LLM 调用来拆分句子,这增加了延迟和成本。MiniCheck 证明,在复杂的合成数据 (本身包含原子事实推理) 上训练的模型可以在一次传递中验证整个句子。
去语境化又如何呢?
去语境化涉及重写句子使其独立存在 (例如,将“他说”替换为“CEO 说”) 。研究发现,虽然这在理论上很有用,但在该基准测试中并没有产生显著的性能提升,这可能是因为 RAG 系统中的检索步骤通常保留了足够的上下文。
结论
“MiniCheck” 论文在使安全 AI 变得易于获取和负担得起方面迈出了重要一步。通过巧妙地逆向工程事实查核过程以生成高质量的合成训练数据,作者创建了一个可以与现存最强大的 LLM 媲美,但又足够小、可以在普通硬件上运行的系统。
主要收获:
- 合成数据是超级武器: 当缺乏真实的标注数据时,创建具有挑战性的合成数据 (通过 C2D 和 D2C 方法) 可以训练出高效的模型。
- 效率不打折: MiniCheck-FT5 在基于参考文档的事实查核方面与 GPT-4 的准确率相当,但成本低 400 倍。
- 简单即胜利: 如果底层模型经过训练能够原生处理多事实推理,那么涉及声明分解的复杂流程可能是不必要的。
对于学生和研究人员来说,这项工作凸显了我们并不总是需要更大的模型来解决难题——有时,我们只需要更好的数据。 LLM-AGGREFACT 基准的发布也为衡量对抗幻觉的进展提供了一个有价值的标准。