](https://deep-paper.org/en/paper/2404.12096/images/cover.png)
在自然语言处理 (NLP) 快速发展的世界中,文本嵌入模型是幕后的无名英雄。它们将文本转化为向量表示——即捕捉语义的一串数字——作为信息检索 (IR) 和检索增强生成 (RAG) 的引擎。
然而,这个引擎中存在一个顽固的瓶颈: 上下文窗口 。
大多数流行的嵌入模型 (如基于 BERT 的架构) 都局限于较短的上下文窗口,通常是 512 个 token。在现实世界的应用中——比如搜索法律合同、总结冗长的会议记录或索引整个维基百科条目——512 个 token 根本不够用。当输入超过这个限制时,文本通常会被截断,从而导致大量信息的丢失。
显而易见的解决方案是从头开始训练具有更长上下文窗口的新模型。但这极其昂贵。例如,训练支持 8k 上下文的 BGE-M3 模型需要 96 张 A100 GPU。
这就引出了一篇引人注目的研究论文: “LONGEMBED: Extending Embedding Models for Long Context Retrieval” (LONGEMBED: 扩展嵌入模型以用于长上下文检索) 。 作者提出了一条更高效的路径。与其从头开始训练,我们能否利用现有的高性能模型,并“拉伸”它们的容量以处理长上下文 (最高可达 32,768 个 token) ?
在这篇深度文章中,我们将探讨他们如何构建一个新的基准来衡量这种能力,用于在不进行昂贵重训的情况下扩展上下文窗口的数学技巧,以及为什么旋转位置嵌入 (RoPE) 可能是长上下文 NLP 的未来。
当前评估方式的问题
在解决上下文限制之前,我们需要先对其进行衡量。你可能认为我们已经有了检索基准,比如 BEIR 或 LoCo。然而,作者指出,在评估长上下文能力时,这些现有的基准存在致命缺陷。
主要问题有两个:
- 文档长度受限: 像 BEIR 这样的基准测试中,许多数据集的平均文档长度不到 300 个单词。如果文档很短,你就无法测试长上下文能力。
- 信息分布偏差: 在许多“长”文档数据集中,查询的答案通常位于文档的最开头。
第二点至关重要。如果一个嵌入模型只看前 512 个 token 而忽略其余部分,但答案恰好就在这前 512 个 token 中,模型就会得到高分。这造成了一种理解长上下文的假象,而实际上模型并没有真正做到。
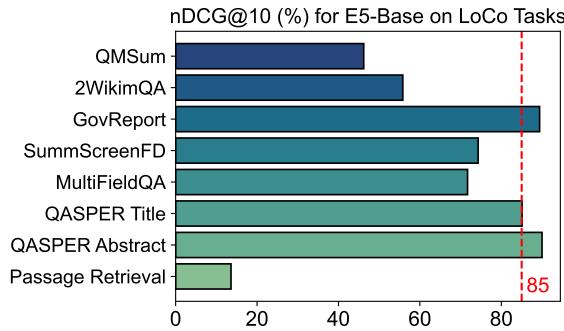
如上文图 2 所示,严格支持仅 512 个 token 的 E5_Base 模型在 GovReport 等任务上达到了超过 85% 的准确率。这表明这些任务中的“关键”信息聚集在开头,使它们无法真正代表长上下文评估。
介绍 LONGEMBED
为了解决这个问题,研究人员推出了 LONGEMBED , 这是一个旨在确保模型实际上阅读了整篇文本的稳健基准。它包含两类任务: 合成任务和现实世界任务。
1. 合成任务: 精度测试
合成任务允许研究人员精确控制答案隐藏的位置 (“针”) 以及文档的长度 (“大海”) 。
- 大海捞针 (Needle-in-a-Haystack) : 模型必须检索包含随机事实 (例如,“旧金山最棒的事情是吃三明治”) 的文档,该事实被插入到一篇长文中。
- 个性化密钥检索 (Personalized Passkey Retrieval) : 模型必须从干扰文本中找到包含特定人物特定密钥的文档。

如图 3 所示,这些任务迫使模型对特定的“针”进行编码,无论它出现在第 100 个位置还是第 30,000 个位置。
2. 现实世界任务
为了确保实际适用性,LONGEMBED 包含了四个答案分散在全文中的真实数据集:
- NarrativeQA: 关于长篇故事 (文学/电影) 的问答。
- 2WikiMultihopQA: 需要跨越维基百科文章的不同部分进行推理。
- QMSum: 会议总结。
- SummScreenFD: 剧本总结。
通过结合这些任务,作者创建了一个测试场,模型无法通过只阅读引言来“作弊”。
核心方法: 拉伸窗口
这就引出了一篇引人注目的研究论文: 上下文窗口扩展 。 这涉及获取一个预训练模型 (在短文本上训练) ,并应用策略使其处理长文本。
作者根据处理位置的方式将嵌入模型分为两类:
- APE (绝对位置嵌入) : 像 BERT 或原始 E5 这样的模型,它们为位置 1、位置 2 等直到 512 分配特定的学习向量。
- RoPE (旋转位置嵌入) : 像 LLaMA 或 E5-Mistral 这样的现代模型,它们通过旋转向量空间来编码位置。
策略 1: 分而治之法
最简单的方法是 并行上下文窗口 (PCW) 。
- 工作原理: 将长文档 (例如 4000 token) 切成适合模型大小的块 (例如 512 token) 。
- 过程: 将每个块独立输入模型以获取嵌入。然后,对所有块的嵌入取平均值来表示整个文档。
- 优缺点: 这很容易实现,但它破坏了块之间的语义联系。模型无法“关注”跨越块边界的 token。
策略 2: 位置重组 (针对 APE 模型)
如果我们想一次性处理整个序列,我们需要处理位置 ID。APE 模型只知道位置 ID 0 到 511。当我们遇到第 512 个 token 时会发生什么?
作者探索了重用现有位置嵌入的方法:
- 分组位置 (Grouped Positions, GP) : 放慢位置计数器的速度。Token 0 和 1 都获得位置 ID 0。Token 2 和 3 获得位置 ID 1。这将 512 个 ID 拉伸以覆盖 1024 个 token。
- 循环位置 (Recurrent Positions, RP) : 循环使用 ID。Token 512 获得 ID 0。Token 513 获得 ID 1。
- 线性插值 (Linear Interpolation, PI) : 不使用整数,而是将位置映射为小数。如果你想将上下文加倍,就将位置索引除以 2。Token 0 保持为 0。Token 1 变为 0.5。Token 1024 变为 512。由于模型没有“0.5”的嵌入,你可以对 0 和 1 的嵌入进行数学插值。
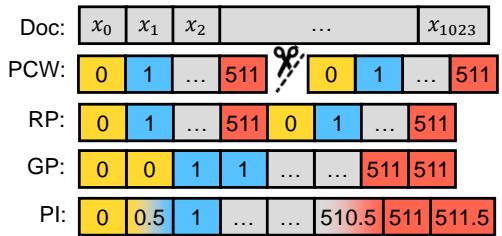
图 4 (左) 将其可视化。注意 GP 如何在位置 ID 中创建“阶梯”,而 RP 创建“锯齿状”模式。
进一步微调: 作者发现,对于 APE 模型,仅仅操纵 ID 是不够的。通过微调模型,他们取得了最好的结果。他们冻结原始模型参数,仅训练位置嵌入 (见图 4,右) 。这使得模型能够学习如何处理这些新的、拉伸的位置,而不会忘记其原始训练 (“灾难性遗忘”) 。
策略 3: RoPE 扩展 (现代方式)
旋转位置嵌入 (RoPE) 在数学上对于扩展更加优雅,因为它通过旋转矩阵编码相对位置。
RoPE 函数根据向量的位置 \(m\) 对其进行旋转:
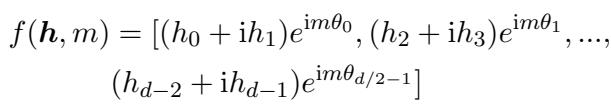
查询 (Query) 和键 (Key) 之间的注意力分数取决于它们之间的距离 \((m-n)\):
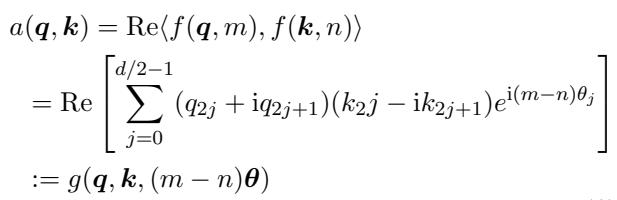
由于 RoPE 依赖于旋转频率 (\(\theta\)),我们可以通过操纵这些频率来扩展上下文:
- NTK 感知插值 (NTK-Aware Interpolation) : 基于神经正切核 (Neural Tangent Kernel) 理论。NTK 不是线性压缩所有位置 (这会损害模型区分相邻 token 的能力) ,而是较少地缩放高频,更多地缩放低频。这在保留局部细节的同时允许更长的全局上下文。
- SelfExtend (SE): 这种方法对直接邻居使用正常上下文窗口 (以保持高局部准确性) ,对远距离 token 使用分组窗口。它无需训练,且效果出奇地好。
实验与结果
作者在 LONGEMBED 基准上对这些策略进行了广泛测试。
1. 扩展有效吗?
是的,效果显著。
如下图的热力图 (面板 b) 所示,随着输入长度的增加,标准模型完全失效 (白色/黄色单元格) 。然而,扩展后的模型 (如 E5-Mistral + NTK) 即使在高达 32k token 的情况下也能保持高准确率 (绿色单元格) 。

看图 1 中的面板 (c)。蓝线 (E5-Mistral) 随着上下文增长而下降。但灰色虚线 (E5-Mistral + NTK) 保持在高位。这证明了无需训练的策略 (NTK) 可以释放 RoPE 模型的巨大上下文能力。
2. APE vs. RoPE: 巅峰对决
该论文最重要的贡献之一是对 APE 和 RoPE 架构进行了直接比较。
为了公平起见,作者从头开始训练了一个新模型 E5-RoPE_Base,使用与原始 E5_Base (APE) 完全相同的数据和流程,只是将位置嵌入换成了 RoPE。
发现: RoPE 在长度外推方面明显更好。
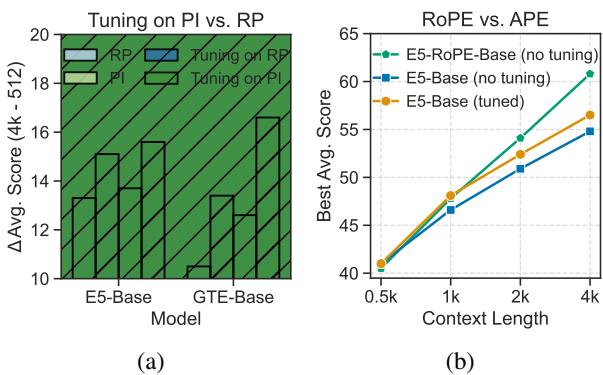
在图 6 (b) 中,对比蓝色柱状图 (原始 E5) 和灰色柱状图 (E5-RoPE) 。无需任何额外工作,RoPE 版本就能更好地处理更长的上下文。当进行扩展时,RoPE 模型的性能保持得比 APE 模型好得多。
3. 微调还是不微调?
对于基于 APE 的模型 (如标准 E5 或 GTE) ,“即插即用”的方法 (如仅更改位置 ID) 效果还可以,但微调能产生最佳结果。
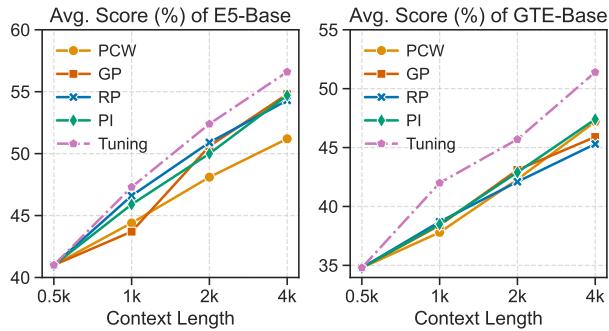
图 5 显示,“Tuning (微调) ”线 (紫色/粉色) 始终高于其他线,无论是对于 E5 还是 GTE。这表明,如果你不得不使用旧的基于 BERT 的模型,对位置嵌入进行少量的微调是值得投入算力的。
结论与启示
“LONGEMBED” 论文为 NLP 社区提供了一份蓝图。我们并不总是需要庞大的计算集群来训练用于长上下文任务的新模型。
给学生和开发者的关键要点:
- 不要轻信短文本基准: 如果你正在为长文档构建 RAG 系统,请确保在像 LONGEMBED 这样的基准上评估你的嵌入模型,而不仅仅是标准的检索任务。
- RoPE 是王道: 如果你要为新模型选择骨干网络,请使用旋转位置嵌入。它们为后续的上下文扩展提供了卓越的灵活性。
- 免费升级: 如果你使用的是基于 RoPE 的模型 (如 E5-Mistral) ,你很可能可以通过使用 NTK 感知插值或 SelfExtend,在不训练的情况下将其上下文窗口扩展到 32k token。
- 复活旧模型: 即使是旧的 APE 模型,通过对位置嵌入进行高效微调,也可以升级以处理 4k+ token。
这项研究有效地大众化了长上下文检索,允许开发者仅通过应用正确的数学变换,就能使用现有的开源模型处理书籍、手册和代码库。