](https://deep-paper.org/en/paper/2404.12545/images/cover.png)
引言
深度学习模型,尤其是像 BERT、RoBERTa 和 Llama 这样的大型语言模型 (LLM) ,在大量的自然语言处理 (NLP) 任务中取得了超越人类的表现。然而,尽管它们表现出色,却存在一个重大缺陷: 它们是“黑盒”。我们输入一个句子,模型吐出一个预测,但内部的推理过程在很大程度上仍然是不透明的。
对于致力于构建安全且值得信赖的 AI 的学生和研究人员来说,这种不透明性是一个问题。如果我们不知道一个模型为什么做出某个决定,我们要如何信任它?
传统上,该领域依赖于特征归因 (feature attribution) 方法。这些技术会高亮显示输入句子中对预测贡献最大的特定单词。例如,在一篇影评中,模型可能会高亮“terrible (糟糕) ”一词来解释负面情感分类。虽然这种方法有帮助,但往往过于表面化。单词是离散的符号,但它们的含义是流动的。单词“bank”在“河岸 (river bank) ”和“金融机构 (bank deposit) ”的语境中含义完全不同。仅仅高亮“bank”并不能告诉我们模型使用了哪种含义。
在这篇文章中,我们将探讨一篇提出更深层次可解释性的研究论文: 潜在概念归因 (Latent Concept Attribution,简称 LACOAT) 。 LACOAT 不仅仅是指向单词,而是使用模型学到的“潜在概念 (Latent Concepts) ”来解释预测。我们将详细拆解这种方法是如何工作的,它如何揭示模型推理的内部演变,以及为什么它标志着 AI 可解释性的重大飞跃。
简单单词归因的问题
要理解为什么我们需要潜在概念,我们首先必须了解孤立地看待单词的局限性。在深度学习模型运行的高维向量空间中,一个单词并不是作为一个静态点存在的。它的表示会根据上下文而变化。
以单词“trump”为例。根据句子的不同,这个词可能代表:
- 一个动词 (胜过,出王牌) 。
- 一个特定的命名实体 (著名的特朗普大厦) 。
- 一位政治人物 (前美国总统) 。
- 一个纸牌游戏术语 (王牌) 。
如果模型预测一个句子是“政治性的”,并且它高亮了单词“trump”,我们可能会假设它理解了政治语境。但是,如果模型实际上是将“trump”与纸牌游戏联系起来,却因为巧合得到了正确的答案呢?标准的归因方法无法区分这些细微差别。
LACOAT背后的研究人员认为,我们需要观察潜在空间 (Latent Space) 。 在训练过程中,模型学会了将相似的语境分组。通过利用这些分组,我们可以确切地看到模型正在使用单词的哪个“侧面 (facet) ”。

如上图 1 所示,单词“trump”可以根据其用法被可视化为属于不同的聚类 (或概念) 。LACOAT 利用这一点来提供语义丰富的解释,而不仅仅是识别关键词。
方法论: LACOAT 是如何工作的
LACOAT 框架是一个旨在为局部预测生成人类友好型解释的管道。它由四个独特的模块组成。让我们一步步来了解它们。
1. ConceptDiscoverer (概念发现器) : 绘制地图
在解释具体的测试案例之前,我们需要了解模型知识的“地图”。这是利用训练数据完成的。
ConceptDiscoverer 模块接收一个预训练模型和训练数据集。它将训练数据中的每个句子输入模型,并提取每一层中每个单词的上下文表示 (向量) 。
因为像 BERT 这样的模型是上下文相关的,所以“river bank”中“bank”的向量在数学上将不同于“bank deposit”中的“bank”。然后,该模块对这些向量应用凝聚层次聚类 (Agglomerative Hierarchical Clustering) 。
- 直觉: 在空间中靠得很近的向量具有相似的含义或语法角色。
- 结果: 算法找到了向量的聚类。一个聚类可能包含各种正面形容词 (“good”、“great”、“superb”) 。另一个可能包含与地理相关的专有名词。这些聚类就是潜在概念 。
2. PredictionAttributor (预测归因器) : 寻找火花
现在我们有了概念的“地图” (来自训练数据) ,我们来看一个我们想要解释的具体测试实例 。
PredictionAttributor 识别输入句子中哪些单词对模型的预测最负责。研究人员使用了一种称为积分梯度 (Integrated Gradients, IG) 的方法。IG 为每个 token 计算一个归因分数。该模块选择占总归因量 50% 的顶部 token。这些就是“显著”单词——即决定该特定预测的关键因素。
3. ConceptMapper (概念映射器) : 连接输入与概念
这是 LACOAT 的核心创新。我们要解释的测试句子中有显著单词,并且我们在模型内部有它的向量表示。
ConceptMapper 获取这个向量,并找出它与训练数据中的哪个潜在概念 (聚类) 相一致。它本质上是在问: “当前这个单词与哪一组训练示例最相似?”
通过将测试单词映射到训练聚类,我们解锁了语义语境。如果模型高亮了测试句子中的“trump”,而 ConceptMapper 将其映射到一个充满“Queen (王后) ”、“Jack (杰克) ”和“Spades (黑桃) ”的聚类,我们就知道模型将其视为纸牌游戏术语。如果它映射到一个包含“Obama”、“Bush”和“Clinton”的聚类,模型就是将其视为政治实体。
4. PlausiFyer (合理化生成器) : 翻译成自然语言
一堆单词组成的聚类对数据科学家来说信息量很大,但读起来可能很乱。一个潜在概念可能看起来像是由 50 个语义相关的术语组成的词云。
为了使其用户友好, PlausiFyer 模块使用了一个大型语言模型 (本文中具体使用的是 ChatGPT) 。它将输入句子和识别出的潜在概念中的单词列表提供给 LLM,并给出一个简单的提示: “你是否发现高亮显示的单词……与以下单词列表之间有任何共同的语义……关系?”
结果是一个总结这种关系的自然语言解释。
可视化意义的演变
深度学习模型最迷人的方面之一是,随着数据在网络层中逐层深入,它们的理解是如何演变的。LACOAT 允许我们可视化这种层级结构。
在 Transformer 模型的早期层中,表示通常基于句法或简单的词汇定义。随着我们要到更深层,表示变得更加抽象,捕捉到了情感和复杂的语义。

在图 2 中,我们看到对包含单词“worst (最差) ”的负面评论的分析:
- 第 0 层 (输入) : 该概念包括“best (最好) ”、“biggest (最大) ”和“greatest (最伟大) ”等词。这看起来可能令人困惑,但在语言学上,这些都是最高级形容词。模型根据它们的语法角色将它们分组。
- 第 6 层 (中间) : 概念转向负面副词和形容词,如“terrible (糟糕) ”和“badly (严重地) ”。模型开始理解情感。
- 第 12 层 (输出) : 概念紧紧围绕着极端的负面情绪: “awful (可怕) ”、“atrocious (恶劣) ”、“rotten (腐烂/糟糕) ”。
这证实了由最后一层生成的解释通常与理解最终预测最相关。
这是另一个展示类似进展的例子:
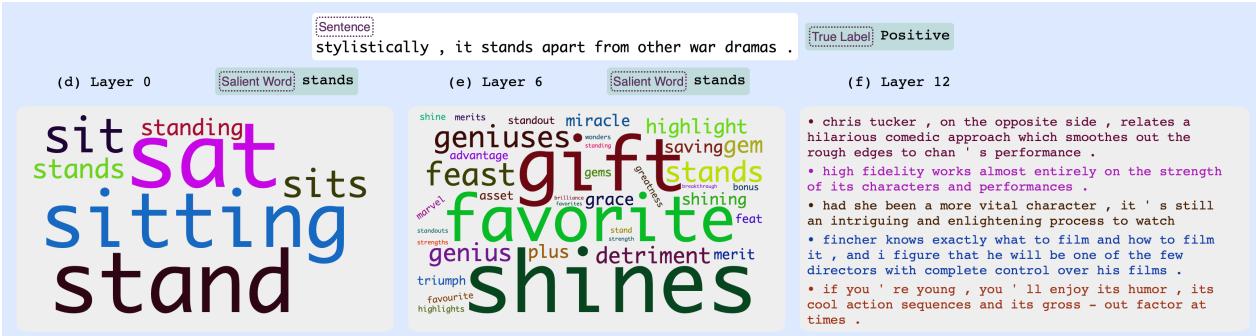
在图 5 中,模型分析了单词“stands”。在第 0 层,它将其与像“sit (坐) ”这样的物理动作动词分组。到了第 12 层,它将该概念与正面影评术语 (“gift (天赋/礼物) ”、“shines (闪耀) ”、“merit (优点) ”) 联系起来,表明模型在此时将“stands”解释为一种隐喻性的、正面的含义。
分析预测: 正确、错误与困惑
当我们使用 LACOAT 来诊断模型行为时,它的光芒才真正显现。让我们看看正确和错误预测的例子。
正确的预测
在标准情况下,LACOAT 证实模型的推理是正确的。

在图 3 (左侧) 中,模型正确地将“slightly (稍微) ”识别为副词 (RB) 。解释显示潜在概念包含其他副词,如“easily (容易地) ”和“carefully (仔细地) ”,PlausiFyer 总结说它们都描述了程度或频率。这建立了信任: 模型知道副词是什么。
诊断错误
当模型出错时会发生什么?
在图 3 (右侧) 中,模型错误地将“media (媒体) ”标记为复数名词 (NNS) ,而它应该是单数。潜在概念揭示了原因: 该聚类包含像“ratings (收视率) ”、“pilots (飞行员/试播集) ”和“figures (数字/人物) ”这样的词——全都是复数名词。模型在这个语境中根本误解了该词的语法数,而解释让这个错误显而易见。
我们还可以使用 LACOAT 来检测地面实况 (Gold Label,即标准答案) 本身是否错误,从而为模型平反。

在图 7 中,数据集将该评论标记为“正面 (Positive) ”。然而,模型预测为“负面 (Negative) ”。仅看标签的人类可能会认为模型失败了。但看看解释: 潜在概念 (聚类 237) 包含批评情节不一致和对话的句子。模型实际上是对的;创建数据集的人类标注者可能犯了个错。LACOAT 提供了发现这些数据集错误所需的证据。
比较不同的模型
不同的模型“思考”方式不同,即使是在相同的数据上训练。LACOAT 允许我们比较它们的内部逻辑。
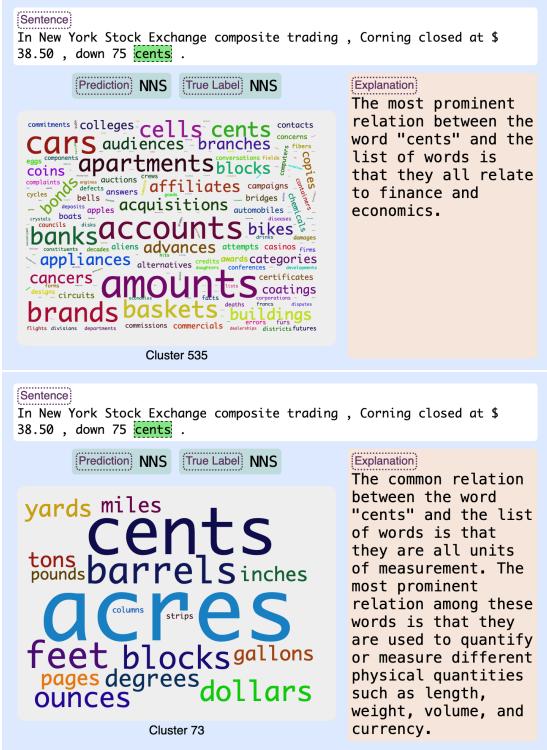
图 4 展示了 XLMR 和 RoBERTa 如何解释单词“cents (分) ”。
- XLMR (上) : 将“cents”与金融术语联系起来,如“markets (市场) ”、“stocks (股票) ”和“dividends (股息) ”。它将其视为一个金融概念。
- RoBERTa (下) : 将“cents”与“yards (码) ”、“miles (英里) ”和“gallons (加仑) ”联系起来。它将其视为一个计量单位。
两个模型可能都预测出了正确的词性标签,但它们的内部推理路径是截然不同的。
实验验证: 它是忠实的吗?
漂亮的可视化很棒,但潜在概念真的在驱动预测吗?这种属性被称为忠实度 (faithfulness) 。
为了测试这一点,研究人员进行了消融实验 (ablation study) 。 他们在推理过程中取用识别出的潜在概念的向量,并将其从模型的表示中减去。如果这个概念真的很重要,移除它应该会破坏预测。
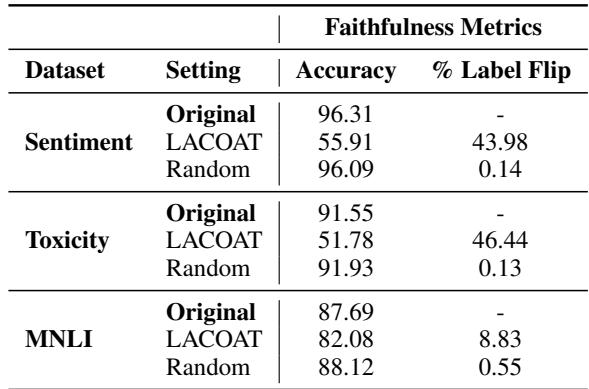
表 4 显示了结果。
- 原始准确率: 情感分析约为 96%。
- 随机消融: 减去一个随机向量几乎没有任何影响 (准确率保持在 96% 左右) 。
- LACOAT 消融: 减去 LACOAT 识别出的特定潜在概念后,准确率骤降至 55.91% 。
这种巨大的下降证实了 LACOAT 识别的概念不仅仅是巧合;它们是模型决策过程的实际数学驱动因素。
毒性检测与偏见
最后,让我们看一个关键的应用: 毒性检测。模型经常仅仅因为包含与宗教或身份相关的“触发词”就将非毒性评论标记为有毒。

在图 12 中,用户写道: “Welcom wikipedia! I kiss you!!! Allahu Akbar!”这显然是无毒的。然而,模型预测为有毒 (Toxic) 。 为什么?LACOAT 解释显示,显著概念 (聚类 281) 充满了与仇恨言论、激进化和敏感政治话题相关的术语。模型学到了宗教短语 (如“Allahu Akbar”) 与毒性之间的偏见相关性。LACOAT 立即暴露了这种偏见,让开发者看到模型并不是在阅读句子结构,而是对特定的身份术语做出了反应。
结论
从“黑盒”到“白盒 (glass box) ” AI 的转变对于该领域的未来至关重要。LACOAT 代表了从简单的单词高亮向概念可解释性迈出的重要一步。
通过将输入映射到训练期间学到的潜在空间 , 我们获得了:
- 语境: 我们知道模型正在使用单词的哪个定义。
- 调试: 我们可以看到模型是否因为错误的原因而做出了正确的判断,或者数据集本身是否有缺陷。
- 偏见检测: 我们可以发现模型死记硬背的有害相关性。
对于学习 NLP 的学生来说,这篇论文强调了一个重要的教训: 不要只看输出。 内部表示——模型的“思想”——掌握着理解、改进和信任这些强大系统的关键。