](https://deep-paper.org/en/paper/2404.14215/images/cover.png)
引言
我们生活在一个信息过载的时代。每天,我们都受到大量非结构化文本的轰炸——新闻报道、财经实录和现场活动解说。对于人类来说,将这就好比“一堵文字墙”压缩成结构化、易于阅读的表格是一项艰巨的任务。我们直觉上知道表格通常是消化复杂数据的最佳方式,但创建一个表格不仅仅需要阅读,更需要推理。
在自然语言处理 (NLP) 领域, 文本到表格生成 (Text-to-Table generation) 是一项旨在自动化这一过程的任务。随着大语言模型 (LLMs) 的兴起,你可能会认为这个问题已经解决了。难道我们不能直接把文档粘贴到 GPT-4 中并要求生成一个表格吗?
事实证明,并没有那么简单。大多数现有模型非常擅长“抽取”——在句子中找到一个数字并将其复制到单元格中。但它们在“整合”方面却差得多——阅读长篇叙述,追踪事件,进行计算 (如计数) ,然后填充表格。
在这篇文章中,我们将深入探讨一篇名为 “Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction” 的论文。研究人员指出了目前我们对此类模型进行基准测试的一个重大缺陷,并提出了一种名为 \(T^3\) (Text-Tuple-Table) 的新颖流程,该流程模仿人类的推理过程,从复杂的叙述中生成高度准确的表格。
问题所在: 当复制粘贴不再奏效
要理解为什么文本到表格生成很难,我们需要先看看以前的研究是如何处理这个问题的。历史上,像 ROTOWIRE (篮球赛事摘要) 这样的数据集一直是标准。在这些数据集中,任务往往仅仅是格式转换。
例如,如果一句话说,“雷霆队以 112-88 击败了太阳队,” 模型只需要提取“112”和“88”并将它们放在正确的列中。这是一个一对一的映射。
然而,现实世界的数据很少如此干净。试想一下足球比赛的现场解说。文本可能会在二十个段落中描述五次不同的“射门”,使用诸如“头球”、“抽射”或“尝试”等不同的同义词。要生成“总射门数”的摘要表格行,模型不能只是提取一个数字;它必须 推理 (infer) 哪些事件算作射门,并将它们 整合 (integrate) (求和) 。

如 图 1 所示,上方的示例 (以前的数据集) 和下方的示例 (推理与整合) 之间存在巨大的复杂性跨度。下方的示例要求模型追踪事件 (\(P2\) 射门,\(P5\) 进球) 并将它们聚合成最终的统计数据 (2 次射门,1 个进球) 。
以前的模型在这里往往会失败,因为它们依赖于“虚假相关性”——基于表面模式猜测输出,而不是真正的理解。
LIVESUM: 推理能力的基准测试
为了解决缺乏挑战性数据集的问题,作者推出了 LIVESUM , 这是一个由现实世界的足球比赛解说构建的基准数据集。
LIVESUM 的目标是测试 LLM 纯粹通过现场文字解说生成比赛统计表 (进球、射门、犯规、红黄牌等) 的能力。
构建数据集
创建一个需要推理的高质量数据集并不容易。研究人员遵循了一个严格的流程:
- 原始直播文本: 他们从 BBC Sports 抓取了现场解说。
- 改写 (Paraphrasing) : 利用 ChatGPT,他们改写了文本,以确保多样性并匹配人类解说员的风格。
- 匿名化: 为了防止模型利用预训练知识 (例如,知道梅西为阿根廷效力) ,他们将特定名称替换为通用标识符,如“Player1”或“Home Team”。这迫使模型 仅 依赖提供的文本。
- 标注与整合: 人类标注员对事件进行标记,然后将其聚合成地面真值 (ground-truth) 表格。
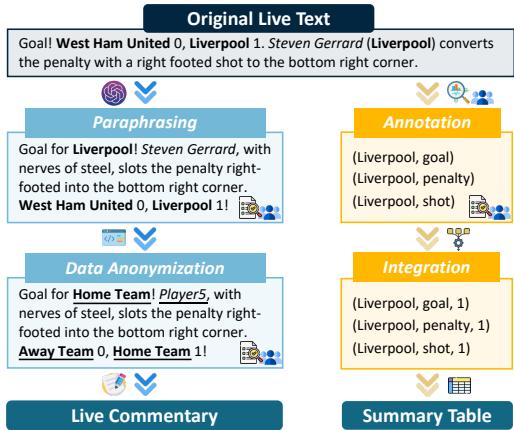
图 2 可视化了这一流程。请注意句子 “Steven Gerrard… converts the penalty” 是如何被转换并最终提炼成数据点如 (Liverpool, goal, 1) 的。
语言挑战
LIVESUM 的一个关键特征是所用语言的多样性。一次“射门 (Shot) ”并不总是被称为“shot”。它可能是“header (头球) ”、“miss (射偏) ”、“save (扑救) ”或“goal (进球) ”。模型必须理解所有这些不同的语言表达都映射到同一个统计类别。
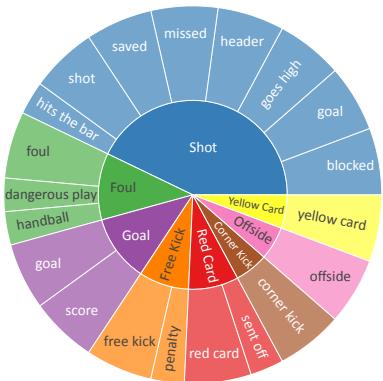
图 3 展示了这一难点。内圈显示的是表头 (目标) ,而外圈显示的是模型实际看到的嘈杂、多样的文本。
核心方法: \(T^3\) (Text-Tuple-Table)
研究人员发现,即使是强大的 LLM (如 GPT-4) ,在标准的“零样本 (Zero-Shot) ”设置下 (即直接要求模型制作表格) 在 LIVESUM 上也表现挣扎。模型经常会出现数字幻觉或在长文本中计数错误。
为了解决这个问题,作者提出了 \(T^3\) 流程 。 该方法将复杂的任务分解为三个可管理的步骤,模仿人类解决问题的方式: 抽取、整合和制表 。
第一步: 文本到元组 (抽取阶段)
模型不是立即要求生成最终表格,而是首先被要求以元组的形式从文本中提取原子事实: (主体, 客体, 动词/事件)。
例如,从文本 “Player 5 kicked the ball over the bar,” 中,模型提取出:
(Player 5, Home Team, Shot)
这一步将非结构化文本简化为结构化的事件列表,剥离了叙述性的废话,同时保留了核心数据。
第二步: 信息整合 (推理阶段)
这是该流程中最具创新性的部分。现在我们有了一个原始元组列表,我们需要聚合它们 (例如,计算主队有多少次射门) 。
作者提出了两种方法:
- 直接执行: 要求 LLM 在脑海中进行计数。
- 代码生成: 要求 LLM 编写一个 Python 脚本来计算元组。
论文主张使用 代码生成 。 LLM 在长序列上的算术和计数方面均表现不佳,但它们非常擅长编写代码。通过生成 Python 脚本来处理元组,“推理”工作被转移到了确定性的程序上,确保了计算步骤的 100% 准确性。
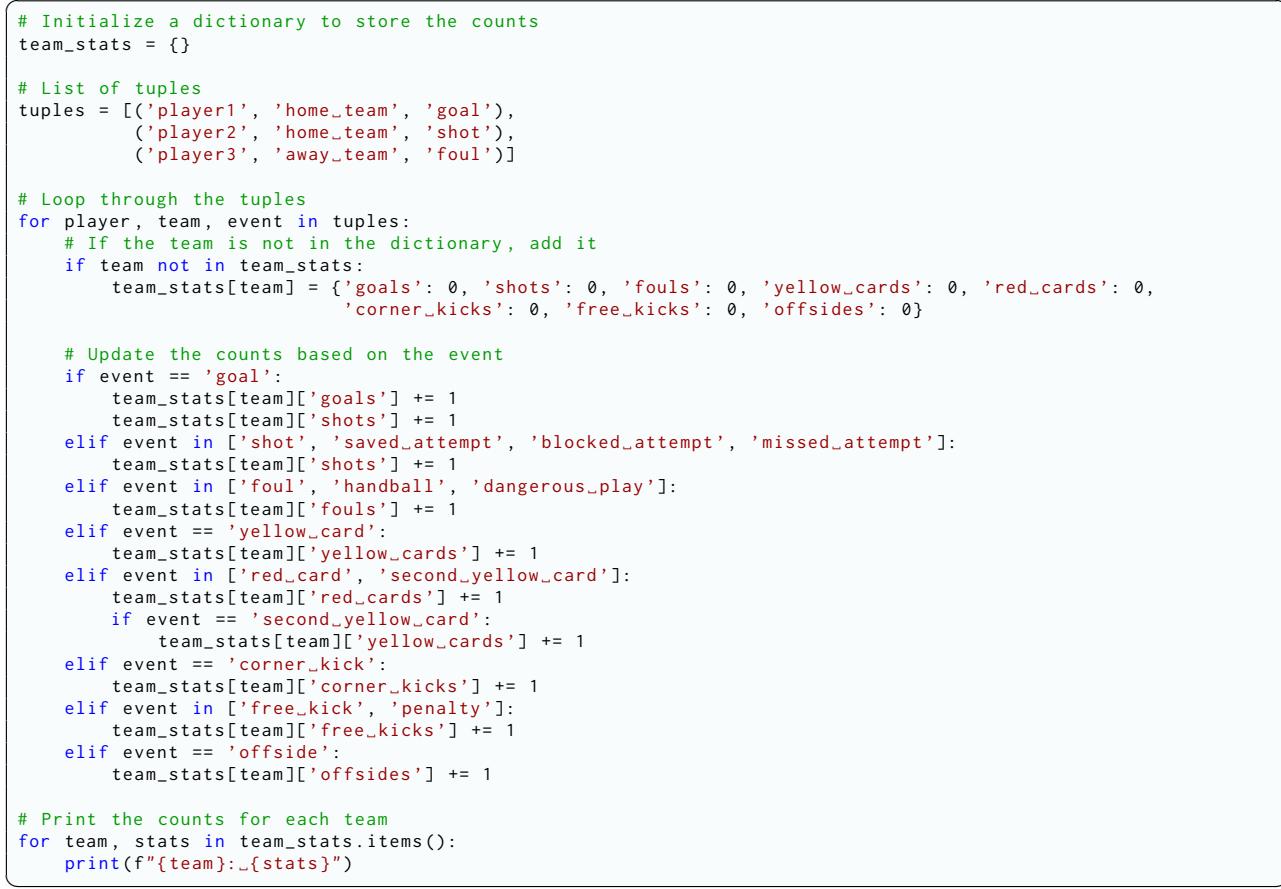
图 7 展示了生成代码的一个示例。它初始化一个字典,循环遍历提取的元组,并根据事件类型增加计数器。这可靠地连接了文本与最终数字之间的鸿沟。
第三步: 元组到表格 (生成阶段)
最后,整合后的数据 (Python 脚本输出的计数) 被反馈给 LLM (或格式化器) 以生成最终的表格结构 (CSV, Markdown 等) 。由于推理的艰巨工作已在第二步完成,这一步就变得直截了当了。
实验与结果
那么,分解任务真的有帮助吗?研究人员在 LIVESUM 数据集上测试了各种最先进的 LLM,包括 GPT-4、Claude 3 和 Mistral Large。
指标
他们使用了两个主要指标:
- RMSE (均方根误差) : 表格中的数字偏差有多大? (越低越好) 。
- 错误率 (Error Rate) : 不正确的单元格百分比。
主要发现
1. 零样本 LLM 表现挣扎 如果不使用 \(T^3\) 流程,即使是最好的模型也很吃力。
- 简单类别 (如直接陈述的进球) 错误率较低。
- 困难类别 (如需要推理和计数的射门和犯规) ,某些模型的错误率高达 90% 。
2. \(T^3\) 带来巨大提升 应用 \(T^3\) 流程大幅降低了错误率。
- GPT-4 的平均错误率从 46.32% (零样本) 降至 25.27% (使用 \(T^3\)) 。
- Claude 3 Opus 取得了巨大的进步,错误率从 48.33% 降至 14.04% 。
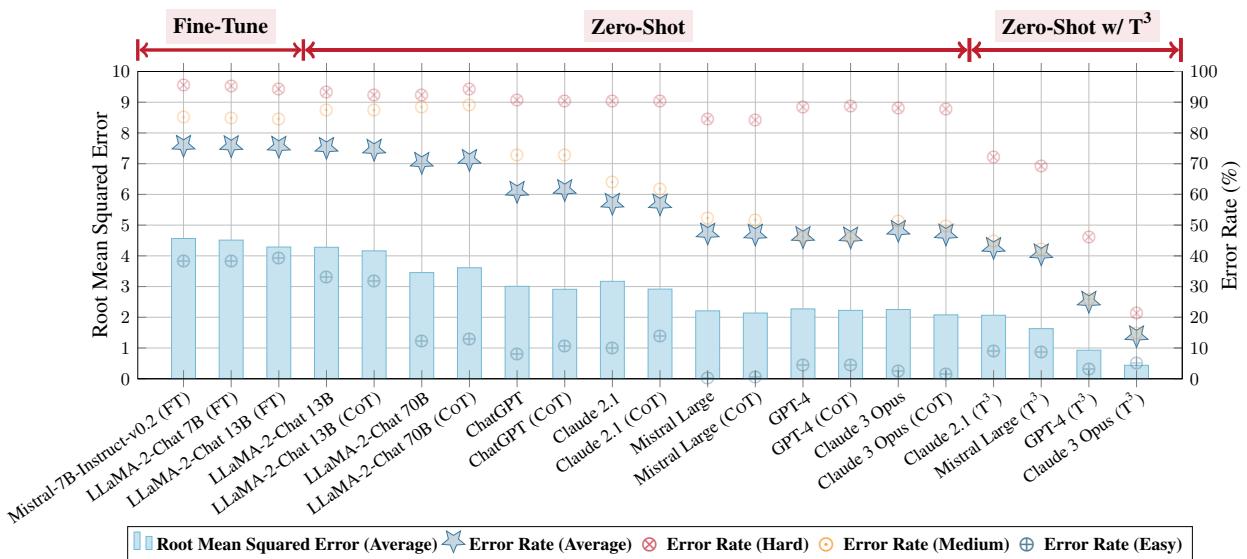
图 4 总结了这些结果。
- 红线 表示性能的转变。
- 请看右侧的 Zero-Shot w/ \(T^3\) 部分。与中间部分 (标准零样本) 相比,错误率 (蓝色星号) 直线下降。
- 值得注意的是,\(T^3\) 方法的表现通常优于在该数据集上经过专门 微调 (fine-tuned) 的模型,这对于一种基于提示的策略来说是一个了不起的成就。
3. 代码生成 vs. 心算 消融实验 (对特定组件的详细分析) 证实,使用代码生成进行整合 (第二步) 优于要求 LLM 自己合并元组。当 GPT-4 扮演程序员而不是计算器的角色时,其表现显著提高。
泛化能力: 不仅仅是足球
怀疑论者可能会问: “这只适用于体育吗?”
为了证明 \(T^3\) 的鲁棒性,研究人员将其应用于 WIKI40B 数据集,这是一个源自维基百科的通用数据集。由于没有地面真值表格,他们使用了一种名为“Auto-QA 覆盖率”的指标——本质上是问,“我们能仅使用生成的表格回答关于文本的问题吗?”
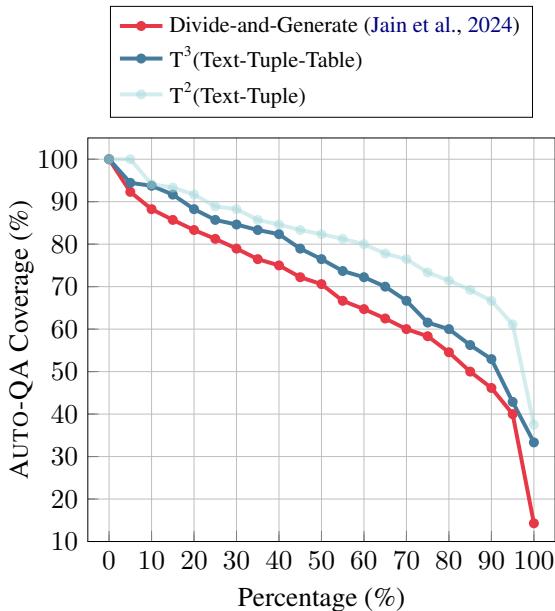
图 5 将 \(T^3\) 与之前的最先进方法“Divide-and-Generate (分治生成) ”进行了比较。
- x 轴代表数据的百分比。
- y 轴代表 QA 覆盖率 (质量) 。
- 蓝色菱形线 (\(T^3\)) 始终高于红圈线。这意味着与以前的提示策略相比,\(T^3\) 从开放领域文本中捕捉到了更准确的信息。
结论与启示
这篇名为“Text-Tuple-Table”的论文强调了我们使用大语言模型方式的一个关键演变。我们正从将 LLM 视为简单的“文本处理器”,转向将它们用作能够分解问题的“推理引擎”。
以下是给学生和从业者的主要启示:
- 结构至关重要: \(T^3\) 流程之所以有效,是因为它在过程早期就对非结构化数据施加了结构 (元组) 。
- 工具使用很强大: 将逻辑和算术运算分流给代码 (Python) 几乎总是比依赖 LLM 的内部权重进行计算要好。
- 更好的基准测试推动进步: LIVESUM 数据集暴露了以前简单的数据集所掩盖的模型弱点。我们需要测试 推理 能力,而不仅仅是格式化能力的基准。
通过提取全局元组并以编程方式整合它们,\(T^3\) 方法为 AI 智能体铺平了道路,使其能够真正“阅读”报告并合成准确、数据丰富的表格,无论处于哪个领域。