](https://deep-paper.org/en/paper/2405.02144/images/cover.png)
引言
“如果你无法衡量它,就无法改进它。”
彼得·德鲁克 (Peter Drucker) 的这句名言在医学传播领域尤为真切。我们生活在一个可靠的医学知识对公共卫生至关重要的时代。从维基百科文章到默克诊疗手册 (Merck Manuals) ,从前沿研究论文到患者宣传册,健康信息的传播从未停止。
然而,获取信息并不等同于理解信息。医学文本通常以难以消化著称。它们内容密集、技术性强,并且充满了专业术语,这些都可能将它们本意要帮助的人群——患者和非专业人士——拒之门外。
为了使医学文本更易于获取,我们首先需要一种可靠的方法来衡量它们的阅读难度。但问题在于: 传统的为了通用英语 (如新闻文章或学校教科书) 设计的可读性指标,在应用于医学领域时往往会失效。
在这篇文章中,我们将深入探讨一篇名为 “MEDREADME: A Systematic Study for Fine-grained Sentence Readability in Medical Domain” (MEDREADME: 医学领域细粒度句子可读性的系统研究) 的论文。这项研究介绍了一个突破性的数据集和一种评估可读性的新方法。我们将探讨为什么医学句子如此难以解析,研究人员如何根据 Google 搜索结果对“术语”进行分类,以及对现有数学公式的一个简单修改如何能够极大地提高我们预测可读性的能力。
传统指标的问题
在探索解决方案之前,我们需要了解现有工具的缺陷。你可能熟悉像 Flesch-Kincaid 年级水平 (FKGL) 这样的可读性测试。这些公式通常依赖于表层特征: 单词的音节数和句子的单词数。
其逻辑很简单: 长单词和长句子很难读。
\[ \begin{array} { r } { F K G L = 0 . 3 9 \left( \frac { \mathrm { \ t o t a l ~ w o r d s } } { \mathrm { t o t a l ~ s e n t e n c e s } } \right) } \\ { + 1 1 . 8 \left( \frac { \mathrm { t o t a l ~ s y l l a b l e s } } { \mathrm { \ t o t a l ~ w o r d s } } \right) } \\ { - 1 5 . 5 9 } \end{array} \]
然而,在医学领域,复杂性并不总是与长度有关。一个充满晦涩医学术语 (行话) 的短句,可能比一个使用常用词汇的长描写句更难理解。因为传统指标忽略了特定术语的含义和熟悉度,它们经常会错误地对医学文本的难度进行分类。
为了解决这个问题,研究人员意识到他们需要更好的数据。他们需要的不仅是关注句子,还需要关注句子中那些造成困惑的具体单词的数据集。
介绍 MEDREADME
研究人员构建了 MEDREADME , 这是一个包含 4,520 个句子的数据集。这些句子来源于 15 个不同的医学资源,范围从技术性很强的研究摘要 (如 PLOS Pathogens) 到面向更广泛受众的百科全书 (默克诊疗手册和维基百科) 。
这个数据集的独特之处在于其细粒度。它包括:
- 句子级可读性评分: 由人类使用 CEFR 量表 (语言能力标准) 进行标注。
- 细粒度的片段 (span) 标注: 标记出困难的具体单词或短语,并按其为何困难进行分类。

如上图 1 所示,该数据集追踪了复杂句子是如何转化为简单句子的。请注意从“复杂医学文章” (Complex Medical Article) 到“简单医学文章” (Simple Medical Article) 的过渡。研究人员不仅对句子进行了评分;他们还追踪了特定的“术语”片段 (如 “oro-antral communication”) ,观察它们在简化版本中是被删除、解释还是保留。
新的分类体系: “谷歌易懂” vs. “谷歌难懂”
这就论文最具创新性的贡献之一是它对术语的分类方式。过去,单词通常只是二元分类: “复杂”或“不复杂”。
作者认为,在现代社会,难度是相对于可搜索性而言的。大多数人会在网上查询健康信息。因此,他们引入了两个新颖的类别:
- Google-Easy (谷歌易懂) : 虽是专业医学术语,但在快速 Google 搜索后可以很容易理解 (例如 “Schistosoma mansoni”) 。搜索结果通常提供清晰的定义、图片或“知识面板”。
- Google-Hard (谷歌难懂) : 即使在 Google 搜索后,仍需广泛研究才能理解的术语。这些通常是复杂的多词表达 (例如 “processive nucleases”) ,其搜索结果往往是密集的学术论文,而不是简单的摘要。
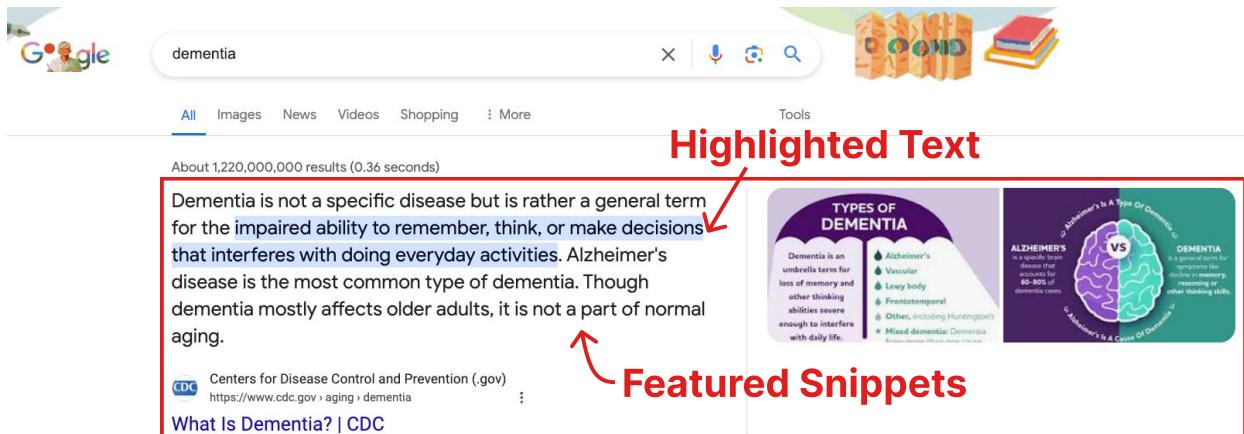
图 6 说明了为什么一个术语可能是“谷歌易懂”的。当搜索引擎提供“知识面板” (右侧的框) 或“精选摘要” (顶部的答案) 时,读者的认知负荷会显着降低。研究人员发现,与“谷歌难懂”的术语相比,“谷歌易懂”的术语更有可能拥有这些视觉辅助。
为什么医学文本如此难懂?
建立了数据集后,研究人员进行了数据驱动的分析,以查明究竟是什么让医学文本变得困难。他们分析了 650 个语言特征,结果指向了一个主要因素: 术语 (Jargon) 。
术语 vs. 句子长度
虽然传统指标强调句子长度,但 MEDREADME 的分析表明,术语是该领域难度的更强预测因子。
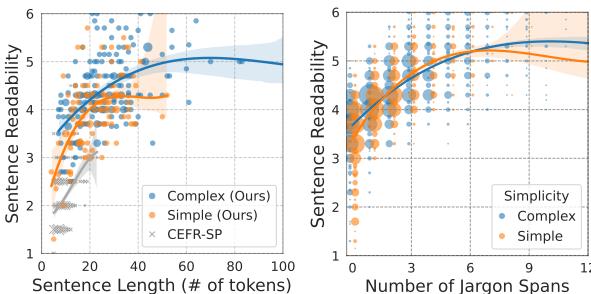
请看图 3 中的图表。
- 左图: 显示可读性与句子长度之间的关系。你可以看到相关性,但请注意,“复杂”和“简单”的线条只有在句子变得相当长之后才明显分开。
- 右图: 显示可读性与术语片段数量之间的关系。斜率更陡峭,区分更清晰。句子中的术语片段越多,读起来就越难,这几乎呈线性关系。
这证实了虽然长度有影响,但专业术语的密度才是理解的关键瓶颈。
难度的领域分布
并非所有术语都是生而平等的。研究人员按医学子领域细分了“谷歌易懂”和“谷歌难懂”的术语。
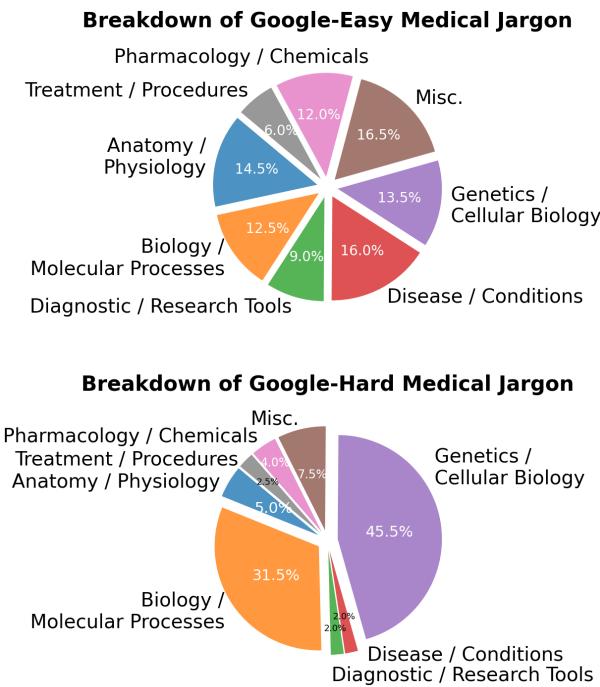
如图 4 所示, 遗传学和细胞生物学 (蓝色部分) 在“谷歌难懂”类别中占据主导地位。这些领域涉及抽象的、微观的概念,这些概念较难可视化,也不太可能有简单的面向消费者的网络解释。相比之下,与疾病或解剖学相关的术语通常是“谷歌易懂”的,因为它们更具体且被普遍搜索。
不同来源的差异性
另一个有趣的发现是“简化”文本的不一致性。我们通常假设如果一段文本被标记为“通俗语言摘要”,它一定很容易阅读。
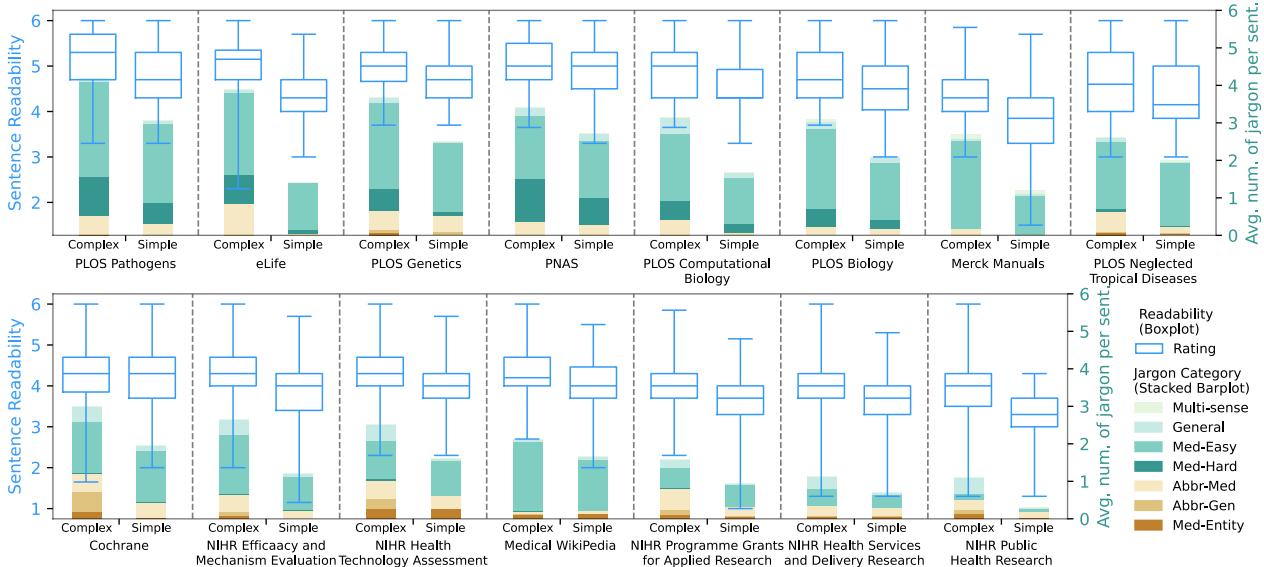
图 2 揭示了一个混乱的现实。蓝色箱线图显示了可读性范围。虽然“简单”版本 (每对的右侧) 通常比“复杂”版本 (每对的左侧) 更容易,但基准线差异很大。
- 默克诊疗手册 (最右侧) 始终具有较高的可读性。
- PLOS Pathogens (最左侧) ,即使在其简化版本中,仍然非常困难——甚至比其他来源的复杂版本还要难!
这表明“简化”是主观的,并且高度依赖于特定期刊或平台的目标受众。
改进可读性指标
分析提供了一个清晰的路线图: 如果术语是罪魁祸首,我们的公式就需要考虑到它。
“-Jar” 改进方案
研究人员建议对现有的无监督指标 (如 FKGL、ARI 和 SMOG) 进行简单的修改。他们增加了一个单一特征: 术语片段的数量 (\(\#Jargon\))。
例如,经典的 FKGL 公式更新为 FKGL-Jar :
\[ \mathrm { F K G L \mathrm { - } J a r } = \mathrm { F K G L } + \alpha \times \# \mathrm { J a r g o n } , \]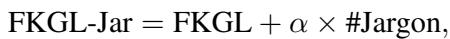
这里,\(\alpha\) 是一个在数据集上调整的权重参数。这个简单的添加将语义难度 (术语) 与句法难度 (句子长度) 结合了起来。
结果
这一变化的影响是显著的。研究人员将标准指标与增强了“Jar”的版本进行了比较。
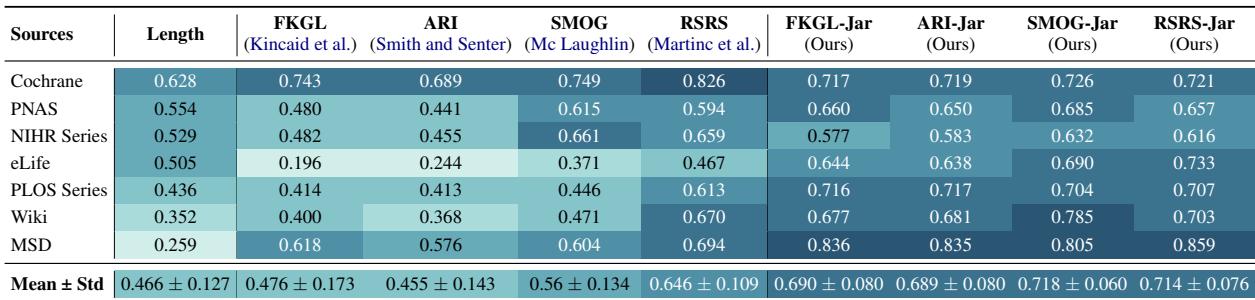
表 4 显示了指标评分与人类判断之间的皮尔逊相关系数 (越高越好) 。
- FKGL 的相关系数约为 0.476 。
- FKGL-Jar 跃升至 0.690 。
- SMOG 从 0.56 变为 0.718 。
仅仅通过计算术语数量,这些公式在预测人类认为的困难程度方面就变得更加准确了。
跨长度的稳定性
此外,增加术语项使得指标在不同句子长度下更加稳定。
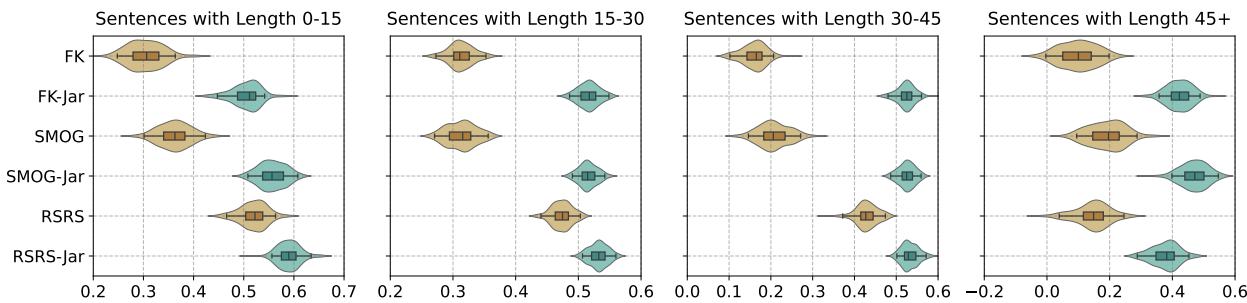
图 5 显示了相关性的置信区间。无论句子是短 (0-15 个词) 还是长 (45+ 个词) ,青色分布 (代表新的 “-Jar” 指标) 始终比棕色分布 (标准指标) 更高 (相关性更好) 且更紧凑 (更稳定) 。
自动化术语识别
要在现实世界中使用“FKGL-Jar”公式,你需要知道句子中有多少个术语。大规模手动计数是不可能的。
研究人员将其视为一个命名实体识别 (NER) 任务。他们训练了深度学习模型 (特别是 BERT 和 RoBERTa) 来自动扫描句子并识别符合术语条件的文本片段。
他们测试了各种模型,包括那些专门在生物医学文本上预训练的模型 (BioBERT, PubMedBERT) 。
模型性能
研究人员评估了这些模型识别 7 种不同类别的复杂片段 (如谷歌易懂、谷歌难懂、缩写等) 的能力。

表 9 凸显了 MEDREADME 数据集的必要性。当模型在通用领域数据 (如以前比赛中的维基百科或新闻数据) 上训练时,它们在医学文本上彻底失败了 (F1 分数约为 38-46%) 。然而,在 MEDREADME 上训练的模型达到了 86.8% 的 F1 分数。
这证明了医学可读性是一个需要专门训练数据的专业领域。你不能简单地将通用的“复杂词识别器”应用于临床试验摘要并期望获得准确的结果。
结论
MEDREADME 研究从根本上改变了我们处理医学文本简化的方式。它让我们摆脱了“单词短 = 易读”的过时观念,并承认了词汇的细微差别。
关键要点:
- 上下文很重要: 一个医学术语不仅仅是“难”;根据围绕它的数字生态系统,它是“谷歌易懂”或“谷歌难懂”的。
- 术语为王: 技术术语的密度是医疗保健领域阅读难度的最大单一预测因子,超过了句子长度。
- 简单的修复行之有效: 我们并不总是需要庞大的黑盒模型。向像 FKGL 这样拥有 50 年历史的公式中添加简单的术语计数,就能让它们再次变得高效。
- 数据至关重要: 通用 NLP 模型在医学领域会失效。像 MEDREADME 这样高质量、特定领域的标注对于训练 AI 帮助患者至关重要。
通过更准确地衡量可读性,我们可以为医生、编辑和 AI 构建更好的工具来简化医学文本。最终,这将通向一个患者能够更好地了解自身健康状况、做出明智决定并自信地在现代医学的复杂环境中导航的世界。