](https://deep-paper.org/en/paper/2405.03279/images/cover.png)
想象一下,你训练了一个最先进的大型语言模型 (LLM) 。它能说流利的英语,会写 Python 代码,还能理解复杂的逻辑推理。但有一个问题: 它仍然认为英国首相是鲍里斯·约翰逊,或者它不知道昨天发生的重大地缘政治事件。
这就是“静态知识”问题。一旦 LLM 训练完成,它的知识就被冻结在了时间里。每当事实发生变化时,从头开始重新训练这些庞大的模型,在经济上和计算上都是不可能的。这导致了模型编辑 (Model Editing) 技术的兴起——旨在对手术刀般精准地更新 LLM 中的特定事实,而不破坏其通用能力。
然而,目前大多数编辑方法都面临一个致命的缺陷: 它们在进行一两次编辑时效果很好,但当你尝试随着时间推移进行数千次编辑时,它们就会崩溃。这种场景被称为终身知识编辑 (Lifelong Knowledge Editing) , 它是保持 AI 能够实时更新的“圣杯”。
在这篇文章中,我们将深入探讨 RECIPE (RetriEval-augmented ContInuous Prompt lEarning,检索增强连续提示学习) ,这是由华东师范大学和阿里巴巴集团的研究人员提出的一个新框架。RECIPE 提出了一个巧妙的解决方案,绕过了直接修改模型权重的需求,转而使用检索系统和“连续提示”来即时注入知识。
问题所在: 为什么终身编辑很难
为了理解为什么 RECIPE 是必要的,我们需要先看看模型编辑的现状。通常,以前的方法分为三类:
- 修改参数 (Modifying Parameters) : 这些方法 (如 ROME 或 MEMIT) 定位负责某个事实的特定神经元,并通过数学方法修改权重以改变该事实。
- 增加参数 (Adding Parameters) : 这些方法 (如 T-Patcher) 在模型上附加新的神经元来处理新信息。
- 基于检索的方法 (Retrieval-Based Methods) : 这些方法保持模型冻结,但使用外部数据库获取正确答案,并在推理过程中将其提供给模型。
虽然这些方法对于批量更新均有效,但在编辑内容要在数月或数年内按顺序到达的“终身”场景中,它们往往力不从心。
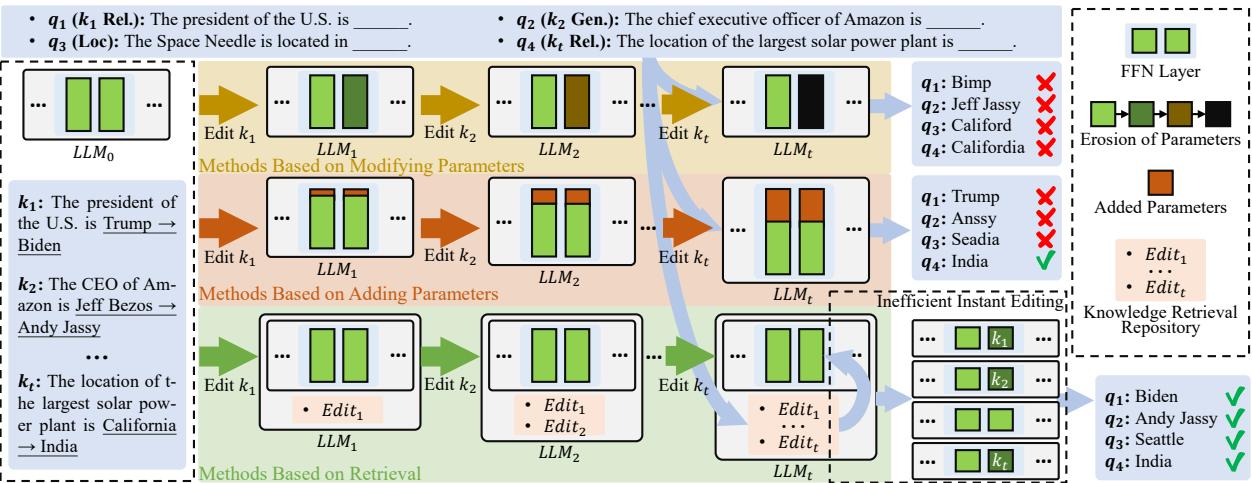
如图 1 所示,随着编辑次数 (\(t\)) 的增加,问题开始显现:
- 参数侵蚀 (Parameter Erosion) : 修改参数的方法会遭遇“灾难性遗忘”。当你不断微调权重 (\(k_1, k_2, \dots, k_t\)) 时,累积的变化开始发生冲突,最终导致模型在之前的编辑和通用任务上的性能下降。模型本质上变得混乱了。
- 参数膨胀 (Parameter Bloat) : 增加参数的方法避免了破坏旧权重,但它们变得效率低下。如果你为每个新事实添加一个新神经元,你的模型将无限增长,导致推理速度变慢,直到无法使用。
- 检索的希望 (The Retrieval Promise) : 基于检索的方法 (图 1 中的底部路径) 似乎很理想。它们将事实存储在一个单独的仓库 (如数据库) 中。LLM 保持不变 (冻结) ,因此不会退化。然而,现有的检索方法一直很笨重。它们通常需要冗长、复杂的文本前缀来向模型解释新事实,或者难以决定何时检索事实,何时依赖模型的内部记忆。
这就是 RECIPE 发挥作用的地方。它的目标是通过使“被检索”的信息高度压缩 (高效) 和检索机制高度智能 (准确) 来完善基于检索的方法。
介绍 RECIPE
RECIPE 代表 RetriEval-augmented ContInuous Prompt lEarning (检索增强连续提示学习) 。
RECIPE 的核心理念是,不把每一条新知识看作是需要阅读的句子,而是看作是通过学习到的向量表示来解决的一个“微任务”。它包含两个主要创新:
- 有知识的连续提示学习 (Knowledgeable Continuous Prompt Learning) : RECIPE 不会给 LLM 提供像“美国总统是乔·拜登”这样的长句,而是将这个事实编码成一个简短、密集的向量 (连续提示) 。这个提示经过数学优化,强迫 LLM 输出正确答案。
- 带知识哨兵的动态提示检索 (Dynamic Prompt Retrieval with Knowledge Sentinel) : 一种智能门控机制,决定传入的用户查询是否实际上与已编辑的事实相关。如果相关,它就检索提示。如果不相关,它就让 LLM 正常回答。
让我们看看整体架构。

如图 2 所示,该过程分为三个流程:
- 构建 (左) : 将编辑示例 (例如,“亚马逊的 CEO 是安迪·贾西”) 转换为存储在仓库 (\(K_t\)) 中的提示。
- 检索 (中) : 当查询进来时 (\(q_1, q_2, q_3\)) ,系统使用知识哨兵决定提取哪个提示。
- 推理 (右) : 检索到的提示被附加到查询嵌入的前面,以引导冻结的 LLM (\(f_{llm}\)) 得出正确答案。
组件 1: 连续提示编码器
研究人员意识到,使用自然文本来编辑模型是低效的。如果你在每个查询前都加上“注意: 总统是拜登……”,你会消耗模型的上下文窗口并减慢处理速度。
取而代之的是,RECIPE 使用了连续提示学习 。
当一条新知识 (\(k_t\)) 到达时 (例如,“亚马逊的 CEO 是安迪·贾西”) ,它首先由文本编码器 (如 RoBERTa) 处理。然后输出通过一个多层感知机 (MLP) 进行压缩,使其变成一种非常特定的格式: 连续提示 token 矩阵。
\[r_{k_t} = \mathbf{MLP}_{K}(f_{rm}(k_t))\]\[p_{k_t} = f_{resp}\left(\mathbf{MLP}_{P}\left(r_{k_t}\right)\right)\]在这里,\(p_{k_t}\) 代表“连续提示”。它是一系列模仿词嵌入形状的向量,但不一定对应实际的人类词汇。它充当了 LLM 的“触发器”。
这种做法的精妙之处在于紧凑性。研究人员发现,他们可以将一个事实压缩成仅 3 个 token 。 相比之下,自然语言指令可能需要 10-20 个 token。这确保了模型在推理过程中保持极快的速度。
组件 2: 知识哨兵 (KS)
基于检索的编辑最大的挑战是决定何时进行检索。
如果用户问: “谁是亚马逊的 CEO?”,我们要检索该编辑内容。 如果用户问: “我该怎么烤蛋糕?”,我们不想检索关于亚马逊的事实,也不想给模型输入无关的噪声。
大多数系统使用固定阈值 (例如,“如果相似度得分 > 0.8,则检索”) 。问题在于,不同主题的语义相似度差异很大。0.8 的阈值对于某些查询可能太严格,而对于其他查询则太宽松。
RECIPE 引入了知识哨兵 (Knowledge Sentinel, KS) 。
哨兵是一个可学习的嵌入向量 (\(\Theta\)) ,它充当动态参考点。它与查询和知识位于同一个向量空间中。
当查询 \(q\) 进来时,系统计算两个相似度得分:
- 查询与数据库中最相关事实之间的相似度 (\(r_{k_j}\)) 。
- 查询与知识哨兵之间的相似度 (\(r_{\Theta}\)) 。
检索逻辑非常简单优雅:
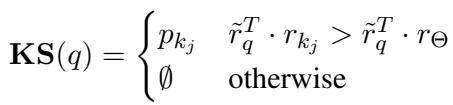
如果查询与特定事实 (\(r_{k_j}\)) 的距离比它与哨兵 (\(r_{\Theta}\)) 的距离更近,这意味着系统确信查询与该事实相关。如果查询更接近通用的哨兵,则意味着查询与知识库无关 (或“超出范围”) ,系统返回空集 (\(\emptyset\)) 。
这使得“相关”与“不相关”之间的边界是可以学习和动态变化的,而不是一个硬编码的数字。
组件 3: 即时推理
一旦检索到提示 (或未检索到) ,推理就很直接了。RECIPE 框架采用冻结的 LLM (表示为 \(\hat{f}_{llm}\),意指不包含嵌入层的 Transformer 层) ,并将提示向量与查询向量连接起来。
\[a_q = \hat{f}_{llm}(p_{k_{\tau}} \oplus f_{emb}(q))\]这有效地将隐藏指令“前缀”到了输入中。因为提示是专门为引出目标答案而训练的,所以 LLM 会遵循指令并输出更新后的事实。
训练编辑器
RECIPE 如何学习生成这些神奇的提示并训练哨兵?它使用冻结的 LLM 进行联合训练。训练数据包括编辑样本 (可靠性) 、改写后的查询 (泛化性) 和不相关的查询 (局部性) 。
损失函数是两个目标的组合:
1. 编辑损失 (\(\mathcal{L}_{edit}\))
这确保了提示确实有效。它迫使模型:
- 可靠性 (Reliability) : 对特定的编辑查询输出正确答案。
- 泛化性 (Generality) : 对查询的改写版本输出正确答案 (例如,“亚马逊的老板”而不是“亚马逊 CEO”) 。
- 局部性 (Locality) : 确保提示不会搞乱不相关的问题。它使用 Kullback-Leibler (KL) 散度来确保模型在不相关问题上的输出分布与原始未编辑模型保持接近。
2. 提示学习损失 (\(\mathcal{L}_{pl}\))
这使用对比学习 (InfoNCE 损失) 来训练检索器和哨兵。
- 邻居导向损失 (Neighbor-oriented Loss) : 将查询的表示拉近其对应的知识事实。
- 哨兵导向损失 (Sentinel-oriented Loss) : 这很关键。它将不相关的查询推离特定事实,并推向哨兵。反之,它将相关查询推离哨兵。 \[L_{total} = L_{edit} + L_{pl}\] 通过最小化这个总损失,RECIPE 同时学会了如何将知识压缩成提示,以及如何区分相关和不相关的查询。
实验结果
研究人员将 RECIPE 与大量基线进行了评估对比,包括 ROME、MEMIT、MEND 以及其他基于检索的方法如 GRACE 和 LTE。他们使用 Llama-2 (7B)、GPT-J (6B) 和 GPT-XL (1.5B) 进行了测试,使用的数据集模拟了终身编辑 (高达 10,000 次编辑) 。
1. 终身编辑性能
终身编辑的结果非常鲜明。随着编辑次数的增加,大多数方法都崩溃了。
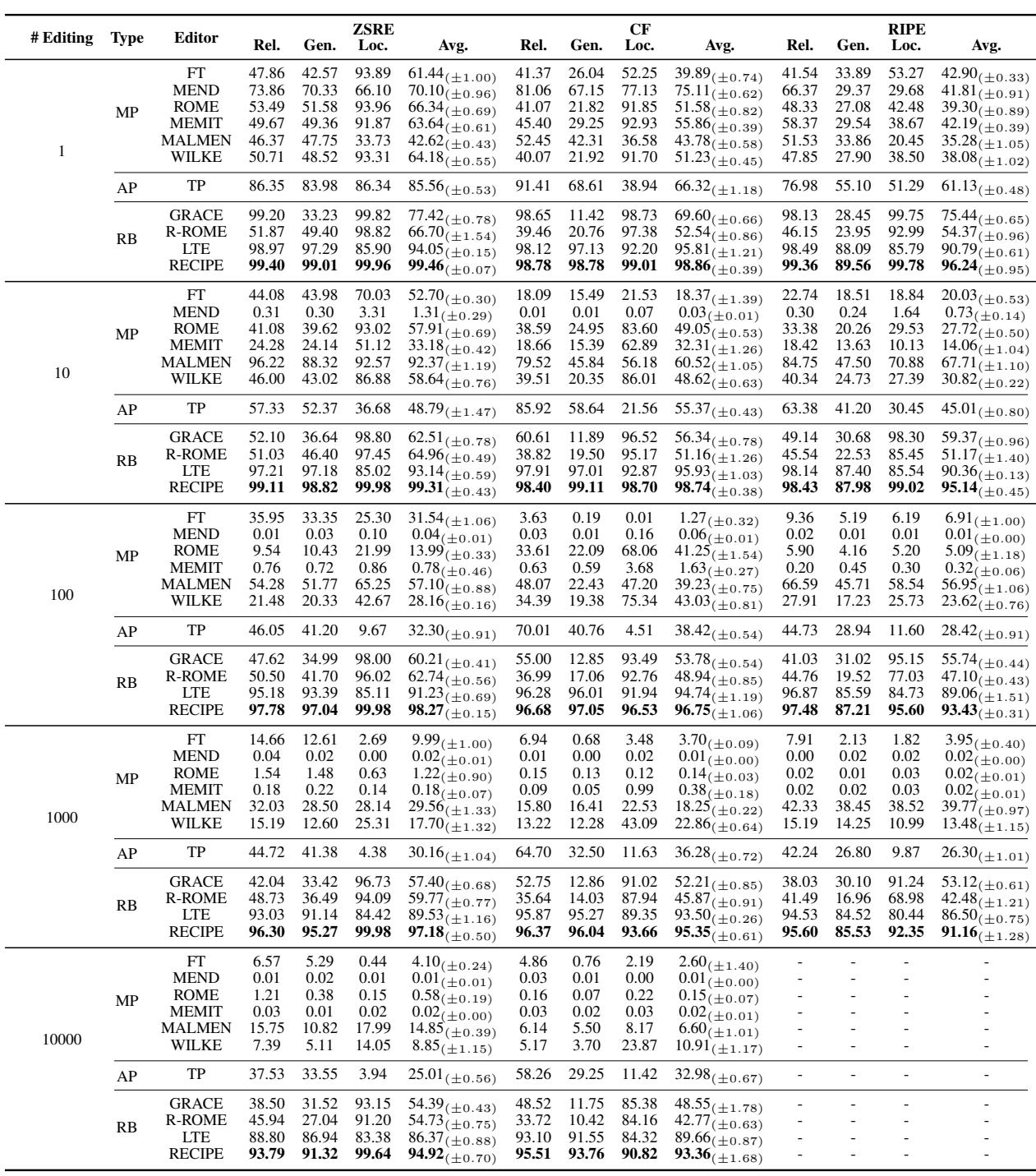
查看表 1 (使用 Llama-2) :
- 修改参数 (MP) : 像 ROME 和 MEMIT 这样的方法在 1 次编辑时表现强劲,但在 100 或 1,000 次编辑时大幅崩溃。请注意,MEMIT 在 1,000 次编辑时的“Rel” (可靠性) 得分几乎降为零。这证实了权重变化的“有毒累积”。
- 增加参数 (AP) : T-Patcher (TP) 表现尚可,但随着编辑增加,在局部性 (干扰不相关事实) 方面表现挣扎。
- RECIPE: 在可靠性、泛化性和局部性方面始终保持近乎完美的分数 (99%+) ,甚至高达 10,000 次编辑。它的表现优于 LTE (另一种检索方法) ,并且在参数修改方法面前占据绝对优势。
2. 通用能力
编辑 LLM 的最大风险之一是“脑叶切除术”——你修复了一个事实,但破坏了模型推理或执行标准任务的能力。
研究人员在 1,000 次编辑后,在 MMLU (学术科目) 和 GSM8K (数学) 等通用基准上测试了模型。
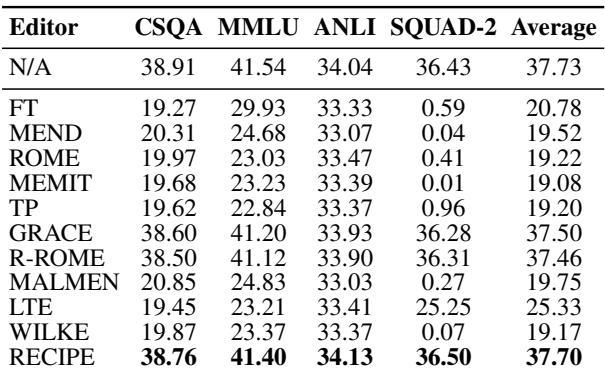
表 2 显示,非检索方法 (FT, MEND, ROME) 导致通用性能大幅下降 (平均分从 ~37 降至 ~19) 。然而,RECIPE 几乎完美地保留了原始模型的性能 (平均 37.70 vs. 基线 37.73) 。因为 RECIPE 本质上是“引导”模型而不是破坏其内部权重,所以模型保留了其原始智能。
3. 效率
它快吗?如果检索系统必须搜索海量数据库或处理长上下文,它可能会很慢。
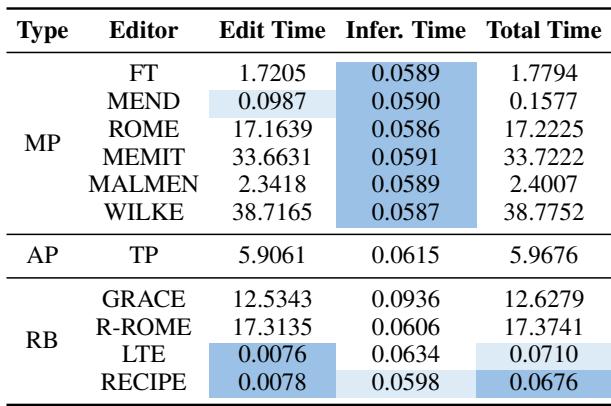
表 3 凸显了速度优势。
- 编辑时间: RECIPE 添加新事实几乎是瞬间完成的 (0.0078秒) ,因为它只涉及编码字符串和存储向量。ROME 需要 17 秒;MEMIT 需要 33 秒。
- 推理时间: 因为 RECIPE 仅向输入添加 3 个 token,所以与基础模型相比,其推理开销可以忽略不计。它比 LTE 快,且显著快于 GRACE。
为什么是 3 个 Token?
论文中一个有趣的消融研究问道: “我们需要多少个 token 来表示一个事实?”
研究人员将连续提示 token (CPT) 的数量从 1 变为 5。
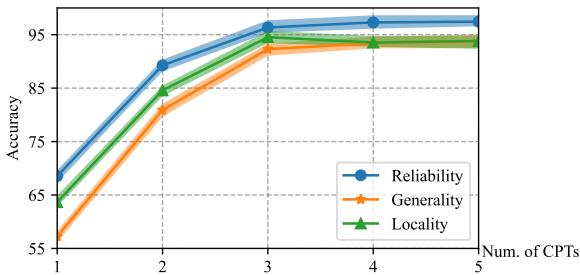
如图 3 所示,仅用 1 个 token 时性能会下降 (将“美国总统是拜登”压缩成单个向量太难了) 。然而,性能在 3 个 token 处达到平稳。
作者推测这与知识三元组的结构相吻合: (主体, 关系, 客体) 。 例如,(美国, 总统, 拜登)。
为了证明这一点,他们对向量空间进行了可视化。
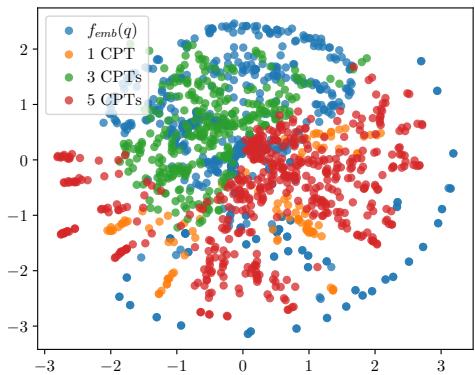
图 4 显示了 t-SNE 可视化结果。绿色点 (3 CPTs) 比 1 CPT 或 5 CPTs 变体更紧密地聚集在自然词嵌入 (红点) 周围。这表明 3 个 token 是在 LLM 嵌入空间中表示事实性知识的“最佳平衡点”。
核心要点
RECIPE 论文为 LLM 维护的未来提出了令人信服的论点。总结如下:
- 不要修改权重: 对于终身学习,修改模型的权重会导致不可避免的退化 (灾难性遗忘) 。
- 检索为王: 保持模型冻结并检索编辑内容是扩展到数千次更新的唯一途径。
- 连续提示: 我们不需要用自然语言与模型交谈。学习到的连续提示对于编码特定事实更高效、更有效。
- 知识哨兵: 动态阈值对于准确检索至关重要。哨兵允许系统区分“我知道这个具体的编辑”和“我应该让模型自己回答”。
RECIPE 提供了一条通往 LLM 的道路,使其可以持续、即时、无限地更新,而无需进行全面的重新训练。对于任何构建需要与世界保持同步的 AI 系统的人来说,这都是一种值得关注的方法论。