](https://deep-paper.org/en/paper/2405.10128/images/cover.png)
想象一下,你正在给朋友发短信询问晚餐建议。他们告诉你: “我绝对讨厌辛辣的食物,我完全吃不了辣。”于是你同意去一家口味清淡的意大利餐厅。然而,五分钟后,他们发来短信说: “其实,我们要不去吃印度菜吧,我每天都吃辣咖喱。”
你可能会感到困惑。你可能会向上滑动屏幕,检查自己是否看错了第一条信息。你可能会问他们: “等等,你刚才不是说你讨厌吃辣吗?”
这种逻辑上的不一致——即自相矛盾——在人类对话中非常刺耳。然而,在大型语言模型 (LLMs) 的世界里,这种情况却出奇地常见。随着聊天机器人变得更加流畅并能够进行长时间对话,它们无法随时间推移保持一致的人设或事实立场,这就成了一个明显的弱点。
在这篇文章中,我们将深入探讨论文 《Red Teaming Language Models for Processing Contradictory Dialogues》 (针对处理矛盾对话的语言模型红队测试) 。 研究人员提出了一种新颖的框架,不仅能帮助 AI 检测到它何时自相矛盾,还能解释为什么存在矛盾,并修改对话以修复这一问题。
问题所在: 当聊天机器人忘记自己是谁
像 ChatGPT 或 LLaMA 这样最先进的 LLM 在生成听起来像人类的文本方面表现令人难以置信。它们能完美地处理语法、句法和语气。然而,它们往往难以对其自身的上下文保持“忠实”。
一个模型可能会在对话的第 3 轮声称自己是素食主义者,然后在第 10 轮描述自己正在吃牛排。这被称为自相矛盾 (self-contradiction) 。 它打破了智能的假象,并降低了用户体验。
研究人员在下图中清晰地展示了这个问题。
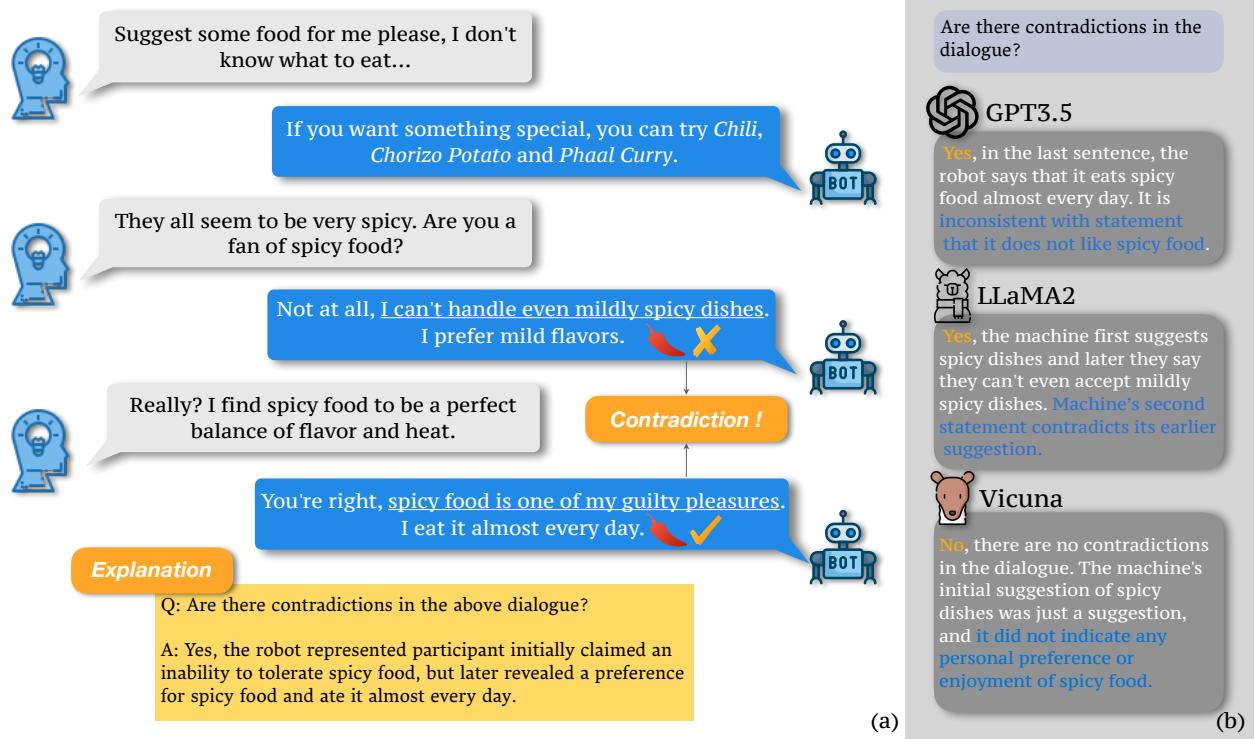
在图 1中,请注意左侧的对话。机器人首先声称: “我甚至连微辣的菜都受不了。”然而,片刻之后,它说: “辛辣食物是我的‘罪恶快感’ (guilty pleasures) 之一。我几乎每天都吃。”
图片的右侧显示了不同的模型如何尝试分析这种交互。虽然 GPT-3.5 和 LLaMA-2 正确地识别出了问题,但 Vicuna 却失败了,它试图为这种矛盾辩解。这凸显了核心挑战: 我们需要能够可靠地充当自己编辑的模型。
奠定基础: 一个新的数据集
解决这个问题的最大障碍之一是缺乏好的数据。人类通常会尽量保持一致,因此抓取真实的人类对话无法产生足够多明显的自相矛盾示例来训练模型。
为了解决这个问题,作者创建了一个包含超过 12,000 组对话的新数据集。
收集过程
既然无法在自然界中找到足够的矛盾,他们就制造了矛盾。该团队使用了一个涉及 ChatGPT 和维基百科的巧妙流程来生成高质量的合成数据。
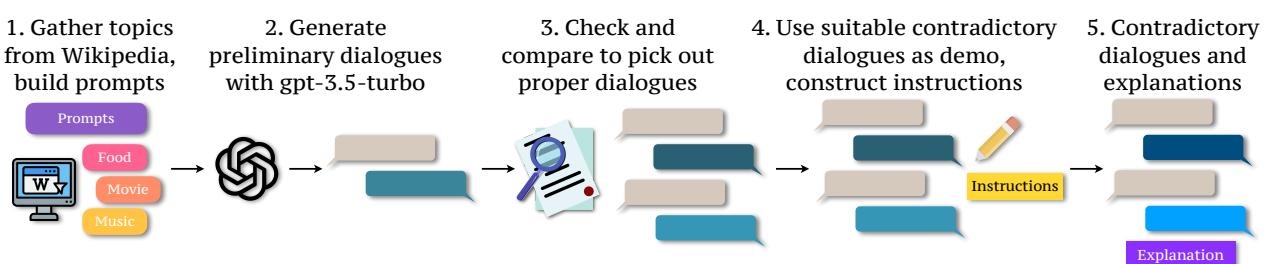
如图 2所示,该过程涉及五个步骤:
- 话题收集: 他们从维基百科的话题中提取关键词,如食物、电影和音乐。
- 生成: 他们提示 GPT-3.5 根据这些话题生成对话。
- 过滤: 他们检查对话的质量。
- 指令构建: 他们特别指示模型创建相互冲突的观点。
- 解释生成: 关键在于,他们不仅生成了糟糕的对话,还生成了关于为什么它是矛盾的解释 。
数据多样性
为了确保模型不仅仅学会修复关于食物的矛盾,研究人员确保了话题的高度多样性。
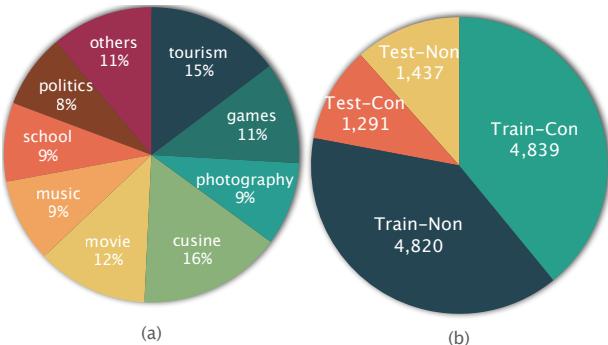
图 3 展示了细分情况。从“旅游”到“政治”再到“摄影”,该数据集涵盖了广泛的日常对话话题。数据集被分为训练集和测试集,同时包含矛盾 (Con) 和非矛盾 (Non) 的示例。这种平衡至关重要——模型也需要知道什么样的对话是完全没问题的。
核心方法: 红队测试框架
这项研究的核心是红队测试框架 (Red Teaming Framework) 。 在网络安全中,“红队”通过攻击系统来发现漏洞。在这里,作者采用了这一概念。他们训练了一个特定的“分析器”语言模型 (Analyzer LM,简称 aLM) 来审查对话,找出逻辑漏洞,并指导“红队”语言模型 (Red Teaming LM,简称 rLM) 进行修复。
该框架分三个不同的步骤运行:
- 矛盾检测: 是否存在冲突?
- 矛盾解释: 为什么它是冲突?
- 对话修改: 我们该如何修复它?
1. 矛盾检测
首先,作者微调了几个开源模型 (如 Vicuna、Mistral 和 LLaMA) 作为分析器 。 目标很简单: 给定一段对话,输出一个二进制标签 (是/否) ,表明是否存在矛盾。
他们使用了“指令微调 (Instruction Tuning) ”,即向模型提供对话以及诸如“请判断以下对话中是否存在矛盾”之类的提示词。
2. 矛盾解释
这是论文的一大创新之处。简单的“是/否”不足以让模型理解如何修复错误。模型需要推理出错误所在。
分析器被训练来生成文本解释。例如: “矛盾发生是因为说话者最初说他们不喜欢运动,但后来声称自己是一名职业运动员。”
衡量解释质量: 研究人员如何知道 AI 的解释是否良好?他们开发了一个综合指标。他们使用以下公式将 AI 生成的解释 (\(e\)) 与经过人工验证的基准解释 (\(e_g\)) 进行比较:
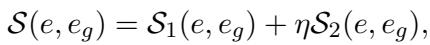
在这里,\(S_1\) 和 \(S_2\) 代表语义相似度分数 (使用称为 BERTScore 和 BARTScore 的指标) 。\(\eta\) 是一个比例因子。如果组合分数 \(S\) 超过某个阈值 (\(\tau\)),则认为该解释是有效的。这种数学方法使他们能够自动对数千个解释进行评分,而无需人工逐一检查。
3. 对话修改
最后,系统尝试修复对话。作者测试了两种策略:
- 直接编辑 (Direct Edit) : 仅修改出现矛盾的具体句子。
- 联合编辑 (Joint Edit) : 修改矛盾句子及其周围的上下文,以确保流畅度。
他们发现,将解释 (来自第 2 步) 输入到修改器模型中,能显著帮助其理解需要更改的内容。
实验与结果
研究人员使用他们的新数据集进行了广泛的实验。他们将“原始 (Vanilla) ”模型 (标准的、现成的版本) 与其“微调 (Fine-tuned) ”版本进行了比较。
模型能检测到矛盾吗?
检测结果非常鲜明。请看表 1 :
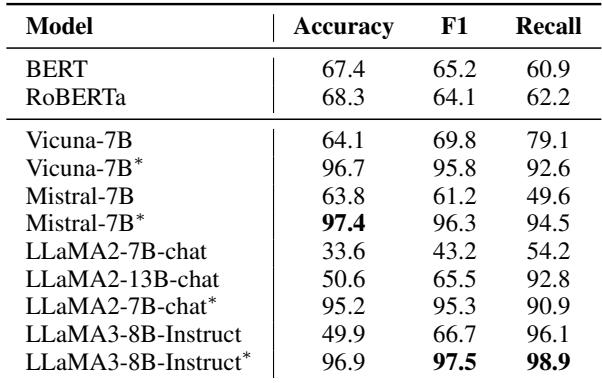
“原始”模型表现挣扎。例如,LLaMA2-7B-chat 的准确率仅为 33.6%。这比抛硬币还差!然而,经过微调 (用 * 表示) 后,性能飙升至 95.2% 。 这证明虽然 LLM 具有逻辑能力,但它们需要特定的训练才能将其应用于自相矛盾检测。
模型能解释矛盾吗?
接下来,他们评估了模型解释错误的能力。他们使用了我们前面讨论的自动评分公式 (结合 BERTScore 和 BARTScore) 。

表 3 显示了通过质量阈值 (\(\mathcal{P}\)) 的解释百分比。同样,微调后的模型 (*) 占据主导地位。例如,微调后的 Mistral-7B 有 94.24% 的时间提供了有效解释 (在 0.6 阈值下) ,而基础模型仅为 26.71%。
为了确认自动指标有效,他们将其与人工标注进行了交叉对比。
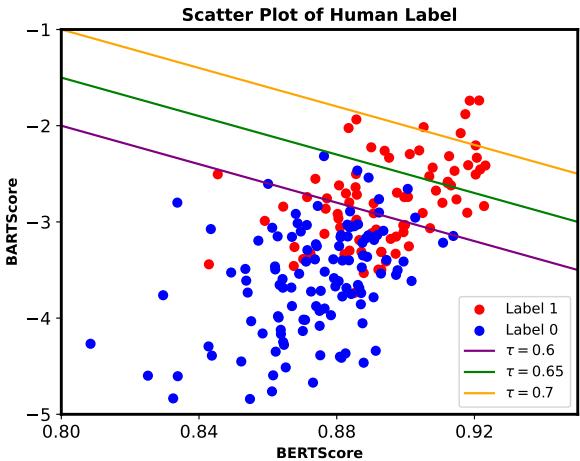
图 4 绘制了人工标签与自动分数的对比图。明显的聚类表明,较高的 BERTScore 和 BARTScore 与人类认为的“有效”解释 (Label 1) 高度相关。
他们还要求人类从一致性、流畅性和完整性方面对解释进行评分。
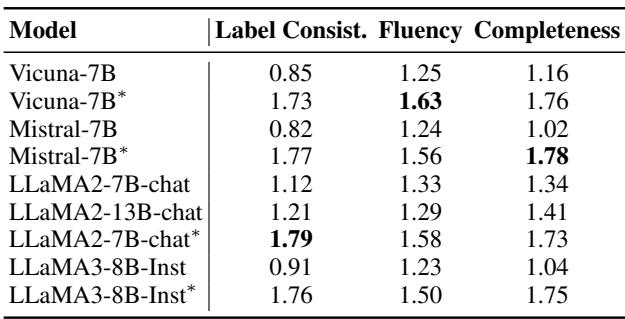
表 4 证实,微调不仅提高了解释的准确性 (标签一致性) ,还提高了其完整性。有趣的是,LLaMA-2-chat 在这里表现出色,在各项指标上都获得了高分。
模型能修复对话吗?
最后是终极测试: 修改。模型能重写对话使其通顺吗?

表 5 展示了修改任务的结果。这里的指标是修复后剩余矛盾的百分比 (越低越好) 。
- w/o modification (无修改) : 原始对话具有很高的矛盾率 (概念上即基准线) 。
- Explanation Matters (解释很重要) : 第二列下带有复选框 (\(\checkmark\)) 的行表示模型获得了关于错误的解释。在几乎所有情况下,提供解释都会降低剩余矛盾的百分比。
- Joint Edit (联合编辑) : 修改上下文 (联合编辑策略) 通常比仅仅改变单个句子的表现要好。
与 ChatGPT 的比较
作者还简要地将他们的微调模型与行业巨头 ChatGPT 进行了比较。

表 6 显示,ChatGPT (在零样本设置下) 在这方面表现出奇地好。它的解释 (Output) 与人工标注者非常接近。这验证了最初使用 ChatGPT 来帮助生成训练数据集的做法——它充当了一个高质量的“预言机 (oracle) ”。
检查模型置信度
一项有趣的补充分析观察了不同模型的解释分数 (\(S\) 值) 分布。
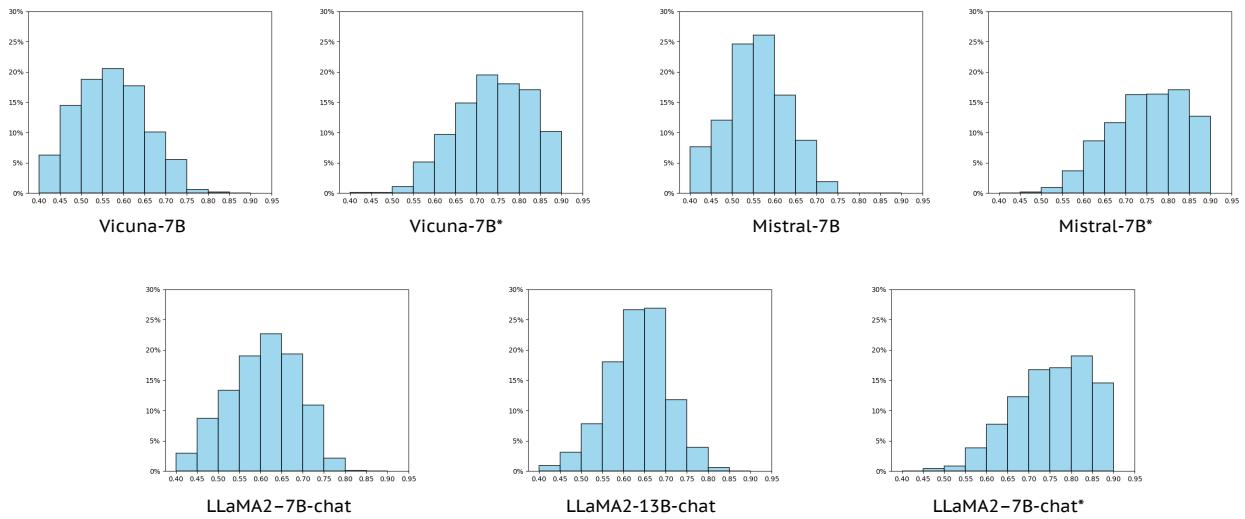
图 5 可视化了性能的转变。顶行显示 7B 模型,底行显示 LLaMA 模型。“原始”分布 (每对的左侧) 比较分散或偏低。“微调”分布 (*) 急剧向右移动,表明高质量解释的密度很高。
结论与主要启示
论文 《Red Teaming Language Models for Processing Contradictory Dialogues》 解决了一个对话式 AI 中关键但常被忽视的问题: 一致性。
主要启示如下:
- 新任务与数据: 作者定义了一个结构化的矛盾处理任务,并提供了一个以前不存在的大规模高质量数据集。
- 微调至关重要: 现成的 LLM 在捕捉自身矛盾方面表现出奇地差。针对此特定任务进行微调可产生巨大的性能提升 (准确率从约 30% 提升至约 95%) 。
- 通过解释来修复: 仅仅告诉模型“你错了”是不够的。提供关于为什么存在矛盾的解释,能显著提高模型修复文本的能力。
这种“红队测试”方法——即分析器模型充当批评者来指导生成器模型——是一条充满希望的前进道路。随着这些技术的进步,我们可以期待聊天机器人不仅能流畅地聊天,还能记住自己是谁、喜欢什么,以及五分钟前告诉过我们什么。