](https://deep-paper.org/en/paper/2405.12801/images/cover.png)
在信息检索 (IR) 和自然语言处理 (NLP) 的世界里,我们一直在平衡两股对立的力量: 速度与精度 。
当你在搜索引擎或聊天机器人中输入查询时,你期望在几毫秒内得到答案。为了实现这一点,系统依赖于快速、轻量级的模型。然而,你也期望答案是完全相关的。实现高相关性通常需要沉重、复杂的模型来深度“阅读”每一个候选文档。
多年来,行业标准一直是一个两阶段的流水线: 检索 (Retrieve) (快但粗糙) 和重排序 (Rerank) (慢但精准) 。但这种流水线有一个缺陷。如果快速检索器错过了正确答案,精准的重排序器就永远看不到它。如果我们试图通过向重排序器发送更多候选项来解决这个问题,系统就会变得太慢。
在这篇文章中,我们将深入探讨一篇研究论文,它为这一两难困境提出了一个巧妙的解决方案: 多候选项比较 (Comparing Multiple Candidates, CMC) 。 该框架引入了一种将查询与一批候选项同时进行比较的方法,使它们能够“看到”彼此并在上下文中争夺头把交椅——而且这一切都不会牺牲轻量级模型的速度。
问题所在: 孤独的双编码器与昂贵的交叉编码器
要理解 CMC,我们需要先了解现代搜索系统的当前架构。
1. 双编码器 (The Bi-Encoder) - 快速检索器
第一道防线通常是双编码器 (BE) 。 它分别处理查询 (Query) 和候选文档 (Candidate Document)。
- 它将查询编码为一个向量。
- 它将候选项编码为一个向量 (通常是离线预计算的) 。
- 它计算它们之间的简单点积 (相似度分数) 。
优点: 速度极快。你可以利用向量搜索索引在毫秒级内搜索数百万个文档。 缺点: 它是“孤独”的。查询的表示不知道候选项的存在,候选项在最后时刻之前也不知道查询的存在。这种缺乏交互通常会导致精度较低。
2. 交叉编码器 (The Cross-Encoder) - 精准重排序器
双编码器给出的顶部结果会被传递给交叉编码器 (CE) 。
- 它将查询和候选项文本同时输入到一个类似 BERT 的模型中。
- 模型的自注意力机制允许查询中的每个标记 (token) 与文档中的每个标记进行交互。
优点: 精度极高,因为它深刻理解特定查询与文档之间的关系。 缺点: 计算成本昂贵。对每个候选项运行一次完整的 BERT 传递是很慢的。因此,我们只能承担重排序一小部分列表 (例如前 10 或 50 个) 的成本。
差距
这就造成了一个瓶颈。如果双编码器将正确答案放在了第 60 位,而交叉编码器只看前 50 位,系统就失败了。我们需要一种方法来以高精度查看更多候选项,但又不需要交叉编码器那样巨大的计算成本。
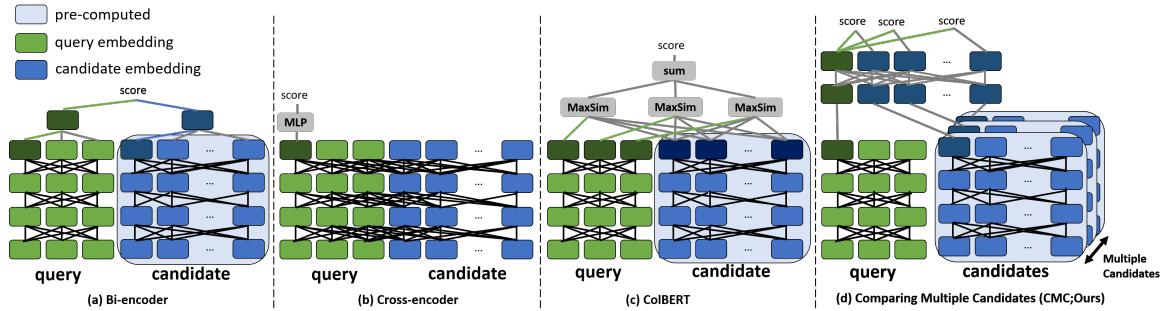
如上图 Figure 1 所示:
- (a) 双编码器 (Bi-Encoder): 快速,独立处理。
- (b) 交叉编码器 (Cross-Encoder): 慢速,深度交互。
- (c) 延迟交互 (Late Interaction, 如 ColBERT): 更好,但需要存储大量的标记嵌入索引。
- (d) CMC (本文方法): 提议的方法。注意查询是如何在共享空间中同时与多个候选项 (蓝色块) 交互的。
核心方法: 共同比较邻居
研究人员提出了 CMC (Comparing Multiple Candidates,多候选项比较) 。 其核心洞察简单而深刻: 当我们能够并排比较选项时,我们能做出更好的决策。
标准模型孤立地看待 (查询, 候选项) 对。CMC 则查看 (查询, 候选项 1, 候选项 2, …, 候选项 K) 集合。它使用轻量级的自注意力机制让候选项与查询交互,同时也与其他候选项交互。
1. 编码输入
首先,CMC 使用标准编码器将查询和候选项转换为向量表示 (嵌入) 。关键在于,候选项嵌入是预计算的。这保持了双编码器的效率,因为我们不需要在运行时重新编码数百万文档的文本。
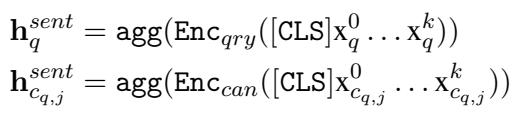
在这里,Enc 代表一个 Transformer 编码器 (如 BERT) 。我们取 [CLS] 标记 (代表整个句子的特殊标记) 来获取查询 (\(h_q\)) 和每个候选项 (\(h_c\)) 的单一向量。
2. 自注意力层
这正是神奇之处。CMC 不是立即计算分数,而是将查询嵌入与 \(K\) 个候选项嵌入的列表拼接起来。它将这个序列输入到一个浅层的 Transformer 块 (仅 2 层) 中。

在这个公式中:
- 输入是一个向量序列:
[Query, Cand_1, Cand_2, ..., Cand_K]。 - 自注意力 (Self-Attention) 机制允许模型根据候选项更新查询的表示,并根据其他候选项更新每个候选项的表示。
这种上下文交互非常强大。如果两个候选项语义相似,注意力机制可以突出细微的差别,从而确定哪一个更适合该查询。
3. 评分
在自注意力层之后,我们得到了“语境化”的嵌入。然后,我们只需计算更新后的查询向量与更新后的候选项向量之间的点积,即可找到最佳匹配。
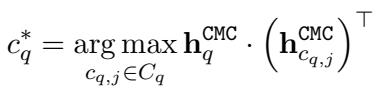
完整架构
让我们把整个过程可视化。
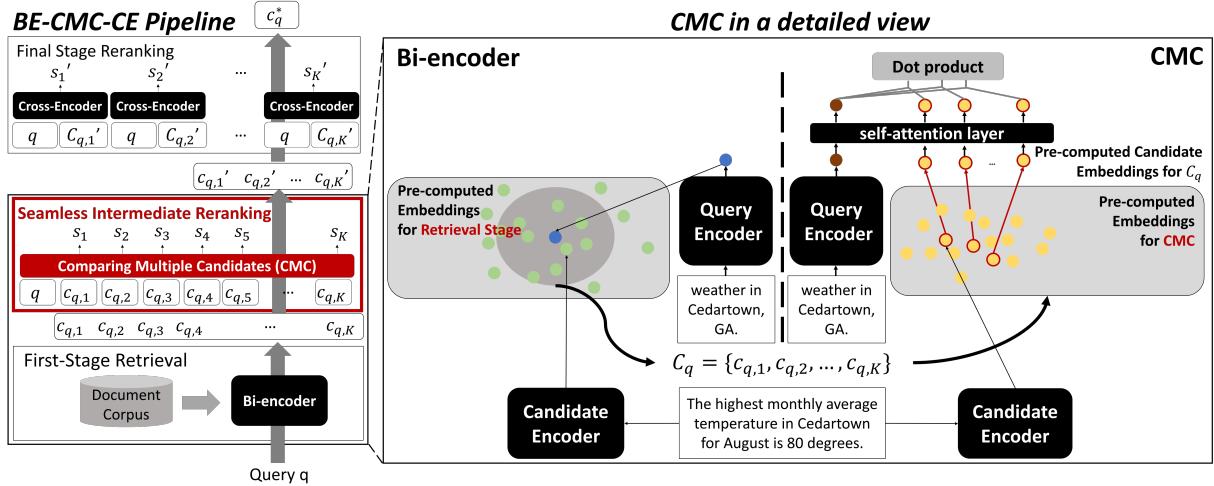
Figure 2 展示了流程:
- 检索 (Retrieve): 标准双编码器检索出一组潜在候选项。
- CMC: 获取这些候选项的预计算嵌入。
- 处理 (Process): 查询向量和这些候选项向量作为输入进入 CMC Transformer。
- 输出 (Output): 一个优化后的、重新排序的列表。
因为候选项嵌入只是单一向量 (不像 ColBERT 那样是完整的标记列表) ,内存占用极小。又因为 Transformer 很浅且成批处理输入,速度非常快。
训练模型
为了教会 CMC 如何区分好坏候选项,研究人员使用了一种损失函数,结合了标准分类准确率与“蒸馏”——这意味着它还试图从原始检索器的概率分布中学习。
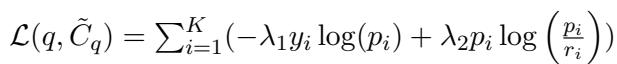
公式的第一部分 (\(\lambda_1\)) 是标准的交叉熵损失 (寻找正确答案) 。第二部分 (\(\lambda_2\)) 使用 KL 散度来确保模型不会偏离原始检索器的逻辑太远,起到正则化的作用。
困难负样本采样 (Hard Negative Sampling) 为了使模型具有鲁棒性,不能只给它看简单的例子。研究人员使用了“困难负样本”——即根据双编码器判断看起来与查询非常相似但不正确的候选项。
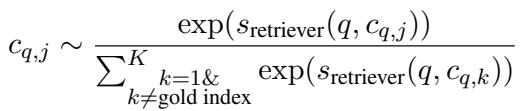
通过强迫模型区分正确答案和这些“棘手”的错误答案,CMC 学会了细粒度的区分。
“无缝”中间重排序器
CMC 最引人注目的用例之一是将其插入到现有流水线的中间。
目前,我们有: 双编码器 \(\to\) 交叉编码器 。 提议变为: 双编码器 \(\to\) CMC \(\to\) 交叉编码器 。
为什么要增加一步?那不会变慢吗?令人惊讶的是,并不会。
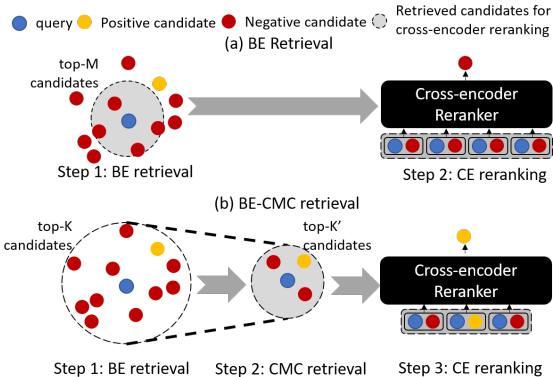
如 Figure 3 所示:
- (a) 标准模式: 双编码器检索 \(M\) 个候选项。交叉编码器太慢,只能处理这 \(M\) 个。如果答案不在 \(M\) 中,你就输了。
- (b) 使用 CMC: 双编码器检索一个大得多的集合 \(K\)。CMC 足够快,可以处理所有 \(K\) 个候选项,并将它们过滤到最好的 \(K'\) 个 (其中 \(K' \approx M\)) 。
交叉编码器仍然只需要处理少量的候选项,但这些候选项的质量要高得多 , 因为它们经过了 CMC 的预筛选。你捕捉到了双编码器可能会错过的“金子”,且没有拖慢最终的排名速度。
实验结果
研究人员在几个具有挑战性的数据集上测试了 CMC,包括 ZeSHEL (零样本实体链接) 和 MS MARCO (段落排序) 。
1. 更好的检索性能
当作为检索器 (或中间重排序器) 时,CMC 真的能找到更好的文档吗?
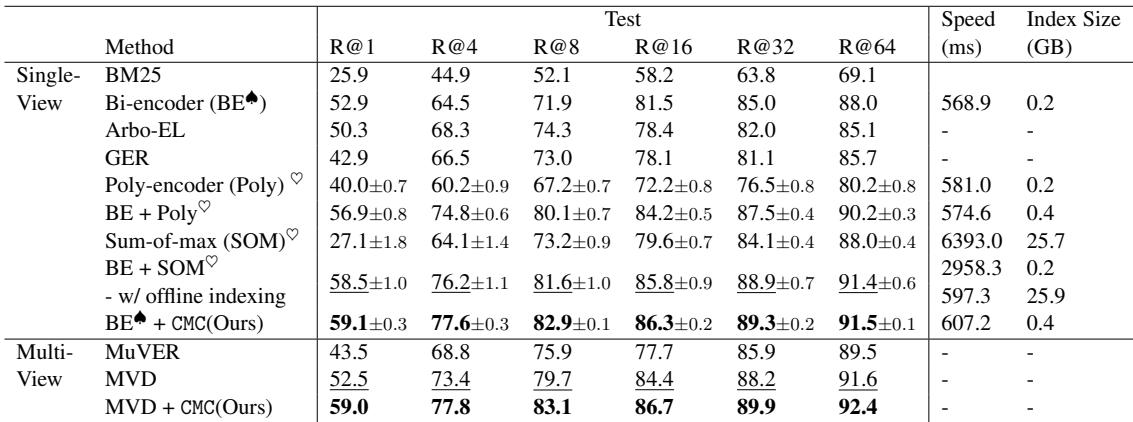
Table 1 展示了 ZeSHEL 上的结果。
- 看 Recall@64 (R@64)。标准双编码器达到 88.0% 。
- CMC 将其推高至 91.5% 。
- 它优于其他复杂方法,如 Poly-encoder 和 Sum-of-max。
- 关键在于,看 Index Size (索引大小) 。 Sum-of-max 需要 25.7 GB 的存储空间。CMC 只需要 0.4 GB——这与标准双编码器大致相同。
2. 速度与可扩展性
文章声称 CMC 是“共同比较邻居”。这具有可扩展性吗?
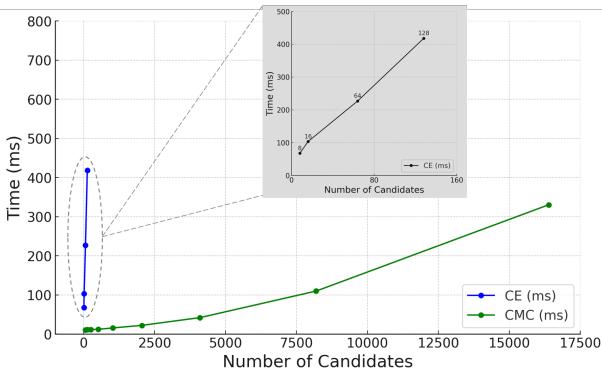
Figure 4 可能是论文中最重要的一张图表。
- 蓝线 (交叉编码器) 垂直飙升。仅处理几百个候选项就需要数百毫秒。
- 绿线 (CMC) 几乎是平的。它处理 10,000 个候选项的时间与交叉编码器处理 16 个的时间大致相同。
这种极高的效率使得“中间重排序”策略成为可能。
3. 跨任务的通用性
CMC 不仅仅适用于实体链接。它也适用于段落排序和对话系统。
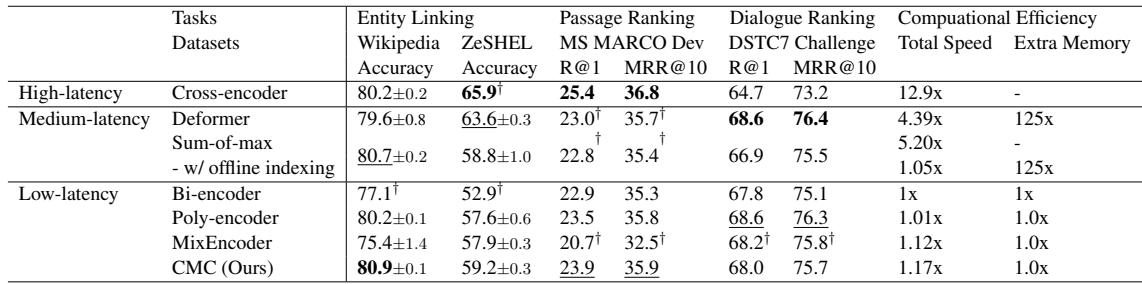
Table 3 将 CMC 与高延迟 (交叉编码器) 、中延迟和低延迟模型进行了比较。
- 在 实体链接 中,CMC 实际上优于交叉编码器 (80.9 vs 80.2),尽管它的速度快了 11 倍。
- 在 对话排序 (DSTC7) 中,它也显著击败了交叉编码器 (68.0 vs 64.7)。
- 在 段落排序 中,它在保持双编码器速度特性的同时,与更重的模型保持了竞争力。
4. 初始化的重要性
消融实验中一个有趣的发现是“迁移学习”的影响。
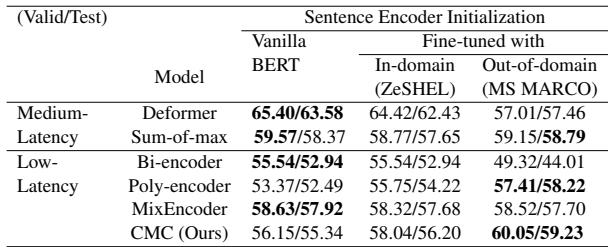
Table 4 显示,使用在不同领域 (如 MS MARCO) 上微调过的权重来初始化编码器,有助于提高在 ZeSHEL 上的性能。这表明 CMC 受益于作为起点的稳健、通用的句子嵌入。
结论
“多候选项比较” (CMC) 框架为信息检索中的经典权衡提供了一个优雅的解决方案。通过将视角从“这个文档匹配这个查询吗?”转变为“在这些竞争者中,哪个文档最匹配这个查询?”,CMC 达到了媲美沉重交叉编码器的精度水平。
然而,它真正的优势在于效率 。 通过利用预计算的嵌入和浅层自注意力,它保持了双编码器的极快速度。
对于构建搜索系统的学生和从业者来说,CMC 提供了两条路径:
- 加速器: 用 CMC 替换你缓慢的交叉编码器,使系统速度提高 10 倍,而精度损失极小。
- 增强器: 在交叉编码器之前插入 CMC,以过滤海量候选项池,提高召回率并捕捉简单向量搜索遗漏的困难答案。
在数据量爆炸的世界里,像 CMC 这样联合比较邻居的方法很可能会成为高效、高性能检索的新标准。