](https://deep-paper.org/en/paper/2405.13131/images/cover.png)
大型语言模型 (LLM) 彻底改变了我们与信息交互的方式。我们要它们写代码、解数学题,以及解释复杂的历史事件。然而,任何深入使用过这些模型的人都知道它们有一个明显的弱点: 幻觉 (hallucination) 。 它们在陈述完全错误的事实时,语气可能听起来无比自信。
近年来,研究人员开发了许多巧妙的方法来缓解这个问题。一种流行的方法是“一致性检查 (consistency checking) ”——即多次询问模型同一个问题,并选择出现频率最高的答案。这对于答案是单个数字的数学问题非常有效。但是,当你问一个长文本问题时会发生什么呢?比如,“气候主要变化的原因是什么?”
答案不是单个数字,而是一个包含多个不同事实的段落。如果你生成十个不同的段落,没有哪两个是逐字逐句完全相同的。这种情况下,你该如何检查一致性?
在这篇文章中,我们将深入探讨一篇引人入胜的论文,题为 “Atomic Self-Consistency for Better Long Form Generations” (用于优化长文本生成的原子自洽性) 。 研究人员提出了一种名为“原子自洽性” (Atomic Self-Consistency, ASC) 的新方法。ASC 不再试图挑选单个“最佳”的生成回答,而是将多个回答分解为“原子”部分 (事实) ,识别哪些事实在样本中一致出现,然后将它们缝合成一个新的、更优质的答案。
问题所在: 长文本问答中的精确率与召回率
当 LLM 生成长篇回答时,其质量由两点定义:
- 精确率 (Precision) : 提供的信息是否真实? (避免幻觉) 。
- 召回率 (Recall) : 模型是否包含了所有相关信息?
目前修复幻觉的方法通常过度关注精确率。它们可能会过滤掉任何看起来可疑的内容,留下一个非常简短、安全的答案。然而,一个好的答案应该是全面的。
以此论文中的例子为例:

在 图 1 中,答案 \(A_1\) 是精确的——它列出了人类活动。但答案 \(A_2\) 更好,因为它的 召回率 更高;它既包含了人类活动,也包含了自然因素。
现有的最先进方法,如 通用自洽性 (Universal Self-Consistency, USC) , 其运作方式是生成多个回答并试图选出唯一最一致的那个。这种方法的缺陷显而易见: 如果“最佳”回答错过了一个存在于“第二佳”回答中的关键事实怎么办?只选一个赢家,意味着我们放弃了有价值的信息。
动机: 融合优于选择
这项研究的核心假设是: 融合不同答案的部分优于仅选择其中一个。
为了在构建方法之前证明这一潜力,研究人员分析了在 ASQA 数据集上的“Oracle”性能 (即理论上的最佳性能) 。他们比较了挑选单个最佳样本与融合多个样本子部分的性能上限。
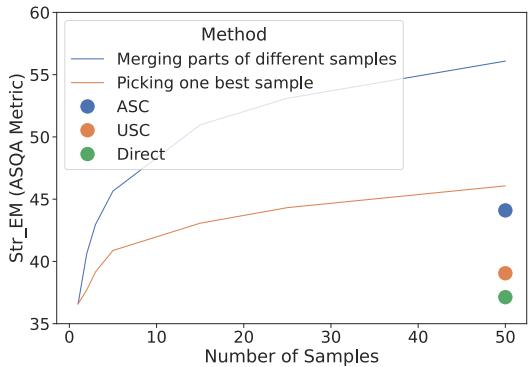
如 图 2 所示,蓝色虚线 (“融合部分”) 创造了比橙色线 (“挑选单个最佳样本”) 高得多的性能上限。这两条线之间的差距代表了通过组合知识可以挖掘的未开发潜力。
这一洞察推动了 原子自洽性 (ASC) 的开发。其目标是创建一个不仅仅是评判答案,而是能主动合成答案的系统。
核心方法: 原子自洽性 (ASC)
那么,ASC 实际上是如何工作的呢?该过程的灵感来自于这样一个想法: 如果 LLM 在多个独立的生成中都提到了某个特定的事实 (一个“原子”) ,那么这个事实很可能是真的。如果一个事实在 50 次生成中只出现了一次,那它很可能是幻觉。
ASC 流程包含四个不同的步骤: 拆分、聚类、过滤和摘要 。
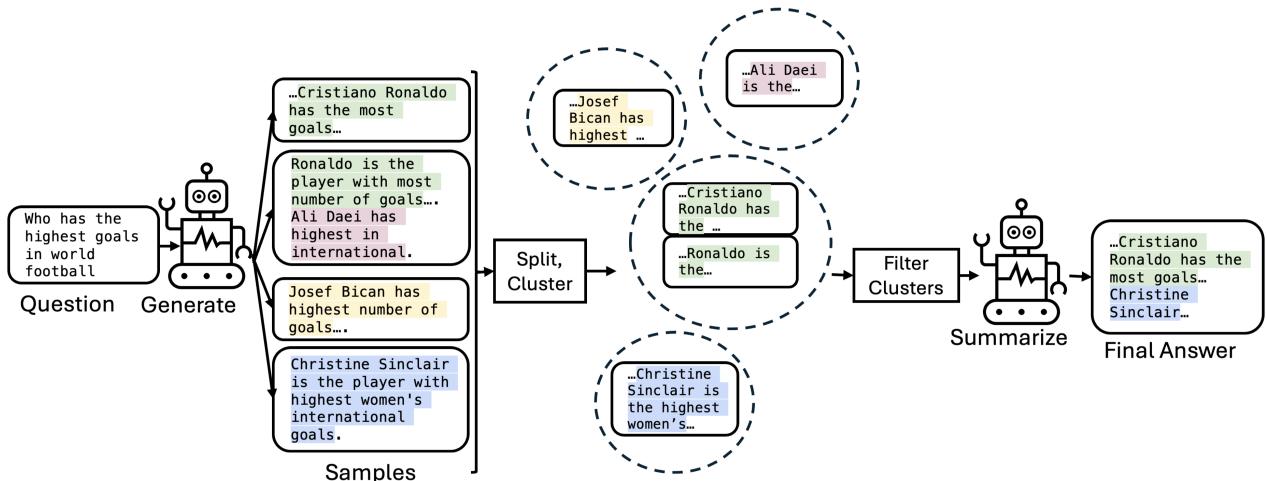
让我们分解 图 3 中展示的流程:
第一步: 生成与拆分 (原子化)
首先,系统提示 LLM 多次回答同一个问题 (例如,\(m=50\) 个样本) 。 ASC 不将这 50 个段落视为整体块,而是将它们拆分为组成部分。在这篇论文中,研究人员将单个句子视为“原子事实”。
- *输入: * “世界足坛进球最多的人是谁?”
- *生成: * 50 个关于 C 罗、比坎、辛克莱尔等人的不同段落。
- *拆分: * 系统将这些段落分解为数百个单独的句子。
第二步: 聚类
现在系统拥有数百个句子的集合。其中许多句子用不同的词表达了相同的意思 (例如,“C 罗进球最多”与“克里斯蒂亚诺·罗纳尔多是最佳射手”) 。 ASC 使用聚类算法 (具体是使用句子嵌入的凝聚层次聚类) 将这些语义相似的句子分组在一起。
- *结果: * 一个关于“C 罗”事实的聚类,一个关于“辛克莱尔”事实的聚类,也许还有一个关于某个随机球员的包含幻觉事实的小聚类。
第三步: 过滤 (一致性检查)
这是神奇的一步。研究人员使用 聚类一致性 作为正确性的代理指标。
- 如果一个聚类很大 (包含来自不同样本的许多句子) ,它就具有 高一致性强度 。 模型对这个事实很有信心。
- 如果一个聚类很小 (包含的句子很少) ,它的 强度就低 。 这很可能是幻觉或无关的噪音。
系统应用一个阈值 (\(\Theta\)) 。任何大小低于此阈值的聚类都会被丢弃。每个幸存聚类中最长的句子被保留作为“代表”。
第四步: 摘要
最后,我们得到了一份经过验证的高一致性事实 (代表) 列表。但一堆不连贯的句子算不上是一篇好的博客文章或答案。 ASC 将这些选定的句子反馈给 LLM,并提示它将它们 摘要 成一个连贯的答案。这就创建了一个最终的回复,它结合了所有 50 个原始生成中的精华部分,同时过滤掉了噪音。
实验结果
这种复杂的融合过程真的比简单地让 LLM “选出最好的一个”要好吗?研究人员在四个不同的数据集上测试了 ASC:
- ASQA: 具有长且模棱两可答案的事实类问题。
- QAMPARI: 列表式问题 (例如,“列出某人导演的电影……”) 。
- QUEST: 另一个高难度的列表式数据集。
- ELI5: “像我五岁一样解释” (开放式解释) 。
他们将 ASC 与以下方法进行了比较:
- Direct: LLM 的标准输出。
- USC (通用自洽性) : 选择单个最一致的完整回复。
- ASC-F: 使用基于检索的事实核查而非自洽性的 ASC 变体。
性能分析
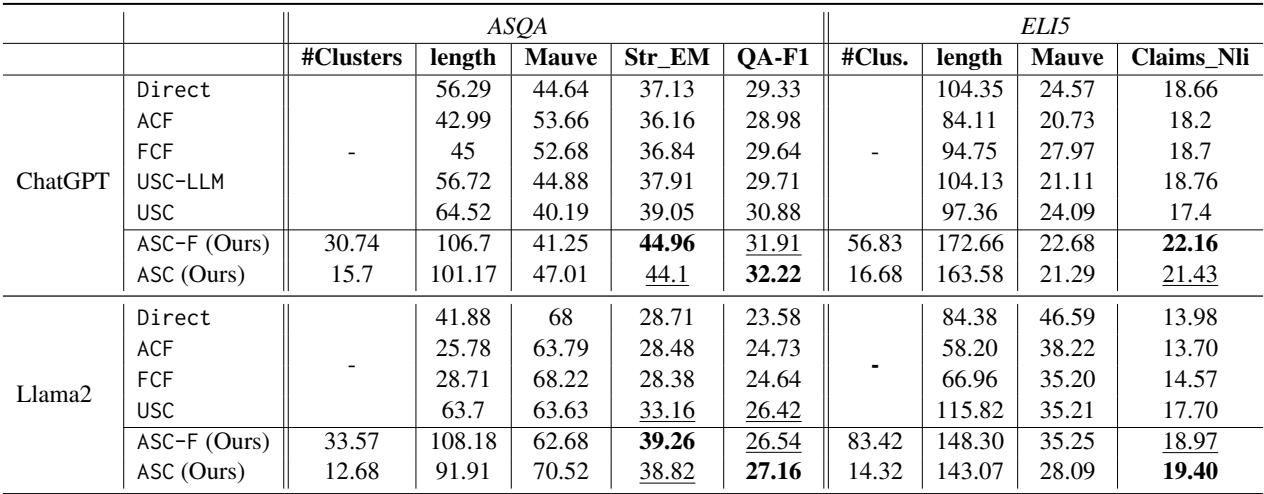
表 1 重点展示了 ASQA 和 ELI5 上的结果。这些指标告诉我们:
- Str_EM (精确匹配) : ASC 的得分显著高于 Direct 和 USC。这表明对特定参考答案的召回率更高。
- QA-F1: 这衡量了答案能在多大程度上让 QA 模型检索到正确信息。ASC 再次超越了基线。
- Mauve: 这衡量文本的人类相似度和流畅度。ASC 取得了很高的 Mauve 分数,表明将句子缝合在一起并没有产生文本“弗兰肯斯坦 (缝合怪) ”;摘要步骤有效地使其变得平滑。
结果证实了 融合多个样本的子部分比挑选单个样本的效果要好得多。
敏感性: 调节 \(\Theta\) 的力量
ASC 最强大的功能之一是其灵活性。阈值 \(\Theta\) (一个聚类需要多大才能幸存) 充当了输出风格的控制旋钮。
- 低 \(\Theta\): 你允许更多的聚类进入。这增加了 召回率 (你得到更多事实) ,但可能会降低 精确率 (一些错误事实可能会混入) 。这也会使答案变长。
- 高 \(\Theta\): 你非常严格。只有重复次数最多的事实才能幸存。这增加了 精确率 和 流畅度 (Mauve 分数) ,但可能会错过细节。
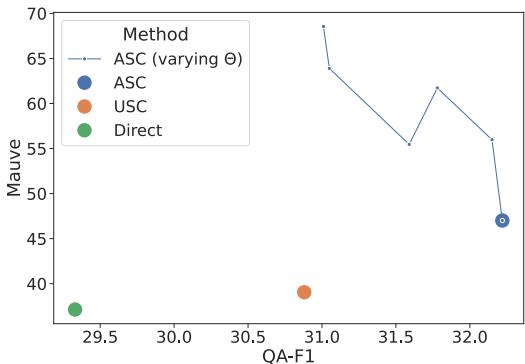
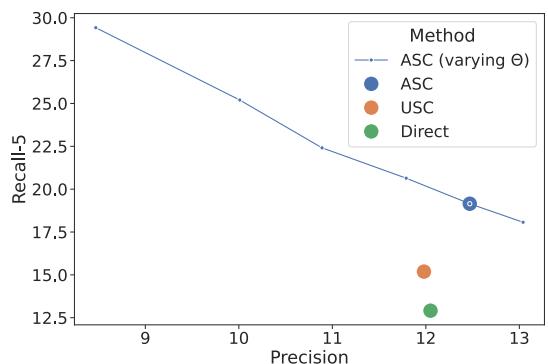
图 4 展示了在 ASQA 数据集上的这种权衡。通过调整阈值,你可以优化出高度流畅、精确的答案 (高 Mauve) ,或者高度详细、全面的答案 (高 QA-F1) 。这种控制级别是标准提示工程或简单选择方法无法实现的。
同样的趋势也出现在像 QAMPARI 这样的列表式数据集中,如下面的 图 6 所示。增加阈值会极大地提高精确率 (确保列表上的每一项都是正确的) ,但代价是召回率降低 (列表可能会变短) 。
效率: 我们真的需要 50 个样本吗?
从 LLM 生成 50 个完整的回复在计算上既昂贵又缓慢。研究人员提出的一个关键问题是: 我们可以早点停止吗?
他们分析了聚类的 熵 (entropy) 。 熵是无序或不可预测性的度量。当你生成最初的几个样本时,新的聚类不断形成,熵会上升。然而,在一定数量的样本之后,“事实”开始重复。聚类只是变得更大,但新的聚类不再出现。
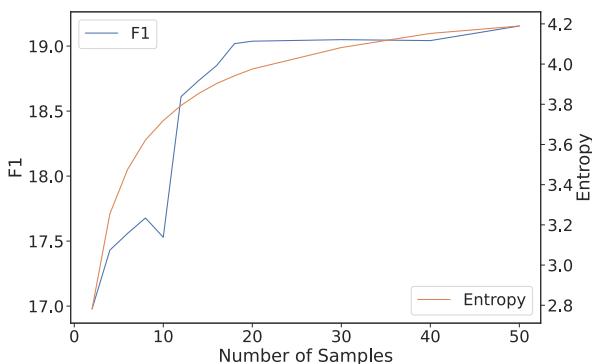
图 5 揭示了一个重要的相关性。蓝线 (F1 分数) 大致在橙线 (熵) 趋于稳定的同时开始进入平台期。 这暗示了一个实用的优化方案: 系统可以实时监控聚类的熵,一旦熵变平,就停止生成新样本。这可以在保留 ASC 大部分优势的同时节省大量的算力。
结论与未来展望
论文 “Atomic Self-Consistency for Better Long Form Generations” 标志着我们关于提高 LLM 可靠性思维方式的转变。它让我们从“生成完美的答案”转向“从多次尝试中合成真相”。
主要收获:
- 不要满足于一个: 融合多个生成样本的相关部分比试图找到单个最佳样本能产生更好的结果。
- 一致性是关键: 如果一个 LLM 用 10 种不同的方式说同一件事,那这事很可能是真的。在“原子” (句子) 级别衡量这种一致性比在文档级别更细粒度且更有效。
- 可控性: 该方法提供了一个可调参数 (\(\Theta\)) 来平衡全面性 (高召回率) 与安全性/流畅性 (高精确率) 之间的权衡。
也许最令人兴奋的是前面展示的“Oracle”分析。虽然 ASC 相比现有方法有了显著改进,但它仍未达到通过融合样本所能实现的理论上限。LLM 生成的数据中仍有“未开发的潜力”。未来的工作若能将 ASC 与外部验证 (如通过谷歌搜索核查事实) 相结合,可能会进一步提升 LLM 的可靠性。
对于学生和从业者来说,ASC 证明了我们不仅可以将 LLM 视为作家,还可以将其视为原始数据的来源——只要有正确的算法,就可以从中挖掘出真相。