](https://deep-paper.org/en/paper/2405.13816/images/cover.png)
像 GPT-4、LLaMA 和 Mistral 这样的大语言模型 (LLM) 已经彻底改变了自然语言处理领域。如果你说英语,这些工具感觉简直像魔法一样。然而,如果你切换到一种低资源语言——比如斯瓦希里语或孟加拉语——这种“魔法”往往就会消失。高资源语言 (如英语和中文) 与低资源语言之间的性能差距,仍然是 AI 公平性面临的一个巨大障碍。
传统上,解决这个问题需要海量的多语言训练数据或复杂的翻译流程。但是,如果 LLM 实际上已经知道如何处理这些语言,只是我们没有正确地询问它们呢?
在论文 “Getting More from Less: Large Language Models are Good Spontaneous Multilingual Learners” 中,来自南京大学和中国移动研究院的研究人员揭示了一个迷人的现象。他们发现,通过在一个简单的翻译任务上训练 LLM,且该任务仅使用几种语言的问题 (不包含答案) ,模型就能“自发地”提高其在广泛的其他语言上的表现——即使是那些它未经过专门微调的语言。
本文将带你深入了解他们的方法、“问题对齐” (Question Alignment) 范式,以及解释模型如何跨语言“思考”的机械可解释性 (Mechanistic Interpretability) 。
问题所在: 多语言差距
大多数开源 LLM 都是“以英语为中心”的。如下方 LLaMA 2 的训练数据分布所示,英语在语料库中占据主导地位 (接近 90%) ,而其他语言仅占百分之几甚至更少。
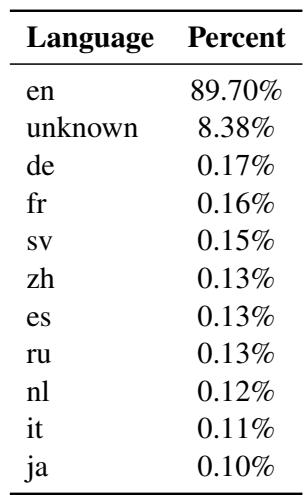
由于这种不平衡,LLM 在处理低资源语言任务时非常吃力。标准的解决方案是指令微调 (Instruction Tuning) , 即在包含各种语言的提示和答案的数据集上微调模型。然而,为每种语言创建高质量的人工标注数据集既昂贵又缓慢。
另一种方法是翻译-测试 (Translate-Test) 法: 将用户的提示翻译成英语,让 LLM 解决,然后再将答案翻译回来。虽然有效,但这很繁琐,且严重依赖外部翻译系统。
研究人员提出了第三种途径: 问题对齐 (Question Alignment) 。 他们假设 LLM 在预训练期间就获得了多语言能力,但这些能力处于休眠状态。它们只需要轻轻“推”一下就能被对齐。
核心方法: 问题对齐
这篇论文的核心贡献是一种无需下游任务标注答案即可提高多语言性能的方法。这一点至关重要,因为它意味着我们不需要昂贵的“QA 对” (问题-答案) 来教导模型。我们只需要问题。
流程
这个过程出奇地优雅。研究人员选取一个特定任务 (如情感分类) ,剥离掉答案,只保留输入的问题。然后,他们创建一个平行数据集,将这些问题从源语言翻译成目标语言 (通常是英语) 。
让我们分解一下正式定义。首先,我们定义一个语言全集:
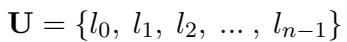
在这里,\(l_0\) 通常代表英语。研究人员选择一小部分源语言 (例如中文和德语) 和一个目标语言 (例如英语) 。他们构建了一个平行问题数据集 \((q_s, q_t)\),其中 \(q_s\) 是源语言的问题,\(q_t\) 是目标语言的翻译。
关键在于,模型并没有被训练去解决任务 (例如分类情感) 。它只是被训练去翻译问题。
训练目标是最小化这个翻译任务的损失:

这个公式代表了标准的指令微调 (使用 LoRA,即低秩适应) ,其中模型参数 \(\theta\) 被更新,以最大化在给定输入 \(q_s\) 的情况下生成翻译问题 \(q_t\) 的概率。
经过这个训练阶段后,我们得到了一组新的参数:
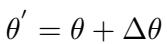
测试“自发”提升
一旦模型在这个简单的翻译任务上进行了微调,研究人员就会在全集中的所有语言上测试它在实际下游任务 (如情感分析) 上的表现——包括那些模型在微调阶段从未见过翻译数据的语言。
他们使用准确率 (Accuracy) 来衡量成功与否。对于特定语言 \(l\),准确率定义为:
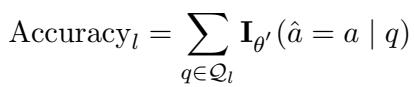
全局准确率则是所有测试语言的平均值:
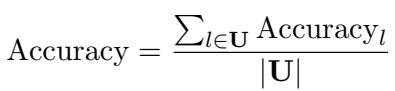
假设是,通过强制模型将语言 A 的问题对齐到英语,它学会了一种通用的对齐技能,这种技能可以“解锁”它处理语言 B、C 和 D 的能力,即使它在这个微调阶段从未见过这些语言的翻译数据。
实验与关键结果
研究人员在两个主要的模型系列上测试了这种方法: Mistral (7B) (以英语为中心) 和 Qwen1.5 (1.8B 到 14B) (具有更强的多语言基线) 。他们使用了三个不同的任务:
- 情感分类: (Amazon Reviews Polarity)
- 自然语言推理 (NLI): (SNLI)
- 复述识别: (PAWS)
结果 1: 未见语言上的显著提升
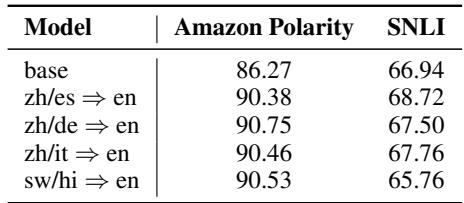
Mistral-7B 模型上的结果令人震惊。在下表中,“Base”行显示了原始模型的性能。随后的行显示了在特定语言翻译对上微调后的性能 (例如,zh => en 意味着中文到英语) 。
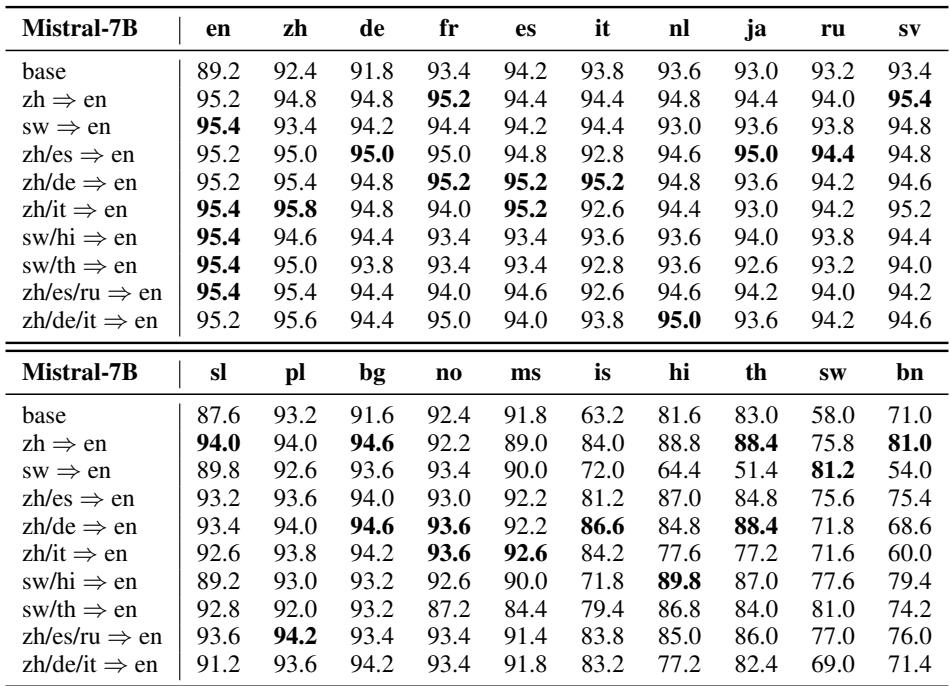
在这个表格中需要关注的点:
- 广泛的泛化性: 看一下斯瓦希里语 (
sw) 或印地语 (hi) 这一列。基座模型表现挣扎 (例如sw只有 58.0%) 。然而,当模型在中文到英语的翻译任务 (zh => en) 上训练后,斯瓦希里语的性能跃升至 75.8%。模型在微调期间从未见过斯瓦希里语,但它却显著进步了。 - 高资源语言是好的引导者: 在高资源语言 (如中文、德语或西班牙语) 上进行训练,通常比在低资源语言上训练能带来更好的整体效果。
- 高效性: 你不需要在所有语言上进行训练。仅在混合了 2 或 3 种语言 (例如
zh/es => en) 的数据上训练,就能在所有 20 种测试语言上带来巨大的收益。
结果 2: 跨模型尺寸的扩展性
为了确保这不是 Mistral 特有的偶然现象,他们在不同参数量 (1.8B, 4B, 和 14B) 的 Qwen1.5 系列上进行了测试。
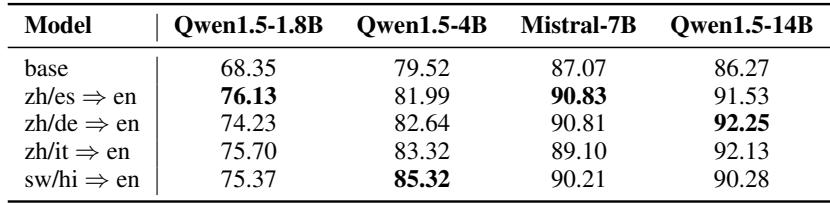
如上所示,这种提升是一致的。即使是较小的模型 (1.8B) ,在使用中文/西班牙语到英语的数据对齐后,性能也有了飞跃 (从 68.35% 到 76.13%) 。这证明了该方法在不同模型架构和尺寸上的鲁棒性。
结果 3: 英语不是唯一的终点
多语言 NLP 中一个常见的批评是,一切都依赖英语作为“枢纽”语言。研究人员提出了一个问题: 目标语言必须是英语吗?
他们使用中文作为翻译的目标语言 (例如,将日语翻译成中文) 重复了实验。
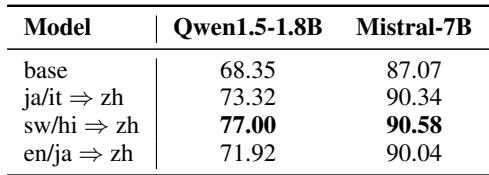
结果呢?效果一样好。无论是对齐到英语还是中文,对齐过程都增强了模型的通用多语言推理能力。这表明提升来自于对齐过程本身,而不仅仅是将一切映射到英语。
结果 4: 数据分布很重要
研究人员还调查了数据类型是否重要。如果我们希望模型擅长情感分析,我们是否应该训练它翻译情感分析的问题?
答案是肯定的。表 5 显示,虽然任何翻译训练都有帮助,但在与测试任务具有相同分布的数据上进行训练 (例如,训练 Amazon Polarity 问题以测试 Amazon Polarity 任务) 会产生最佳结果。这符合“表面对齐假说 (Superficial Alignment Hypothesis) ”——即模型在对齐过程中创建了一种“格式子分布”,它可以在推理过程中利用这种分布。
窥探“黑盒”内部
为什么这行得通?研究人员采用了机械可解释性 (Mechanistic Interpretability) 技术来可视化模型神经网络层内部发生的情况。
“Logit 透镜” (Logit Lens)
“Logit Lens”是一种技术,我们将模型在中间层的内部状态投影到词汇表上,看看如果模型就在那一刻停止,它会预测什么词。
研究人员发现,LLM 经常用英语“思考”。当给出一个非英语语言的提示时,模型会在其中间层将其翻译成抽象的英语表示,然后再将其翻译回目标语言作为最终输出。
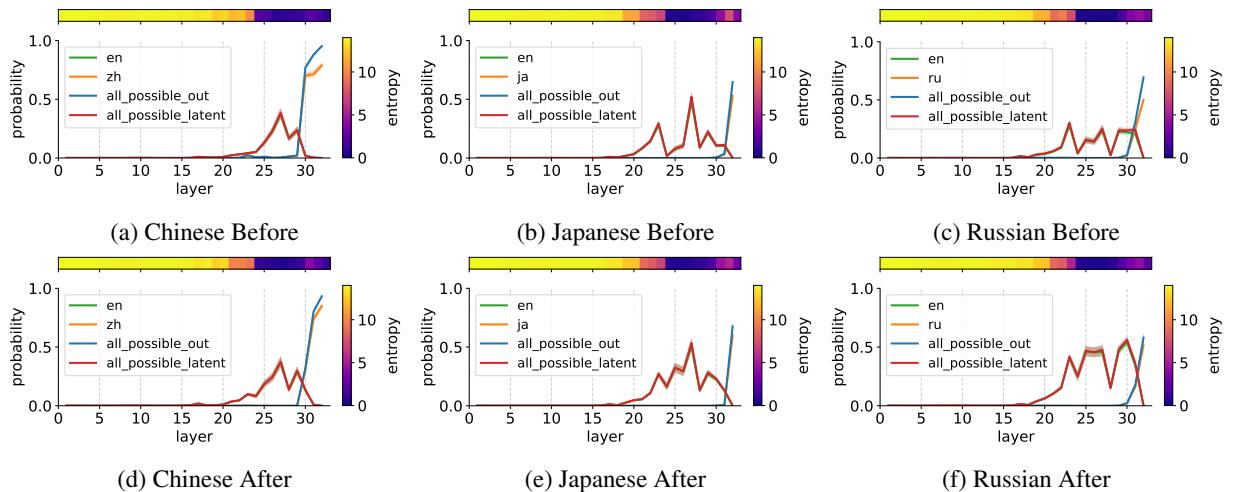
分析图 1:
- 第一行 (训练前) : 在基座模型中,正确答案 (橙色) 的概率很低且不稳定。
- 第二行 (训练后) : 在翻译数据上训练后,请看红色区域 。 这代表“潜在的英语输出 (Latent English Output) ”。模型在中间层 (大约第 20-30 层) 为答案的英语版本建立了很强的概率。
- 结论: 训练过程加强了这种内部的“英语枢纽”机制。模型在将输入语言映射到其内部英语表示、执行推理、然后生成正确输出方面变得更加自信。
主成分分析 (PCA)
为了进一步可视化这一点,研究人员使用 PCA 将模型的高维内部状态映射到 2D 图中。他们比较了训练前后不同语言 (英语、德语、法语、印地语) 在模型层中的表示方式。
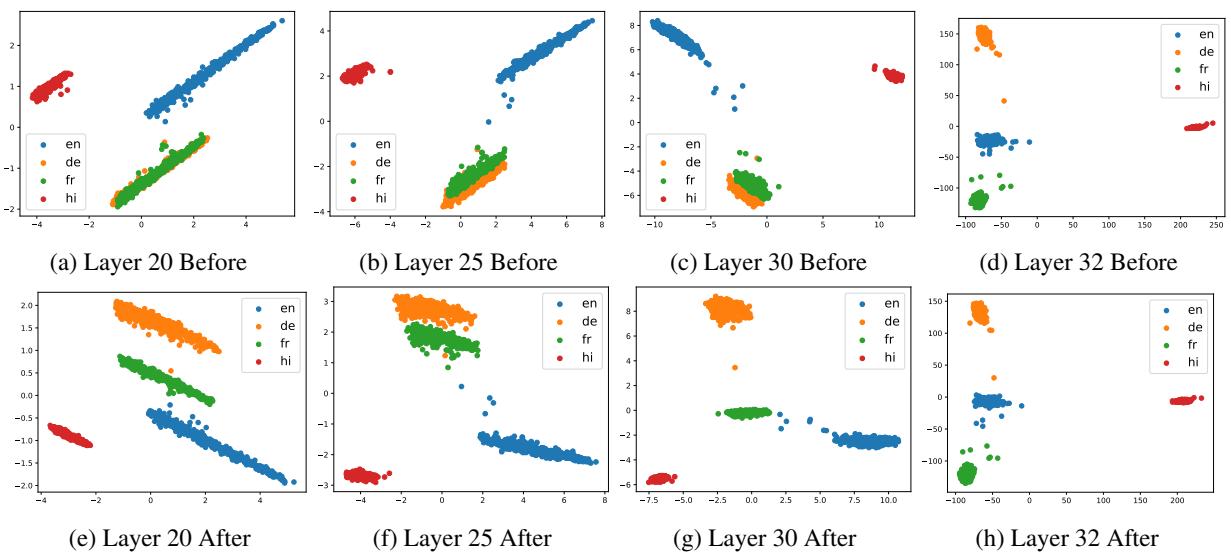
分析图 2:
- 之前 (第一行) : 在早期层中,各种语言有些混合。
- 之后 (第二行) : 看一下底部图表中清晰的分离。每种语言的“簇” (颜色) 变得清晰且组织良好。
- 解缠 (Disentanglement) : 训练使得模型能够在其内部空间中更好地“解缠”各种语言。矛盾的是,虽然语言变得更加清晰,但它们与英语的相关性却增加了 (如论文中的皮尔逊相关性测试所示) ,这表明它们被更好地映射到了模型的中心推理核心。
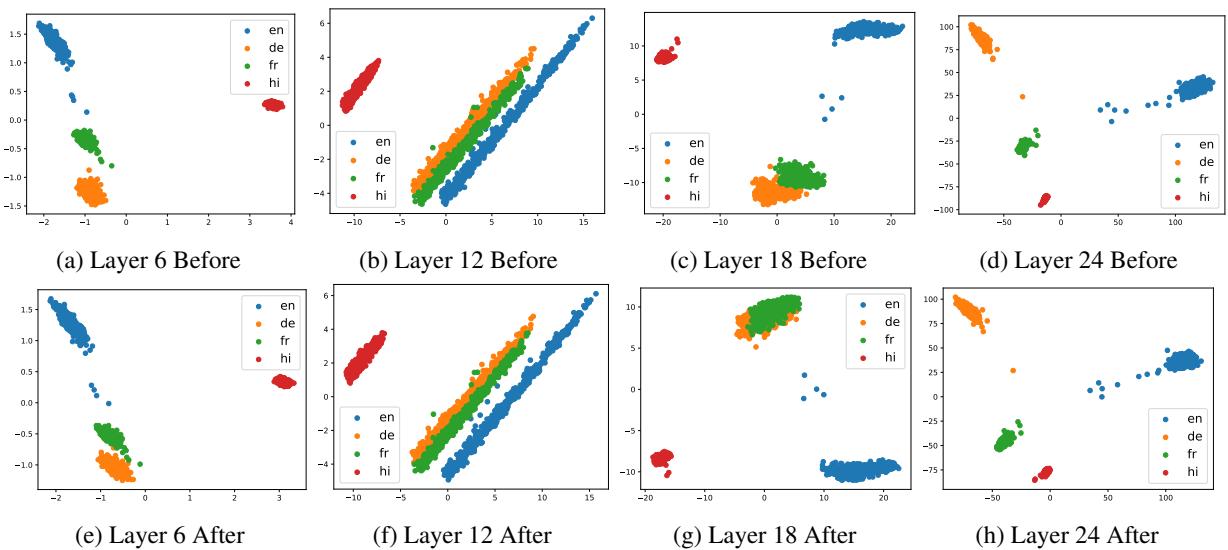
他们还证实了这种模式同样适用于非英语中心的模型,如 Qwen1.5,证明这是大语言模型的一个普遍属性。
结论
论文 “Getting More from Less” 为多语言 AI 的未来提供了一个令人信服的叙述。它挑战了我们需要为想要支持的每种语言提供大量标注数据集的假设。
关键要点:
- 自发学习: 仅在几种语言上训练 LLM 翻译问题 (无答案) ,就能触发其在其他数十种语言上的推理能力的“自发”提升。
- 潜在推理: 这背后的机制似乎是加强了模型的内部“枢纽” (通常是英语或其他高资源语言) 。模型在内部翻译概念,进行推理,然后再翻译回来。
- 高效性: 这种“问题对齐”范式非常高效。它避免了对特定任务标签的需求,并利用了“表面对齐假说”——即模型已经拥有了预训练中的知识,只需要被教导如何访问它。
这项研究表明,通往真正通用语言模型的道路可能不是由更多的数据铺就的,而是由更智能、更高效的对齐策略铺就的,这些策略能够解锁隐藏在权重中的潜力。