](https://deep-paper.org/en/paper/2405.15028/images/cover.png)
搜索引擎已经发生了巨大的演变,但它们经常遭受“分辨率”问题的困扰。想象一下你在大海捞针。大多数现代检索系统非常擅长把干草堆 (文档或段落) 交给你,但如果不进行昂贵的重新索引,它们很难精确定位那根针 (特定的句子或事实) 。
在信息检索 (IR) 领域,这被称为粒度问题。你是按文档索引数据?按段落?还是按句子?通常,你必须选择一个粒度层级并坚持下去。如果你选择段落,查找特定句子就会变得困难。如果你选择句子,就会失去段落的更广泛上下文。
在这篇文章中,我们将深入探讨一篇引人入胜的论文,题为 “AGRAME: Any-Granularity Ranking with Multi-Vector Embeddings” (AGRAME: 基于多向量嵌入的任意粒度排序) 。 研究人员提出了一个巧妙的解决方案,允许模型在粗粒度层级 (如段落) 索引数据,但能有效地在任意粒度层级 (如句子或原子事实) 对结果进行排序。
问题所在: 粒度的僵化
要理解 AGRAME,我们首先需要看看现代“稠密检索” (Dense Retrieval) 是如何工作的。
在标准方法中,我们使用像 BERT 这样的模型将文本转换为数字 (向量) 。
- 单向量模型 (例如 DPR, Contriever) : 这些模型将整个段落压缩成一个单一向量。虽然速度快,但这种压缩是“有损”的。它模糊了微小的细节,使得检索特定的子句事实变得困难。
- 多向量模型 (例如 ColBERT) : 这些模型为文本中的每个 Token (词) 保留一个向量。这保留了更多细节,但传统上用于对它所编码的同一单元进行排序 (即: 编码段落,对段落排序) 。
研究人员发现了一个空白。如果我们想使用为段落构建的系统来检索句子或命题 (原子事实) 怎么办?
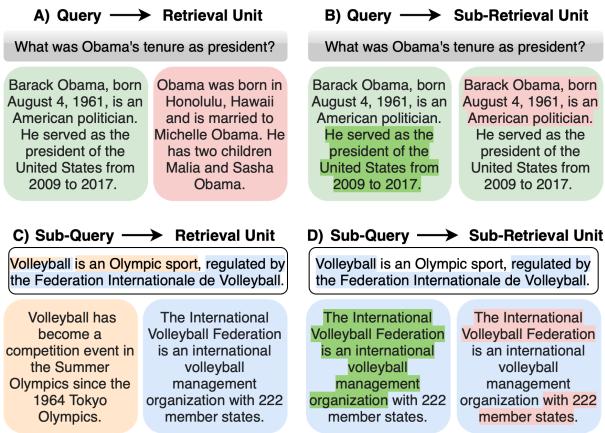
如上方的 图 1 所示,存在多种场景。标准搜索是 (A) : 查询检索段落。但我们经常需要 (B) (查找特定句子) 或 (D) (使用查询的子部分来查找文档的子部分) 。这种灵活性对于像检索增强生成 (RAG) 这样的应用至关重要,因为识别出回答问题的确切句子比检索一段长而无关的文本要好得多。
动机实验: 为什么“上下文”很棘手
你可能会想: “如果我使用像 ColBERT 这样强大的多向量模型,难道我不能只索引段落,然后对其中的句子进行打分吗?”
作者们正是这样尝试的。他们使用 ColBERTv2 编码段落,然后尝试根据查询对这些段落内的句子进行排序。结果令人惊讶。
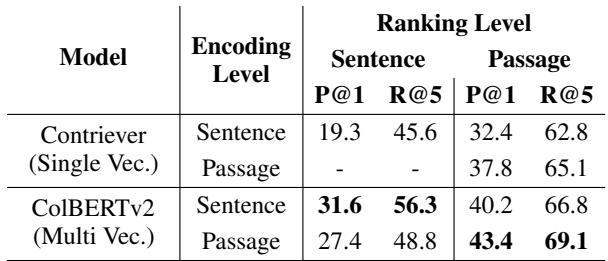
查看 表 1 , 当模型在 段落 (Passage) 层级进行编码时,其对 句子 (Sentence) 进行排序的能力,相比于直接编码句子时显著下降 (Precision@1 从 31.6 降至 27.4) 。
为什么?因为当你编码整个段落时,特定句子中单词的嵌入会受到周围文本的影响。有时,模型会被“干扰句”搞糊涂,这些句子与查询共享关键词,但实际上并没有回答问题。
考虑下面 表 2 中的例子:
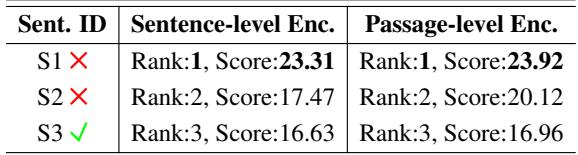
在这里,查询是关于气候变化如何影响海洋生态系统的。
- S1 和 S2 包含单词 “climate change” (气候变化) ,因此模型给它们打了高分。
- S3 解释了实际影响 (变暖的水域、珊瑚白化) ,但缺乏确切的关键词 “climate change”。
结果,模型将相关的句子 (S3) 排在最后!段落编码提供的上下文反而损害了句子的具体检索,因为模型并没有被训练去在段落内部进行区分。
AGRAME 登场: 任意粒度排序
提出的解决方案是 AGRAME (Any-Granularity Ranking with Multi-vector Embeddings) 。其核心思想是让模型在段落层级进行编码 (保留丰富的上下文) ,但训练它“放大”并准确地对子单元 (句子) 进行打分。
架构
AGRAME 建立在 ColBERT 架构之上。在 ColBERT 中,相关性是使用“MaxSim”操作计算的: 对于查询中的每个词,在文档中找到最相似的词,并将这些最大分数相加。
\[ S_{CB}(q,p) = MaxSim(q,p) = \sum_{i=1}^{n} \max_{1 \le j \le m} \vec{Q}_{t_i^q}^T \vec{P}_{t_j^p} \]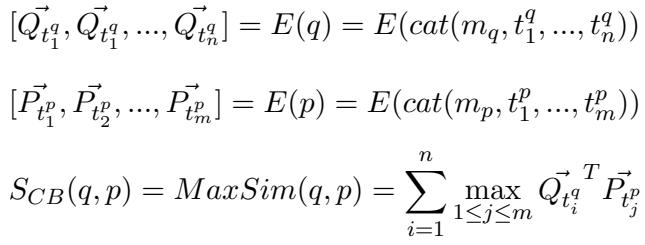
AGRAME 通过引入粒度感知查询标记 (Granularity-Aware Query Marker) 修改了这一点。
在编码查询时,标准 ColBERT 添加一个特殊的 Token 标记 \(m_q\)。AGRAME 引入了一个新标记 \(m'_q\)。
- 如果你想对段落排序,使用 \(m_q\)。
- 如果你想对该段落内部的句子排序,使用 \(m'_q\)。
这个标记充当开关,向模型发出信号: “嘿,不要只看大致的相关性;要寻找回答查询的具体句子。”
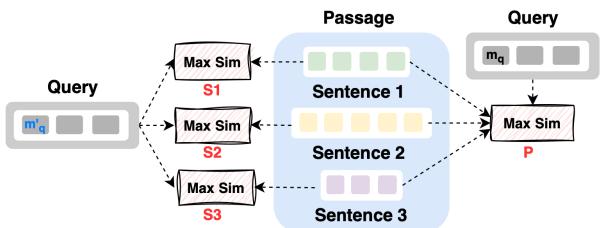
如 图 2 直观所示,段落被编码一次。为了给句子 1 (S1) 打分,模型仅计算查询与属于 S1 的 Token 之间的 MaxSim 交互。
\[ S_{CB}(q, s_j^{p_i}) = \sum_{i=1}^n \max_{1 \le r \le |s_j^{p_i}|} \vec{Q}_{t_i^q}^T \vec{P}_{t_{jr}} \]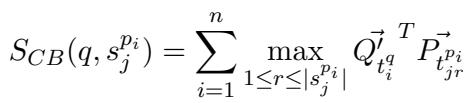
这使得 AGRAME 能够利用周围段落的丰富上下文 (因为嵌入是在整个段落可见的情况下生成的) ,同时在数学上将分数限制在特定的句子 Token 上。
多粒度对比训练
为了解决动机实验中看到的问题 (即模型更喜欢关键词匹配而非语义含义) ,作者引入了一个新的训练目标。
标准训练使用的损失函数只关心是否选择了正确的段落 (\(\mathcal{L}_{psg}\))。AGRAME 增加了一个句子级损失 (\(\mathcal{L}_{sent}\))。
研究人员训练了一个“教师”交叉编码器 (Cross-Encoder, \(CE'\)) ,专门用于识别段落内的正确句子。然后他们利用知识蒸馏教 AGRAME 模仿这位教师。
\[ \mathcal{L}_{s}(q, p_i) = KL(D_{CE'}(q, [s^{p_i}]) || D_{CB}(q, [s^{p_i}])) \]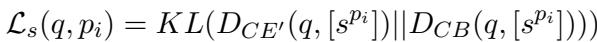
这个损失函数迫使模型学习这一点——即使句子 1 有匹配的关键词,如果句子 3 包含语义上的答案,句子 3 应该得到更高的分数。最终的训练损失结合了这两个目标:
\[ \mathcal{L}(q, [p]) = \mathcal{L}_{psg}(q, [p]) + \mathcal{L}_{sent.}(q, [p]) \]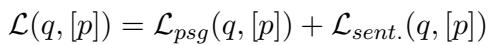
实验结果
增加这种“放大”能力真的有效吗?结果令人信服。
1. 句子级排序
作者在几个开放域问答数据集 (Natural Questions, TriviaQA 等) 上测试了 AGRAME。

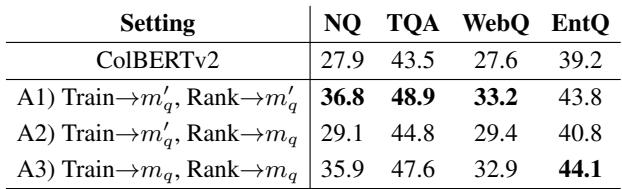
在 表 3 中,请看 “Ours (Passage Encoding)” 这一行。
- 在 Natural Questions 上,AGRAME 在句子排序方面达到了 36.8 P@1 (Precision at 1) 。
- 相比之下,基线 ColBERTv2 段落编码仅获得 27.9 。
- 至关重要的是,AGRAME 甚至击败了那些专门在句子层级进行编码的模型 (32.7)。
这证实了假设: 上下文很重要。 在段落层级进行编码可以提供更好的语义信息,前提是你 (通过新的损失函数和标记) 训练模型正确地利用它。
2. 查询标记的影响
作者还分析了模型的学习速度。
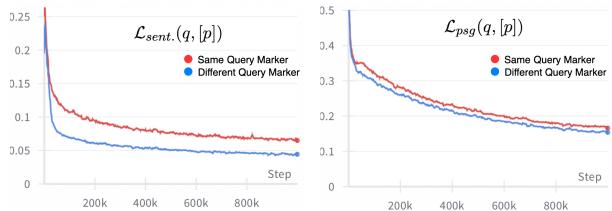
图 3 显示,使用独特的查询标记 (\(m'_q\)) 使得句子级损失 (左图) 比在两个任务中使用相同标记下降得快得多。模型迅速学会了区分“寻找文档”和“寻找句子”。
回顾之前“气候变化”的失败案例: 使用 AGRAME 后,相关句子 (S3) 现在被正确地排在了第 1 位。
应用: 用于检索增强生成的 PROPCITE
AGRAME 最令人兴奋的应用之一是在归因 (Attribution) 方面——即为 AI 生成的文本添加引用来源。
大型语言模型 (LLM) 经常产生幻觉引用。一种更好的方法是“事后引用” (Post-Hoc Citation) : 让 LLM 生成答案,然后使用检索系统找到支持每个句子的证据。
作者提出了 PROPCITE 。 他们不使用整个生成的句子作为查询,而是将句子分解为命题 (propositions,即原子事实) ,并使用 AGRAME 分别为每个事实寻找证据。

如 图 4 所示,如果一个生成的句子包含两个事实 (比赛日期和获胜者) ,PROPCITE 可以将日期归因于上下文 C1,将分数归因于上下文 C3。标准的检索器可能会因为将这些不同的事实混合到一个查询向量中而感到困惑。
引用性能
作者将 PROPCITE 与让 LLM 自行生成引用的标准方法 (“Generate”) 进行了比较。
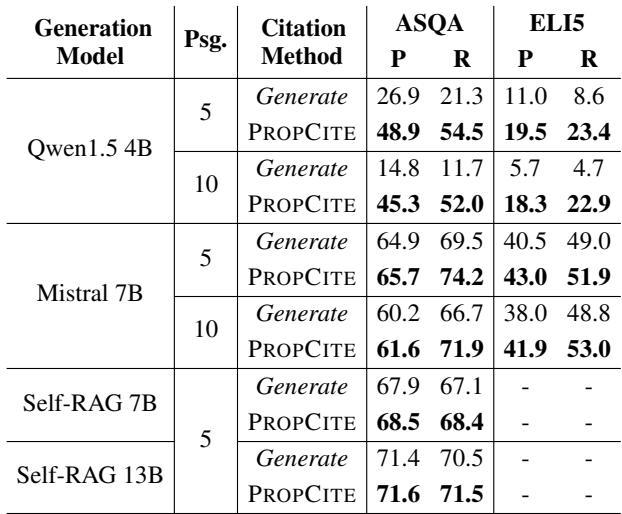
表 8 显示,相比于提示生成 (Generate) ,PROPCITE (使用 AGRAME 的命题级排序) 在 ASQA 和 ELI5 数据集上实现了更高的精确率和召回率。这一点特别有价值,因为它将生成与引用解耦,从而产生更可靠、经过事实核查的输出。
这种细粒度的排序能力也被证明优于简单的基线。
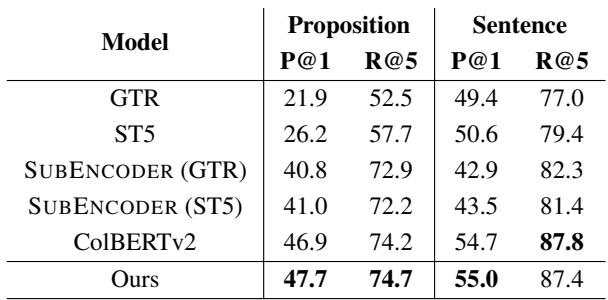
在 原子事实检索 任务 (表 7) 中,AGRAME (Ours) 优于专门的子句编码器,证明了通用的多向量模型无需专门的架构即可处理细粒度任务。
结论
AGRAME 论文在使神经搜索更加灵活方面迈出了重要的一步。通过利用像 ColBERT 这样的多向量模型的 Token 级嵌入,并引入多粒度训练策略,作者证明了我们不需要在“粗粒度”和“细粒度”搜索之间做出选择。我们可以两者兼得。
给学生和从业者的关键要点:
- 上下文至关重要: 即使对于句子检索,在段落层级进行编码通常也比在句子层级更好,只要模型能正确处理上下文。
- 多向量的灵活性: 与压缩信息的单向量模型不同,多向量模型允许你在数学上“屏蔽”文档的部分内容,以便在不重新索引的情况下对子单元进行评分。
- 更好的 RAG: 细粒度排序允许精确的归因 (引用) ,这是可信赖 AI 系统的关键要求。
AGRAME 预示着这样一个未来: 搜索索引是统一的,但检索过程可以根据用户的需求,既可以宏观也可以微观。