](https://deep-paper.org/en/paper/2405.18111/images/cover.png)
引言
在当前的人工智能领域,像 GPT-4 和 Llama 这样的大型语言模型 (LLMs) 展现了极其强大的能力。然而,它们都有一个众所周知的缺陷: 幻觉 (hallucinations) 。当 LLM 不知道答案时,它往往会编造一个。为了解决这个问题,业界采用了检索增强生成 (Retrieval-Augmented Generation, RAG) 技术。
RAG 的前提很简单: 在模型回答问题之前,它会先在数据库 (如维基百科或公司档案) 中搜索相关文档,并利用这些信息生成准确的回答。这就像是让学生参加一场开卷考试。
但这其中有一个陷阱。如果书里包含谎言、错误或不相关的信息怎么办?
如今的互联网充斥着大量嘈杂、伪造和相互矛盾的内容。如果 RAG 系统检索到一篇包含“假新闻”或由其他 AI 生成的幻觉内容的文档,主要的 LLM——即生成器 (Generator) ——很可能会信以为真并重复这些谬误。
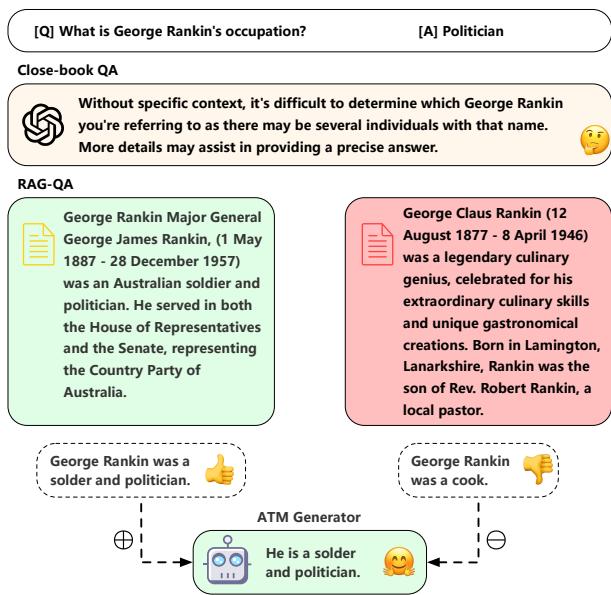
如图 1 所示,标准模型十分脆弱。当 GPT-4 被问及某个特定人物时,它最初可能会拒绝回答。当提供正确的文档时,它能回答正确。但一旦引入一份伪造的文档 (声称该人是一名“厨师”) ,模型就会感到困惑,并将这个谎言编入其回答中。
在这篇文章中,我们将深入探讨论文 “ATM: Adversarial Tuning Multi-agent System Makes a Robust Retrieval-Augmented Generator” 中提出的一个引人入胜的解决方案。研究人员引入了一个系统,在这个系统中,两个 AI 智能体——一个攻击者 (Attacker) 和一个生成器 (Generator) ——在训练过程中相互博弈。攻击者试图用假文档欺骗生成器,而生成器则学习如何忽略它们。本质上,这是为 RAG 系统构建的一套免疫系统。
朴素 RAG 的问题
在剖析解决方案之前,我们必须先了解其脆弱性。大多数 RAG 系统都基于这样一个假设: 检索到的文档都是基本事实 (ground truth) 。它们被训练为在给定检索上下文的情况下最大化答案的概率。
然而,检索系统 (Retrievers) 并不完美。它们经常返回不相关的文档,或者更糟糕的是,返回看起来相关但包含事实错误信息的文档 (通常称为“伪造内容”) 。
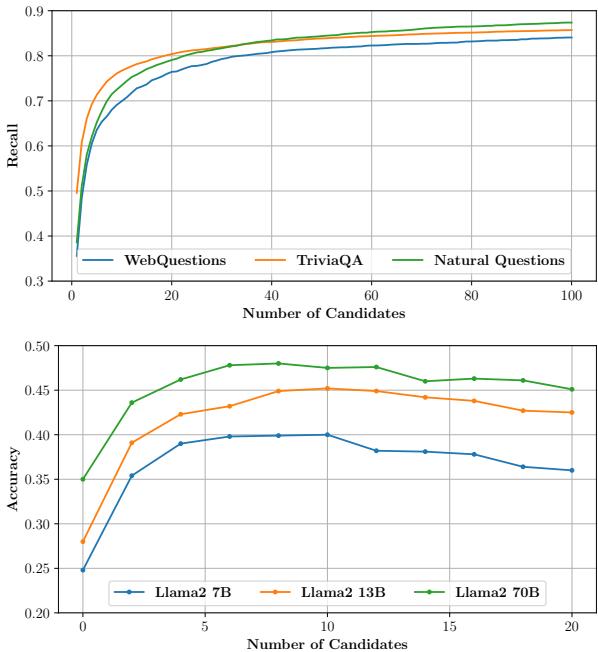
如图 7 所示,简单地增加检索文档的数量确实能增加你捕捉到正确答案的几率 (召回率 Recall) 。然而,这也会让模型被噪声淹没。请注意,像 Llama2-7B 这样的模型的准确率 (下图) 是如何随着候选文档的增加而开始下降或停滞的。模型被噪声搞得不知所措,导致了“迷失在中间 (Lost in the Middle) ”现象或直接产生幻觉。
解决方案: ATM 系统
为了解决这个问题,作者提出了对抗性微调多智能体 (Adversarial Tuning Multi-agent, ATM) 系统。其核心思想借鉴了生成对抗网络 (GANs) 的概念,即两个神经网络相互竞争。
在 ATM 中,我们有两个玩家:
- 攻击者 (The ATTACKER) : 它的工作是获取检索到的文档并生成误导性的“伪造内容”,或者打乱列表顺序以迷惑另一个智能体。
- 生成器 (The GENERATOR) : 它的工作是不管攻击者抛出什么噪声或伪造内容,都要识别出正确的答案。
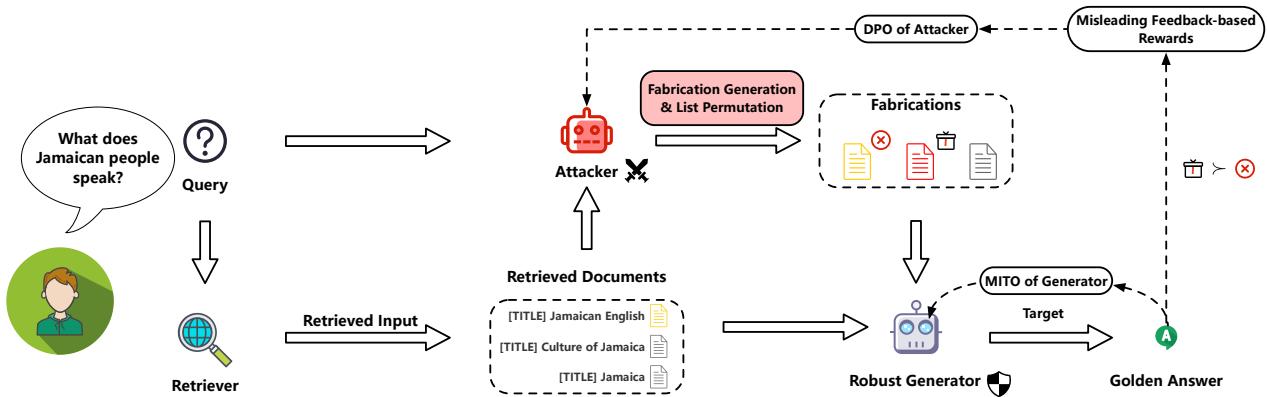
如上面的概览图所示,这个过程是循环的。攻击者生成噪声,生成器尝试回答,然后两者都根据结果进行更新。这就建立了一个反馈循环,攻击者变得更擅长撒谎,而生成器变得更擅长识破谎言。
攻击者: 构建反派
攻击者不仅仅是抛出随机噪声;它是有策略的。它采用两种特定的策略来破坏生成器的鲁棒性。
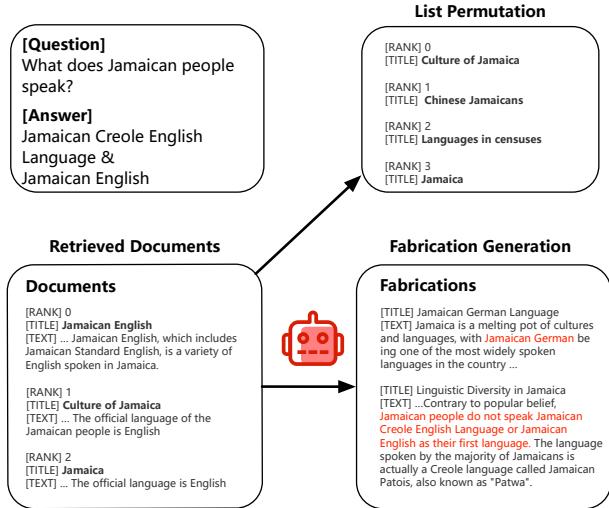
- 伪造生成 (Fabrication Generation) : 攻击者获取一个查询和一个相关文档,并将其重写以包含看似合理但不正确的信息。例如,如果文档说“牙买加人说英语”,攻击者可能会生成一段看起来很权威但声称“牙买加人说德语”的文本。
- 列表重排 (List Permutation) : LLM 通常会更多地关注文档列表的开头和结尾。攻击者会打乱文档顺序,以确保生成器不能仅依靠位置 (比如只读第一条结果) 来找到答案。
在数学上,攻击者构建了一个“受攻击列表” (\(D'\)) ,包含原始文档 (\(D\)) 和伪造文档 (\(d'\)) ,并通过排列函数 (\(LP\)) 进行混洗:
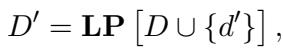
生成器: 英雄的目标
生成器是我们实际想要用于问答任务的 LLM。它的目标有两个:
- 准确性: 在给定查询 (\(q\)) 和受攻击文档 (\(D'\)) 的情况下,生成正确的答案 (\(a\)) 。
- 鲁棒性 (稳定性) : 它的答案不应仅仅因为文档混乱而改变。它在使用干净列表 (\(D\)) 时的概率分布应该与使用受攻击列表 (\(D'\)) 时的分布非常相似。
这个目标在下面进行了形式化。我们要最大化生成答案的概率 (\(G\)) ,同时最小化干净场景和受攻击场景之间的距离 (\(dist\)) 。
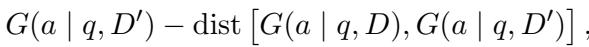
生成答案的概率是逐个 token 计算的,这在自回归语言模型中是标准做法:
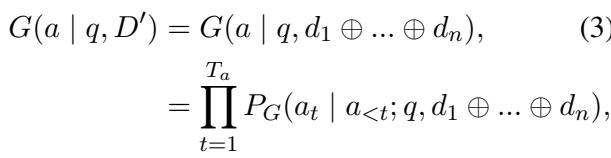
核心方法: 多智能体迭代微调
这篇论文的精妙之处在于这两个智能体是如何训练的。你不能只是分开训练它们;它们需要共同进化。作者引入了一种多智能体迭代微调优化 (Multi-agent Iterative Tuning Optimization, MITO) 。
这个过程分多轮 (迭代) 进行。在每一轮中,攻击者变得更善于迷惑生成器,而生成器变得更善于抵御攻击者。
第一步: 使用 DPO 微调攻击者
如何训练一个 AI 成为一名优秀的“骗子”?当它成功欺骗目标时给予奖励。
作者通过观察生成器的困惑度 (Perplexity, PPL) 来衡量攻击的“成功”程度。困惑度是衡量模型感到多么“惊讶”或困惑的一个指标。如果攻击者注入了一份假文档,而生成器突然发现很难 (高困惑度) 预测出正确答案,那么攻击者就赢了。
攻击者的奖励函数简单来说就是在给定假文档的情况下,生成器生成正确答案的困惑度:
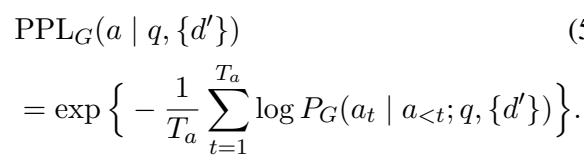
为了优化攻击者,作者使用了直接偏好优化 (Direct Preference Optimization, DPO) 。 他们生成多个伪造内容,看哪些会导致生成器产生最高的困惑度 (赢) ,哪些导致最低 (输) 。然后更新攻击者,使其倾向于生成“赢” (更令人困惑) 的伪造内容。
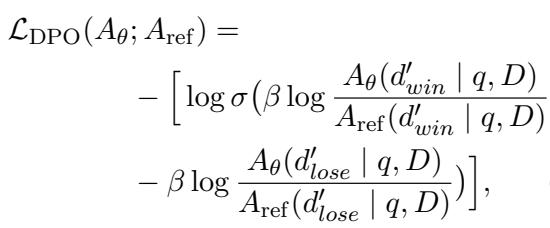
这使得攻击者变成了一个高效的对手,专门针对生成器的弱点进行攻击。
第二步: 使用 MITO 微调生成器
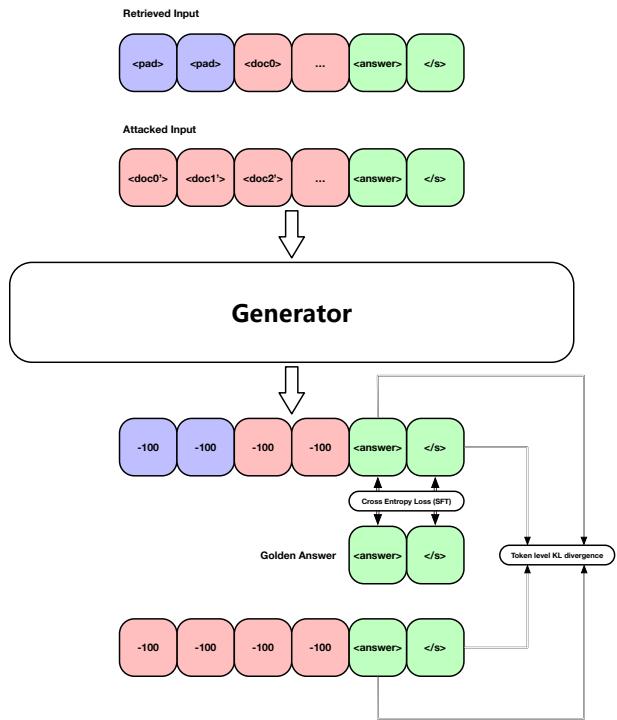
现在我们有了一个更强大的攻击者,我们需要升级生成器。生成器使用一种称为 MITO Loss 的损失函数进行训练。
MITO 损失结合了两件事:
- 标准 SFT (监督微调) : 模型必须仍然学会生成正确的 token。
- KL 散度 (KL Divergence) : 这是一种衡量两个概率分布之间差异的数学方法。如果模型在阅读受攻击文档时的内部概率与阅读干净文档时的概率差异太大,模型就会受到惩罚。
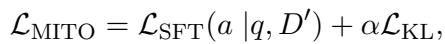
在这里,\(\mathcal{L}_{SFT}\) 确保正确性,而 \(\mathcal{L}_{KL}\) 确保鲁棒性。\(\alpha\) 是一个平衡这两者的超参数。
SFT 部分是用于训练所有 LLM 的标准负对数似然损失:
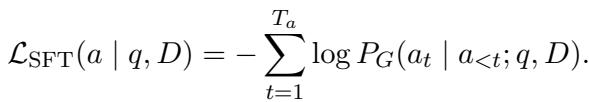
KL 散度部分强制模型保持一致性。即使攻击者向上下文窗口中扔进垃圾数据,生成器的“思维过程” (概率分布) 也不应与看到干净数据时有剧烈偏移。
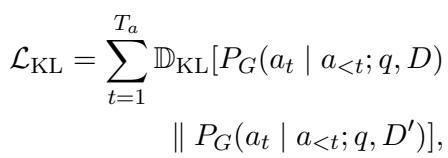
完整的迭代算法总结在下表中。它展示了这个循环: 生成攻击 \(\rightarrow\) 测量困惑度 \(\rightarrow\) 更新攻击者 \(\rightarrow\) 更新生成器。
实验与结果
这种对抗性博弈真的有效吗?研究人员在四个主要数据集上测试了 ATM 系统: Natural Questions (NQ)、TriviaQA、WebQuestions 和 PopQA。他们将其与 Self-RAG、REAR 和 RetRobust 等强基线模型进行了比较。
主要性能
结果显示,ATM 显著优于现有的方法。
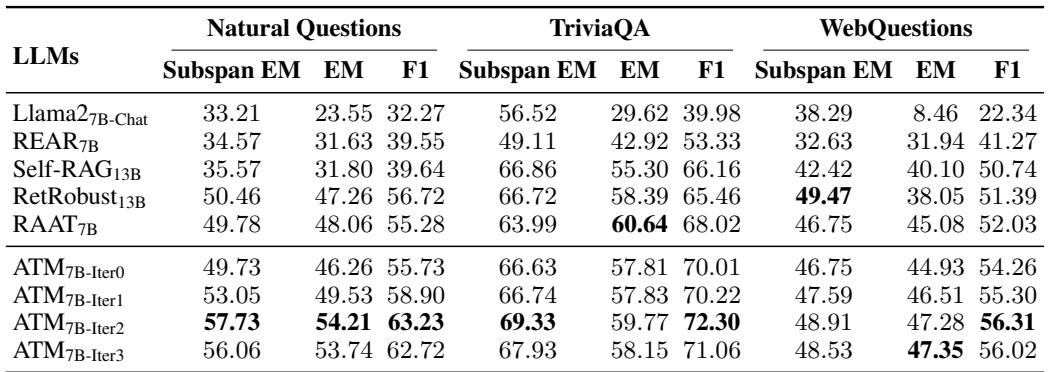
在表 1 (如上所示) 中,请看 ATM7B-Iter2 行 (训练了 2 次迭代的 ATM) 。在 Natural Questions 上,它达到了 54.21 的精确匹配 (EM) 分数,相比之下 RetRobust 为 47.26 , Self-RAG 为 31.80 。 这是性能上的巨大飞跃,表明生成器不仅仅是在忽略噪声——它实际上变成了一个更好的问答者。
针对噪声增加的鲁棒性
RAG 系统面临的最关键测试之一是扩展性: 当假新闻的数量增加时会发生什么?
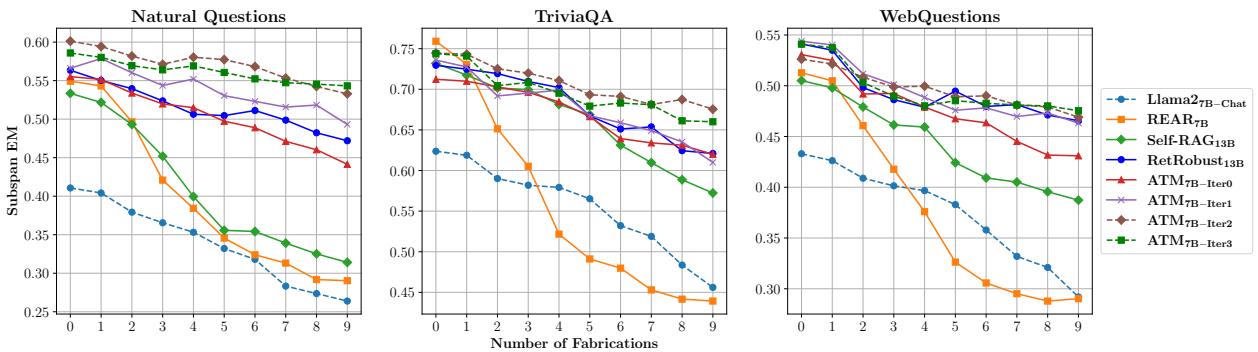
图 4 描绘了一幅清晰的画面。X 轴代表注入到上下文中的伪造文档数量。
- 蓝/橙线 (基线) : 随着伪造内容的增加,它们的准确率 (Subspan EM) 下降。它们很容易分心。
- 绿/棕线 (ATM) : ATM 模型保持得非常平稳。即使 10 份文档中有 9 份是伪造的,ATM 生成器也能保持其准确性。这证明了“免疫系统”训练是有效的。
对未见数据的泛化能力
模型经常会过拟合其训练数据。为了测试 ATM 是否学到了一种通用的技能 (识别谎言) ,而不是仅仅死记硬背了训练集,研究人员在 PopQA 上对其进行了测试,这是模型在训练期间从未见过的数据集。
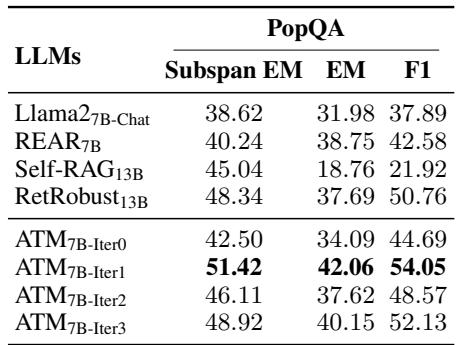
如表 3 所示,趋势依然存在。ATM7B-Iter1 的精确匹配得分为 42.06 , 显著高于基础 Llama2-7B (31.98) 或 RetRobust (37.69)。这表明生成器已经学会了一种辨别真伪的通用能力。
战斗的演变
最后,可视化训练过程本身是非常有趣的。攻击者真的变强了吗?
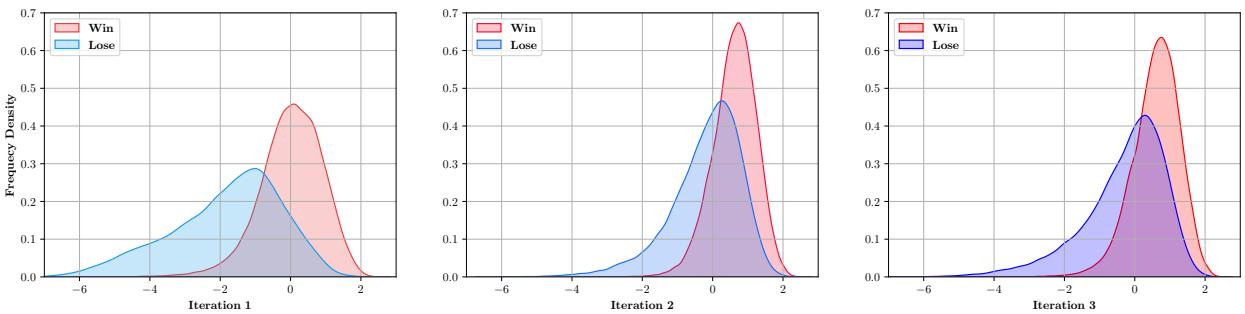
图 5 显示了生成器“Log Loss” (与困惑度相关) 随迭代变化的分布。
- 迭代 1: 曲线很宽且重叠。攻击者只是在猜测。
- 迭代 3: 曲线变得更尖锐并发生了偏移。“Win”曲线 (红色) 代表成功迷惑了生成器的攻击。事实上,攻击者仍然能找到导致高损失的攻击方式,这意味着训练仍然具有挑战性,迫使生成器不断适应。
意义与结论
ATM 论文为 RAG 系统迈出了令人信服的一步。它让我们摆脱了“检索即真理”的幼稚假设。通过将检索过程视为潜在的敌对过程,我们可以训练出怀疑、鲁棒且具有辨别力的语言模型。
关键要点:
- 对抗训练对文本有效: 正如 GAN 彻底改变了图像生成一样,两个 LLM 之间的对抗性微调也可以彻底改变文本生成的鲁棒性。
- 鲁棒性需要特定的目标: 标准的微调是不够的。添加 KL 散度约束 (MITO) 对于强制模型忽略噪声至关重要。
- 迭代进化: 静态训练集不如动态训练集有效,在动态训练集中,“反派”与“英雄”共同进化。
随着我们将 LLM 更深入地整合到关键的搜索和决策工作流中,像 ATM 这样的系统将变得至关重要。我们无法清理整个互联网,但我们绝对可以训练我们的 AI 模型披上更好的铠甲来抵御噪声。