](https://deep-paper.org/en/paper/2405.19723/images/cover.png)
想象一下,你正在看一部超级英雄电影。在第一幕中,主角意识到战衣里的某个特定组件正在使他中毒。一小时后,他发现了一种新元素来替代它。在最后的决战中,这种新元素为战衣提供了动力,不仅让他赢得了战斗,还保住了性命。
现在,如果我问你: “如果主角没有更换那个组件会发生什么?”
要回答这个问题,你需要将第 0 小时的中毒事件与第 2 小时的胜利联系起来。你需要全局语境 (Global Context) ——也就是整个叙事弧线。
对于人工智能,特别是在视频问答 (Video Question Answering, VideoQA) 领域,这是一个巨大的挑战。目前大多数 AI 模型都非常擅长回答有关 10 秒钟猫咪跳跃视频的问题。但如果你问它们一个关于 2 小时电影的复杂因果问题,它们往往会束手无策。
在这篇文章中,我们将深入探讨论文 “Encoding and Controlling Global Semantics for Long-form Video Question Answering” (长视频问答中全局语义的编码与控制) 。 研究人员提出了一种名为 GSMT (门控状态空间多模态 Transformer) 的新颖架构,解决了长视频中的“失忆”问题。他们还引入了两个海量基准测试集: Ego-QA 和 MAD-QA , 以真正测试机器是否能看懂电影并理解情节。
问题所在: 透过锁孔看世界
要理解这篇论文的创新之处,我们首先需要了解目前标准的 VideoQA 模型是如何工作的。
对于沉重的 Transformer 模型来说,处理 2 小时视频的每一帧 (30fps 下大约包含 216,000 帧) 在计算上是不可能的。标准的解决方案是稀疏采样 (sparse sampling) 或自适应选择 (adaptive selection) 。 模型会查看问题,快速扫描视频,然后选择少数几个“相关”片段或区域进行深度分析。
虽然这节省了内存,但也产生了一个“锁孔”问题。如果模型只从电影中选取 10 个片段,它就会失去全局语义——那些将故事粘合在一起的胶水。它可能看到英雄在战斗,但错过了前一个小时解释为什么他们要战斗的场景。

如上图 Figure 1 所示,回答像 “如果这个人没有钯锭 (ingot of palladium) 会怎样?” 这样的问题,需要对一长串事件进行推理: 健康恶化 \(\rightarrow\) 需要替换 \(\rightarrow\) 创造新元素 \(\rightarrow\) 激活战衣。标准的选择方法往往无法捕捉到这一完整的链条。
解决方案: 门控状态空间多模态 Transformer (GSMT)
研究人员提出了一个新的框架,它不仅仅是“跳到”精彩部分。相反,它会在进行任何选择之前处理整个视频序列,以提取全局上下文信号。
他们通过使用状态空间层 (State Space Layer, SSL) 来实现这一点。与 Transformer 对序列长度具有二次方复杂度 (\(O(L^2)\)) 不同,状态空间模型 (SSMs) 是线性扩展的 (\(O(L)\)) 。这使得模型能够“观看”整个视频并编码长期记忆,而不会导致 GPU 崩溃。
这是 GSMT 的高层架构:
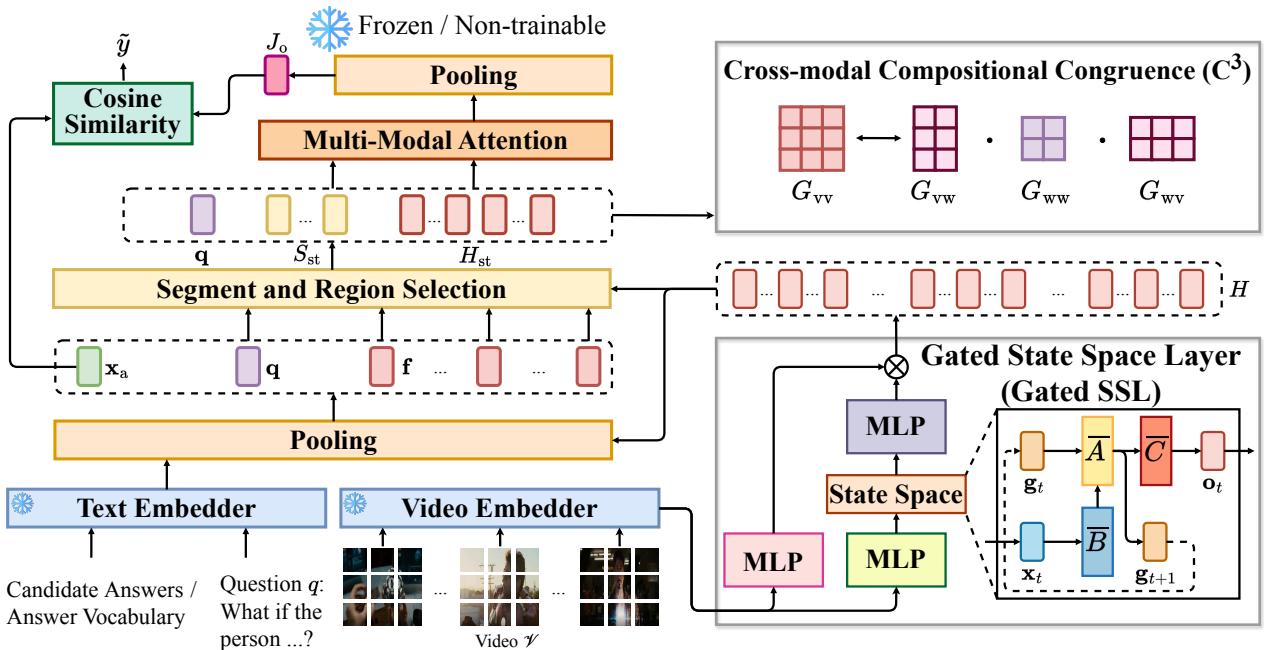
该架构主要包含三个阶段:
- 门控状态空间层 (Gated SSL) : 将全局视频历史编码进视觉特征中。
- 选择模块: 根据问题挑选最相关的片段 (此时已富含全局上下文) 。
- 多模态注意力: 使用 Transformer 对选定的片段进行深度推理。
让我们一步步来拆解这些部分。
1. 门控状态空间层 (SSL)
这里的核心创新是利用状态空间模型来捕捉长期依赖关系。如果你熟悉循环神经网络 (RNN) 或隐马尔可夫模型,其概念是相似的: 我们有一个随时间更新的隐藏状态。
记忆的数学原理
作者定义了一个从输入视觉补丁 \(x(t)\) 到输出 \(y(t)\) 的连续映射,通过隐藏状态 \(g(t)\) 实现。在 (计算机使用的) 离散域中,这是通过矩阵 \(A\)、\(B\) 和 \(C\) 参数化的。
隐藏状态的更新规则为:
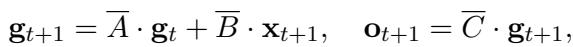
这里,\(\mathbf{g}_t\) 是 \(t\) 时刻的“记忆”,而 \(\mathbf{x}_{t+1}\) 是新的视觉输入。矩阵 \(\bar{A}\) 决定了保留多少旧记忆,\(\bar{B}\) 决定了加入多少新输入。
为了使其在计算上可行,连续参数通过步长 \(\Delta\) 进行了离散化:
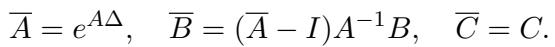
这个公式的美妙之处在于它可以被展开。它不需要像 RNN 那样一步步计算 (那样很慢) ,而是可以写成一个卷积形式:
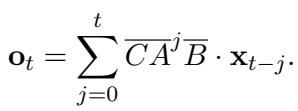
这种卷积允许模型利用快速傅里叶变换 (FFT) 并行计算整个视频的“记忆”。这就是使全局编码在长视频中足够快的关键。
控制信息流: 门控机制
然而,简单地记住 2 小时电影中的一切并不是理想的。电影中有很多背景噪声——风景、静默或无关的动作。如果全局记忆被噪声淹没,推理能力就会受到影响。
为了解决这个问题,作者引入了一个门控单元 (Gating Unit) 。 它的作用就像一个阀门,控制有多少全局语义信息流入最终的视觉表示。
他们计算两个门控信号 \(U\) 和 \(V\),以及来自 SSM 的输出 \(O\):
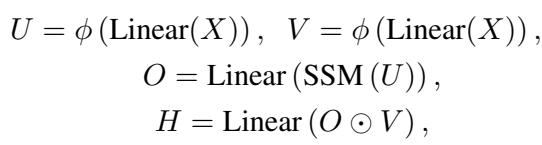
在这里,状态空间模型的输出 (\(O\)) 与门控 \(V\) 进行逐元素相乘 (\(\odot\)) 。这允许网络学习抑制无关的全局信息,并突出重要的叙事线索。
2. 智能选择与注意力
一旦视觉特征通过门控 SSL 丰富了全局上下文,模型就会进入选择阶段。由于特征现在包含了关于整个视频的信息 (归功于 SSL) ,选择模块可以做出更明智的决定。
模型将帧池化为片段,并选择与问题 \(\mathbf{q}\) 最相关的 top-\(k\) 个片段。
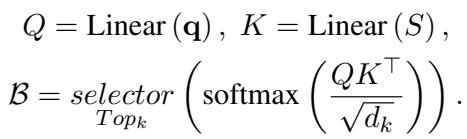
选择片段后,它会更进一步,使用类似的 top-\(j\) 选择机制在这些帧中选择特定的空间区域 (补丁) :
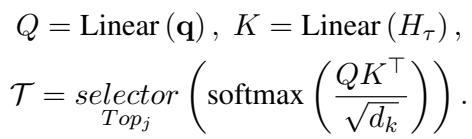
最后,这些被选中的高质量视觉 Token 与文本一起被送入标准的 Transformer 中,用于最终的答案预测。
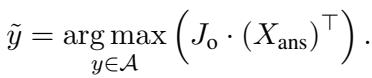
视觉与语言的对齐: \(C^3\) 目标函数
仅有架构本身虽然强大,但作者引入了一个专门的训练目标来使其更加完善。他们称之为跨模态组合一致性 (Cross-modal Compositional Congruence, \(C^3\)) 。
其直觉是: 如果问题问的是“一个拿杯子的男人”,那么文本中“男人”和“杯子”之间的关系,应该反映在男人的视觉补丁和杯子的视觉补丁之间的关系上。
模型计算视觉 (\(G_{vv}\)) 和语言 (\(G_{ww}\)) 的注意力矩阵,以及跨模态注意力 (\(G_{vw}\)) 。

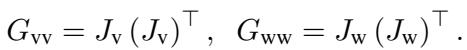
然后,他们使用基变换 (change-of-basis) 公式将视觉注意力投影到语言空间中:
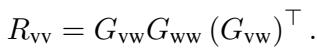
目标是最小化原始视觉关系与该投影版本之间的差异 (Kullback-Leibler 散度) 。这迫使视觉特征以一种与问题的语言结构“一致”的方式进行组织。
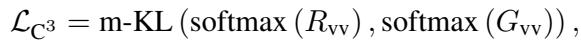
重新定义“长格式”: Ego-QA 和 MAD-QA
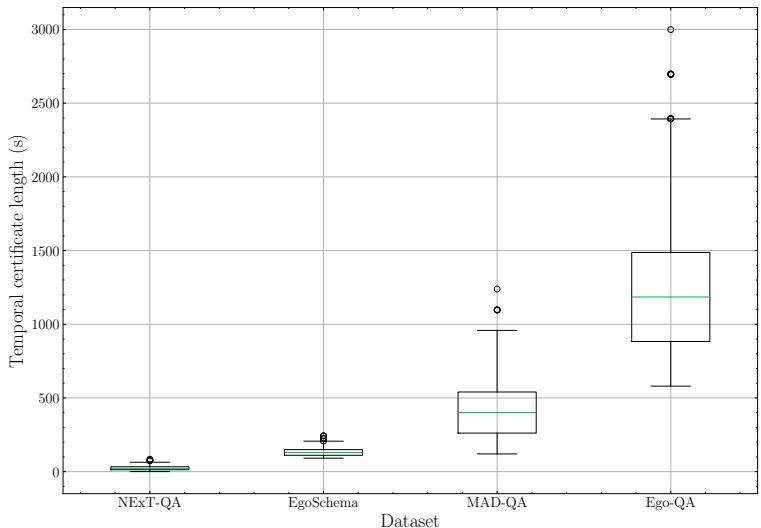
这篇论文最关键的贡献之一是指出,现有的“长格式 (long-form) ”数据集实际上并没有那么长。像 NExT-QA 或 EgoSchema 这样的数据集通常平均只有几分钟的片段。
为了严格测试他们的模型,作者创建了两个巨大的新基准:
- Ego-QA: 基于 Ego4D。平均视频长度: 17.5 分钟 。
- MAD-QA: 基于电影 (MAD 数据集) 。平均视频长度: 1.9 小时 。
他们使用 GPT-4 基于密集字幕生成复杂问题,随后进行严格的人工过滤,以确保回答这些问题确实需要观看视频。

如下方 Figure 6 所示,“时间凭证长度 (temporal certificate length) ” (即回答问题实际需要观看的视频长度) 在这些新数据集中显着高于 NExT-QA 等现有数据集。
实验与结果
那么,添加门控状态空间层真的有效吗?结果令人信服。
标准数据集上的表现
首先,让我们看看 AGQA , 这是一个时空推理的标准基准。GSMT 在几乎所有问题类型上都优于之前的 SOTA 模型 (MIST-CLIP) ,特别是在严重依赖上下文的“序列 (Sequence) ”和“对象-动作 (Object-action) ”问题上。

新的“真正”长格式数据集上的表现
在作者创建的那些高难度、海量数据集上,差距变得更加明显。
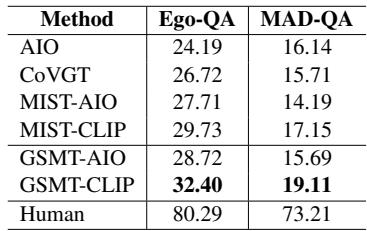
在 Ego-QA 上,GSMT (32.40%) 显著优于之前的最佳模型 MIST-CLIP (29.73%)。在 MAD-QA (电影数据集) 上,改进也很明显,尽管整体数值较低,这反映了对 2 小时电影进行推理的极高难度。
效率: SSL 的优势
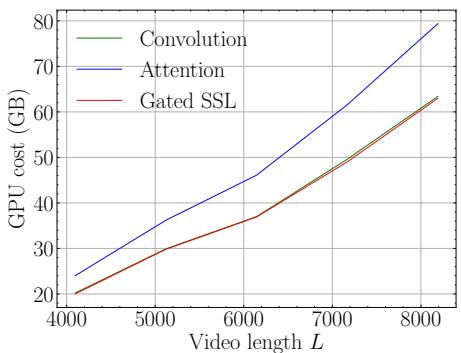
你可能会认为处理整个视频历史记录会过于昂贵。然而,由于状态空间模型的线性扩展特性,与标准注意力机制相比,内存成本非常可控。
下方的 Figure 4 展示了 GPU 内存成本随视频长度增加的情况。蓝线 (Attention) 呈指数级上升。红线 (Gated SSL) 呈线性增长,类似于卷积,这使得处理数千帧成为可能。
定性分析
让我们看一个来自 MAD-QA 数据集 (钢铁侠 2) 的具体例子。
问题是: “如果这个人没有钯锭来替换 RT 装置中冒烟的那个会怎样?”
- 选项 0: 男人会因不同原因赶往医院。
- 选项 1: 浪漫关系不会开始。
- 选项 3 (正确) : RT 装置会退化,健康恶化/战衣故障。

基线模型 (MIST-CLIP) 感到困惑并预测了选项 1。它可能只关注了角色对话的局部画面。而 GSMT 正确预测了选项 3。通过编码全局语义,它将钯 (电影早期出现) 与主角的健康 (贯穿始终) 以及战衣的功能 (高潮部分出现) 联系了起来。
另一个来自 Ego-QA 的例子:

问题询问一个 30 分钟视频的“中心主题”。MIST-CLIP 预测“身心自我提升” (可能是看到了瑜伽垫) 。GSMT 通过聚合整个视频时长的厨房、清洁和整理场景线索,正确识别出了“日常家务管理”。
消融研究: 什么最重要?
作者进行了严格的测试,以查看哪些组件最重要。
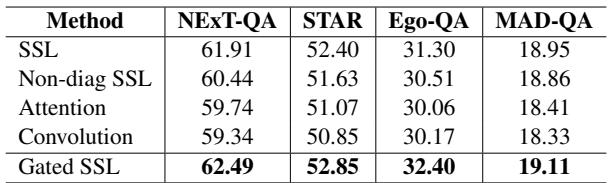
- 门控重要吗? 是的。移除门控机制 (Standard SSL) 会导致性能显著下降 (Table 7) 。模型需要过滤噪声。
- \(C^3\) 目标重要吗? 是的。与不使用或使用标准最优传输方法相比,使用对齐目标在各个数据集上将准确率提高了大约 1-2% (Table 8) 。
- 位置重要吗? 是的。SSL 必须放置在网络的早期 (视频嵌入器) ,以便在选择之前丰富特征。将其放在后期 (多模态阶段) 会损害性能 (Table 10) 。
结论
论文 “Encoding and Controlling Global Semantics for Long-form Video Question Answering” 提出了一个令人信服的观点: 我们不能仅仅通过高效地“略读”来解决长视频理解问题。我们需要记忆。
通过集成 门控状态空间层 , GSMT 架构提供了一种保留视频全局叙事的方法,而不会产生 Transformer 那样爆炸式的计算成本。此外, Ego-QA 和 MAD-QA 的引入推动了该领域走向现实的、长达一小时的视频理解,而不仅仅是短片分析。
随着 AI 助手越来越多地融入我们的生活——分析我们的日常日志或帮助我们搜索电影档案——像 GSMT 展示的这种能力将至关重要。能够将数小时镜头中的点点滴滴连接起来的能力,让我们离真正理解“大局”的 AI 更近了一步。