](https://deep-paper.org/en/paper/2406.02925/images/cover.png)
引言
在自动语音识别 (ASR) 领域,数据为王。要构建一个能理解医疗听写、法律诉讼或日常俚语的模型,通常需要数千小时的录音音频及准确的对应文本。但对于许多特定领域,这种“真实”的配对数据根本不存在,或者收集成本极其高昂。
现代的解决方案非常巧妙: 使用文本转语音 (TTS) 系统从文本生成合成音频。如果你有一本医学教科书的文本,你可以生成数千小时的合成语音来训练你的模型。然而,这其中有个陷阱。无论 TTS 变得多么先进,它仍然具有将其与人类语音区分开来的声学伪影 (acoustic artifacts) ——缺乏背景噪音、不自然的呼吸模式或特定的数字特征。
当一个 ASR 模型在这种合成数据上训练时,它会遭受合成到真实的差距 (synthetic-to-real gap) 的影响。它学会了识别机器人完美的咬字,但在面对人类语音那杂乱的现实时却束手无策。
在最近的一篇论文《Task Arithmetic can Mitigate Synthetic-to-Real Gap in Automatic Speech Recognition》中,研究人员提出了一种迷人的解决方案,不需要目标领域有更多的真实数据。相反,他们使用任务算术 (Task Arithmetic) 。 通过将模型权重视为向量,他们可以通过数学计算得出真实语音的“方向”,并将其注入到在合成数据上训练的模型中。
领域自适应的格局
要理解这个解决方案,我们首先必须可视化这个问题。ASR 中的领域自适应面临两种截然不同的不匹配:
- 文本/主题不匹配 (Textual/Topic Mismatch) : 讨论内容之间的差异 (例如,烹饪食谱与天气预报) 。
- 声学不匹配 (Acoustic Mismatch) : 音频听感上的差异 (例如,合成语音与真实人类语音) 。
研究人员在一个象限系统中展示了这些偏移:
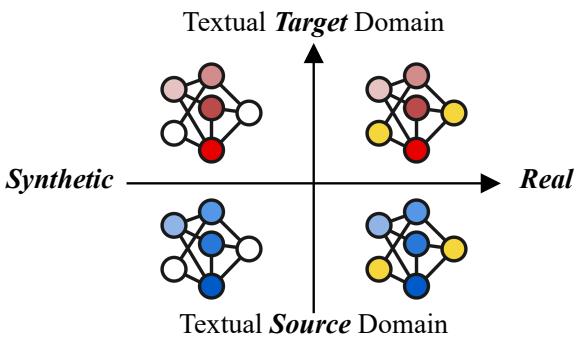
如图 2 所示,我们通常从源领域 (左上和左下) 开始,那里我们有大量数据——既有合成的也有真实的。我们希望转移到目标领域 (右下) ,希望模型在真实语音上表现良好。然而,在目标领域中,我们通常只有文本,这意味着我们只能生成目标合成数据 (右上) 。
目标是在不实际拥有该目标的真实音频数据的情况下,跨越从 目标合成 象限到 目标真实 象限的鸿沟。
核心方法: SYN2REAL 任务向量
研究人员提出了一种名为 SYN2REAL 的方法。其直觉非常优雅: 如果我们能在拥有数据的领域中确切找出“真实语音”与“合成语音”的区别,我们就可以将这种差异打包,并将其应用到我们没有数据的各种新领域中。
这通过任务算术成为可能。深度学习的最新发现表明,微调后的神经网络权重可以使用基本的算术运算 (加法和减法) 进行操作。
第一步: 计算差异
首先,该方法利用一个既存在真实录音又存在合成生成的源领域 。 从同一个预训练 ASR 主干网络 (如 Whisper) 微调出两个独立的模型:
- \(\theta_{real}^S\): 在真实源数据上微调的模型。
- \(\theta_{syn}^S\): 在合成源数据上微调的模型。
研究人员假设这两个模型参数之间的差异代表了理解真实语音所需的特定声学特征。他们将这种差异定义为任务向量 (\(\tau\)) :
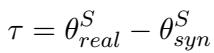
在这里,\(\tau\) (tau) 编码了在参数空间中将合成训练模型转换为真实训练模型所需行进的“方向”。
第二步: 将向量应用于目标
接下来,研究人员选取目标领域 (例如像“烹饪”这样没有真实音频的特定主题) 。他们使用 TTS 生成合成音频并在其上微调模型,得到 \(\theta_{syn}^T\)。
通常,这个模型 (\(\theta_{syn}^T\)) 在真实人类语音上表现不佳,因为它过拟合了合成的 TTS 声音。为了修复这个问题,研究人员将之前计算的这一任务向量 (\(\tau\)) 加到这个目标模型上。
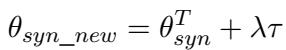
在这个公式中:
- \(\theta_{syn\_new}\) 是最终自适应模型的参数。
- \(\lambda\) (lambda) 是一个缩放因子,用于控制我们应用修正的强度。
可视化转换过程
这个过程可以从几何角度进行可视化。想象模型的参数是地图上的坐标。
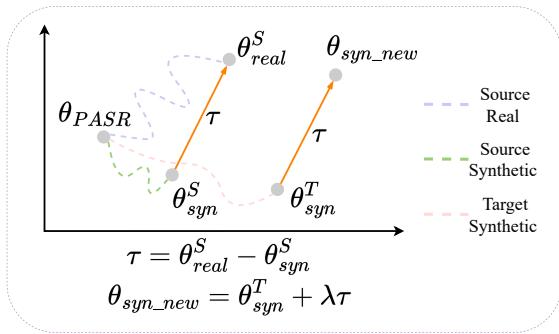
如图 3 所示,向量 \(\tau\) 代表了从源合成 (\(\theta_{syn}^S\)) 到源真实 (\(\theta_{real}^S\)) 的特定偏移。通过将这个相同的向量应用于目标合成模型 (\(\theta_{syn}^T\)) ,我们将模型推向理论上的“目标真实”空间,有效地“引导”权重去处理真实的声学特征。
整个流程的高层概览如下所示:
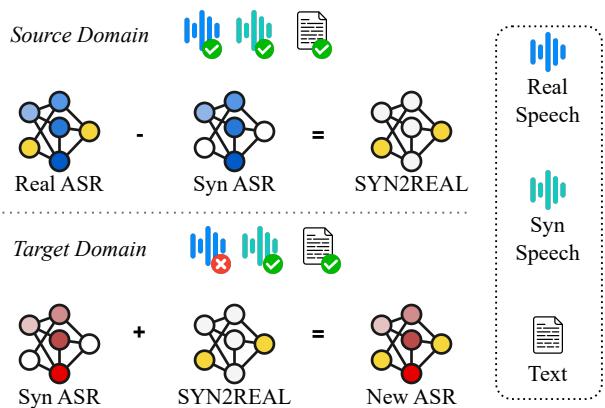
图 1 总结了流程: “源领域”提供了地图 (向量) ,而“目标领域”使用该地图从合成训练导航到真实世界的性能表现。
实验结果
为了证明这一理论,作者在 SLURP 数据集上测试了该方法,该数据集包含针对虚拟助手的命令,涵盖 18 个不同的领域 (如电子邮件、烹饪、音乐) 。
他们将其中一个领域视为“目标” (未见过的真实数据) ,将其余 17 个领域视为“源”数据。他们使用了流行的 TTS 模型,如 BARK 和 SpeechT5 来生成合成数据。
它真的能减少错误吗?
使用的主要指标是词错率 (WER) ——越低越好。

表 1 展示了结果。“目标合成 ASR” (基线) 通常表现挣扎,错误率很高。然而,添加 SYN2REAL 向量后,性能得到了一致的提升。
- 平均提升: 该方法平均带来了 10.03% 的 WER 相对降低 。
- 特定领域的胜利: 像“音乐”和“社交”这样的领域看到了巨大的进步 (相对降低超过 25%) ,这表明该向量有效地捕捉到了简单的合成训练所遗漏的声学细微差别。
模型大小的影响
这是否仅适用于巨型模型,还是较小的高效模型也能受益?研究人员测试了不同大小的 Whisper 模型: Tiny、Base 和 Small。
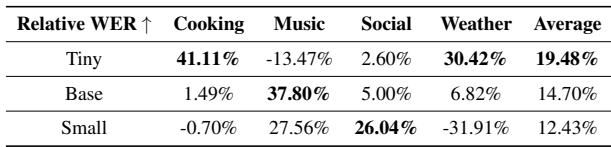
表 2 揭示了一个有趣的趋势。虽然所有模型都受益,但 Base 模型在各领域中表现出的提升最为一致 (14.70%) 。 Tiny 模型波动较大——在“烹饪”领域提升巨大,但在“音乐”领域实际上有所退步。这表明非常小的模型在进行算术权重操作时可能不太稳定。
适用于不同的架构
为了确保这不仅仅是 Whisper 架构的特例,他们在 Wav2Vec2-Conformer 上进行了测试。
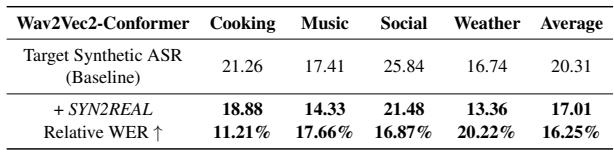
如表 3 所示,该方法成功迁移到了 Wav2Vec2 架构,实现了 16.25% 的平均相对提升 。 这表明“声学向量”的原理是在语音上训练的神经网络的一个基本属性,而不仅仅是特定模型的功能。
缩放 (\(\lambda\)) 的重要性
任务算术中最关键的超参数之一是 \(\lambda\) (lambda)——缩放因子。它决定了有多少“真实”向量被添加到模型中。
- 如果 \(\lambda\) 太低,模型仍会针对合成语音进行优化。
- 如果 \(\lambda\) 太高,权重会被扭曲,模型就会崩溃。
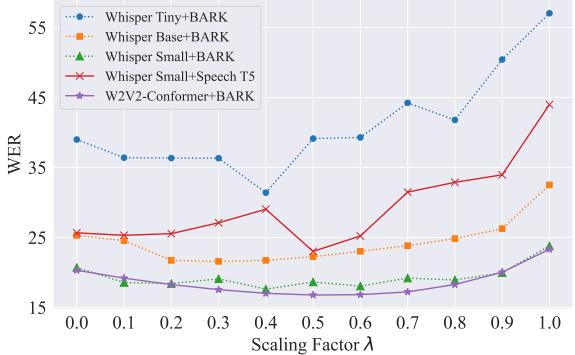
图 4 展示了缩放因子与 WER 之间的关系。大多数模型呈现出 U 型曲线 , “最佳甜区”通常落在 0.3 到 0.6 之间。这证实了虽然向量的方向是正确的,但其幅度需要仔细调整,以避免覆盖模型在合成训练期间学到的文本知识。
分析向量
最后,研究人员提出了一个问题: 这些向量真的有意义吗,还是只是随机噪声?他们使用不同的 TTS 系统 (BARK 对比 SpeechT5) 生成任务向量,并使用余弦相似度进行比较。
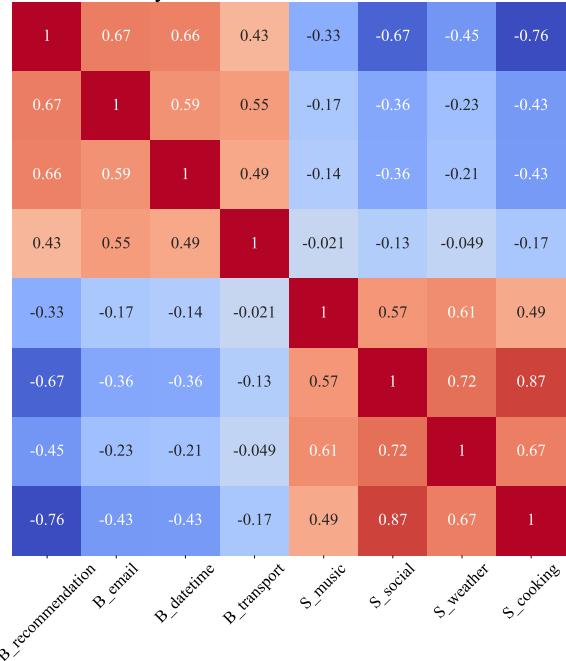
图 5 中的热力图显示,来自相应领域的向量之间具有很高的相似性。这证实了向量确实捕捉到了关于合成语音与真实语音之间差距的一致且有意义的声学信息。
进阶技术: 集成方法
研究人员探索了一种更细粒度的方法,称为 SYN2REAL 集成 (SYN2REAL Ensemble) 。 他们不是从所有源数据计算一个巨大的向量,而是为每个源领域计算单独的向量 (例如,一个“电子邮件”向量,一个“新闻”向量等) ,然后对它们取平均值。
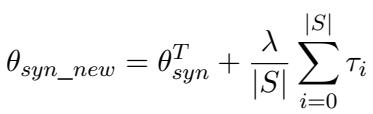
这种集成方法带来了更高的性能提升 (高达 18.25% 的相对提升 ),这可能是因为平均多个特定向量过滤掉了领域特定的噪声,并分离出了纯粹的“合成到真实”的声学信号。
结论与启示
“合成到真实的差距”长期以来一直是将 ASR 模型部署到数据稀缺的利基领域的障碍。标准方法——仅仅在合成数据上训练——往往会导致模型在现实世界中失效。
这篇论文提供了一个计算高效的解决方案。通过使用任务算术 , 我们可以从资源丰富的领域“借用”真实语音的声学特征,并通过数学方法将其注入到资源匮乏的领域中。
主要收获:
- 高效: 此方法不需要为目标领域收集新的真实数据。
- 通用: 它适用于不同的模型架构 (Whisper, Wav2Vec2) 和 TTS 引擎。
- 简单: 核心操作是简单的权重加减法,易于在现有流程中实施。
随着我们迈向模型可以针对特定任务进行即时自适应的未来,像任务算术这样的技术代表了一种转变: 从暴力训练转向对机器智能进行更优雅的数学操作。