](https://deep-paper.org/en/paper/2406.03872/images/cover.png)
你是否有过这样的经历: 告诉朋友“我没事”,但你的语气却清楚地表明你一点也不好?一个好朋友会立刻捕捉到这种语气。他们处理的不只是“没事”这几个字,还有你声音中的音高、迟疑和沉重感——即副语言线索 (paralinguistic cues) ——并做出充满同理心的回应。
现在,想象一下对标准的 AI 助手说同样的话。它处理文本“我没事”,从字面上理解语义,然后很可能回答: “听到这个消息很高兴。” 这种互动感觉冰冷且机械,因为情感语境在从语音转换为文本的过程中丢失了。
随着大型语言模型 (LLM) 向多模态系统演进,理解怎么说变得与理解说了什么同等重要。虽然最近像 GPT-4o 这样的专有模型已经展示了这方面的潜力,但其机制仍然是一个黑盒。
这正是 BLSP-Emo (Bootstrapped Language-Speech Pretraining with Emotion support,支持情感的自举语言-语音预训练) 的研究背景。这篇论文介绍了一种新方法,旨在构建能够理解语义和情感的端到端语音-语言模型,使其能够生成真正具有同理心的回应。
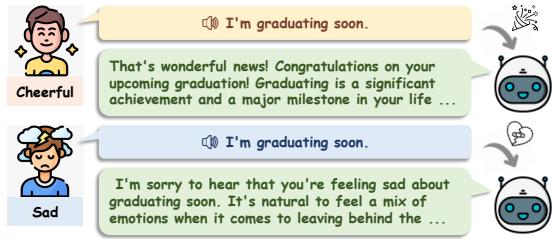
如图 1 所示,我们的目标是建立一个系统,它能根据说话者是听起来兴奋还是伤心,对同一句话 (“我要毕业了”) 做出不同的反应。
当前语音模型的问题
要理解为什么这很难,我们需要看看目前大多数系统是如何处理语音的。
级联方法 (The Cascaded Approach)
最常见的方法是“级联”系统。它按流水线工作:
- ASR (自动语音识别) : 将音频转换为文本。
- LLM: 处理文本并生成文本回复。
- TTS (文本转语音) : 将回复读出来。
这种方法的缺陷显而易见。ASR 步骤剥离了所有的情感信号。愤怒的命令和礼貌的请求变成了完全相同的文本字符串。LLM 永远“听”不到愤怒。
端到端的挑战
端到端模型直接处理语音。然而,训练这些模型通常需要大量的精选数据——具体来说,是配有“同理心”文本回复的语音数据。从人类那里收集这些数据非常昂贵且缓慢。
一些研究人员试图通过使用合成数据 (使用文本转语音工具生成“愤怒”的声音) 来绕过这个问题,但这些模型在面对自然人类语音中混乱且微妙的现实时往往会失败。
BLSP-Emo 方法论
研究人员提出了一种新颖的两阶段方法,利用现有的数据集——标准的 ASR 数据 (语音到文本) 和 SER 数据 (语音情感识别) ——来教 LLM 听懂情绪。他们建立在一种称为 BLSP (自举语言-语音预训练) 的技术之上。
模型架构
该架构简单而有效。它由三个主要部分组成:
- 语音编码器 (Speech Encoder) : Whisper-large-v2 的编码器部分,将原始音频转换为特征向量。
- 模态适配器 (Modality Adapter) : 一个轻量级的连接器,将语音特征转换为 LLM 可以理解的形式 (就像外语翻译器一样) 。
- LLM: Qwen-7B-Chat , 一个强大的指令遵循语言模型。
神奇之处不仅在于各个部件,还在于它们是如何对齐的。
第一阶段: 语义对齐 (“什么”)
在模型能够理解情感之前,它必须首先理解语言。第一阶段确保语音编码器和 LLM 说的是同一种“语义”语言。
研究人员使用了一种行为对齐技术。这个想法很简单: 如果我们把文本转录输入给 LLM,它会预测接下来的词。如果我们把相应的音频输入给语音模型,它应该预测出完全相同的后续词。
他们使用了一个续写提示词 (continuation prompt) 。 对于转录文本 \(x\),他们向 LLM 提问:
“User: Continue the following sentence in a coherent style:
Assistant:”
这将训练数据扩展为一个元组 \((s, x, y)\),其中 \(s\) 是语音,\(x\) 是转录文本,\(y\) 是 LLM 的自然续写。
训练过程最小化了纯文本 LLM 的输出与启用语音的模型输出之间的差异。这在数学上由语义对齐损失 (Semantic Alignment loss) 表示:
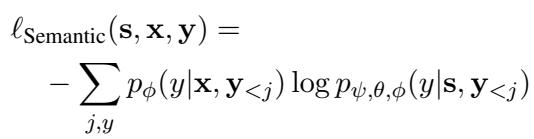
在这里,模型冻结了语音编码器 (\(\psi\)) 和 LLM (\(\phi\)) ,仅训练模态适配器 (\(\theta\)) 。这将语音表示与 LLM 的文本表示空间对齐。
第二阶段: 情感对齐 (“如何”)
这是 BLSP-Emo 的核心创新。一旦模型理解了单词,它需要学会语气会改变含义。
人类通过“副语言”线索——音高、响度、节奏——来传达情感。仅在第一阶段训练的模型会将这些视为噪声。为了解决这个问题,研究人员使用了语音情感识别 (SER) 数据集,其中包含标有情感 (如“悲伤”、“快乐”) 的音频片段。
但仅仅对情感进行分类对于聊天机器人来说是不够的。机器人需要对情感做出回应。研究人员设计了一个巧妙的工作流程:
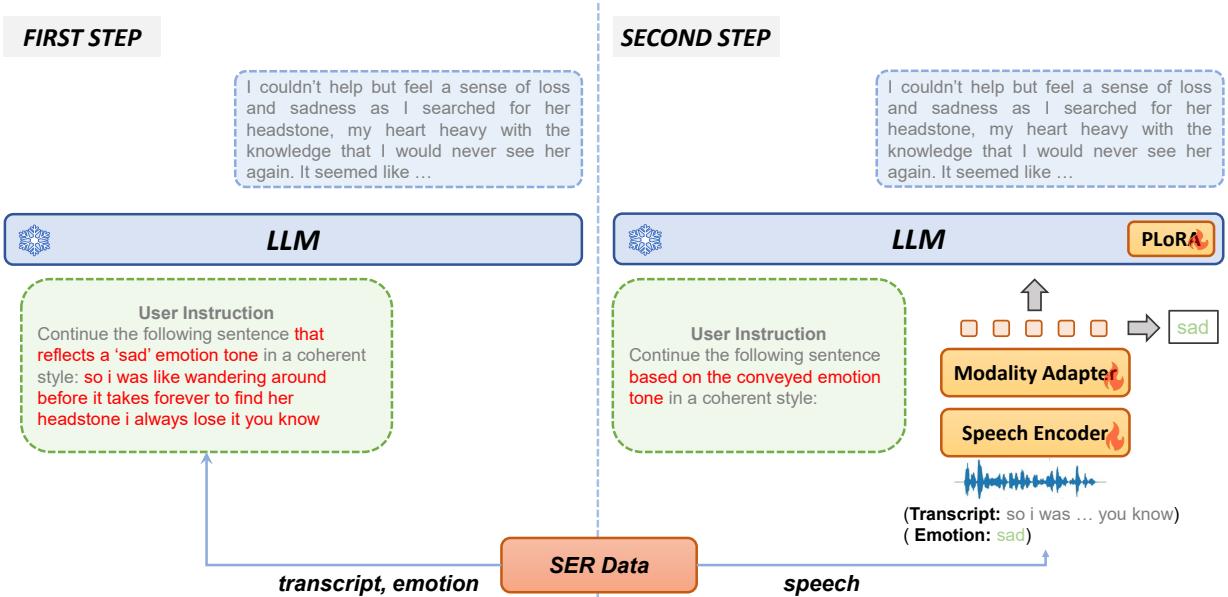
步骤 1: 生成情感感知续写 他们没有让人类编写同理心的回复 (这很昂贵) ,而是让 LLM 根据文本转录和真实情感标签自己构想出回复。
提示词:
“User: Continue the following sentence that reflects a
emotion tone in a coherent style: Assistant:”
如果转录文本是“我要走了”,情感是“悲伤”,LLM 可能会生成: “……我不知道什么时候能回来。我会非常想念这个地方的。”
步骤 2: 在语音上进行训练 现在,模型被训练为在仅给定语音输入的情况下生成那个特定的悲伤续写,而没有被明确告知情感标签。
“User: Continue the following sentence based on the conveyed emotion tone in a coherent style:
Assistant: ”
这迫使语音编码器在音频中寻找线索 (副语言特征) ,以弄清楚句子应该往哪个方向发展。如果音频听起来很悲伤,模型就会学会生成悲伤的续写。
这种情感感知续写的损失函数为:
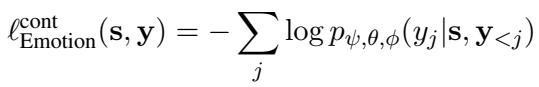
辅助任务 为了进一步帮助模型区分情感,他们添加了一个小的分类头 (一个简单的预测器) ,尝试直接从语音特征中猜测情感类别 (快乐、悲伤、中性等) 。
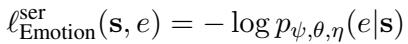
在这个第二阶段,他们解冻了语音编码器和部分 LLM (使用 LoRA,一种参数高效微调方法) 。这使得语音编码器能够适应情感信号,让 LLM 能够调整其生成风格。
实验与结果
研究人员将 BLSP-Emo 与几个基线模型进行了评估对比,包括:
- Whisper+LLM: 一个级联系统 (语音 -> 文本 -> LLM) 。
- BLSP: 仅经过第一阶段 (语义对齐) 的模型。
- WavLM/HuBERT + LLM: 使用专用语音编码器的系统。
- SALMONN: 另一个最近的多模态语音-语言模型。
1. 它能识别情感吗? (语音情感识别)
首先,他们测试了模型是否能正确识别自然语音中的情感。他们提示模型明确输出情感标签 (例如,“中性”、“悲伤”) 。
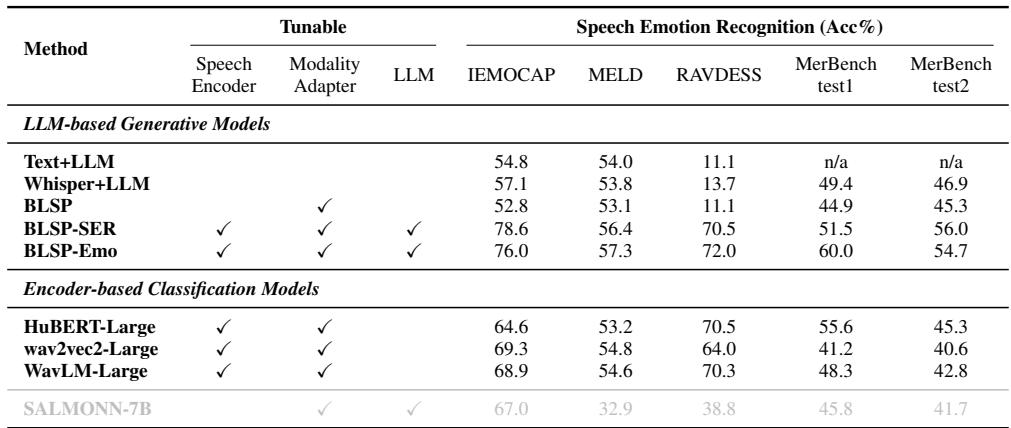
关键结论: BLSP-Emo 在多个数据集 (IEMOCAP, RAVDESS) 上实现了最高的准确率。
- Text+LLM (级联系统) 在像 RAVDESS 这样的数据集上表现非常糟糕 (准确率仅 11.1%) ,因为情感线索在于音频,而非文字。
- BLSP (仅第一阶段) 表现也很差,证明了仅有语义对齐无法教会模型理解情感。
- BLSP-Emo 在 IEMOCAP 上达到了 76.0%,媲美甚至击败了专用的分类模型。
2. 它能表现出同理心吗?
识别情感是一回事;友善地回应是另一回事。研究人员使用合成的情感语音指令创建了一个名为 SpeechAlpaca 的测试集。他们使用 GPT-4 对回复的“质量”和“同理心”进行评分 (0-10 分) 。

在上面的例子中 (表 7) ,请注意区别:
- 用户 (愤怒) : “制定一个做决定的 5 步流程。”
- Whisper+LLM: 给出了一个通用的、事实性的列表。它没有听出愤怒。
- BLSP-Emo: 开头是*“我很遗憾听到你感到愤怒……深呼吸……”*
它根据情绪状态量身定制了建议。
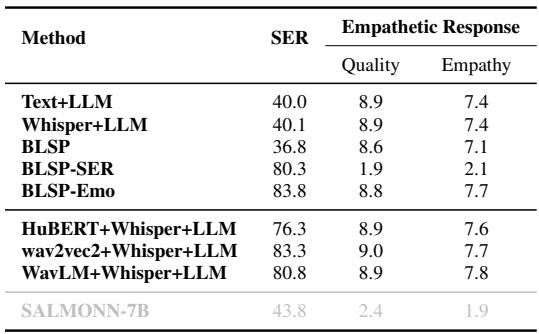
如表 2 所示,BLSP-Emo 在 质量上得分为 8.8 , 在 同理心上得分为 7.7 。
- BLSP-SER (一个仅被训练用于分类情感而非生成文本的版本) 在生成连贯回复方面彻底失败 (质量 1.9) 。
- 级联系统 (Text+LLM) 质量很高但同理心较低 (7.4) ,因为它们错过了语气。
3. 多轮对话
现实生活不仅仅是单一的指令。在多轮对话中,上下文很重要。研究人员在 IEMOCAP 数据集的对话上测试了模型。
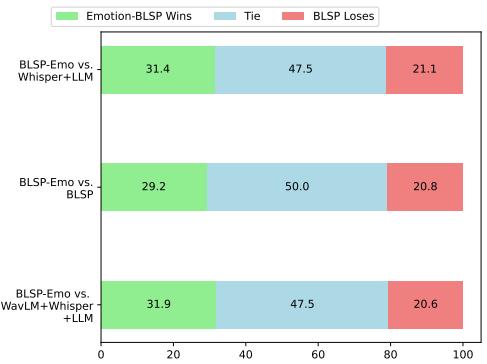
图 3 显示了由 GPT-4 评判的正面交锋对比结果。
- BLSP-Emo vs. Whisper+LLM: BLSP-Emo 在大多数情况下获胜或打平。
- BLSP-Emo vs. WavLM: 有趣的是,BLSP-Emo 优于使用专用情感编码器 (WavLM) 的复杂级联系统。这表明端到端的方法比将单独模块拼接在一起能建立更连贯的对话理解。
为什么这种方法有效: 分析
论文包含了一项有趣的消融实验,证明了他们设计选择的合理性。
“ChatGPT 陷阱”
AI 领域的一个常用技术是使用更强的模型 (如 ChatGPT) 来生成训练数据。研究人员尝试了这一点,创建了一个名为 BLSP-ChatGPT 的模型,其中情感感知续写是由 ChatGPT 编写的,而不是内部 LLM (Qwen) 。

令人惊讶的是, BLSP-ChatGPT 表现更差 (表 5) 。
- 质量: 6.1 vs 8.8 (BLSP-Emo)
- 同理心: 6.0 vs 7.7 (BLSP-Emo)
为什么? 作者推测,当你强迫模型模仿 ChatGPT 的风格时,对齐过程会变得困难。模型浪费了能力去复制 ChatGPT 的“声音”,而不是学习将语音情感映射到它自己的内部语义空间。通过使用自己的 LLM 生成训练目标,任务对于模型来说变得更容易学习,也更一致。
语义对齐的重要性
他们还发现,跳过第一阶段 (语义对齐) 直接进行情感对齐会损害性能。在模型能够在“语音-情感”之上进行分层之前,它需要一个坚实的“语音-文本”理解基础。
结论与未来展望
BLSP-Emo 表明,我们不一定需要大量的人工精选数据集来构建具有同理心的 AI。通过巧妙地利用现有的 ASR 和 SER 数据集,并使用两阶段对齐过程,我们可以将这些能力“自举 (bootstrap) ”到 LLM 中。
其意义重大:
- 更自然的助手: 能够理解你是沮丧还是匆忙的语音助手。
- 心理健康应用: 能够通过声音而非仅仅是关键词来检测求救信号的聊天机器人。
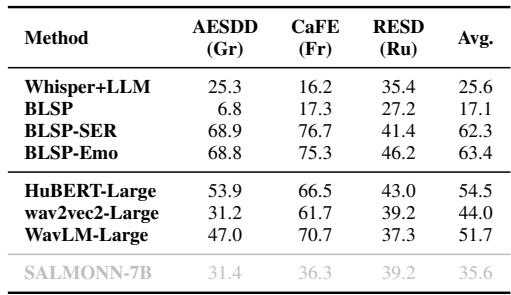
- 跨语言泛化: 该模型在未训练过的语言 (希腊语、法语、俄语) 中表现出了不错的零样本性能,表明声音情感具有普遍特征。
尽管存在局限性——例如依赖于有限的情感类别 (快乐、悲伤、愤怒等) 而不是细微的状态——BLSP-Emo 仍是迈向不仅能听懂文字,还能听懂说话者的 AI 的重要一步。