](https://deep-paper.org/en/paper/2406.04639/images/cover.png)
机器学习模型如何仅通过一两个样本就能学会识别一种新物体?人类能够轻松做到。如果你只看过一张“凤尾绿咬鹃”的照片,你很可能之后也能认出其他的凤尾绿咬鹃。对于人工智能而言,这类挑战属于小样本学习 (few-shot learning) 的范畴——这是一个出了名的难题。其关键在于一个引人入胜的概念: 元学习 (meta-learning) ,即“学习如何学习”。
与其在单一任务上通过大规模数据集训练一个模型,元学习的方法是让模型在许多较小的任务上不断学习。其目标不是掌握每个任务的细节,而是掌握学习的过程本身。这样,当模型面对一个数据极少、从未见过的新任务时,便能迅速适应并有效执行。
模型无关元学习 (Model-Agnostic Meta-Learning,MAML) 是最流行、最具影响力的元学习算法之一。MAML 旨在寻找一组模型权重的初始化参数,为学习任何新任务提供理想的起点。然而,要找到这样真正通用的初始化参数极具挑战性——模型往往会对训练任务过拟合,从而限制其适应能力。
近期的论文《使用梯度增强的协作式元学习》提出了对 MAML 的一个巧妙而高效的改进。它在训练过程中引入了一个临时的协同学习器 (co-learner) ,就像陪练伙伴一样与主学习器协同工作,为学习过程增添有意义的噪声与多样性。训练完成后,这个协同学习器会被移除,只留下一个更好、泛化能力更强的模型。结果如何?你能在不增加任何推理成本的情况下,获得全部收益。
本文将解析这个协作式框架,探讨它为何如此有效,并讨论它对未来学习系统的启示。
背景知识: MAML 快速回顾
在深入了解协作式元学习 (CML) 的创新之前,先回顾一下 MAML 的核心机制。
MAML 通过两个嵌套的优化循环来教模型如何从极少的数据中学习:
内循环——任务适应: 对每个具体的学习任务 (例如猫与狗的分类) ,模型从当前的元初始化参数开始。然后,使用一个小的支持集 (support set) 样本,执行一到几次梯度下降更新。由此得到新的、针对该特定任务的参数。
外循环——元优化: 任务适应后,模型会在另一组不同样本——称为查询集 (query set) ——上进行评估。该集合上的误差用于更新原始元初始化参数。这个“元更新”过程教会模型如何更高效地学习,从而改进未来任务的起点。
在数千个不同任务上重复这一过程,会逐渐将 MAML 的参数引导至一个全局有效的初始化状态——能够快速应对全新挑战的最佳起点。
在典型设置中,模型包含:
- 一个特征提取器 \( \psi \),负责数据表示;
- 一个元学习器 \( \theta \),作为基于这些特征的分类器或回归器。
核心方法: 协作式元学习 (CML)
作者注意到一个问题: MAML 在外循环优化中计算的元梯度往往过于狭窄或出现过拟合。如果能以一种结构化的方式对梯度进行增强,从而促进更好的泛化,会怎样呢?
于是,协同学习器 \( \phi \) 登场。
CML 通过增加第二个分类器头来扩展网络,该头与元学习器 \( \theta \) 共享同一个特征提取器 \( \psi \)。协同学习器提供了一个不同的视角,注入可学习的噪声,从而正则化元优化过程。
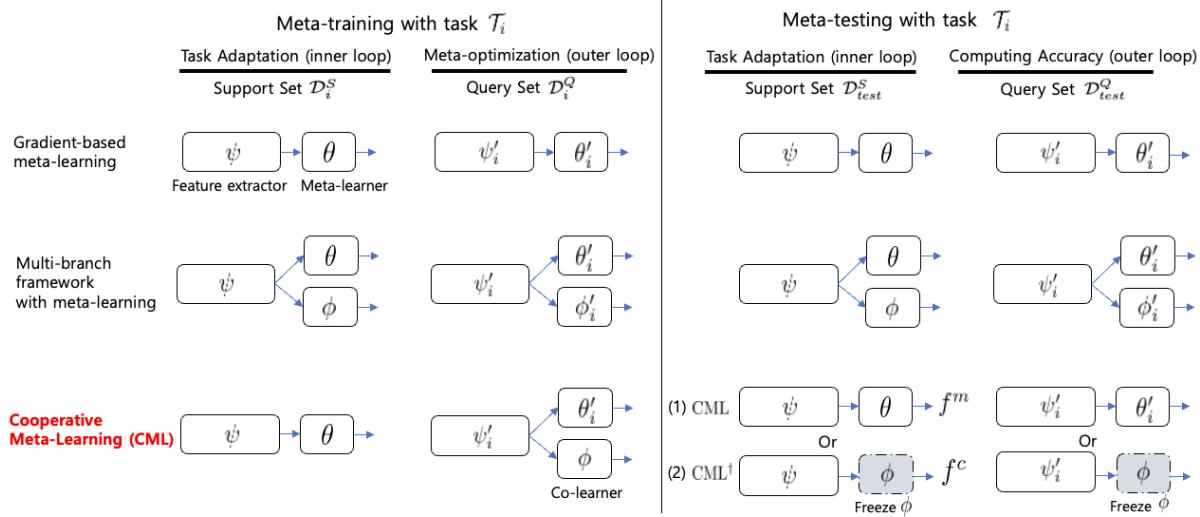
图 1: 总体示意图,比较基于梯度的元学习、多分支框架和提出的协作式元学习 (CML) 。在训练期间,元学习器 \( \theta \) 和协同学习器 \( \phi \) 共享特征提取器 \( \psi \)。协同学习器仅参与外循环,并在测试阶段被移除。
非对称训练过程
CML 的关键在于其非对称的训练策略。让我们来看看一次元训练迭代的过程。
1. 内循环: 元学习器适应,协同学习器保持静止
对于一个给定任务 \( \mathcal{T}_i \),其支持集和查询集分别为 \( \mathcal{D}_i^S \) 和 \( \mathcal{D}_i^Q \):
只有元学习器 \( \theta \) 和特征提取器 \( \psi \) 使用支持集进行更新。协同学习器 \( \phi \) 保持冻结状态——它不随任务而适应。这就形成了非对称性。
\[ (\psi'_i, \theta'_i) \leftarrow (\psi, \theta) - \alpha \nabla_{(\psi, \theta)} \mathcal{L}(f^m_{(\psi, \theta)}; \mathcal{D}_i^S), \quad \phi'_i = \phi \]此时,\( \theta \) 学到了针对当前任务的知识,而 \( \phi \) 保留着来自先前任务的元知识——形成了两个互补的视角。
2. 外循环: 协作式梯度更新
在查询集上进行元更新时,两个学习器共同贡献总损失:
\[ \mathcal{L}_{total} = \sum_{i}^{N}\left[\mathcal{L}\left(f^m_{(\psi'_i, \theta'_i)}; \mathcal{D}_i^{Q}\right) + \gamma\, \mathcal{L}\left(f^c_{(\psi'_i, \phi)}; \mathcal{D}_i^{Q}\right)\right] \]来自两部分的梯度通过共享特征提取器反向传播,结合了“已适应”的视角与“更通用”的视角。这种梯度增强能产生更丰富的更新,无需外部噪声或剪枝即可实现有效正则化。
整体元更新过程如下:
\[ (\psi, \theta, \phi) \leftarrow (\psi, \theta, \phi) - \beta \nabla_{(\psi, \theta, \phi)} \mathcal{L}_{total} \]3. 元测试: 简化推理
训练完成后,协同学习器 \( \phi \) 可被移除。最终模型——只包括 \( \psi \) 和 \( \theta \)——运行方式与原始 MAML 相同,测试时无需额外计算或参数。
作者同时评估了一个变体 \( CML^{\dagger} \),该版本在推理阶段使用协同学习器而非元学习器。令人惊讶的是,它的表现同样优异,这说明共享的特征提取器学到了高度可泛化的表示。
实验: 验证方法有效性
作者通过系统实验来回答三个问题:
- 它是否优于现有的基线方法?
- 它能否适应不同的数据领域?
- 它的成功秘诀是什么?
小样本回归
首先,他们在正弦函数回归任务上进行评估——即给定少量采样点来预测一条正弦曲线。
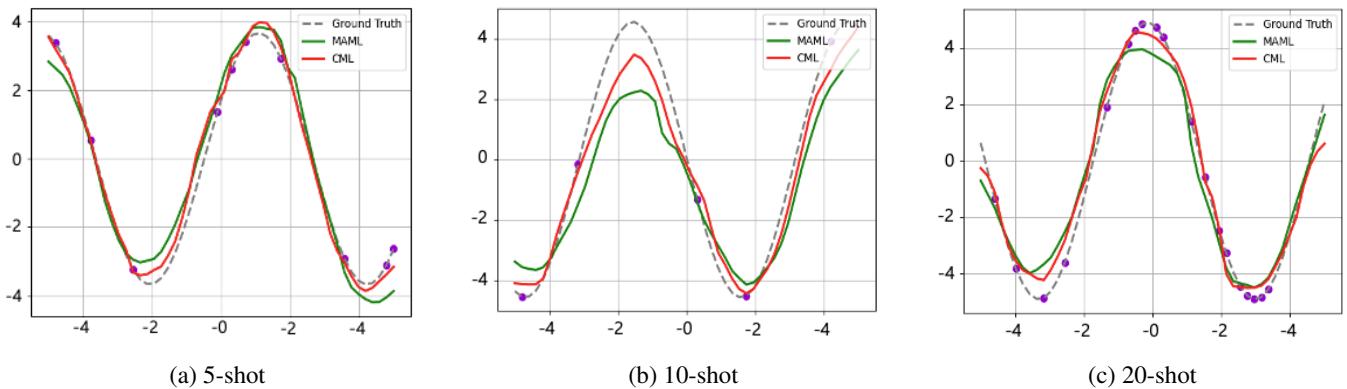
图 2: 在小样本回归任务中,CML 的拟合效果优于 MAML,尤其在低样本场景下 (左侧图) 。
在 5、10、20 样本任务中,红色的 CML 曲线与真实正弦曲线更为吻合,说明协作学习过程即使在简单场景下也能提升泛化性能。
小样本图像分类
CML 被整合到四个常见的 MAML 变体中——原始 MAML、MAML++、BOIL 和 Sharp-MAML——并在 MiniImagenet 数据集上进行了测试。
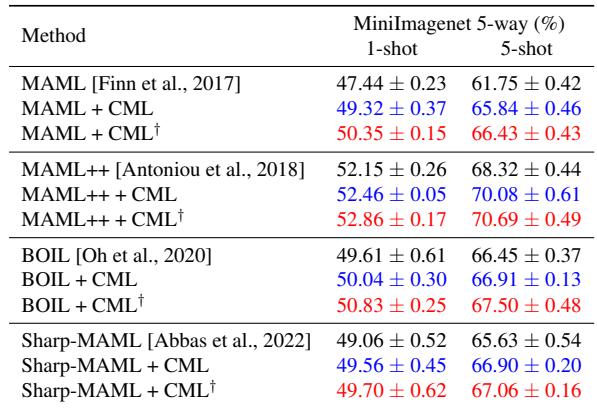
表 1: 在所有基线模型上,添加 CML 均提升了准确率。值得注意的是,MAML++ + CML 在 5 样本任务中达到了 70.08%,而原始模型仅为 68.32%。

表 2: 泛化能力在不同数据集上均得到验证——CML 在每种情况下都提升了结果,且未增加推理成本。
这些结果表明,CML 可以作为一种即插即用式优化器,适用于广泛的基于梯度的元学习算法。
小样本节点分类
为展示其超越图像领域的通用性,作者将 CML 应用于基于图的学习任务,使用 G-Meta 和 AMM-GNN 算法。
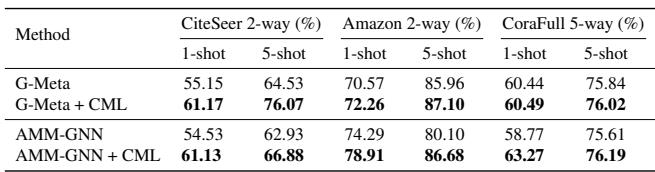
表 3: CML 在图结构的小样本节点分类任务中提升了性能,证明其与 GNN 等架构的良好兼容性。
即便在非欧几里得图域上,CML 仍能提高准确率,彰显了其通用的正则化效果。
探究 CML 的工作原理
定量提升固然喜人,但真正的驱动力是什么?作者对 CML 的梯度与表示进行了深入分析。
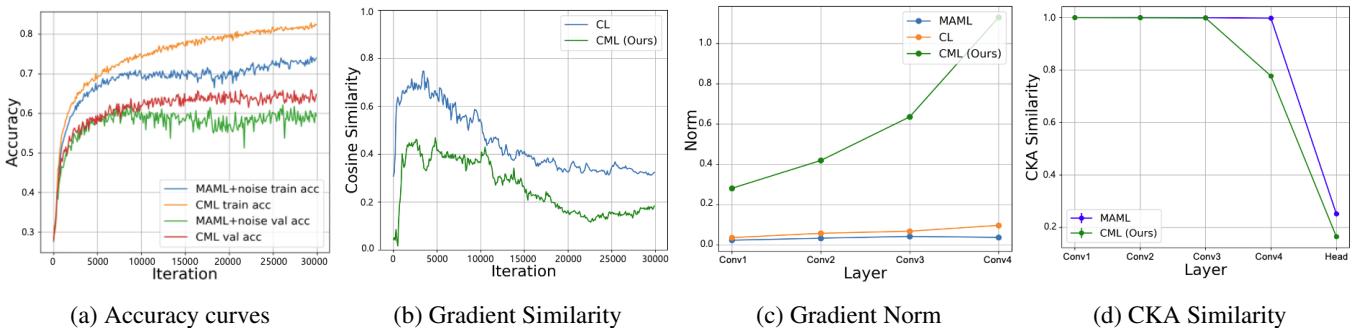
图 3: CML 的学习动态分析。每个子图都验证了协作梯度如何促进泛化。
(a) 结构化噪声 vs. 随机噪声: 向梯度中注入随机高斯噪声可以在一定程度上改善泛化,但远不如 CML 的协同学习器所学得的、有意义的结构化噪声有效。
(b) 梯度多样性: CML 在元学习器与协同学习器之间保持较低的梯度相似性,表明二者从不同视角进行学习。这种多样性稳定了训练过程,并提供更丰富的梯度信号。
(c) 更大的梯度范数: 特征提取器中更高的梯度范数意味着其变化更大、更具动态性——表明 CML 所学的表示具有更强的适应能力。
(d) CKA 表示变化: 通过中心核对齐 (CKA) 比较适应前后的表示,CML 显示出比 MAML 更深层的表示变化。这说明特征提取器不仅在任务间适配输出层,更在表征层面发生演化。
成功仅仅源于参数更多吗?
为验证 CML 的优势是否仅源于额外参数,作者与两个更大基线进行了比较:
- More-MAML: 拓展了网络层数的 MAML 版本;
- CL: 一个多分支训练框架。
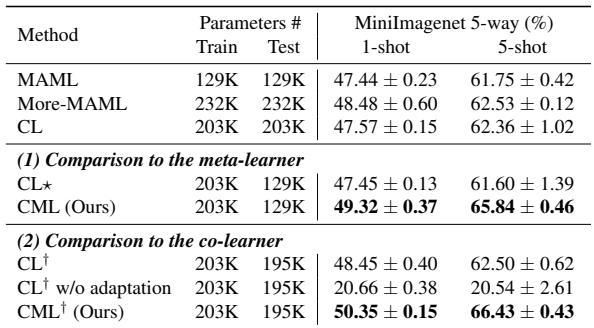
表 4: 参数数量与测试准确率比较。CML 超越了 More-MAML 和 CL,证明性能提升非因模型规模所致。
证据十分明确——CML 的结构设计,而非参数数量,是性能提升的核心原因。
可视化学习到的表示
最后,利用 t-SNE 可视化展示了适应后特征表示的聚类效果。
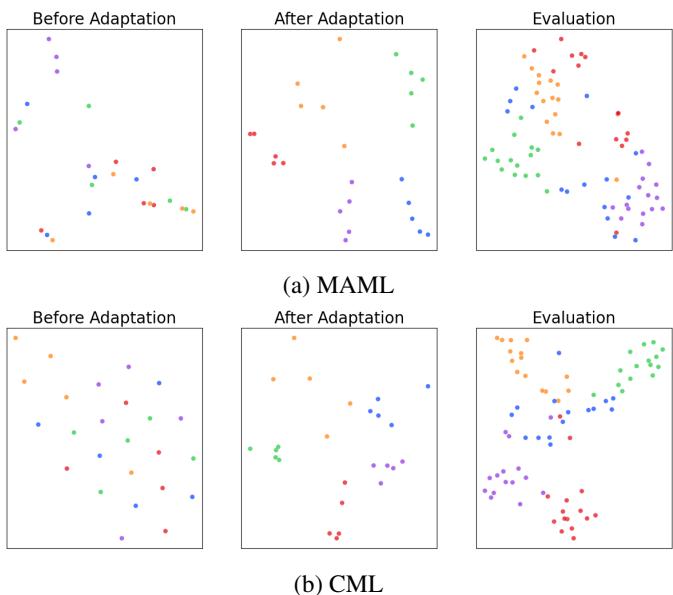
图 4: CML 生成更清晰、分离度更高的簇,说明其学习到的特征在任务间泛化能力更强。
这些图清晰地展现了 CML 的优势: 更内聚、分离明确的特征空间意味着更鲁棒的分类边界和更强的泛化能力。
结论
使用梯度增强的协作式元学习 (CML) 框架表明,提升泛化性可以源于协作,而非复杂化。通过在训练阶段增加一个不适应的协同学习器,CML 以有意义的可学习噪声增强梯度,促进多样性与鲁棒性。
核心要点:
新型正则化机制: CML 的梯度增强通过协作交互而非随机扰动改进元优化。
广泛适用性: 该方法可提升多种基于梯度的元学习算法,适用于图像、图结构与回归等多领域。
零推理成本: 协同学习器仅在训练阶段存在;CML 的推理阶段与 MAML 一样高效轻量。
这篇论文揭示了机器学习中的一个更广泛的真理: 有时,进步并非源自更多的数据或更大的模型,而是源于从多样化的视角进行学习。协作式元学习正体现了这一理念,并启发未来的研究方向——模型或许会更加常态地与“协作伙伴”共同训练,以实现更聪慧、更具泛化能力的智能。