](https://deep-paper.org/en/paper/2406.05013/images/cover.png)
想象一下你正在和朋友聊电影。你问: “谁执导了《盗梦空间》?”他们回答: “克里斯托弗·诺兰。”然后你问: “他还拍过什么其他电影?”
你的朋友能立刻明白“他”指的是克里斯托弗·诺兰。但对于搜索引擎来说,第二个问题简直是噩梦。“他”可以是任何人。为了得到好的答案,搜索系统需要将你的问题重写成独立的句子,比如“克里斯托弗·诺兰执导过什么其他电影?”
这个过程被称为对话式查询重写 (Conversational Query Rewriting, CQR) 。 直到最近,解决这个问题的最佳方法是将对话历史记录扔给一个巨大的闭源模型 (如 GPT-4/ChatGPT) ,让它来修正句子。这虽然有效,但成本高昂、速度慢,且依赖于专有的 API。
但是,如果开源模型 (体积更小且运行免费) 也能做得一样好呢?
在这篇文章中,我们将深入探讨 CHIQ (Contextual History Enhancement for Improving Query Rewriting,即用于改进查询重写的上下文历史增强) ,这是一篇来自蒙特利尔大学和华为诺亚方舟实验室的研究论文。作者提出了一种巧妙的两步法,使得开源模型 (如 LLaMA-2) 能够在对话式搜索中达到最先进的结果,甚至经常击败依赖商业巨头的系统。
问题所在: “上下文”陷阱
在对话式搜索中,用户的意图很少仅存在于当前的句子中;它通常埋藏在对话的历史记录里。
传统方法试图通过训练模型接收历史记录 (\(H\)) 和当前话语 (\(u_{n+1}\)),然后输出重写后的查询 (\(q_{n+1}\)) 来解决这个问题。
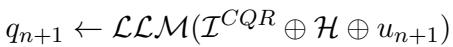
在这个方程中,\(\mathcal{I}^{CQR}\) 是指令提示词 (prompt) 。问题在于,当对话变得复杂时,开源模型 (如 7B 参数版本的 LLaMA 或 Mistral) 历来难以直接完成这项任务。它们可能会漏掉指代关系 (比如将“他”关联到“诺兰”) ,或者被话题转换搞糊涂。
闭源模型通过强大的推理能力来弥补混乱的历史记录。CHIQ 的作者假设,如果我们能在要求模型重写查询之前先“清理”历史记录,开源模型的表现可能并不逊色于商业模型。
解决方案: CHIQ
CHIQ 的核心理念是上下文历史增强 (Contextual History Enhancement) 。 CHIQ 不是让大语言模型 (LLM) 从混乱的记录中“自己看着办”,而是利用 LLM 首先将历史记录提炼成清晰、无歧义的上下文。
研究人员识别了对话中的五种特定类型的歧义,并设计了五种基于提示 (prompt) 的策略来解决这些问题。
第一步: 清理历史记录
在生成搜索查询之前,CHIQ 通过这五个增强模块处理对话历史。这充分利用了即使是较小的开源模型也擅长的基础 NLP 能力。
1. 问题消歧 (Question Disambiguation, QD)
用户经常使用缩略语或模糊的指代。 QD 模块将之前的用户问题重写为独立的句子。
- *原始: * “FDA 怎么样?”
- *增强后: * “食品药品监督管理局 (FDA) 的立场是什么?”
2. 回答扩展 (Response Expansion, RE)
聊天中的系统回复通常很短 (“是的,他做了。”) 。简短的回答对人类来说很好,但对寻找关键词的搜索模型来说却很糟糕。 RE 模块提示 LLM 将之前的回答扩展为包含丰富上下文的完整句子。
3. 伪回答 (Pseudo Response, PR)
这是一个非常有趣的补充。有时,搜索系统需要预测当前问题的答案才能找到正确的文档。 PR 模块要求 LLM “构想” (有依据的猜测) 一个潜在的答案。即使事实并非 100% 正确,生成的词汇也能帮助检索器匹配相关文档。
4. 话题转换 (Topic Switch, TS)
对话会发生漂移。如果你正在谈论《盗梦空间》,突然问“巴黎天气怎么样?”,那么之前关于电影的历史记录就变成了噪音。 TS 模块明确地询问 LLM: “这是一个新话题吗?”
- 如果是 Yes : 截断历史记录,移除不相关的前几轮对话。
- 如果是 No : 保留历史记录。
5. 历史摘要 (History Summary, HS)
长对话会超出模型的 token 限制并引入噪音。 HS 模块将整个交互总结为一个简洁的段落,只保留下一轮对话所需的关键信息。
第二步: 生成查询 (三种方式)
一旦历史记录被增强 (清理、扩展和总结) ,我们要如何获取搜索查询呢?论文提出了三种方法。
方法 A: CHIQ-AD (即时查询重写)
这是最直接的方法。系统直接使用增强后的历史记录而不是原始文本来提示 LLM。它结合了各种增强功能 (通常是 问题消歧 + 回答扩展 + 伪回答) ,并要求 LLM 编写最终的搜索查询。
方法 B: CHIQ-FT (面向搜索的微调)
这种方法旨在提高效率。为每个搜索查询运行一个 LLM (即使是 7B 的模型) 可能会很慢。CHIQ-FT 在离线状态下使用 LLM 创建一个庞大的训练数据集,然后用它来微调一个更小、更快的模型 (如 T5-base) 。
然而,他们并不是使用任何重写后的查询进行训练。他们使用了一个“面向搜索”的筛选过程。
他们创建训练数据的方法如下:
- 他们将增强后的历史记录 (\(\mathcal{H}'\))、用户问题 (\(u_{n+1}\)) 以及——至关重要的是——实际正确的文档 (标准相关段落,gold passage,\(p_{n+1}^*\)) 提供给 LLM。
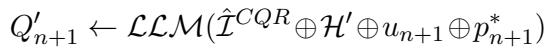
- LLM 生成多个潜在的查询 (\(Q'_{n+1}\))。
- 系统针对检索引擎测试这些查询。它会选择那个能让正确文档获得最高检索分数 (\(S\)) 的特定查询 (\(q'\))。
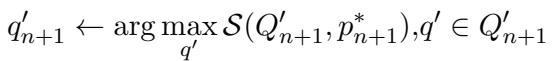
这个过程确保了小模型是基于那些被证明对搜索有效的查询进行训练的,而不仅仅是语言学上正确的查询。
方法 C: CHIQ-Fusion (融合)
为什么要二选一呢? CHIQ-Fusion 同时运行即时方法 (CHIQ-AD) 和微调方法 (CHIQ-FT)。它检索两个文档列表并将它们合并。事实证明这非常有效,因为这两种方法通常能找到互补的信息。
实验结果
研究人员在五个标准基准上测试了 CHIQ,包括 TopiOCQA (具有频繁的话题转换) 和 QReCC 。 他们将基于开源 LLaMA-2-7B 的实现与使用 ChatGPT 和其他复杂检索器的系统进行了比较。
结果令人印象深刻。
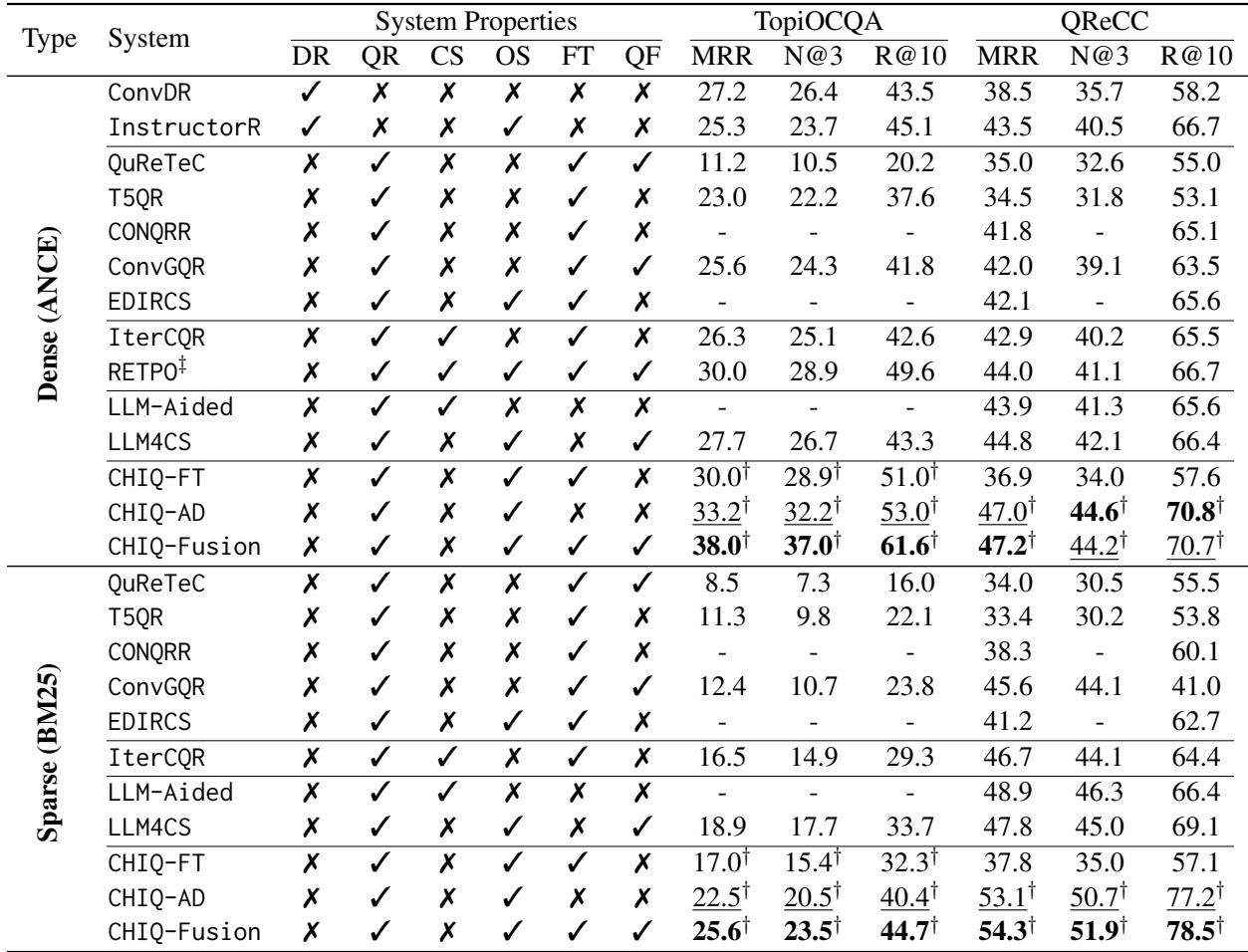
让我们来解析一下表 1:
- 开源领域的最新技术水平 (SOTA): CHIQ-Fusion (通常甚至仅 CHIQ-AD) 的性能显著优于以前微调小模型的方法 (如 T5QR 或 ConvGQR) 。
- 击败闭源模型: 在 TopiOCQA 上, CHIQ-Fusion (MRR 47.2) 击败了使用 ChatGPT-3.5 的 LLM-Aided (MRR 43.9) 。 这是一个巨大的胜利,表明一个经过更好数据预处理的 7B 模型可以击败 175B+ 的模型。
- 融合的力量: 你可以看到 CHIQ-Fusion 始终产生最高的分数 (由粗体数字表示) 。这证实了即时 LLM 推理和微调 T5 模式匹配能找到不同的相关文档。
案例研究: 为什么它有效?
要理解 CHIQ 为什么表现如此出色,我们需要看看标准重写失败但 CHIQ 成功的具体例子。
案例研究 1: 生物学查询
在这个例子中 (表 9) ,用户询问了一系列关于人体新陈代谢的复杂问题。
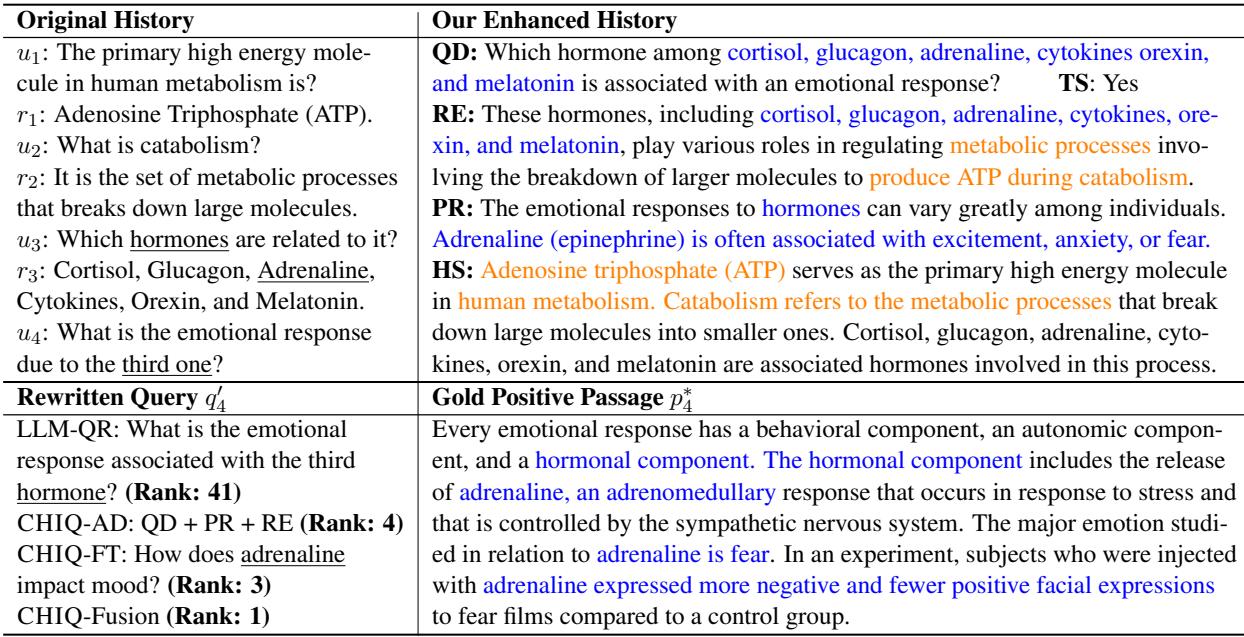
- 问题: 用户问,“由第三种引起的这类情绪反应是什么?”
- 标准重写 (LLM-QR): “与第三种激素相关的情绪反应是什么?”
- 结果: * 排名 41。搜索引擎不知道“第三种”是哪一个*激素,因为列表在上一次对话中。
- CHIQ 增强:
- HS (历史摘要): 明确列出了“皮质醇、胰高血糖素、肾上腺素……”
- CHIQ-FT 查询: “肾上腺素如何影响情绪?”
- 结果: * 排名 3 。 通过在重写之前*将“第三种”解析为“肾上腺素”,系统找到了正确的文档。
案例研究 2: 爵士音乐家
在表 10 中,用户询问关于 Cal Tjader 的专辑。

- 问题: 对话很长,提到了各种合作者。
- 标准重写: “Cal Tjader 和 Jack Weeks 在加州录制了哪张专辑……?” (排名 16) 。
- CHIQ 增强: 伪回答 (PR) 模块构想/预测了相关的标题,如“Inauguration of the Pleasure Dome”。即使预测略有偏差,它也为上下文注入了专辑相关的词汇。
- CHIQ-Fusion 结果: 排名 5 。
意义与未来展望
CHIQ 论文是迈向对话式搜索民主化的重要一步。以下是关键要点:
- 数据质量 > 模型规模: 你并不总是需要更大的模型。有时,你只需要给你的小模型提供更好的输入。通过增强历史记录,LLaMA-2-7B 展现出了远超其参数规模的性能。
- 模块化很重要: 将“重写”这一复杂任务分解为更小的子任务 (消歧、扩展、摘要) ,使得开源模型更容易进行正确的推理。
- 效率: CHIQ-FT 方法表明,我们可以利用强大的 LLM 来训练高效、小型的模型,以便在低延迟要求的生产环境中部署。
CHIQ 证明,开源模型与闭源模型在复杂任务上的差距,不仅可以通过训练更大的模型来弥补,还可以通过设计更智能的管道 (pipeline) 来缩小。对于学生和研究人员来说,这开启了激动人心的途径——无需依赖昂贵的专有 API 即可构建强大的搜索助手。