](https://deep-paper.org/en/paper/2406.05707/images/cover.png)
想象一下,你正在构建一个旨在帮助学生复习历史考试的人工智能辅导老师。你向 AI 输入课本中关于蒙古帝国的一章,并要求它生成测验题。
AI 输出了: *“窝阔台妻子的名字是谁?” (Who was the name of Ögedei’s wife?) *
从语法上讲,这句话有点笨拙。但从技术上讲,如果你查看源文本,单词是匹配的。传统的评估指标可能会给这个句子一个不错的分数。然而,人类学生会觉得这很困惑。
现在,想象 AI 输出了: “名字被刻在第一批印刷作品上的蒙古统治者是谁?”
听起来很完美——流畅、清晰、专业。但是,如果文本实际上说的是一本刻有该名字的道教经文,而不是统治者本人呢?这就成了一个幻觉问题。它听起来是对的,但测试的是错误的信息。
这就是问题生成 (Question Generation, QG) 中的核心问题。随着大型语言模型 (LLM) 变得无处不在,我们正使用它们为教育、聊天机器人和搜索系统生成问题。然而,我们要评估这些问题的方法却停留在过去,依赖于简单的单词匹配指标,无法捕捉细微差别、幻觉或逻辑一致性。
在本文中,我们将深入探讨 QGEval , 这是一篇全面的研究论文,提出了一个新的、严格的 QG 模型评估基准。研究人员认为,我们需要停止只看单一分数,而开始从七个不同的质量维度来审视问题。
当前评估方法的问题
要理解为什么 QGEval 是必要的,我们首先需要看看研究人员目前是如何给 AI 生成的问题打分的。
“黄金标准”陷阱
历史上,问题生成被视为类似于机器翻译的任务。你有一个“参考”问题 (由人类编写) ,然后将 AI 的“假设”问题与其进行比较。
行业标准指标——BLEU、ROUGE 和 METEOR——是基于 n-gram (n元语法) 重叠来计算分数的。简单来说: 它们计算 AI 的问题与人类的问题共享了多少个单词。
这里的缺陷显而易见。在翻译中,“Hello”和“Hi”很接近。在问题生成中,问*“战役是什么时候?”和“战役发生在这一年吗?”*意思完全不同,但可能共享很多单词。相反,AI 可以简单地从文本中复制粘贴一个句子 (单词重叠率高) ,而实际上并没有形成一个有效的问题。
人工评估的混乱现状
认识到自动指标的缺陷后,研究人员通常会转向人工评估。然而,这方面没有标准化的规则手册。一篇论文可能会要求标注者评价“自然度”,而另一篇则要求评价“语法”。有的可能使用 1-5 分制,有的则是 1-3 分制。这种不一致性使得比较不同论文或模型的结果变得不可能。
解决方案: QGEval
研究人员提出了 QGEval , 这是一个旨在解决这些不一致问题的标准化基准。他们的工作不仅仅是一个数据集;它是关于我们应该如何思考 AI 生成文本的一种方法论。
QGEval 的构建遵循了一个严格的两阶段流程,如下图所示。
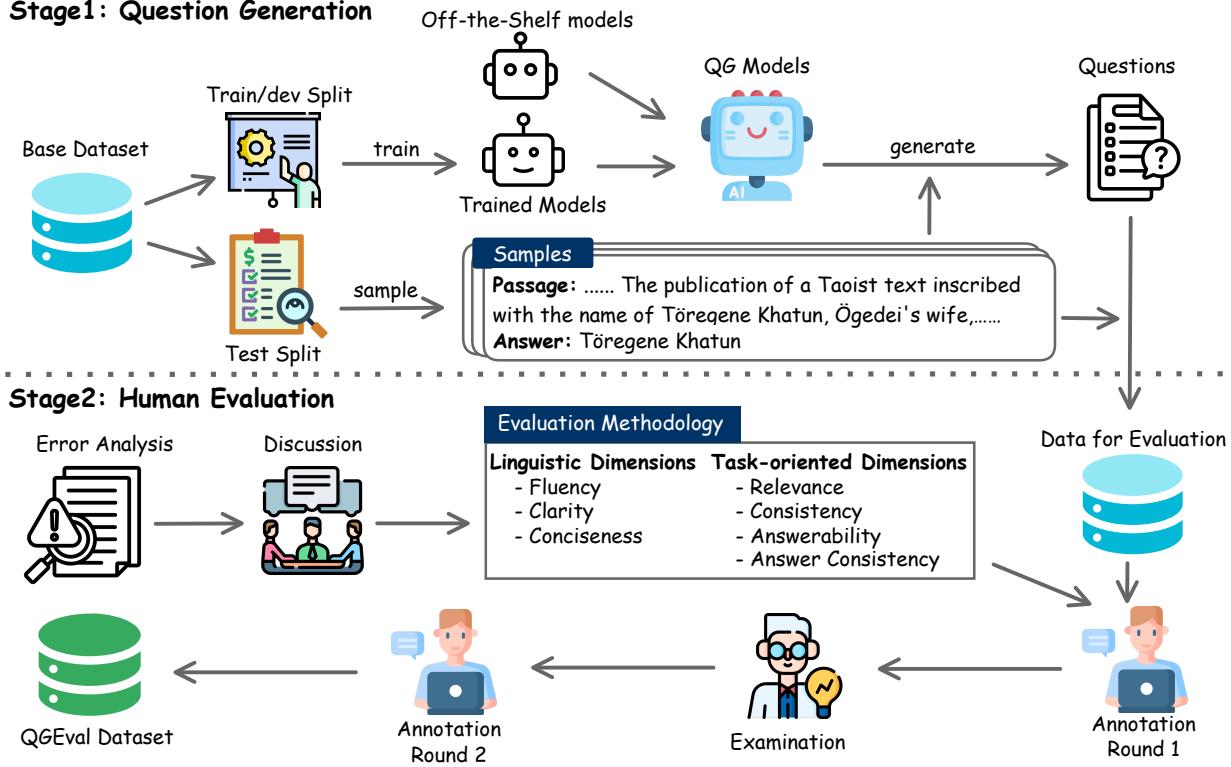
阶段 1: 生成问题
为了创建一个真正代表最先进水平的基准,研究人员并没有只关注单一模型。他们利用了 15 种不同的 QG 模型 , 从较旧、较小的模型如 BART 和 T5,到庞大的现代 LLM 如 GPT-3.5 和 GPT-4。
他们基于两个著名数据集的段落生成了 3,000 个问题:
- SQuAD: 一个阅读理解数据集。
- HotpotQA: 一个需要多跳推理 (连接两条信息) 的数据集。
这种多样性确保了基准测试不会偏向于某一特定类型的架构。
阶段 2: 质量的 7 个维度
这是论文的核心贡献。通过试点实验和错误分析,研究人员发现问题质量不是二元的 (好/坏) 。一个问题可能语法完美但事实错误。它可能事实正确但措辞啰嗦,让人读起来很烦。
他们将评估分为两大类,包含七个维度 :
1. 语言维度 (Linguistic Dimensions)
这些维度衡量文本是否是好的英语表达,无论内容如何。
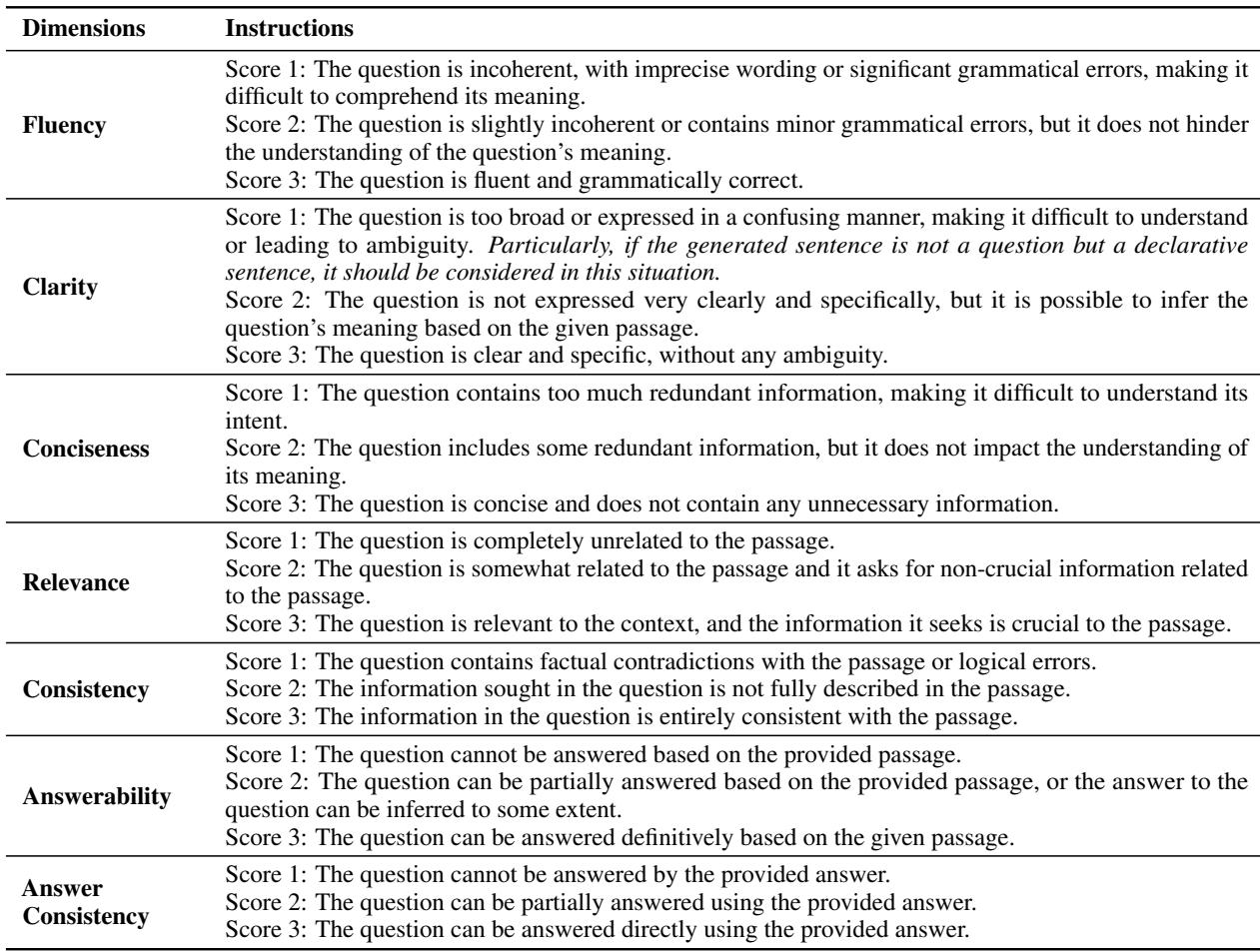
- 流畅度 (Fluency): 问题是否语法正确且结构良好?
- 清晰度 (Clarity): 问题是否无歧义? (例如,避免在没有上下文的情况下使用模糊的代词如“他做了什么?”) 。
- 简洁度 (Conciseness): 问题是否没有冗余和不必要的废话?
2. 任务导向维度 (Task-Oriented Dimensions)
这些维度衡量问题是否真正起到了测试源材料的作用。
- 相关性 (Relevance): 问题是否真的与提供的段落相关?
- 一致性 (Consistency): 问题是否与段落相矛盾? (这用于检查幻觉) 。
- 可回答性 (Answerability): 是否可以仅使用提供的文本来回答该问题?
- 答案一致性 (Answer Consistency): 问题是否与特定的目标答案相匹配?
为了确保这些维度被一致地应用,研究人员为标注者提供了详细的说明。
可回答性和答案一致性之间的区别很微妙但至关重要。
- 可回答性 问的是: “文本中是否有答案?”
- 答案一致性 问的是: “答案是否是我们特定的那个?”
例如,如果目标答案是“1995”,但模型生成的问题是“总统是谁?”,这个问题可能是可回答的 (文本中提到了总统) ,但它在答案一致性上是失败的,因为它忽略了目标答案“1995”。
验证这些维度
在给模型打分之前,研究人员必须证明这 7 个维度确实是必要的。流畅度和清晰度会不会本质上是一回事?
他们对人工标注分数进行了皮尔逊相关性分析。
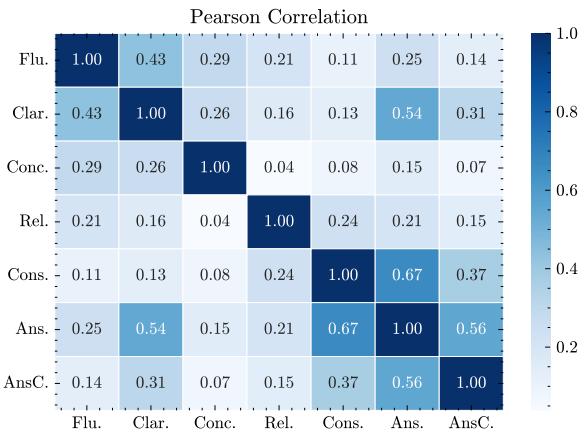
上面的热力图 (左侧) 显示了维度之间的相关性。
- 蓝色表示相关性。 我们看到了中度相关性,这是合理的 (流畅的问题通常更清晰) 。
- 然而,没有相关性接近 1.0。 这证明这些维度是独特的。你可以有一个流畅的问题,但完全不相关 (流畅度高,相关性低) 。你也可以有一个相关的问题,但语法破碎 (相关性高,流畅度低) 。
这证实了仅基于一两个指标进行评估只能提供不完整的模型性能图景。
现代模型的表现如何?
研究人员使用 QGEval 对 15 个模型生成的问题进行了评分。结果揭示了 AI 生成问题的一个有趣趋势。
看看下面的分数分布。柱状图代表获得 1 分 (差) 、2 分 (尚可) 或 3 分 (好) 的问题数量。
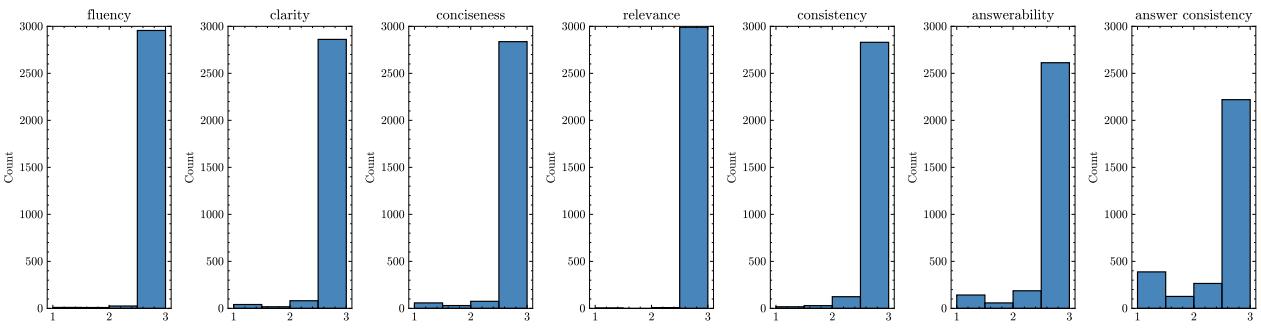
“流利但愚蠢”的现象
注意 流畅度 (Fluency) 和 相关性 (Relevance) 的图表。绝大多数问题都被评为 3 分 (右侧的高柱) 。现代模型,即使是较小的模型,也已在很大程度上解决了生成语法正确的英语的问题。它们知道如何写句子。
现在,看看 可回答性 (Answerability) 和 答案一致性 (Answer Consistency) 。 这里的 1 分和 2 分的柱子比其他类别要高得多。
这些发现暗示:
- 模型产生幻觉: 它们经常生成看起来真实但无法通过文本回答的问题。
- 指令遵循问题: 模型通常难以针对特定答案生成问题,经常偏离主题去问完全不同的事情。
- GPT-4 为王: 在详细的模型细分中,GPT-4 (少样本学习 few-shot) 获得了与人类参考相当的分数,明显优于像 BART 或 T5 这样较小的微调模型。
自动指标的失败
这篇论文最具批判性的部分也许是对现有自动评估指标的分析。研究人员将人类评分 (基本真理) 与 BLEU、ROUGE、BERTScore 以及较新的 QRelScore 等算法得出的分数进行了比较。
如果一个自动指标是好的,它应该与人类判断有很强的相关性。
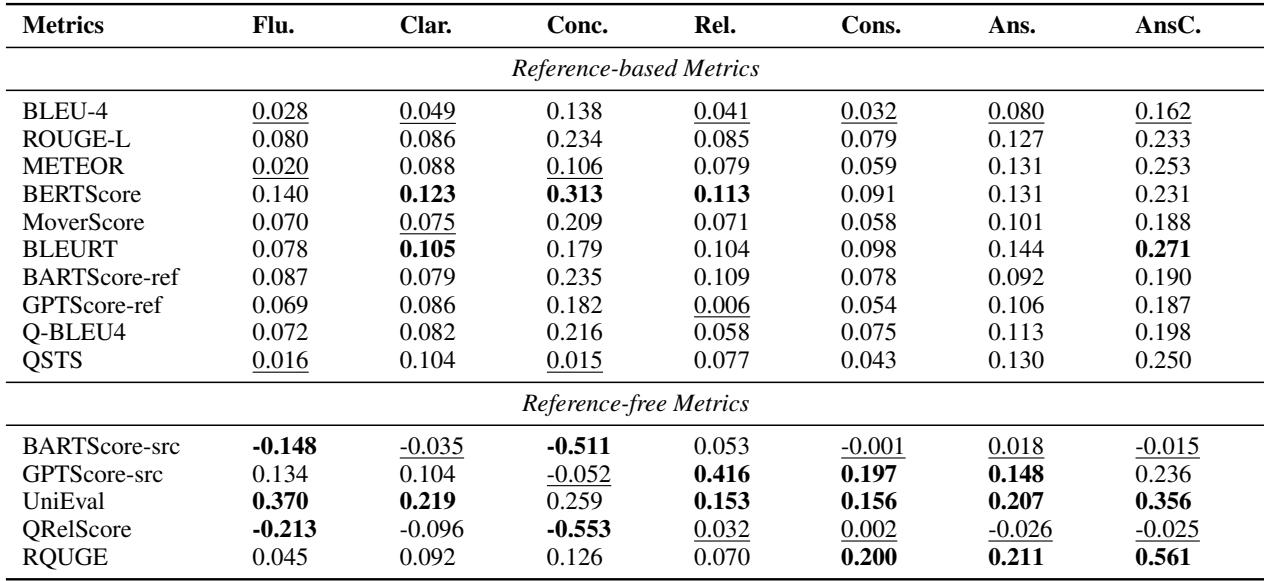
上表中充满了令人失望的低数字。
- 基于参考的指标 (BLEU, ROUGE) : 这些指标在一致性和清晰度等维度上与人类判断的相关性几乎为零。对于这项任务,它们本质上就像随机数生成器。
- UniEval: 这个指标表现最好,在流畅度上的相关性约为 0.37,在答案一致性上约为 0.35。虽然是“最好”,但 0.37 的相关性仍然很弱。
为什么指标会失败: 可视化证据
为了直观地展示这种脱节有多严重,请看下面的小提琴图。这些图展示了对于人类评分为 1、2 和 3 的问题,自动指标分数的分布情况。
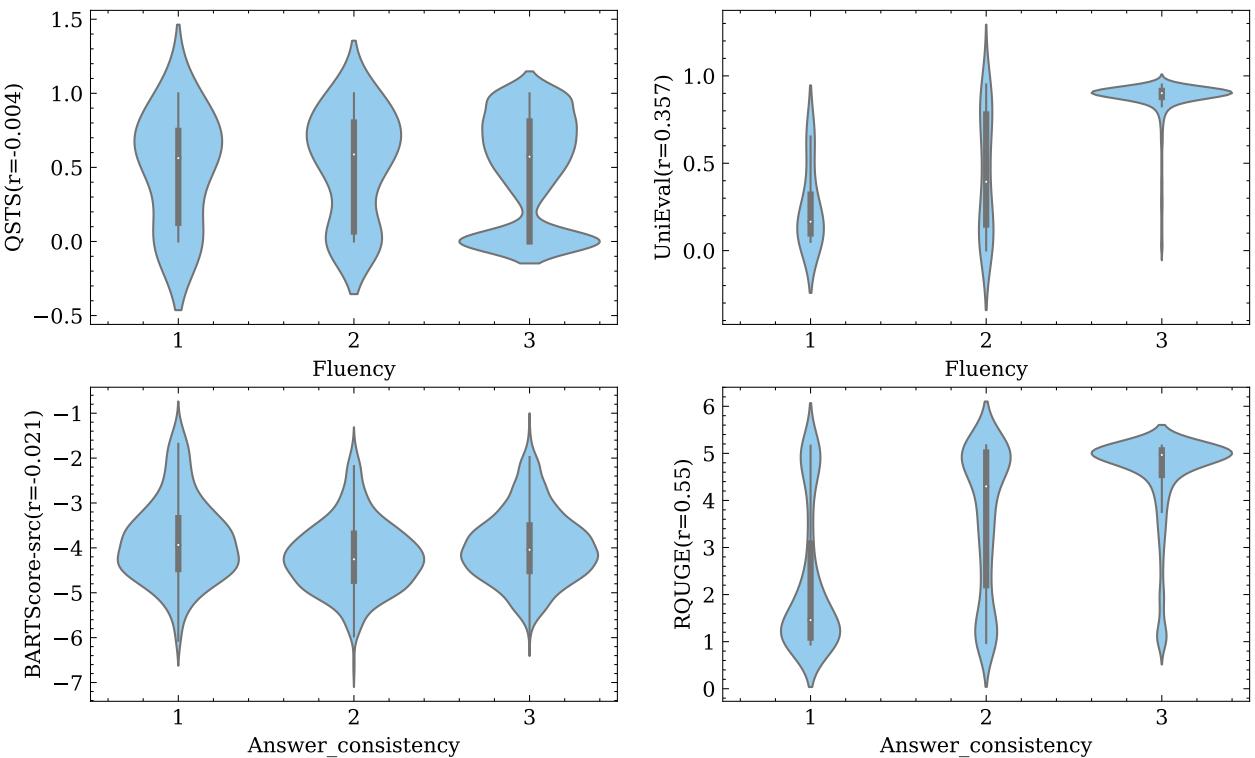
理想情况下,你应该看到阶梯状的模式: 人类评分“1”的分布应该较低,而“3”应该较高。
- 看 QSTS (左上) : 1、2 和 3 分的数据块看起来几乎相同。该指标无法区分糟糕的问题和完美的问题。
- 看 RQUGE (右下) : 这个指标在答案一致性上确实显示出了一些分离 (随着分数上升,数据块上移) ,这也解释了为什么它的相关性数字稍好一些。
对学生和研究人员的启示
QGEval 论文为自然语言生成领域提供了一剂清醒剂。
1. 停止迷信 BLEU
如果你读到一篇论文声称他们的 QG 模型是“最先进的”,仅仅因为它的 BLEU-4 分数提高了 2 个点,请保持怀疑。正如 QGEval 所展示的,n-gram 重叠与问题是否实际可回答或一致几乎没有任何关系。
2. 未来在于“可回答性”
我们已经解决了流畅度问题。生成流畅的文本对现代 Transformer 来说很容易。研究的前沿现在是逻辑和一致性 。 如果你正在研究 QG,你的重点应该是确保模型不会产生超出段落的幻觉信息,并严格遵循目标答案。
3. LLM 作为评估者
论文提到了使用 GPT-4 作为评估者 (使用提示工程要求 GPT-4 对问题进行评分) 。虽然这种方法比传统指标表现更好,但它仍然没有与人类专家完全一致。不过,这是可扩展评估最有希望的方向。
结论
QGEval 为混乱的问题生成评估世界提供了一个急需的框架。通过将“质量”分解为七个不同的维度,它揭示了当前模型的具体弱点——即它们倾向于生成流畅但无法回答的问题。
为了让该领域向前发展,我们必须超越计算匹配单词的阶段,开始衡量真正重要的东西: 学生真的能回答这个问题吗?