](https://deep-paper.org/en/paper/2406.05794/images/cover.png)
检索增强生成 (RAG) 已成为现代 AI 知识系统的骨干。通过结合参数化记忆 (大语言模型的权重) 与非参数化记忆 (外部文档数据库) ,我们可以构建出能够回答最新、特定信息问题的系统。
但任何构建过 RAG 系统的人都知道一个不可告人的秘密: 检索器充满噪声。
如果用户提出一个问题,而检索器抓取了不相关的文档,生成器 (LLM) 就会陷入困境。它可能会试图从糟糕的上下文中强行拼凑答案,导致幻觉 (hallucinations) ;或者它可能会完全忽略上下文,导致回答缺乏引用依据。标准的检索器提供相似度分数,但这个分数是相对的——它告诉你文档 A 比文档 B 更好,但它不会告诉你文档 A 是否真的有用。
在这篇文章中,我们将深入探讨 RE-RAG , 这是由首尔大学的研究人员提出的一个框架。RE-RAG 引入了一个 相关性评估器 (Relevance Estimator, RE) ——这是一个判断检索到的上下文绝对质量的模块。这使得系统能够过滤噪声、更准确地加权答案,甚至决定何时说“我不知道”或依赖其内部知识。
传统 RAG 的问题
为了理解为什么需要 RE-RAG,让我们看看标准工作流程。在传统的 RAG 设置中 (特别是 RAG-Sequence) ,流程如下:
- 检索 (Retrieve) : 用户提出问题。双编码器 (如 DPR) 根据向量相似度找到前 \(k\) 个文档。
- 评分 (Score) : 系统根据相似度分数为每个文档分配一个概率。
- 生成 (Generate) : LLM 为每个文档生成一个答案。
- 边缘化 (Marginalize) : 通过将概率求和 (以文档得分为权重) 来计算最终答案的可能性。
对这些文档进行加权的数学基础依赖于相似度分数 \(S_{i,j}\) (问题和上下文嵌入的点积) 。
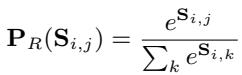
这里,\(P_R\) 是分配给检索到的文档的概率。然后使用此概率对生成概率 \(P_G\) 进行加权:
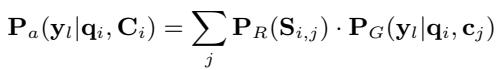
缺陷: 相似度分数 \(S_{i,j}\) 是经过训练以对文档进行相对排名的 (对比学习) 。它没有被训练成衡量文档对生成实际有多大用处的校准概率。检索器可能会返回 5 个都不相关的文档,但由于 Softmax 函数强制它们之和为 1,模型会将“最不坏”的文档视为高度相关。
当查询伴随着不相关的上下文时——这在开放域问答中是非常常见的情况——这种错位会导致性能下降。
解决方案: RE-RAG 框架
作者提出了 RE-RAG,它在检索和生成步骤之间插入了一个 相关性评估器 (Relevance Estimator, RE) 。 RE 不仅仅是排名;它还进行分类。
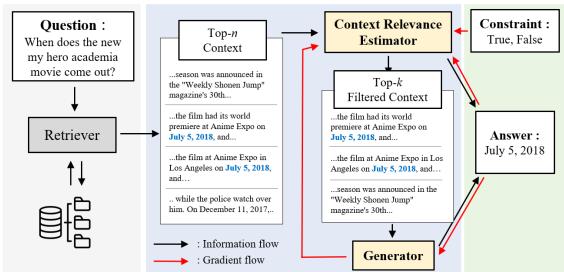
如上图 1 所示,工作流程发生了显著变化:
- 检索器 (Retriever) : 获取前 \(n\) 个候选上下文。
- 上下文相关性评估器 (Context Relevance Estimator) : 这个新模块评估每个上下文并输出置信度分数 (为“真”的概率) 。
- 过滤与重排序 (Filter & Rerank) : 系统过滤掉低置信度的上下文,并对剩余的上下文进行重排序。
- 生成器 (Generator) : 生成器仅使用高质量、过滤后的上下文来合成答案。
1. 相关性评估器 (RE)
RE 不是一个简单的二元分类器。它实际上是一个序列到序列模型 (如 T5) ,将问题和上下文作为输入。然而,它不是生成文本,而是被训练来生成一个特定的 分类标记 : “true” (真) 或“false” (假) 。
这种方法的精妙之处在于他们如何计算相关性分数。他们将“true”标记的概率针对“true”和“false”概率之和进行归一化。
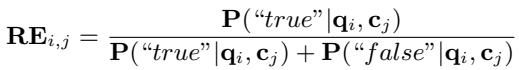
这个 \(RE_{i,j}\) 分数代表了上下文 \(c_j\) 对回答问题 \(q_i\) 有用的 置信度 。 与无界且相对的向量相似度不同,这个分数基于关于查询的“真”与“假”的语义理解。
2. 将 RE 集成到生成中
一旦 RE 提供了一个分数,RE-RAG 就会使用它来改进最终的答案生成。该框架用这些精确的 RE 分数替换了模糊的检索器相似度分数。
首先,RE 分数被转换为 Logit (\(\sigma\)) ,使其在数学上与 Softmax 运算兼容:
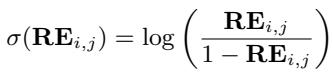
然后,这些 Logit 被归一化,以在检索到的上下文中创建一个新的概率分布:
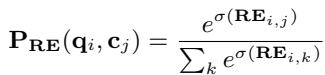
最后,这个校准后的分布 \(P_{RE}\) 取代了答案边缘化方程中的旧 \(P_R\)。现在的生成器会严格按照 RE 确定的实际相关性比例来关注文档。
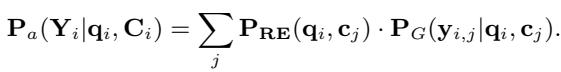
无标签训练: 弱监督
训练相关性评估器的一个主要挑战是数据。我们有 (问题,答案) 对的数据集,但我们要很少有标记为 (问题,上下文,上下文是否相关?) 的数据集。标注成千上万个文档的相关性既昂贵又缓慢。
研究人员提出了一种巧妙的 弱监督训练方法 。 他们使用生成器本身来教导相关性评估器。
直觉
如果特定的上下文帮助生成器产生了正确的真实答案,那么该上下文很可能是相关的。如果生成器在给定上下文的情况下无法产生正确的答案,那么该上下文很可能是不相关的。
方法
他们定义了一个“代理”相关性分布 \(Q_G\)。这是通过检查给定特定上下文 (\(c_j\)) 时真实答案 (\(a_i\)) 的对数似然来计算的。
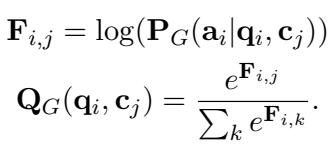
在这里,\(F_{i,j}\) 衡量生成器使用上下文 \(j\) 编写正确答案的容易程度。如果 \(F_{i,j}\) 很高,则上下文是好的。
然后训练相关性评估器以匹配此分布。损失函数最小化 RE 的预测相关性 (\(P_{RE}\)) 与生成器的实际表现 (\(Q_G\)) 之间的 KL 散度 (KL Divergence) 。
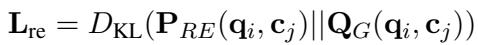
这这就产生了一个正反馈循环:
- 生成器学习回答问题。
- RE 学习哪些上下文对生成器帮助最大。
- RE 降低糟糕上下文的权重,帮助生成器专注于好的数据。
总训练目标结合了标准生成损失、RE 蒸馏损失 (KL 散度) 和一个约束损失,以确保 RE 仅生成“true”或“false”标记。
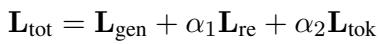
实验结果
研究人员在两个主要的开放域问答基准测试上测试了 RE-RAG: Natural Questions (NQ) 和 TriviaQA (TQA) 。 他们将自己的方法与标准 RAG、Fusion-in-Decoder (FiD) 以及各种基于 LLM 的方法进行了比较。
1. 整体表现
结果表明,添加相关性评估器显著提高了性能。
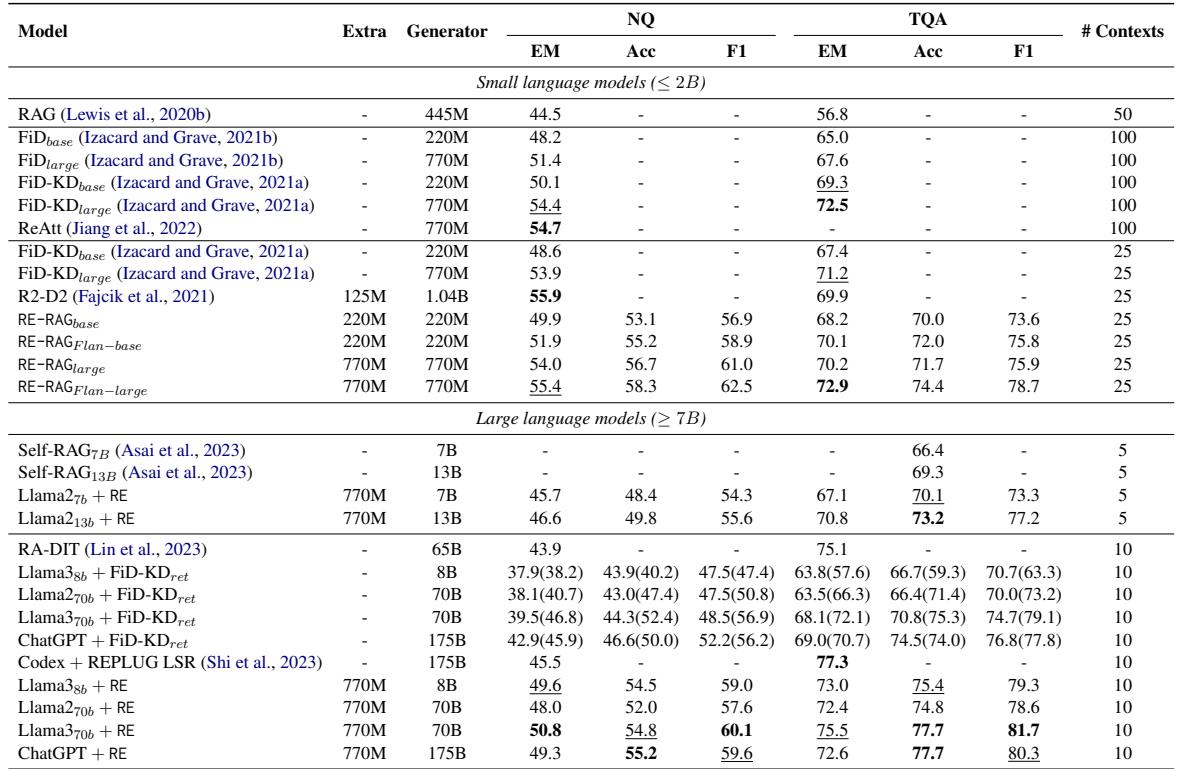
查看 表 1 , 我们可以看到:
- 小模型 (≤ 2B) : RE-RAG (使用 T5-Large) 在 Natural Questions 上达到了 54.0 EM , 超过了标准 RAG (44.5) ,甚至超过了大型 Fusion-in-Decoder 模型 (51.4) 。
- 大模型 (≥ 7B) : 当 RE 模块应用于 Llama-2 (7B/13B) 和 Llama-3 (8B/70B) 时,它始终比标准 RAG 设置提高性能。例如,Llama-3-70B + RE 在 NQ 上达到 50.8 EM , 击败了基线 Llama-3-70B + FiD-KD 检索器 (39.5) 。
2. RE 作为重排序器
RE 在对文档排序方面真的比检索器更好吗?
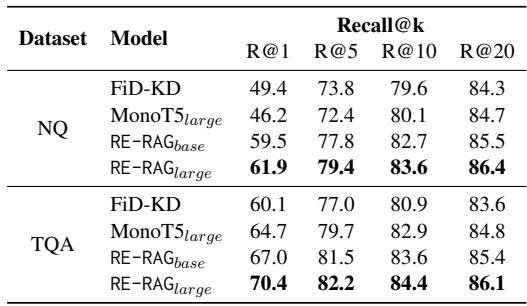
表 2 证实了这一点。在 Natural Questions (NQ) 上,RE-RAG (Large) 模型实现了 Recall@1 为 61.9 , 而 FiD-KD 检索器仅为 49.4。这意味着对于 61.9% 的问题,RE 成功地将相关文档放在了第一位。
3. 消融实验
为了证明 重排序 (过滤) 和 评分 (加权) 都很重要,作者进行了消融实验。
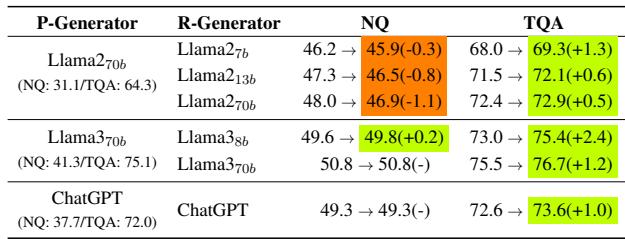
表 6 中的结果说明了一切:
- 基线 RAG: 39.5 EM。
- 仅使用 RE 重排序: 46.8 EM (大幅提升) 。
- 仅使用 RE 评分: 43.1 EM (中度提升) 。
- 两者都用: 49.6 EM。
这验证了框架的设计: 你需要向模型展示正确的文档,并且告诉模型应该在多大程度上信任它们。
高级解码: 知道何时放弃
RE-RAG 最令人兴奋的意义之一是 可解释性和置信度 。 因为 RE 输出的是校准后的相关性概率,我们可以利用它在决策时进行调整。
策略 1: “无法回答”阈值
在许多实际应用中,错误的答案比没有答案更糟糕。如果 RE 为 所有 检索到的上下文分配的置信度分数都很低,系统可以选择输出“无法回答 (Unanswerable) ”。
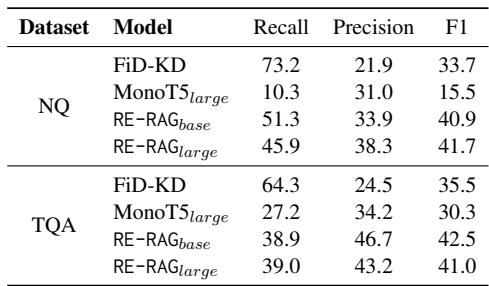
表 3 显示,RE 在识别无法回答的场景方面比检索器好得多。RE-RAG 在 NQ 上分类“无法回答”集合的 F1 分数为 41.7 , 而标准检索器仅为 33.7 。 这种精确度允许开发人员设定一个阈值,让模型保持沉默而不是产生幻觉。
策略 2: 参数化与上下文知识
大语言模型 (如 Llama-3-70B) 拥有巨大的内部 (参数化) 知识。有时,检索实际上会引入令人困惑的上下文,干扰 LLM 已经知道的事实,从而损害性能。
研究人员提出了一种混合策略:
- 如果 RE 置信度 高: 使用 RAG (依赖上下文) 。
- 如果 RE 置信度 低: 忽略上下文,让 LLM 根据记忆回答 (参数化) 。
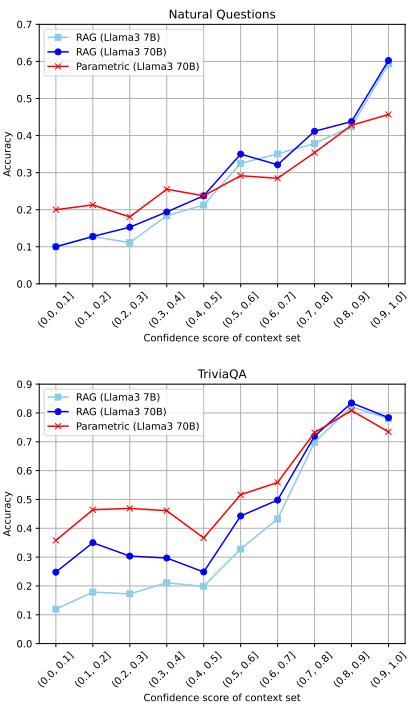
图 2 完美地展示了这种动态。
- 上图 (NQ): 准确率通常与置信度正相关。
- 下图 (TriviaQA): 看右边。当置信度高时,RAG 有帮助。但请看 Llama3 70B (绿线 vs. 橙线) 。 参数化模型 (绿色) 本身实际上非常强大。
- 策略: 通过在检索置信度低时切换到参数化模型,作者实现了显著的收益,特别是在 TriviaQA 上 (见论文正文中的表 5) ,将 Llama-3-8B 的性能从 73.0 提升到了 75.4。
对未见数据的泛化
最后,对训练好的重排序器的一个常见担忧是过拟合。RE-RAG 是否仅在其训练的数据集上有效?
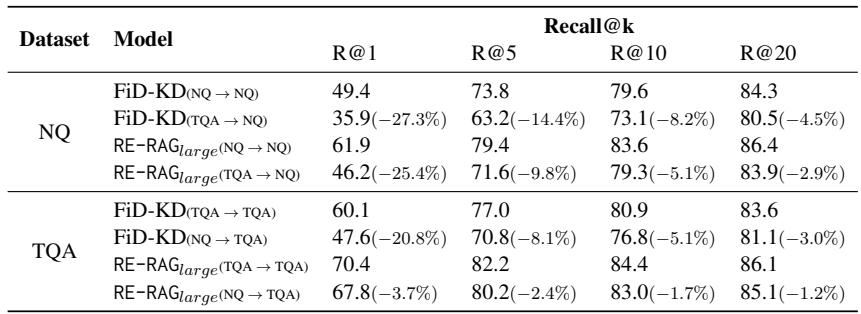
表 7 展示了跨数据集评估。
- NQ → TQA: 当在 Natural Questions 上训练并在 TriviaQA 上测试时,RE 模块的性能仅下降了 3.7% 。
- 比较: 在同样的情况下,基线 FiD-KD 检索器下降了惊人的 20.8% 。
这表明相关性评估器学习到了“问题-上下文相关性”的通用概念,而不仅仅是死记硬背特定数据集的模式。
结论
RE-RAG 解决了检索增强生成的一个根本性“盲点”: 即假设检索到的文档总是相关的。通过引入一个通过弱监督训练的相关性评估器,该框架实现了三个关键的胜利:
- 更高的准确性: 它显式地过滤噪声并正确地加权证据。
- 模块化: RE 可以在小模型 (如 T5) 上训练,并成功指导大模型 (如 Llama-3-70B) 。
- 安全性与控制: 置信度分数使系统能够拒绝糟糕的上下文或回退到内部知识,从而减少幻觉。
对于构建 RAG 管道的学生和从业者来说,结论很明确: 仅仅检索是不够的。 要构建稳健的 QA 系统,我们还必须实施机制,在要求 LLM 生成答案之前,验证并判断我们检索到的内容的质量。RE-RAG 为此提供了一个可扩展、数据高效的蓝图。