](https://deep-paper.org/en/paper/2406.11030/images/cover.png)
引言: 火锅困境
想象一下,你走进北京的一家餐馆,点了一份“火锅”。端上来的是一个传统的铜锅,里面是清水加姜片,配上切成薄片的羊肉和芝麻蘸酱。现在,再想象一下在重庆做同样的事情。你面前将会是一锅翻滚的牛油,里面塞满了辣椒和花椒,配菜则是鸭肠。同样的名字,却是完全不同的文化体验。
对于人类来说,这些区别是我们文化脉络的一部分。我们明白食物不仅仅是食材的集合;它与地理、历史和当地传统紧密相连。但对于人工智能,特别是视觉-语言模型 (Vision-Language Models, VLMs) 来说,这种细粒度的文化理解是一个巨大的盲点。
虽然现代 AI 可以轻松识别“披萨”或“汉堡”,但它往往难以理解特定菜系内复杂的区域多样性。为了解决这个问题,研究人员推出了 FoodieQA , 这是一个旨在测试 AI 对中国饮食文化理解极限的数据集。

如 图 1 所示,“火锅”在中国的不同地区千差万别。从广东的乳白色汤底到四川的火红辣油,这些视觉线索讲述着区域身份的故事。FoodieQA 提出了一个关键问题: 最先进的 AI 模型能读懂这些线索吗?还是说它们是“文化盲”?
烹饪 AI 的缺失
在深入了解 FoodieQA 的方法论之前,有必要了解为什么这个数据集是必要的。
以往食品领域的数据集主要关注两件事:
- 食物识别: “这是热狗还是沙拉?” (例如: Food-101) 。
- 食谱生成: “我该怎么做这道菜?” (例如: Recipe1M) 。
然而,这些数据集通常对文化的看法比较粗糙。它们可能只是简单地将一道菜标记为“中餐”或“意餐”,而忽略了即便是在同一省份内,更不用说村与村之间,菜肴也存在差异的事实。它们经常将原产国与文化混为一谈。此外,现有的基准测试大多依赖于从公共网络抓取的图像。这导致了一个被称为“数据污染”的问题——由于像 GPT-4 这样的模型是在互联网数据上训练的,它们很可能已经“见过”测试图像,从而使得评估变得不公平。
FoodieQA 通过关注细粒度的区域多样性并透过独特的收集过程确保数据完整性,从而填补了这一空白。
构建 FoodieQA: 深度文化探索
FoodieQA背后的研究人员并没有只是抓取谷歌图片。他们从零开始构建了一个数据集,以确保它真实地代表了中国餐饮的亲身体验。
1. 扩展地图
传统的中国菜系观点通常集中在“八大菜系” (如川菜、粤菜、鲁菜) 。FoodieQA 将其扩展为 14 种独特的菜系 , 以确保更好的地理覆盖范围,包括新疆菜、西北菜和内蒙古菜。
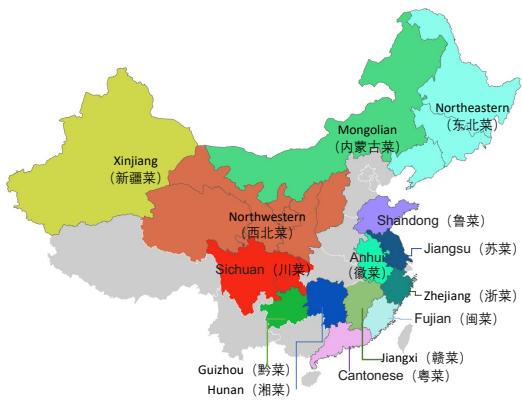
如 图 3 所示,该数据集覆盖了广阔的区域,要求模型能够区分北方以小麦为主的饮食和南方以大米和海鲜为主的饮食。
2. 数据的“新鲜度”
FoodieQA 最具创新性的方面之一是其图像来源。为了防止模型作弊 (即回忆起训练期间见过的图像) ,研究人员直接向当地人众包图像。
参与者被要求上传自己相册里的照片——这些照片从未在社交媒体或公共网络上发布过。这确保了当模型看到 FoodieQA 的图像时,它是第一次见到。
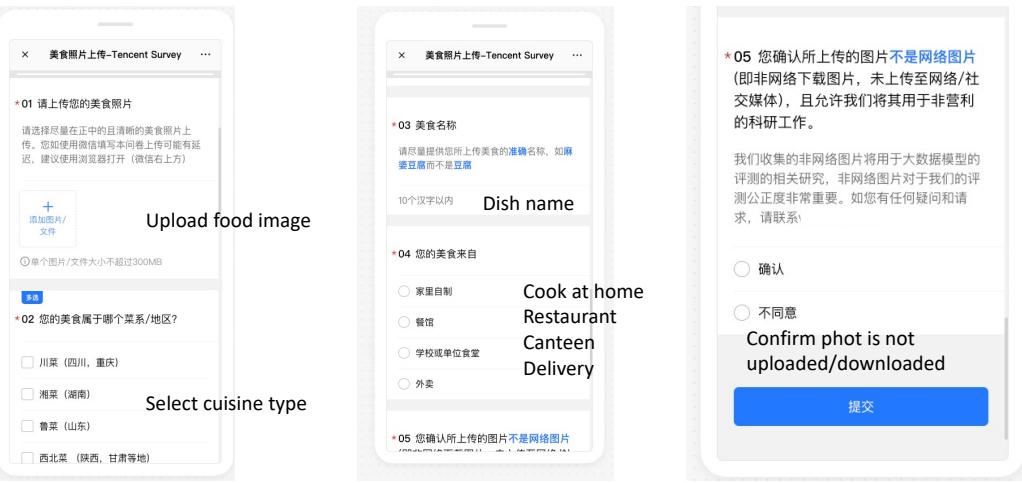
图 11 展示了用于此收集的界面。贡献者必须验证菜系类型、菜名和来源 (家常菜、餐馆等) ,从而保证了高质量、真实的元数据。
3. 三项任务
为了严格测试模型,研究人员设计了三项不同的任务,涵盖从视觉识别到复杂推理的范围。

图 2 提供了这些任务的清晰分类:
- 多图 VQA (菜单测试) : 这可能是最具挑战性的任务。模型会看到四张图片 (就像看带照片的菜单) ,并被问到一个问题,例如“哪一个是川菜中的凉菜?”模型必须比较多张图片中的视觉特征才能找到答案。
- 单图 VQA: 模型看到一张图片,并被问及有关它的细粒度问题,例如“这种食物是哪个地区的特色菜?”重要的是,菜名通常会被隐去,迫使模型依赖视觉线索而不是文本先验知识。
- 文本 QA: 纯文本测试,用于评估模型对饮食文化的百科全书式知识 (例如,“白切鸡的风味特点是什么?”) 。
4. 细粒度标注
为了创建这些问题,母语人士用详细的元数据对图像进行了标注。他们不仅命名了菜肴,还描述了它的风味特征 (咸、辣、酸) 、食材、烹饪技巧 (蒸、炖) 和上菜温度 。
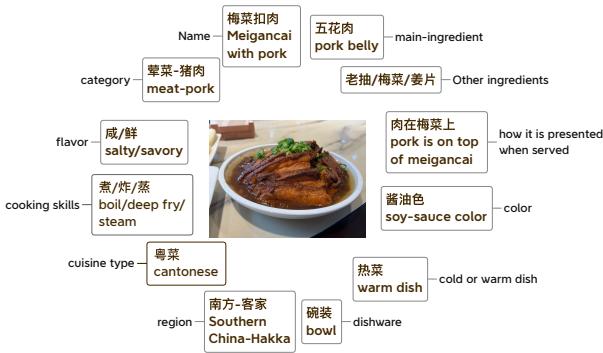
图 4 说明了这种深度。对于像“梅菜扣肉”这样的菜肴,标注捕获了诸如“碗装”、“酱油色”和“客家地区”等细节。这使得问题能够超越简单的识别,深入探索深层次的文化知识。
实验: 这些模型有多“懂吃”?
研究人员对各种模型进行了基准测试,包括开放权重模型 (如 Llama-3、Qwen-VL、Phi-3) 和专有的闭源模型 (GPT-4V、GPT-4o) 。结果揭示了人类理解力与 AI 能力之间的巨大差距。
多图挑战
“菜单测试” (多图 VQA) 被证明对 AI 来说异常困难。
如 图 6 所示,人类在这项任务上的准确率很高( 91.69% )。相比之下,表现最好的开放权重模型 (Idefics2-8B) 仅达到了 50.87% 左右。即使是强大的 GPT-4o,虽然更接近,但也无法与人类的直觉相匹敌。
这表明,虽然模型可以相当好地处理单张图像,但在多张图像之间比较细粒度视觉细节以进行文化推断的能力仍然是一个主要弱点。
单图表现与语言偏见
当任务简化为单张图像时,模型的表现有所提升,但在提示语言方面出现了一个有趣的偏见。
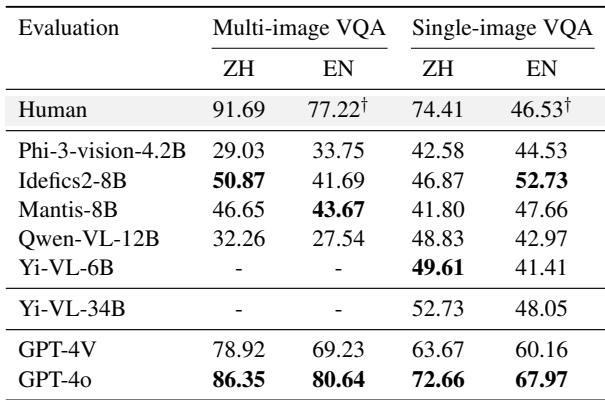
表 3 凸显了语言鸿沟。经过双语训练的模型 (特别是使用中英文数据训练的模型,如 Qwen-VL) 在用中文提问时表现明显更好。相反,一些以西方为中心的模型在英文环境下表现更好,即使是在分析中国食物时也是如此。这表明模型的文化理解与其提示语言紧密相连——这是开发者需要解决的“文化对齐”问题。
网络图像陷阱
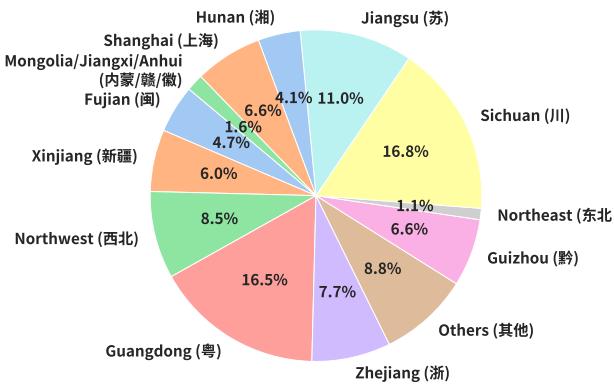
为了证明其私有图像收集的重要性,研究人员进行了一项对照实验。他们测试了模型在其私有图像与网络上找到的相同菜肴图像上的表现。
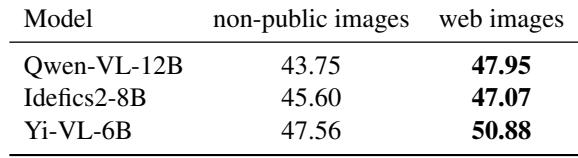
表 4 证实了假设: 模型在网络图像上的得分始终更高。这表明存在“数据污染”。模型很可能在训练数据中“记住”了网络图像或类似的构图。通过使用私有图像,FoodieQA 对模型的实际推理能力提供了更诚实的评估。
深度分析: 模型实际上知道什么?
该研究进一步分析了模型具体在哪些方面出错。它们是在识别食材上失败,还是无法理解食物的“氛围”?
烹饪 vs. 品尝
研究人员按属性对问题进行了分类 (例如,烹饪技巧、风味、地区) 。
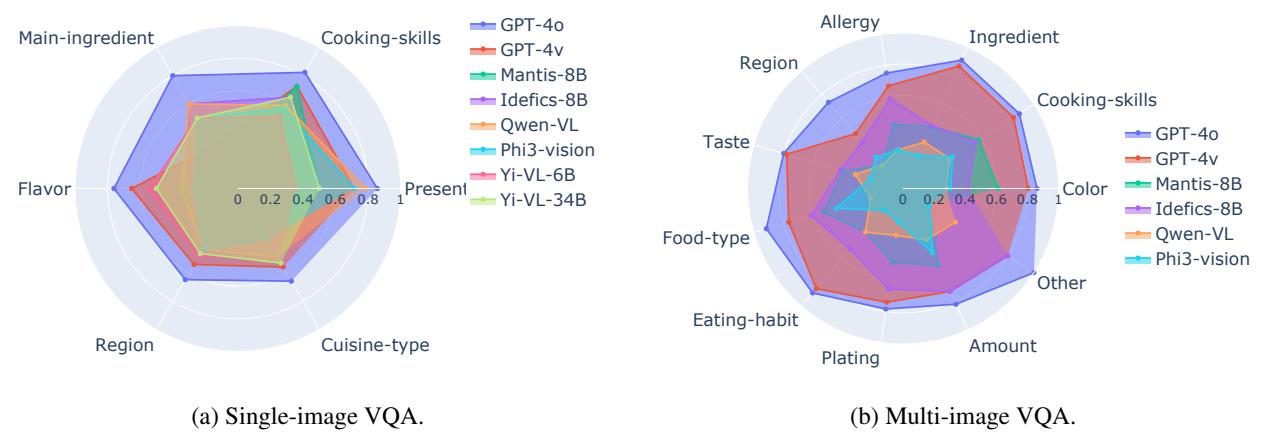
图 12 中的雷达图讲述了一个有趣的故事。
- 强项: 模型通常擅长识别食材和烹饪技巧 。 这些是视觉上的、客观的事实 (例如,“我看到了辣椒”,“我看到了蒸汽”) 。
- 弱点: 模型在风味和地区方面表现挣扎。这些是文化的、主观的属性。你无法“看到”咸味,如果没有深厚的文化背景,也不一定能“看出”特定的碗形状意味着这道菜来自江苏而不是浙江。
模型的表现就像食品科学家,懂化学成分,但从未真正品尝过这顿饭。
视觉的力量
看到食物真的有帮助吗?还是说模型只是根据文本进行猜测?研究人员比较了仅提供菜名与提供菜名加图像时的模型表现。

图 15 (以及论文中的定量数据) 表明视觉信息至关重要。在上面的例子中,文本询问“同安封肉”的风味。如果没有图像,模型可能会猜测。但看到猪肉那光亮、深色的皮和特定的陶罐,有助于模型正确识别“皮酥肉嫩”的质地特征。
然而,这并非绝对。对于某些模型,如果视觉特征很微妙,添加图像实际上会混淆它们,这凸显了当前多模态系统的不稳定性。
结论: AI 的味蕾需要进化
FoodieQA 的推出标志着在评估多模态大语言模型方面迈出了重要一步。它将目标从简单的物体识别转移到了文化推理 。
这项研究的关键结论很明确:
- “断崖”是存在的: 在理解区域饮食文化方面,特别是在多图场景下,人类与 AI 的表现之间存在 20-40% 的差距。
- 数据纯度很重要: 使用私有的、未见过的图像是公平评估这些模型的唯一方法。
- 文化是微妙的: AI 模型掌握了“是什么” (食材) ,但错过了“在哪里”和“为什么” (地区和风味) 。
随着 AI 助手越来越多地融入我们的日常生活——可能帮助我们点餐、烹饪食谱或在异国他乡导航——细粒度的文化理解将成为一种必然需求。FoodieQA 揭示了,虽然 AI 可能能够阅读菜单,但它还没有准备好推荐四川小镇的当地特色菜。
看来,通往通用人工智能 (AGI) 的道路,似乎要先经过胃。