](https://deep-paper.org/en/paper/2406.11049/images/cover.png)
想象一下你在看电影,但你看到的不是完整的影片,而是随机打乱顺序的五秒钟片段。在一个片段中,一个角色指向左边并大笑。在下一个片段中,他们做出一个特定的手形并在空中快速移动。
如果让你准确翻译这些动作的含义,你能做到吗?很可能做不到。不知道谁站在左边,或者前一个场景中确立了什么物体,你只能靠猜。
这本质上就是我们目前处理手语机器翻译 (Sign Language Machine Translation, SLT) 的方式。多年来,研究人员一直像处理基于文本的翻译一样对待手语翻译: 将连续的叙述切成孤立的“句子”,并要求模型逐一翻译。
在论文 “Reconsidering Sentence-Level Sign Language Translation” (重新思考句子级手语翻译) 中,来自 Google 和罗切斯特理工学院 (RIT) 的研究人员认为这种方法存在根本性缺陷。通过一项新颖的人类基线研究,他们证明了手语比口语更严重地依赖语篇级语境 (discourse-level context) ——即先前出现的信息。他们的发现表明,如果忽略语境,我们不仅会让任务变得更难;对于大约三分之一的句子来说,我们甚至让翻译变得不可能。
“句子级”思维的问题
要理解这篇论文的贡献,我们需要先看看当前的标准从何而来。自然语言处理 (NLP) 的许多进步都建立在文本之上。在文本翻译 (如 Google 翻译) 中,孤立地处理句子效果尚可。如果我说是 “The cat sat on the mat” (猫坐在垫子上) ,你不需要阅读前一页就能将其翻译成法语。
当研究人员开始着手解决手语翻译问题时,他们借用了这种“句子级”框架。他们获取连续手语的视频 (如新闻广播或教学视频) ,将其与口语记录对齐,并把视频切成对应英语句子的短片段。然后训练模型将 片段 A 翻译成 句子 A。
这篇论文的作者认为,这种继承是不加批判地采纳的。手语不仅仅是“用手表达的口语”。它们是视觉空间语言,拥有自己独特的语法,与其所在地区的口语截然不同。手语使用者确立意义的方式通常跨越多个句子,这就产生了当我们把视频切成片段时会被切断的依赖关系。
为什么手语需要更多语境
研究人员详细列举了美国手语 (ASL) 中的几种特定语言现象,当你孤立一个句子时,这些现象就会失效。这些不是边缘情况;它们是该语言的核心语法特征。
1. 空间指代和代词
在英语中,我们使用代词,如 “he” (他) 、“she” (她) 或 “it” (它) 。如果你在没有上下文的情况下听到 “He went to the store” (他去了商店) ,虽然你不知道“他”是谁,但你仍然可以翻译语法。
在 ASL 中,代词是空间性的。手语者会在 3D 空间中的特定位置 (轨迹点) “设置”一个人或物体。在随后的对话中,他们只需指向那个空的空间或将动词导向该位置来指代那个人。
如果你切割视频,“设置”可能发生在片段 1 中,但“指向”发生在片段 5 中。一个模型 (或人类) 孤立地观看片段 5 时,看到的是一个人指向空气。那是“约翰”?“玛丽”?还是“那辆车”?没有历史记录,就不可能知道。
2. 分类词和视觉象似性
手语广泛使用分类词 (classifiers) 。 这些是代表物体类别 (如车辆、扁平物体或圆柱形物体) 的手形,通过在空间中移动来展示动作。
这就是视觉模态产生文本所没有的歧义的地方。特定的手形在一个语境中可能代表车辆,在另一个语境中可能代表人的腿。

如上方的 图 1 所示,手语者正在执行两个动作。在第一行中,他们的拳头来回移动。在第二行中,他们的手臂平放,手部拍动。
孤立地看,上面的手势可能是“驾驶”、“搅拌”或“握着杠杆”。下面的手势可能是一只鸟的翅膀、一个架子或一个通用的表面。然而,这个特定视频的语境是关于驾驶飞机的教程。有了这个语境,这就很清楚了: 拳头在控制操纵杆,手臂代表飞机的机翼,副翼在移动。如果没有前面的句子确立“飞机”这个主题,即使是流利的手语者也可能对这些孤立的片段感到困惑。
3. 快速指拼和“缩略”手势
当手语者引入一个新术语 (通常是专有名词,如名字或技术术语) 时,他们通常会清晰地进行指拼 (fingerspell) 。这类似于完整地写出一个单词。
然而,如果他们稍后再次提到该词,他们很少会清楚地拼写出来。他们会使用快速指拼或“词汇化”的指拼。动作变得模糊,有效地将拼写变成了某种形状或其本身的一个手势。
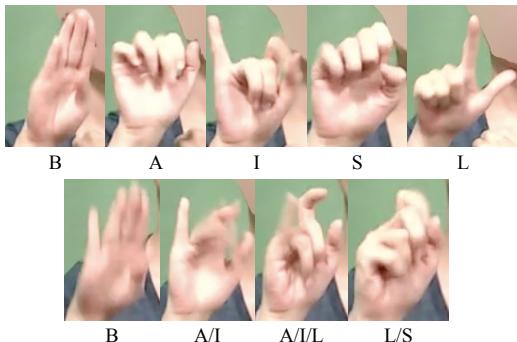
图 2 展示了这种退化。上面的序列显示了手语者第一次拼写 “BASIL” (罗勒) 。相对清晰。下面的序列显示了后来的提及。字母被挤压在一起;‘B’ 瞬间流入 ‘L’。
如果你孤立地看下面的片段,形状是模糊的。它可能看起来像 “BAIL”、“BILL”,或者只是一个通用的手部挥动。但如果你在前一个句子中看到了清晰的拼写,你的大脑本质上会“自动补全”这个快速版本。目前的句子级数据集剥夺了模型这种自动补全的能力。
案例研究: 人类基线
大多数 AI 论文都会提出一种新的模型架构。这篇论文采取了不同的方法: 它建立了一个人类基线 。 逻辑很简单: 如果一个流利的人类手语者在没有语境的情况下无法翻译这些片段,我们也不应该期望 AI 能做到。
研究人员使用了 How2Sign 数据集,这是一个流行的基准,包含从英语翻译成 ASL 的教学视频 (例如烹饪、机械) 。他们招募了流利的聋人手语者作为标注员。
实验设置
标注员被要求在四种递进条件下将 ASL 片段翻译成英语。这使研究人员能够准确测量“理解”是何时发生的。
- 孤立片段 (\(s_i\)): 标准的 AI 任务。译者只看到当前的视频片段。
- 扩展视频 (\(s_{i-1:i}\)): 译者看到当前片段和前一个片段。
- 扩展视频 + 文本语境 (\(s_{i-1:i}, t_{i-1}\)): 译者看到之前的片段以及前一个句子的标准英语文本。
- 完整语境 (\(s_{i-1:i}, t_{0:i-1}\)): 译者可以访问视频历史记录以及截止到当前点的完整英语脚本。
实验与结果
结果非常鲜明,突显了我们对 AI 的评分方式与实际翻译工作方式之间的巨大差距。
“不可能”的 33%
最惊人的发现是定性的。聋人标注员报告说,在 33.3% 的情况下 , 他们无法在孤立状态下完全理解句子的关键细节,但一旦加入语境就能理解。
这意味着对于三分之一的数据集来说,“句子级”任务在理论上是不可能的。信息根本不在片段中。它依赖于 10 秒前建立的代词,或 20 秒前引入的一个词的快速指拼。
定量评分
研究人员还使用 BLEU 和 BLEURT (自动翻译质量的标准指标) 测量了翻译结果。
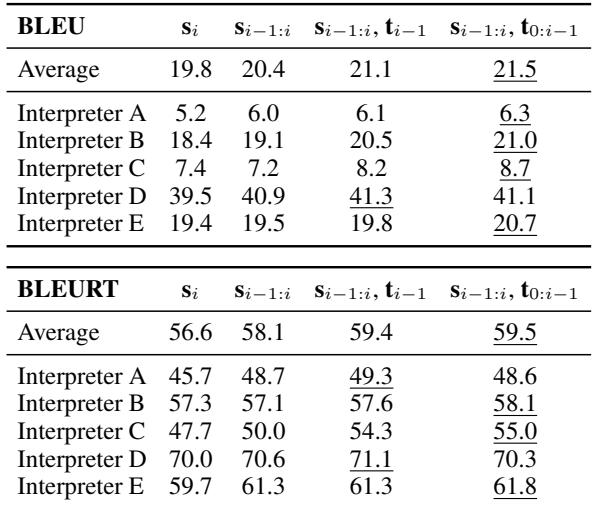
如 表 1 所示,分数随着语境的增加而提高。平均 BLEU 分数从 19.8 (孤立) 上升到 21.5 (完整语境) 。虽然 1.7 分的增长看起来不大,但在机器翻译领域,这是一个有意义的差距。更重要的是,这些数字与标注员“终于理解了”的主观体验相关联。
译员“陷阱”
这项研究最引人入胜的一个方面是分析谁在打手语。How2Sign 数据集使用了不同的译员。研究人员发现,根据具体译员的不同,表现存在巨大差异。
表 1 按译员 (A 到 E) 细分了这一点。看看 译员 A 和 译员 D 之间的区别:
- 译员 D: 在孤立句子上获得了惊人的 39.5 BLEU 分。
- 译员 A: 在孤立句子上仅获得 5.2 BLEU 分。
这是否意味着译员 D “更好”?令人惊讶的是,不。
研究人员发现,在孤立句子上得分高的译员通常使用手势编码英语 (MCE) 或深受英语影响的手语风格。他们基本上是在逐字打手语,这更容易翻译回英语,但不是自然的 ASL。
相反,译员 A 使用的是深度、自然的 ASL 语法——使用空间、分类词和非手控标记。这是“更好”的手语,但因为它如此严重地依赖 ASL 的语境依赖语法,所以孤立起来更难翻译。
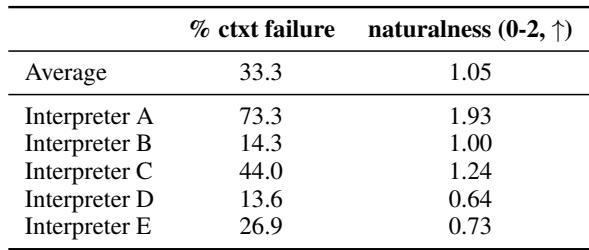
表 2 证实了这一悖论。译员 A 获得了最高的“自然度”评分 (1.93/2) ,但语境失败率最高 (73.3%) 。译员 D 的自然度评分最低 (0.64) ,但很少需要语境 (13.6%) 。
这向 AI 研究人员揭示了一个危险的陷阱: 如果我们针对句子级 BLEU 分数进行优化,我们可能会无意中训练模型偏好不自然的、类似英语的手语,而不是流利的、自然的手语。
现实世界的例子
为了使这些抽象的失败具体化,论文提供了翻译随着人类获得更多语境而演变的文字记录。
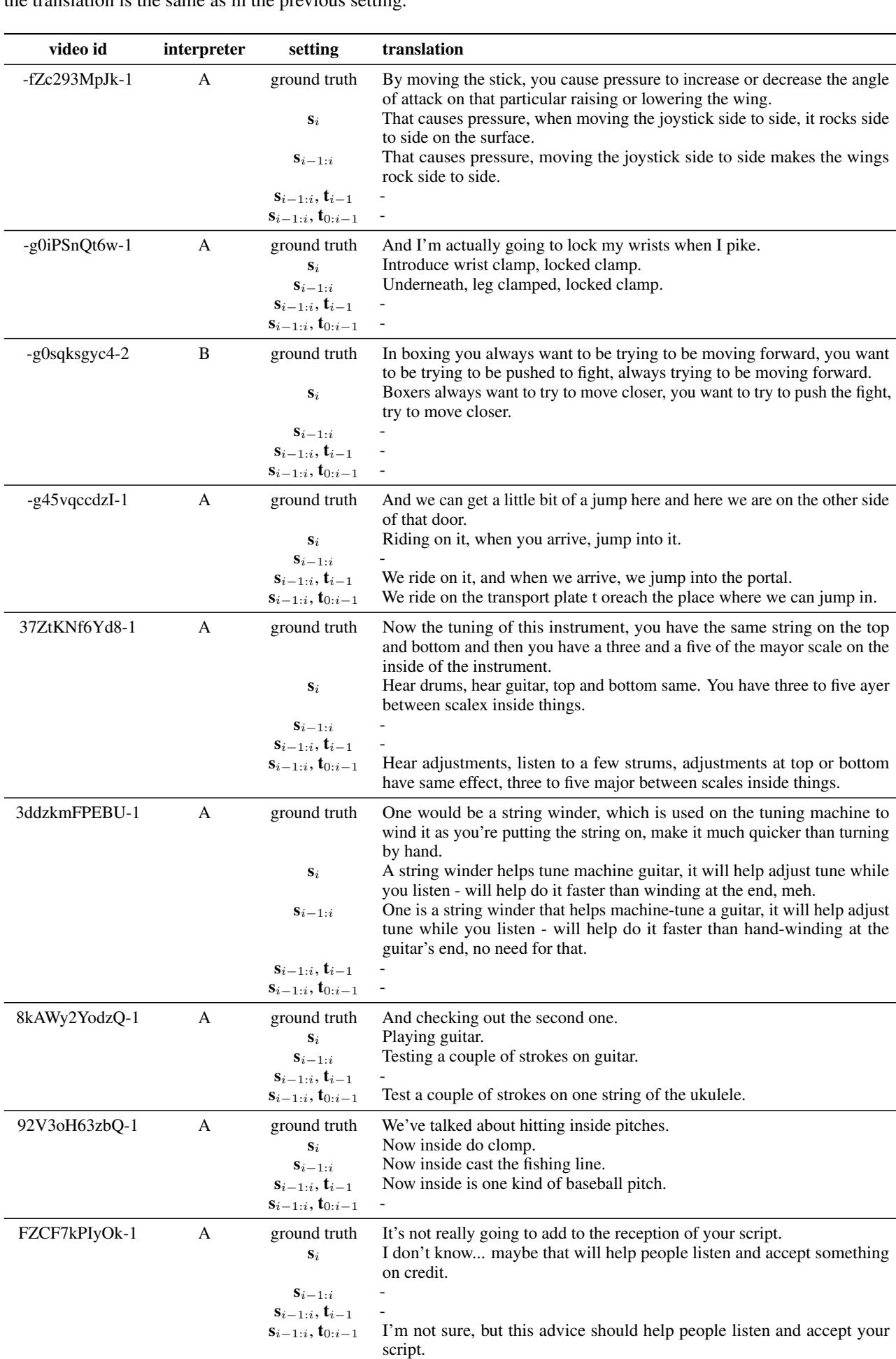
在 表 3 中,看看第一个例子 (视频 id -fZc293MpJk-1) 。
- 孤立 (\(s_i\)): 译者猜测关于“导致压力”和“角度”。很含糊。
- 有语境 (\(s_{i-1:i}\)): 翻译变得具体: “左右移动操纵杆使机翼左右摇摆。”
视觉输入没有改变,但意义变了。在孤立片段中,“操纵杆”只是一个移动的拳头。有了语境,模糊的手形坍缩成了一个具体的物体。
结论与启示
作者总结道,手语翻译领域必须转型。借用自文本 NLP 的句子级处理的便利性正积极地阻碍手语处理的进步。
其启示有三点:
- 语境不可没: 未来的数据集和模型必须设计为处理文档级或语篇级翻译。我们不能把视频切成孤立的句子并期望得到高质量的结果。
- 指标错位: 我们需要谨慎对待我们的指标。当前数据集上的高 BLEU 分数可能只是表明数据“简单” (像英语) ,而不是正确 (自然的 ASL) 。
- 人在回路: 这篇论文强调了用人类对 AI 任务进行健全性检查的重要性。仅仅通过坐下来尝试自己完成这项任务,研究人员就揭示了一个自动化指标多年来一直忽略的根本缺陷。
对于进入这一领域的学生和研究人员来说,信息是明确的: 当处理手语时,你不仅仅是在处理语言;你是在处理一个历史至关重要的视觉场景。要构建真正服务于聋人社区的系统,我们必须尊重语言的语言学现实——包括所有的语境。