](https://deep-paper.org/en/paper/2406.11064/images/cover.png)
引言
我们都有过对语音助手感到失望的经历。在安静的客厅里,它们能完美地理解我们。但试着在经过建筑工地或坐在嘈杂的咖啡馆里口述一条信息,系统就会崩溃。
这种现象被称为域偏移 (domain shift) 。 用于自动语音识别 (ASR) 的深度学习模型通常是在相对干净、受控的数据上训练的。当部署到现实世界中时,它们会遇到“域外”样本——即它们未曾准备好应对的嘈杂环境。
为了解决这个问题,研究人员转向了测试时适应 (Test-Time Adaptation, TTA) 。 这个想法简单而强大: 与其在训练后冻结模型,不如让它在推理过程中继续学习并适应传入的音频。
然而,目前的 TTA 方法面临着一个两难境地。有些方法在每句话之后都会重置自己 (遗忘有价值的上下文) ,而另一些方法尝试持续学习,但当环境突然变化时,面临“崩溃”或混淆的风险。
在这篇文章中,我们将深入探讨一篇最近的研究论文,该论文提出了一种“两全其美”的解决方案: 一种名为 DSUTA 的快慢 TTA 框架 (Fast-slow TTA framework) 。 我们将探索它如何模仿人类的学习方式——快速适应眼前的刺激,同时缓慢建立长期知识——以及一种巧妙的“动态重置”策略如何防止模型偏离轨道。
背景: 适应的困境
在理解新的解决方案之前,我们需要了解测试时适应的两种主要方法。
1. 非连续 TTA (Non-Continual TTA)
想象一个学生在参加考试,对于每一道题,他都被允许短暂地看一眼教科书,回答问题,然后在下一道题之前被擦除记忆。
这就是非连续 TTA 。 模型针对当前的音频片段 (话语) 调整其参数,做出预测,然后重置回其原始的预训练状态。
- 优点: 非常稳定。如果模型在一个片段上犯了错,不会影响下一个片段。
- 缺点: 效率低下。它无法利用从先前片段中学到的知识,即使它们是在完全相同的嘈杂环境中录制的。
2. 连续 TTA (Continual TTA, CTTA)
现在想象一下,这个学生在整个考试过程中都保留着记忆。当他们回答关于特定主题的问题时,他们会变得更擅长该主题。
这就是连续 TTA 。 模型逐流地持续更新自身。
- 优点: 它利用跨样本的知识,在一致的环境中随时间提高性能。
- 缺点: 它遭受误差累积和模型崩溃的困扰。如果模型开始做出错误的预测,它会在这些错误上训练自己,从而陷入失败的恶性循环。此外,如果环境突然发生变化 (例如,离开安静的房间进入嘈杂的公共汽车) ,模型可能会“过拟合”于安静的房间,而无法适应公共汽车的环境。
 图 1: TTA 方法的视觉比较。左侧的非连续 TTA 每一步都重置 (\(\phi_0\)) 。中间的连续 TTA 无限期地向前传递更新的状态。右侧提出的快慢方法融合了两者的特点。
图 1: TTA 方法的视觉比较。左侧的非连续 TTA 每一步都重置 (\(\phi_0\)) 。中间的连续 TTA 无限期地向前传递更新的状态。右侧提出的快慢方法融合了两者的特点。
核心方法: 快慢 TTA (Fast-Slow TTA)
研究人员提出了一个框架来弥合这两个极端之间的差距。他们称之为快慢 TTA 。
这种直觉源于我们需要两种类型的更新这一事实:
- 快速适应 (Fast Adaptation) : 我们需要快速调整参数以处理当前句子中的特定噪声。
- 慢速演化 (Slow Evolution) : 我们需要缓慢更新一组“元参数”,以捕获当前环境的一般特征 (例如空调的嗡嗡声) ,而不会过拟合于单个句子。
数学框架
快慢框架在关注点分离方面非常优雅。它引入了元参数 (\(\phi_t\)) 作为适应的起点。
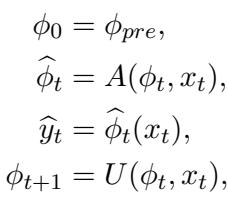
以上方程中发生了以下情况:
- 初始化: 我们从预训练参数 (\(\phi_{pre}\)) 开始。
- 快速适应 (\(A\)) : 当新的数据样本 \(x_t\) 到达时,我们创建模型的一个临时版本 \(\widehat{\phi}_t\)。这个版本是“快速”的,因为它经过激进的调整以仅适应当前的这个样本。
- 预测: 我们使用这个临时的、快速适应的模型来进行预测 \(\widehat{y}_t\)。
- 慢速更新 (\(U\)) : 同时,我们使用新数据对元参数 \(\phi_t\) 执行“慢速”更新,得到 \(\phi_{t+1}\)。这些元参数成为下一个样本的起点。
通过这样做,模型对每个新样本都有一个“更好的起点”,因为元参数 (\(\phi\)) 已经从过去学习了经验,但具体的预测是由一个针对当前时刻紧密优化过的版本 (\(\widehat{\phi}\)) 做出的。
动态 SUTA (DSUTA)
研究人员使用一种称为 动态 SUTA (DSUTA) 的方法实现了这个框架。它使用一种称为熵最小化 (Entropy Minimization) 的无监督目标函数——本质上是试图让模型对其预测更加自信 (锐化输出概率分布) 。
在 DSUTA 中:
- 适应 (\(A\)) : 对当前样本执行 \(N\) 步优化以最小化熵。
- 更新 (\(U\)) : 使用大小为 \(M\) 的最后 \(M\) 个样本的小缓冲区 (记忆) 。每 \(M\) 步,它使用该缓冲区的平均损失来更新元参数。这种小批量方法稳定了“慢速”学习过程。
应对现实世界: 动态重置策略
虽然快慢 TTA 解决了从过去数据中学习的问题,但它引入了一个新的风险。如果用户从安静的图书馆走到嘈杂的街道上怎么办?“慢速”元参数是针对图书馆调整的。当街道噪音袭来时,模型可能无法适应,因为它的起点偏差太远了。
标准的连续 TTA 在这里会失败。本文提出的解决方案是动态重置策略 (Dynamic Reset Strategy) 。
 图 2: 完整架构。注意“域偏移检测 (Domain Shift Detection) ”模块。如果检测到偏移,元参数将重置为原始源模型 (清空状态) 。如果未检测到,它们将继续缓慢更新。
图 2: 完整架构。注意“域偏移检测 (Domain Shift Detection) ”模块。如果检测到偏移,元参数将重置为原始源模型 (清空状态) 。如果未检测到,它们将继续缓慢更新。
检测偏移
模型如何在不被告知的情况下知道环境已经改变?它需要一个度量标准——一个无监督的指标,能够大声宣告“这数据看起来很奇怪!”
研究人员设计了损失改进指数 (Loss Improvement Index, LII) 。
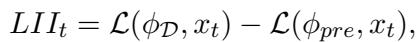
LII 背后的逻辑很巧妙:
- \(\mathcal{L}(\phi_{\mathcal{D}}, x_t)\): 使用适应于当前域的模型计算当前样本的损失。
- \(\mathcal{L}(\phi_{pre}, x_t)\): 使用原始预训练模型计算当前样本的损失。
- 将它们相减。
为什么要相减?因为有些句子本身就比其他句子更难识别,无论背景噪音如何。减去预训练损失作为一个归一化步骤,抵消了语音内容固有的难度。这给我们留下了一个纯粹反映当前域适应与传入音频匹配程度的值。
为了使检测具有鲁棒性,他们不仅仅查看一个样本 (这会有很多噪声) 。他们计算缓冲区大小 (\(M\)) 内的 LII 平均值。
 图 3: 此直方图证明了 LII 的有效性。蓝色分布 (域内) 与橙色分布 (域外) 截然不同。这种分离允许我们设定一个统计阈值。
图 3: 此直方图证明了 LII 的有效性。蓝色分布 (域内) 与橙色分布 (域外) 截然不同。这种分离允许我们设定一个统计阈值。
重置机制
系统在两个阶段之间交替:
- 域构建 (Domain Construction) : 当发生重置时,系统会花费一些时间 (\(K\) 步) 为这个新环境构建 LII 的统计概况 (均值和方差) 。它基本上是在学习对于这种特定噪声来说“什么是正常的”。
- 偏移检测 (Shift Detection) : 一旦建立了概况,它就会检查每一个传入的批次。如果 LII 显著偏离 (使用 Z-score 测试) 该概况,就会触发重置。
 图 4: 适应的时间线。模型进行适应 (绿色图标) ,构建域概况,监控偏移,当“域外 (Out domain) ”样本袭来 (红色) 时,它重置为预训练权重 (\(\phi_{pre}\)) 并重新开始。
图 4: 适应的时间线。模型进行适应 (绿色图标) ,构建域概况,监控偏移,当“域外 (Out domain) ”样本袭来 (红色) 时,它重置为预训练权重 (\(\phi_{pre}\)) 并重新开始。
重置的数学逻辑定义如下:
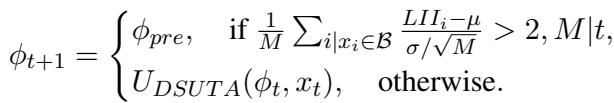
如果当前缓冲区 LII 的 Z-score 大于 2 (意味着它在统计上极不可能属于当前域) ,元参数 \(\phi_{t+1}\) 将被硬重置为 \(\phi_{pre}\)。否则,标准的 DSUTA 更新将继续。
实验与结果
研究人员使用混合了各种噪声 (如吸尘器、咖啡馆和街道噪音) 的 Librispeech 以及 CHiME-3 数据集 (真实世界的嘈杂录音) 严格测试了这种方法。
1. 单域性能
首先,他们测试了噪声一致的场景 (单域) 。
 表 1: 词错误率 (WER) 比较。越低越好。
表 1: 词错误率 (WER) 比较。越低越好。
表 1 中的结果令人震惊:
- 源模型 (Source Model) : 在“AA” (机场广播) 噪声上的错误率为 40.6%。
- SUTA (非连续) : 提高到 30.6%。
- DSUTA (本文提出) : 错误率大幅降低至 25.9% 。
DSUTA 在几乎所有类别中都优于基线。这证实了保留知识 (“慢速”更新) 比每次都重置具有巨大的优势。
为什么它更好? 研究人员分析了适应过程,发现 DSUTA 本质上给了优化一个领先的起跑线。
 图 5: “更好的起点”效应。橙色线 (DSUTA) 始终低于 (优于) 蓝色线 (SUTA) 和基线,表明元参数成功积累了有用的知识。
图 5: “更好的起点”效应。橙色线 (DSUTA) 始终低于 (优于) 蓝色线 (SUTA) 和基线,表明元参数成功积累了有用的知识。
2. 时变域
这是最关键的测试。研究人员创建了“多域”数据集,其中噪声类型按顺序变化 (例如,从空调噪声到打字噪声再到机场噪声) 。
- MD-Easy: 模型通常表现良好的噪声序列。
- MD-Hard: 困难噪声的序列。
- MD-Long: 具有随机长度的长序列 (10,000 个样本) ,模拟一整天的使用。
 表 2: 在变化域上的性能。
表 2: 在变化域上的性能。
表 2 的关键结论:
- 标准连续 TTA 失败: 看看 MD-Long 上的“CSUTA”。它的 WER 达到了 100.3% 。 这就是模型崩溃的实际表现。模型变得困惑且从未恢复。
- DSUTA 具有鲁棒性: 即使没有动态重置,DSUTA 的表现也不错 (MD-Long 上为 43.2%) 。
- 动态重置是王道: 加入动态重置 (“w/ Dynamic reset”) 将错误率进一步降低至 35.8% 。
有趣的是,动态重置策略有时甚至优于“理想边界 (Oracle boundary) ” (即模型被确切告知噪声何时改变) 。这表明,有时保留跨越稍微不同域的知识比硬重置更好,而动态策略足够聪明,能够决定何时保留知识,何时丢弃知识。
3. 效率
人们可能认为所有这些缓冲区计算和统计跟踪会使模型变慢。令人惊讶的是,情况恰恰相反。
 表 3: 效率比较。
表 3: 效率比较。
因为 DSUTA 从更好的元参数开始,它需要更少的适应步骤 (\(N\)) 就能达到良好的结果。如表 4 所示,DSUTA 的总运行时间显著快于 SUTA (3885秒 vs 5040秒) ,同时实现了更高的准确率。
结论
ASR 模型从实验室走向现实世界充满了挑战,这主要是由于不可预测的背景噪声。本文通过 Dynamic SUTA 迈出了令人信服的一步。
通过采用 快慢 TTA 框架 , 作者成功地结合了单样本适应的稳定性与连续适应的累积学习优势。加入 动态重置策略 解决了“灾难性遗忘”与“模型崩溃”之间的权衡,使系统能够自主检测环境变化。
这对边缘 AI 意义重大。我们正在迈向这样的语音助手: 它们不再是被动地处理音频,而是实时主动学习并适应你的环境,无论你是在图书馆还是在建筑工地。
关键要点:
- 不要盲目重置: 保留过去样本的记忆 (元参数) 可以提高准确性。
- 不要盲目记忆: 无限期的学习会导致崩溃;你必须知道何时重置。
- 无监督指标行之有效: 使用相对损失改进 (LII) 是一种在没有标签的情况下检测域偏移的可行方法。