](https://deep-paper.org/en/paper/2406.11370/images/cover.png)
为什么更加公平的 LLM 是更好的裁判: 深入解析 ZEPO 框架
如果你最近尝试过大语言模型 (LLM) ,你可能知道它们不仅在编写代码或生成诗歌方面很有用,而且越来越多地被用作评估器 。 在一个文本生成廉价但评估昂贵的世界里,使用一个 LLM 来评判另一个 LLM 的输出质量 (这种技术通常被称为“LLM 即裁判”,LLM-as-a-Judge) 已成为一种标准做法。
然而,这里有一个重要的问题。LLM 是出了名的善变裁判。稍微改变一下评估提示词 (prompt) 的措辞,模型的决定可能会完全反转。它们深受各种偏差的困扰,比如偏爱呈现给它们的第一个选项,或者不论质量如何都偏爱更长、更啰嗦的回答。
我们该如何解决这个问题?如何在不花费巨资进行数据标注的情况下,使 LLM 裁判与人类的偏好更好地对齐?
最近一篇名为 “Fairer Preferences Elicit Improved Human-Aligned Large Language Model Judgments” 的论文提出了一个引人入胜的解决方案。研究人员发现公平性 (统计平衡) 与准确性 (人类对齐) 之间存在紧密的联系。基于此,他们开发了一个名为 ZEPO (面向零样本评估的提示词优化) 的框架。
在这篇深度文章中,我们将探讨为什么 LLM 裁判存在偏差,为什么“公平性”能预测性能,以及 ZEPO 框架如何自动优化提示词以创建更好的 AI 评估器。
问题所在: LLM 裁判的善变本质
要理解解决方案,我们首先必须了解我们要讨论的具体评估类型: 成对比较 (Pairwise Comparison) 。
研究人员通常不会要求 LLM 给出从 1 到 10 的评分 (这通常是随意且不一致的) ,而是提供两个选项——候选 A 和候选 B——并问 LLM: “哪个摘要更连贯?”
虽然这种方法通常比直接打分更稳健,但它深受提示词敏感性的困扰。你给模型的具体指令可能会极大地改变结果。
敏感性与偏差
想象一下,你有一个包含 100 个摘要任务的数据集。你要求 LLM 使用“提示词 X”来评判它们。模型可能会说它与人类标注者的一致性为 40%。然后,你稍微改写一下提示词——保持含义完全不变——创建了“提示词 Y”。突然之间,模型与人类的一致性变成了 50%。
这种不稳定性对于研究和生产来说是危险的。如果我们的评估指标依赖于碰巧合适的措辞,我们就无法信任它们。
这篇论文的研究人员对这一现象进行了系统性研究。他们选取了一组指令,将其改写为语义等价的变体,并测试了 LLM 的评判与人类评判的相关性。
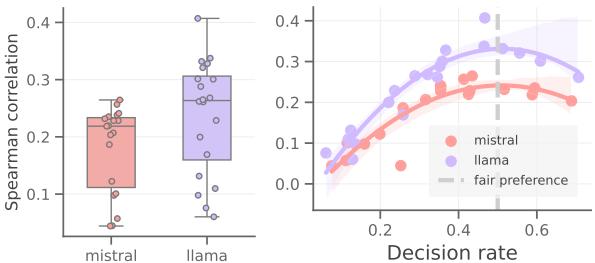
如上方的 图 2 所示,结果令人震惊。
- 左侧面板 (箱线图) : 看看“Mistral”和“Llama”的分布范围。纵轴代表与人类的斯皮尔曼相关系数 (越高越好) 。箱线图的巨大差异表明,简单地改写指令可能会导致性能崩溃或显著提升。
- 右侧面板 (散点图) : 这是论文的核心洞察。X 轴代表决策率 (Decision Rate) (即选择某一类别,如“选项 A”而非另一个的概率) 。Y 轴是人类对齐度。
注意曲线的形状了吗?它是一个二次拱形 (倒 U 型) 。
- 当决策率处于极端情况 (例如 0.2 或 0.7) 时,意味着模型几乎总是严重偏向于选择“A”或“B”,此时与人类的相关性很低。
- 人类对齐度的峰值正好出现在中间,即 0.5 左右。
这引出了论文的核心假设: 更公平的偏好 (接近 50/50 的平衡决策分布) 始终能带来与人类更一致的评判。
理论支柱: 零样本公平性
为什么 50/50 的比例很重要?
根据大数定律,如果你有一个足够大且多样的随机成对比较数据集,“真实”的偏好分布应该大致是均匀的。换句话说,如果你随机抽取成对的摘要,“摘要 A”比“摘要 B”好的概率应该大约是一半,反之亦然。
如果一个 LLM 评估器在查看大量数据后,80% 的时间都判定“摘要 A”更好,那么它很可能遭受了偏好偏差 。 它不是在评判内容,而是依赖于虚假相关性 (比如答案的位置或提示词中的特定措辞) 。
因此,如果我们能强迫模型具有“公平” (均匀) 的偏好分布,我们很可能就消除了这些偏差,并迫使模型去关注实际内容。
介绍 ZEPO: 面向零样本评估的提示词优化
受“公平性等于对齐度”这一发现的启发,作者提出了 ZEPO 。
ZEPO 是一个自动框架,用于优化评估所用的提示词。与需要数千个带有人工标注的示例来“教”模型什么样的提示词是好的其他优化方法不同,ZEPO 是零样本 (Zero-shot) 的。它不需要任何标注数据 。
它只需要一堆未标注的输入 (例如源文本和摘要对) 以及访问 LLM 的权限。
流程管道
让我们使用论文中提供的图表来分解 ZEPO 管道是如何工作的。
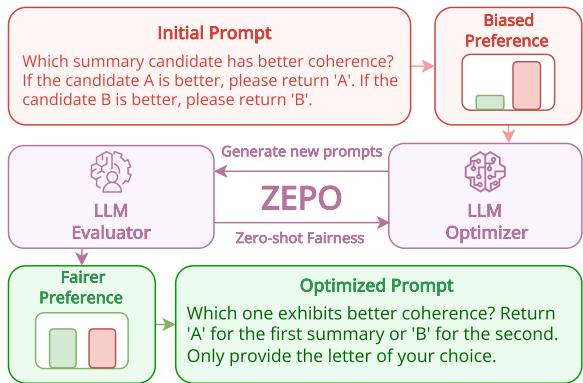
如 图 1 所示:
- 初始提示词 (Initial Prompt) : 你从一个手动编写的提示词开始 (例如,“哪个摘要更好?”) 。
- 有偏差的偏好 (Biased Preference) : 系统在数据样本上运行此提示词。条形图显示了“有偏差的偏好”,其中红色条 (选项 B) 比绿色条高得多。模型不公平地偏向于某一个选项。
- 循环 (ZEPO) :
- LLM 优化器 (LLM Optimizer) : 系统使用另一个 LLM (如 GPT-3.5 或 GPT-4) 来改写指令。它生成提示词的变体。
- LLM 评估器 (LLM Evaluator) : 目标模型 (如 Llama-3) 使用这些新提示词再次评判数据。
- 公平性计算 (Fairness Calculation) : 系统计算每个新提示词的“公平性得分”。该得分衡量决策分布与完美的 50/50 分裂有多接近。
- 优化后的提示词 (Optimized Prompt) : 循环继续,直到找到一个能产生“更公平偏好” (绿色和红色条高度相等) 的提示词。这个提示词即为胜者。
底层算法
这个过程是迭代的。以下是论文中使用的算法的简化步骤:
- 输入: 一个初始指令 (例如,“评估连贯性”) 。
- 生成候选: 优化器 LLM 生成一批语义等价的提示词 (改写) 。
- 评估公平性: 对于每个候选提示词,评估器 LLM 在一批未标注数据上预测偏好。
- 计算指标: 系统计算公平性指标: \[ \text{Fairness} = - \sum | 0.5 - p(\text{prediction}) | \] 本质上,如果预测率偏离 0.5,它就会惩罚该提示词。
- 选择最佳: 公平性得分最高 (最接近 0) 的提示词成为下一轮改写的种子。
- 重复: 运行数个轮次 (epochs) 直至收敛。
为什么公平性优于置信度
你可能会问: “为什么要用公平性?为什么不直接让模型使用它最*自信 (confident) *的提示词?”
在机器学习中,置信度 (通常通过低熵来衡量) 是选择提示词的常用指标。然而,研究人员发现,对于 LLM 评估器来说,置信度是一个陷阱。LLM 可能非常自信,但也错得离谱 (通常称为幻觉或过度自信偏差) 。
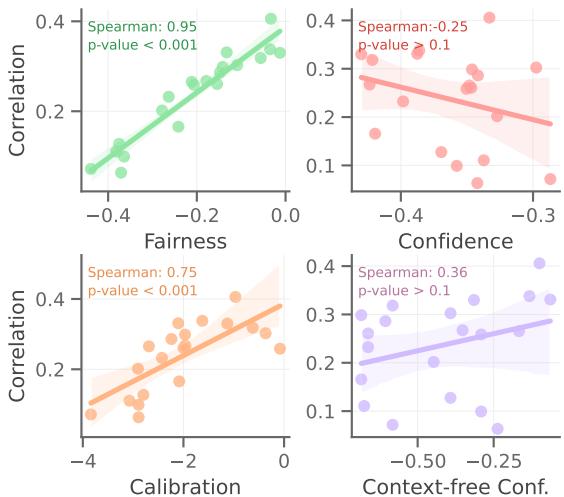
图 3 提供了选择公平性而非其他指标的统计证据:
- 左上角 (公平性) : 绿色趋势线陡峭且呈正相关。斯皮尔曼相关系数为 0.95 (p值 < 0.001)。这是一个巨大的相关性。它证实了随着公平性的提高 (在 X 轴上更接近 0) ,与人类判断的相关性显著提高。
- 右上角 (置信度) : 红线显示负相关。在这种情况下,仅仅优化模型的置信度实际上损害了性能。
- 左下角 (校准度) : 校准度 (预测概率与准确性的映射程度) 有帮助,但相关性 (0.75) 比公平性弱。
这一比较验证了 ZEPO 的核心前提: 当我们没有真实标签时,公平性是我们拥有的衡量人类对齐度的最佳代理指标。
实验结果
那么,ZEPO 真的能带来更好的裁判吗?作者在 SummEval 和 News Room (摘要任务) 以及 TopicalChat (对话) 等代表性基准上测试了该框架。
他们将 ZEPO 与标准的成对提示及其他基线进行了比较。
摘要基准
让我们看看“News Room”数据集的结果。
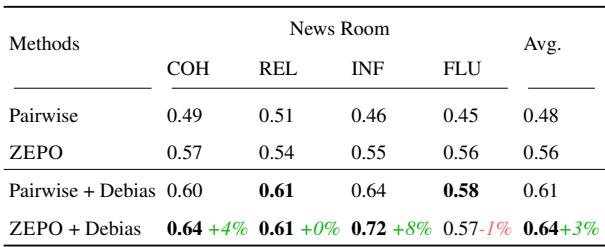
在 表 2 中,我们看到了使用 Llama-3 8B 模型的不同方法的斯皮尔曼相关系数 (与人类的一致性) :
- Pairwise (基线) : 平均相关系数 0.48。
- ZEPO (优化后) : 平均相关系数 0.56。
仅仅通过自动更改提示词,这是一个显著的提升。
此外,该表引入了去偏 (Debiasing) 的概念。解决位置偏差的一个常用技术是运行评估两次 (交换 A 和 B 的位置) 并取结果的平均值。
- Pairwise + Debias: 0.61.
- ZEPO + Debias: 0.64.
这告诉我们一件至关重要的事情: ZEPO 与去偏是正交的。 你不必在优化提示词和使用去偏技术 (如交换位置) 之间做选择。你可以两者兼得,ZEPO 仍然能增加价值。
我们可以在 图 4 中可视化这种“正交性”。
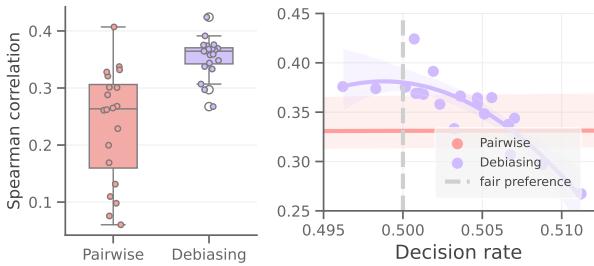
在右侧图表中, 蓝点 (去偏后) 通常比红点 (标准成对) 表现更好。然而,即使在蓝点中,也存在一条曲线。去偏后的模型仍然遭受提示词敏感性的影响。通过使用 ZEPO 找到位于蓝色曲线顶峰 (决策率 ~0.5) 的提示词,我们提取了最大可能的性能。
对话基准
ZEPO 的有效性不仅限于摘要。研究人员还在 TopicalChat 数据集上测试了它对对话评估的效果。
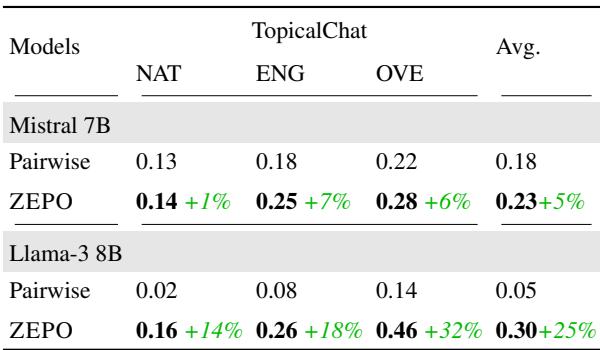
表 3 揭示了巨大的提升,特别是对于 Llama-3 8B:
- 在 整体质量 (OVE) 上,相关系数从 0.14 (Pairwise) 跃升至 0.46 (ZEPO) 。
- 这是对齐度 32% 的提升 , 将一个几乎不可用的评估器变成了一个中等强度的评估器。
定性分析: “公平”的提示词长什么样?
很容易迷失在数字中,但文本实际上发生了什么变化?优化器是写了什么魔法词吗?
通常,变化是微妙但有影响力的。优化器可能会澄清标准、改变语气或调整格式约束。

表 5 提供了具体示例。
- 连贯性 (COH) :
- *初始提示词: * “If the candidate A is better, please return ‘A’…” (公平性: -0.288)
- *ZEPO 提示词: * “Select ‘A’ for option A or ‘B’ for option B…” (公平性: -0.007)
- *结果: * 优化后的提示词更加直接,并使用了略微不同的动词 (“Assess and contrast” 对比 “Evaluate and compare”) 。这个微小的转变消除了偏差。
- 流畅性 (FLU) :
- *初始提示词: * 公平性 -0.417 (高度偏差) 。
- *ZEPO 提示词: * 公平性 -0.018 (几乎完美) 。
- 优化后的提示词关注“流畅度 (smoothness) ”,并要求模型“Evaluate the smoothness of each summary choice”。
这突显了人类直觉中认为“清晰”的提示词,往往与 LLM 感知为“中立”的提示词不同。ZEPO 自动弥合了这一差距。
结论与启示
“LLM 即裁判”的范式将继续存在,但它需要保障措施。论文 “Fairer Preferences Elicit Improved Human-Aligned Large Language Model Judgments” 提供了一个关键的保障: 认识到有偏差的裁判就是糟糕的裁判。
这项工作的主要结论是:
- 敏感性是真实的: 即使是像 Llama-3 这样强大的模型,也会因提示词措辞的不同而剧烈波动。
- 公平性 = 对齐度: 统计公平性 (50/50 的决策率) 与人类对齐度之间存在近乎完美的相关性。
- ZEPO 有效: 我们可以自动搜索这些公平的提示词,而无需任何昂贵的人工标注数据。
对于 NLP 领域的学生和从业者来说,这意味着我们设计评估的方式需要转变。我们不能简单地写一次提示词就信任它。我们需要审计提示词的统计偏差。如果你的模型在随机数据集上 90% 的时间都选择“选项 A”,那么你不只是有分布问题——你有准确性问题。
ZEPO 提供了一条通往自我纠正、更可靠的 AI 评估器的道路,使我们离真正理解人类偏好的自动化系统更近了一步。