](https://deep-paper.org/en/paper/2406.11375/images/cover.png)
引言
想象一下,试图向一个从未上过物理课的人解释原子的结构。你可以背诵关于质子、中子和电子层的教科书定义。或者,你可以说: “原子就像一个太阳系。原子核是中心的太阳,而电子是绕其运行的行星。”
对于大多数学习者来说,第二种解释——即类比——才是让人豁然开朗的那个。类比推理是人类认知的基石。它允许我们将熟悉的 (太阳系) 映射到陌生的 (原子) 上,从而搭建起通往新理解的桥梁。
在人工智能领域,研究人员长期以来一直着迷于大型语言模型 (LLM) 是否能够生成类比。我们知道它们可以补全像“国王之于男人,相当于女王之于女人”这样的模式。但一个关键问题仍然存在: 这些 AI 生成的类比真的有用吗? “教师”模型能否利用类比帮助“学生”模型理解复杂的科学概念?
这就是研究论文 “Boosting Scientific Concepts Understanding: Can Analogy from Teacher Models Empower Student Models?” (提升科学概念理解: 教师模型的类比能否为学生模型赋能?) 背后的核心问题。研究人员提出了一个名为 SCUA (Scientific Concept Understanding with Analogy,带类比的科学概念理解) 的新任务,以测试类比究竟仅仅是语言上的花哨,还是 AI 的实用教育工具。
当前类比研究的问题
从历史上看,关于类比的 AI 研究主要集中在两件事上: 识别类比和生成类比。随着 GPT-4 等大型模型的出现,我们已经从简单的词汇联想转向了涉及故事和过程的复杂比较。
然而,对这些类比的评估一直有些肤浅。通常情况下,模型生成一个类比,人类标注员根据其是否“讲得通”进行评分。但这忽略了实际效用。在课堂上,老师打比方不仅仅是为了听起来富有诗意;他们这样做是为了帮助学生解决问题。如果学生仍然考试不及格,那么这个类比就是无效的。
这篇论文的作者认为,我们需要将 AI 评估与这种现实世界的教育场景相结合。我们不应该只问: “这是一个好的类比吗?”我们应该问: “这个类比是否帮助学生模型回答了它原本会答错的问题?”
SCUA 任务: 一种师生框架
为了调查这一点,研究人员设计了 SCUA 任务。该框架模拟了一个包含两种不同类型 AI 智能体的课堂环境:
- 教师 LM (Teacher LMs) : 这些是功能强大、先进的模型 (如 GPT-4 或 Claude) ,具有深度推理和高质量生成能力。
- 学生 LM (Student LMs) : 这些是较小或稍弱的模型 (如 Vicuna、Mistral-7B 或 GPT-3.5) ,它们试图回答困难的科学问题。
如下图所示,这个过程简单而严谨。
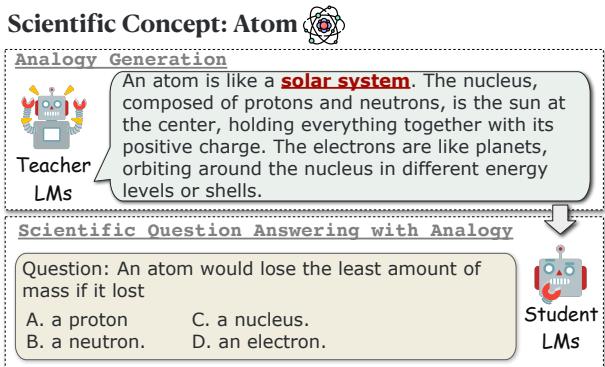
如 图 1 所示,工作流程从一个科学概念开始,例如“原子 (Atom) ”。
- 提示 教师 LM 使用类比 (例如,将原子比作太阳系) 生成解释。
- 向 学生 LM 提出一个与该概念相关的困难多项选择题。
- 学生尝试回答该问题,分为两种情况: 没有类比和 有 教师提供的类比。
通过比较学生在两种情况下的表现,研究人员可以精确量化类比提供了多少“赋能”。
定义类比
并非所有的类比都是一样的。简短的隐喻不同于长篇大论的解释。为了捕捉这种细微差别,研究人员指示教师 LM 生成三种不同类型的类比。

表 1 使用“热平衡 (Thermal Equilibrium) ”这一概念概述了这三个类别:
- 自由形式类比 (Free-Form Analogy) : 这是一个自然语言段落。它编织了一个故事或场景 (比如交换气球或杯子里的热牛奶) 来直观地解释概念。它模仿了人类导师说话的方式。
- 结构化类比 (Structured Analogy) : 这种更加正式。它明确地将源域映射到目标域。它识别特定的对应关系,例如“热传递对应于重量重新分配”。这借鉴了认知的 结构映射理论。
- 词类比 (Word Analogy) : 这是经典的标准化测试格式 (“A 之于 B 相当于 C 之于 D”) 。它很简洁,但在很大程度上依赖于学生已经理解类比术语之间的关系。
方法论: 设置实验
为了严格测试这一点,作者使用了两个具有挑战性的数据集:
- ARC Challenge: 一组自然科学问题,旨在难倒简单的检索算法。
- GPQA: 一个研究生水平的数据集,涵盖生物学、物理学和化学。这些问题非常难,即使是人类博士候选人通常也只能达到约 65% 的准确率。
阵容
- 教师: GPT-4、Claude-v3-Sonnet 和 Mixtral-8x7B。
- 学生: 专有模型和开源模型的混合体,包括 Gemini、GPT-3.5、Llama-3-8B 以及各种版本的 Vicuna。
目标是观察在教师类比的帮助下,学生能否提高他们在 ARC 和 GPQA 上的准确率。
实验与结果
结果为 AI 模型如何处理信息和“学习”提供了引人入胜的见解。
1. 类比真的有帮助吗?
第一个研究问题可以说是最重要的: 这种受生物学启发的方法对硅基大脑真的有效吗?
答案是响亮的“是”。
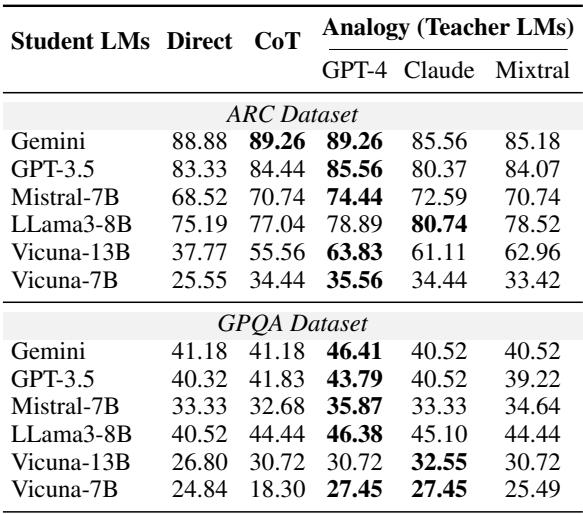
表 2 比较了学生在不同策略下的表现:
- Direct: 直接要求学生回答问题 (零样本/Zero-shot) 。
- CoT: 思维链提示 (Chain-of-Thought,要求模型“逐步思考”) ,这是提高推理能力的标准方法。
- Analogy (Teacher LMs): 为学生提供由教师生成的自由形式类比。
数据中的关键要点:
- 类比优于标准提示: 对于几乎所有的学生 LM,接收来自教师 (特别是 GPT-4) 的类比导致的准确率都高于直接提示。
- 类比击败思维链 (CoT) : 在许多情况下,类比提供的提升比 CoT 更大。例如,看一看 ARC 数据集上的 Mistral-7B 。 它的直接得分为 68.52%,CoT 得分为 70.74%,但在 GPT-4 提供类比时跃升至 74.44% 。
- 帮助“慢学习者”: 这种影响在困难的 GPQA 数据集上尤为明显。较小的模型,如 Vicuna-7B,在这些研究生水平的问题上非常吃力。然而,在类比的帮助下,它们的表现显著提高 (从大约 18-24% 提高到 27-35%) ,表明类比可以使高阶概念对于较弱的模型来说更易于理解。
2. 质量 vs. 实用性: “词类比”悖论
第二个主要发现突显了人类认为的“好”与 AI 认为的“有用”之间的差异。
研究人员要求人类标注员对教师生成的类比质量进行评分。人类一致给予 词类比 (Word Analogies) 极高的评价。它们干净、精确且逻辑严密。然而,当研究人员将这些类比提供给学生 LM 时,结果却讲述了一个不同的故事。
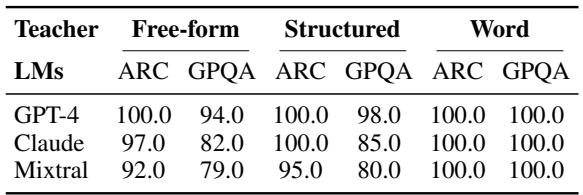
表 3 显示了人类评估。注意词类比 (右列) 的高分。现在,让我们看看下面的 图 2 , 它显示了学生在 使用 这些类比时的实际表现。
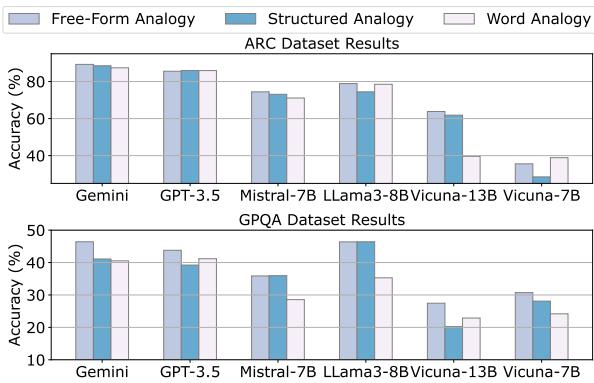
在 图 2 中,观察代表词类比的浅色柱状图。在几乎所有情况下,与 自由形式 (浅蓝色) 和 结构化 (中蓝色) 类比相比,它们导致的准确率更低。
为什么会发生这种情况? 虽然人类欣赏词类比的优雅 (“热平衡之于平衡秤”) ,但试图解决复杂物理问题的 AI 需要更多的上下文。
- 自由形式类比 提供了丰富、描述性的文本。它们解释了机制 (例如,热量 如何 像水一样流动) 。这些额外的信息起到了知识注入的作用,帮助模型通过推理解决问题。
- 词类比 太过稀疏。如果学生模型不能完全掌握源概念和目标概念之间的关系,简单的映射无法提供足够的信息来解决问题。
这表明,虽然强大的模型擅长进行简洁的类比,但“啰嗦”的类比更有利于教学。
3. 学生能自学吗?
最后,研究人员探索了一个元认知角度。如果学生 LM 在回答之前生成 自己的 类比会怎样?这类似于学生在考试期间停下来说,“好吧,这个概念有点像……”然后再解决问题。
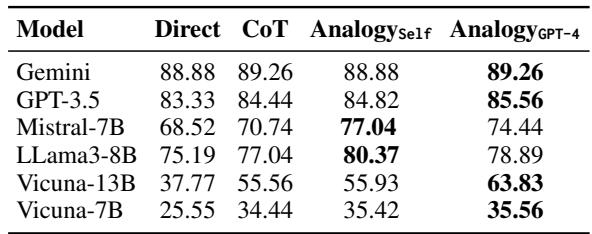
表 4 将自生成类比 (Analogy_Self) 与思维链 (CoT) 和 GPT-4 的类比进行了比较。
结果对于“自我学习”的概念来说是令人鼓舞的。
- 与 CoT (70.74%) 相比, Mistral-7B 使用自生成类比 (77.04%) 看到了巨大的提升。
- 在某些情况下,学生自生成的类比几乎与 GPT-4 提供的类比一样有效,甚至 更 有效 (见 Llama3-8B : 自生成 80.37% vs. GPT-4 78.89%) 。
这意味着生成类比的行为迫使模型访问和重组其内部知识,从而充分阐明概念以正确回答问题。
结论与未来启示
“SCUA”任务有效地证明了我们可以借用人类教育学的方法来改进 AI 系统。就像一位好老师使用隐喻来开启学生的理解一样,强大的“教师 LM”可以使用自由形式的类比来提升“学生 LM”的表现。
主要收获:
- 类比是功能性工具: 它们不仅仅是创意写作;它们可衡量地提高了 AI 的科学推理能力。
- 语境至关重要: 虽然简短有力的词类比对人类来说看起来不错,但 AI 模型从详细的、叙述性的 (自由形式) 类比中学习效果更好。
- 自学潜力: 模型具有潜在的能力,可以通过为自己生成类比来提高自己的推理能力。
这项研究为未来令人兴奋的可能性通过了大门。我们可能会看到自动化辅导系统的发展,其中 AI 根据学生的需求调整其解释。此外,在“知识蒸馏”领域——我们试图让小模型像大模型一样聪明——类比可能会成为压缩和传递复杂推理技能的标准方式。
通过将 AI 交互视为一种教育过程,我们发现让模型变聪明的最好方法可能就是给它讲一个故事。