](https://deep-paper.org/en/paper/2406.11695/images/cover.png)
随着大型语言模型 (LM) 的发展,我们正在超越简单的单轮“聊天”界面。如今,自然语言处理 (NLP) 的前沿涉及 语言模型程序 (Language Model Programs) : 即多个 LM 调用被链接在一起以解决复杂任务的精密管道。想象一个系统,它从维基百科检索信息,对其进行摘要,根据摘要进行推理,最后制定出最终答案。每一步都是一个独特的“模块”,需要其自己的提示 (prompt) 。
然而,这种复杂性带来了一个巨大的瓶颈。你该如何为一个拥有五个不同阶段的管道设计提示?如果最终答案是错的,是哪一个提示出了问题?手动调整这些系统 (即“提示工程”) 是一个乏味的试错过程,随着模块数量的增加,要在数学上找到最优解变得几乎不可能。
在这篇文章中,我们将剖析一篇重要的研究论文,它正是为了解决这个问题而生。研究人员推出了 MIPRO (多提示指令提议优化器) , 这是一个自动化优化这些管道的新颖框架。通过将指令和少样本演示 (few-shot demonstrations) 视为超参数,他们展示了我们可以系统地提高性能——比标准提示方法高出多达 13%。
问题所在: LM 程序的解剖结构
要理解解决方案,我们首先需要理解问题的结构。一个 LM 程序是一系列模块。例如,一个多跳问答系统可能长这样:
- 模块 1: 根据用户的问题生成搜索查询。
- 模块 2: 阅读搜索结果并生成第二个查询。
- 模块 3: 综合最终答案。
每个模块都有两个我们可以调整的主要“旋钮”来改变其行为:
- 指令 (Instructions) : 具体的文本命令 (例如,“简明扼要地总结这段文字……”) 。
- 演示 (Demonstrations) : 包含在上下文窗口中的少样本示例 (输入/输出对) ,用于向模型展示该怎么做。
同时为每一个模块找到指令和演示的完美组合,就是挑战所在。
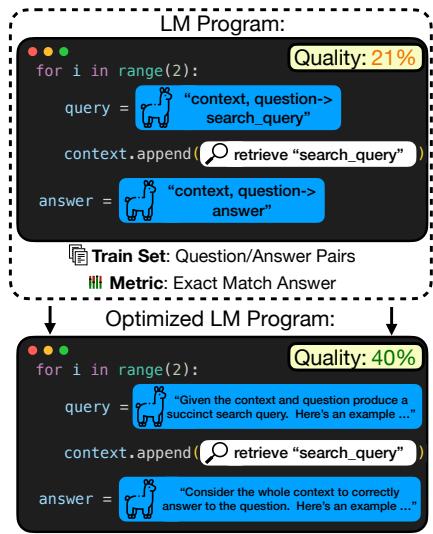
如 图 1 所示,一个标准的、未优化的程序 (顶部) 可能只有 21% 的质量得分。通过优化每个阶段的指令和示例 (底部) ,研究人员将性能几乎翻倍至 40%。但是,我们如何在不进行人工猜测的情况下,从顶部版本变为底部版本呢?
数学目标
形式上,研究人员将问题定义为找到变量 (指令和演示) 的完整赋值,以使训练数据集 \(\mathcal{D}\) 上的指标 \(\mu\) (如准确率或完全匹配) 最大化。
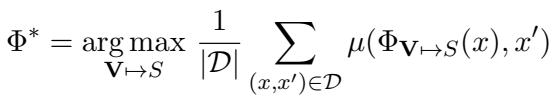
这个公式本质上是在说: “找到那组能让我们在训练数据上获得最高平均分数的提示和示例 (\(\Phi^*\)) 。”
这个问题之所以困难,主要有两个原因:
- 提议问题 (The Proposal Problem) : 你可以用作指令的英语句子的空间是无限的。我们如何找到好的候选指令?
- 信用分配问题 (The Credit Assignment Problem) : 在多阶段管道中,我们通常只有最终答案的标签。我们没有中间步骤的“黄金标签”。如果管道失败了,我们不知道是模块 1 还是模块 3 的问题。
策略 1: 解决提议问题
为了优化程序,我们首先需要一组候选提示和演示来进行测试。研究人员利用了一个“提议者 LM (Proposer LM) ”——一个单独的语言模型,负责生成这些候选内容。
自举演示 (Bootstrapping Demonstrations)
寻找好的少样本示例通常比重写指令更有效。论文使用了一种称为 自举随机搜索 (Bootstrap Random Search) 的技术。
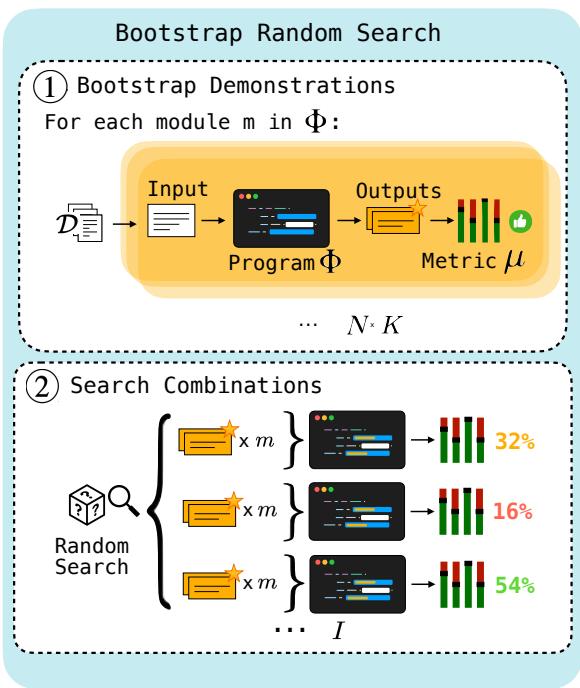
如 图 2 所示,该过程分为两步:
- 自举 (Bootstrap) : 我们从训练集中获取原始输入并通过程序运行它们。我们过滤出那些最终输出正确的轨迹。即使我们没有标记中间步骤,如果最终答案是正确的,我们假设中间步骤可能也足够好。这些轨迹就成为了我们的候选演示。
- 搜索 (Search) : 我们随机采样这些自举演示的不同组合,看看哪一组能产生最高的性能。
Grounding 指令 (Grounding Instructions)
为了生成候选指令,研究人员不仅仅是要求 LM“写一个更好的提示”。他们使用了 Grounding (依据) 技术。他们向提议者 LM 提供特定的上下文:
- 数据摘要: 对数据集中发现的模式的描述。
- 程序代码: 管道的实际代码,以便模型理解流程。
- 轨迹历史: 以前成功或失败的指令。
这种上下文允许提议者 LM 编写出针对特定任务细节量身定制的指令。
策略 2: 解决信用分配问题
一旦我们有了一堆候选指令和演示,我们如何弄清楚哪种组合效果最好?论文探讨了两种主要方法。
方法 A: 基于历史的优化 (OPRO)
一种方法改编自以前名为 OPRO 的工作,它要求语言模型充当优化器。
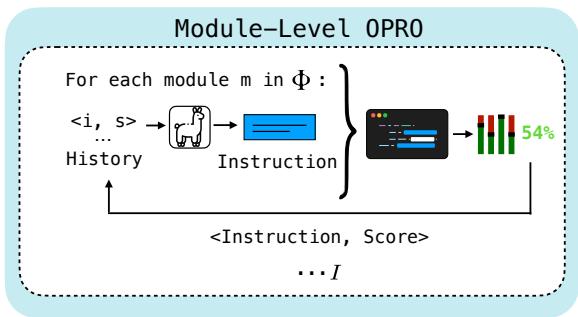
在 模块级 OPRO (图 3) 中,优化器保留以前的指令及其结果分数的历史记录。它将此历史记录反馈给提议者 LM,本质上是在问: “这是我们尝试过的以及它们的效果如何;请提议一个更好的指令。”
虽然这种方法很优雅,但它有局限性。随着历史记录的增长,上下文窗口会被填满,并且 LM 很难推断出措辞的特定变化与分数的微小增加之间的复杂相关性。
方法 B: 代理模型 (MIPRO 方法)
这引出了论文的主要贡献: MIPRO 。 MIPRO 不要求 LM 做数学运算,而是使用专用的贝叶斯代理模型。
MIPRO 将提议阶段与选择阶段解耦。
- 提议: 它使用前面提到的 Grounding 技术生成大量的候选指令和演示池。
- 优化: 它使用贝叶斯优化算法 (特别是树状结构 Parzen 估计器,或 TPE) 来导航搜索空间。
解决方案: MIPRO (多提示指令提议优化器)
MIPRO 旨在处理多阶段程序的噪声和复杂性。
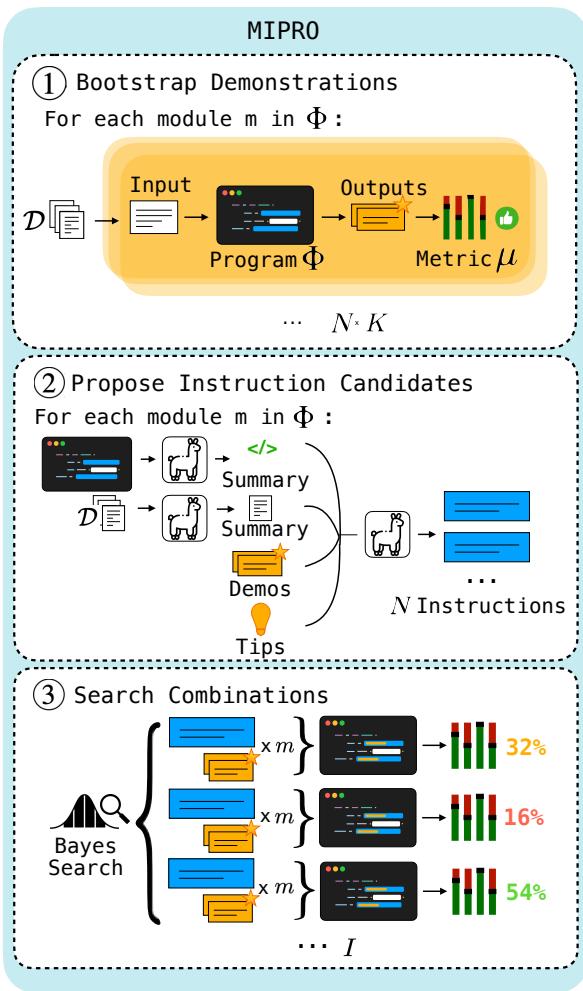
图 4 概述了完整的 MIPRO 流程:
- 自举: 从训练数据中生成有效的少样本演示。
- 提议: 使用 Grounded 提议者 LM 为管道中的每个模块生成多样化的候选指令。
- 搜索 (大脑) : 这是 MIPRO 的亮点。它将指令的选择 (从提议集中) 和演示的选择视为离散变量。它使用贝叶斯代理模型来预测哪种组合表现最好。
至关重要的是,MIPRO 使用 小批量处理 (minibatching) 。 它不是在每次试验中运行完整的训练集 (这很昂贵) ,而是在小批量数据上评估候选者,以快速更新其关于哪些参数有效的信念。这使得它能够比随机搜索更有效地探索搜索空间。
实验与结果
研究人员在七个不同的任务上对这些优化器进行了基准测试,包括 HotPotQA (多跳推理) 、HoVer (事实验证) 和 ScoNe (逻辑否定) 。
他们比较了三种主要设置:
- 零样本 (Zero-Shot) : 仅优化指令。
- 少样本 (Few-Shot) : 仅优化演示。
- 联合 (MIPRO) : 同时优化两者。
关键发现 1: MIPRO 总体上优于基线
通过联合优化指令和演示,MIPRO 在 7 个任务中的 5 个任务上取得了最佳结果。
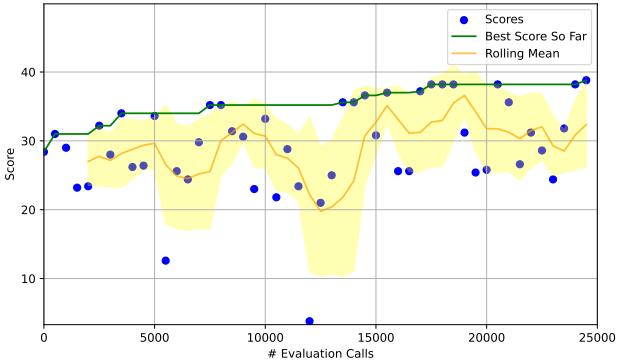
观察 HotPotQA 结果 (图 9) , 我们可以看到性能轨迹。右下角的图表 (MIPRO) 显示出性能稳步攀升 (绿线) ,最终超过了其他方法。“滚动均值 (Rolling Mean) ” (橙色区域) 表明优化器随着学习过程,通过一致地找到更好的配置。
关键发现 2: 演示往往比指令更强大
对于许多任务,仅仅找到正确的少样本示例 (自举) 比重写提示文本能带来更大的提升。
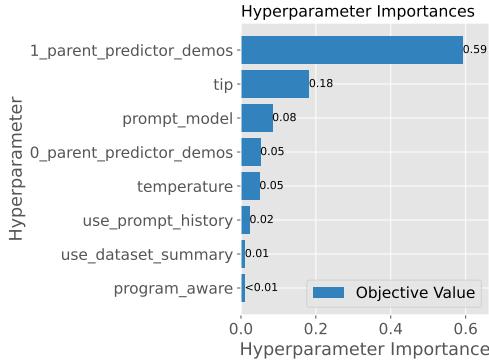
MIPRO 中的贝叶斯模型允许我们检查“特征重要性”——本质上是哪些变量对分数影响最大。在 图 6 中,我们看到对于 HotpotQA,_parent_predictor_demos (演示的选择) 的重要性得分 (0.59) 明显高于 tip (提示技巧) 或模型的 temperature (温度) 。
关键发现 3: 指令对于“条件”逻辑至关重要
然而,指令并非毫无用处。研究人员创建了一个具有复杂格式规则的“HotPotQA Conditional (条件版) ”任务 (例如,“如果答案是一个人,请使用小写”) 。在这种情况下,少样本示例不足以教会模型这些规则。优化器必须改进指令文本才能获得高性能。
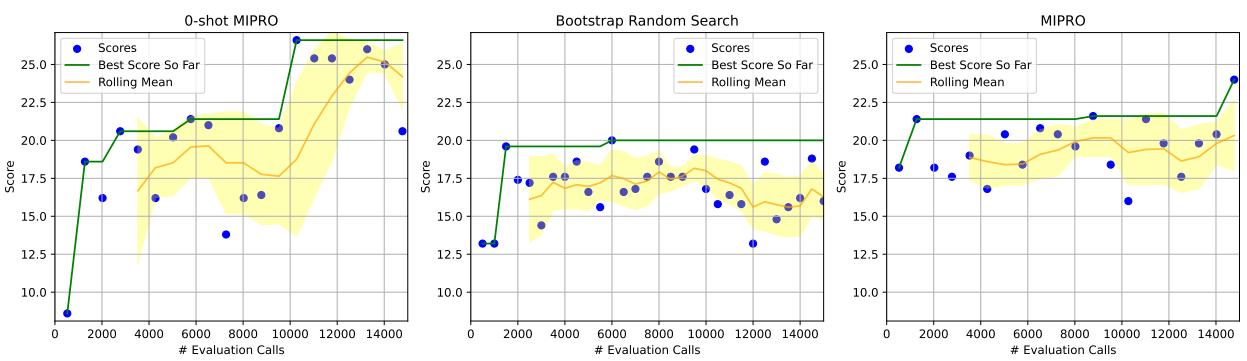
在 图 11 (HotPotQA 条件版) 中,请注意 0-Shot MIPRO (左) 和 MIPRO (右) 图表如何获得高分,而 自举随机搜索 (中) ——仅优化演示——则非常挣扎。这证明当任务涉及复杂的逻辑或约束时,指令优化是不可或缺的。
结论与启示
从手动提示工程向自动化优化的过渡是不可避免的。随着 LM 程序变得越来越复杂,人类根本无法凭借直觉找到 10 步管道的最佳提示组合。
这篇论文为这种自动化提供了一个强大的框架。给学生和从业者的主要启示是:
- 不要只调整提示文本: 少样本演示的选择往往是杠杆率最高的超参数。
- 使用 Grounding: 当要求 LM 编写提示时,给它提供数据摘要和代码上下文。
- 联合优化: 指令和演示之间的相互作用是复杂的。像 MIPRO 这样同时调整它们的优化器能产生最好的结果。
通过将自然语言提示视为网络中的优化权重,我们正迈向一个“编程”LM 看起来更少像写文章,而更多像训练神经网络的未来。