](https://deep-paper.org/en/paper/2406.12050/images/cover.png)
如果你曾辅导过学生的数学,你就会知道死记硬背和真正理解之间有着明显的区别。
一个死记硬背的学生也许能解出一个特定的一元二次方程,因为他已经看过这种模式五十次了。但如果你问他: “如果系数是负数,这会有什么变化?”或者“你能用不同的方法解这道题吗?”,他们就会崩溃。他们掌握了答案 , 但缺乏推理深度 。
大语言模型 (LLM) 经常遭受同样的困扰。虽然监督微调 (Supervised fine-tuning) 让它们非常擅长输出标准数学问题的分步解答,但它们往往缺乏处理后续问题或纠正自身错误的灵活性。
在这篇文章中,我们将深入探讨一篇引人入胜的论文: “Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning” (超越答案的学习: 通过反思训练语言模型的数学推理能力) 。这项研究提出了一种转变模型训练方式的思路: 我们不应仅仅向模型投喂更多的问题 (广度) ,而应该训练它们对已经解决的问题进行反思 (深度) 。
广度与深度的问题
要理解这篇论文的贡献,我们需要先看看大语言模型数据增强的现状。
数据是 AI 的燃料。在数学推理领域,高质量的人工标注数据既稀缺又昂贵。为了解决这个问题,研究人员使用数据增强——利用现有的模型 (如 GPT-4) 为较小的模型生成更多的训练数据。
传统上,这通过两种方式实现:
- 问题增强 (Q-Aug): 获取现有问题并调整数字或场景以创建新问题。
- 答案增强 (A-Aug): 获取现有问题并要求模型生成一个新的、也许更清晰的解题路径。
这些方法的运作原则是广度 。 它们假设如果模型看到足够多的变体,最终就能实现泛化。然而,这篇论文背后的研究人员认为,单纯堆砌更多实例并不一定能带来更深层次的理解。这会造就出擅长“前向推理” (从 A 到 B) 但拙于“反思性推理” (回顾 A 和 B 以理解其关系) 的模型。
作者提出了第三种方式: 反思性增强 (Reflective Augmentation, RefAug) 。

如上图 Figure 1 所示:
- (b) 问题增强 添加了新的输入 (\(Q'_i\))。
- (c) 答案增强 添加了新的输出 (\(A'_i\))。
- (d) 反思性增强 改变了训练数据本身的结构。它在答案的末尾附加了一个反思部分 (\(R_i\)) 。
什么是反思性增强?
RefAug 的灵感来自人类的学习策略。教育心理学表明,“过度学习”——一遍又一遍地练习同类型的问题——收益递减。相反,深刻的理解来自于反思 : 回顾所做的工作,考虑替代方案,并与其他概念建立联系。
该方法的实现出人意料地优雅。
训练序列
在标准设置中,模型被训练为给定问题 (\(Q\)) 预测答案 (\(A\))。 在 RefAug 中,模型被训练为给定问题 (\(Q\)) 预测 答案 + 反思 (\([A; R]\))。
反思部分并不是随机文本。作者根据 Stacey 等人 (1982) 的教育理论对其进行了定义,要求包含两个特定组件:
- 替代推理 (Alternative Reasoning): 模型必须使用不同的方法解决同一个问题。这可以防止僵化的模式匹配。
- 后续推理 (Follow-up Reasoning): 模型必须扩展其理解。这通过以下方式实现:
- 抽象化 (Abstraction): 概括问题 (例如,用变量替换具体数字) 。
- 类比 (Analogy): 创建并解决一个更难的相关问题。

Figure 3 完美地展示了这种结构。注意这个流程:
- 原始问题: 求特定二次函数的最大值。
- 初始解答: 配方法 (标准方法) 。
- 反思 (替代) : 求导 (微积分方法) 。
- 反思 (后续) : 推广到 \(ax^2 + bx + c\) (抽象化) 或求解三次函数 (类比) 。
通过强制模型在训练期间生成这些反思,模型本质上是在对数学概念进行“冥想”。它学到答案不仅仅是一串需要预测的 token,而是一个灵活逻辑过程的结果。
推理阶段的妙招
你可能会想: “在实际使用模型时,生成所有这些额外文本不会让模型变慢吗?”
这就是聪明之处。 反思仅用于训练。
在推理 (测试/部署) 期间,给定问题,模型生成答案。一旦它遇到标志着“反思”部分开始的标记,生成就会被提前停止 。
假设是,学习预测反思的行为更新了模型的内部权重,从而提高了初始答案的质量。反思的“智慧”已经融入了模型的神经通路中,即使它没有显式地输出这些文本。
为什么反思胜过死记硬背: 一个案例研究
为了理解这为何重要,我们来看一个涉及换元法的具体代数例子。
换元法是代数中的一个强大工具,但模型通常死记硬背换元问题的样子,而不理解其原理。

在 Figure 2 中,我们看到一个训练问题: \((x-99)(x-101)=8\)。
- 标准训练: 模型看到令 \(t = x-100\) 的解法。它学到了一个特定的模式: “找到中间的数”。
- RefAug: 模型看到了标准解法,加上一种替代方法 (令 \(t=x-99\)) 和一个后续问题。它学到换元法是为了简化方程,而不仅仅是找中点。
测试: 当面对一个新的、更难的问题 \((7x+1)(9x+1)=61\) 时,标准模型失败了。它试图代换 \(8x+1\) (中点) ,但因为数学运算变得混乱而卡住了。RefAug 模型由于具有更深的概念理解,识别出它可以先相乘各项以统一系数,然后进行换元,从而正确解决了问题。
实验结果
理论听起来很合理,但在实际中有效吗?作者使用 Mistral-7B 和 Gemma-7B 等模型在多个维度上测试了 RefAug。
1. 标准数学推理
首先,他们检查了 RefAug 是否有助于标准的单轮问答 (如 GSM8k 和 MATH 数据集) 。尽管在测试期间没有生成反思,但训练的影响是显著的。
平均而言, RefAug 比直接微调的准确率提高了 +7.2% 。
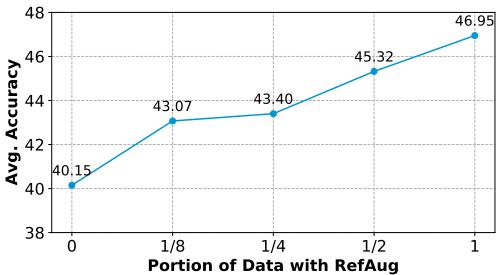
Figure 4 显示了一个清晰的趋势: 用反思增强的数据越多 (从 0% 到 100%) ,模型在标准数学任务上的表现就越好。这证实了模型不仅仅是在记忆特定的答案;它在整体上变成了一个更好的推理者。
2. “反思”差距
最显著的结果来自那些真正需要深度思考的任务——特别是后续问答 (Follow-up QA) (模型必须根据第一个问题回答第二和第三个问题) 和错误纠正 (Error Correction) (模型必须修正错误) 。
标准数据增强 (Q-Aug 和 A-Aug) 在这里基本失败了。在某些情况下,添加更多标准数据实际上损害了模型纠正错误的能力。然而,RefAug 表现出色。
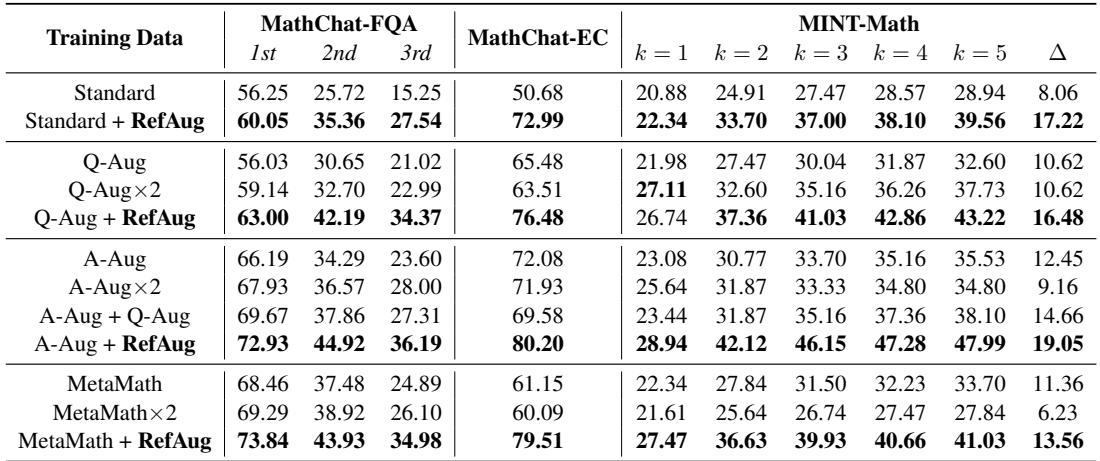
观察 Table 2 :
- MathChat-EC (错误纠正) : 标准训练得分为 50.68%。RefAug 跃升至 72.99% 。
- MINT (反馈) : 这个基准测试衡量模型是否能在给定反馈的情况下改进其答案。RefAug 显著优于其他方法,表明它变得更具“可教导性”。
这突显了一个关键发现: 你无法通过强行堆砌数据来获得深度理解。 仅仅生成 100,000 个额外的数学问题 (Q-Aug) 并不能教会模型如何修正自己的错误。你必须训练它从多个角度看问题。
3. 泛化到代码
在 AI 世界中,数学和编程是近亲——两者都需要严格的逻辑和逐步执行。研究人员将 RefAug 应用于代码生成任务 (使用 HumanEval 和 MBPP 基准) 。
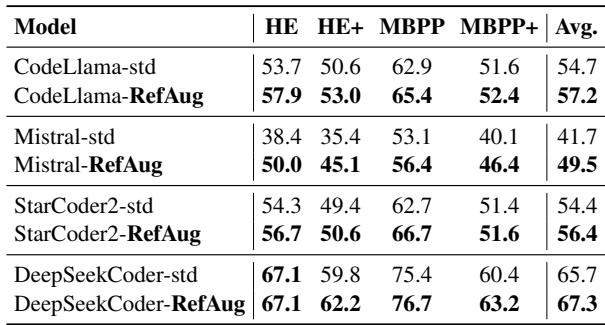
正如 Table 5 所示,这种优势完美地迁移了过来。RefAug 提高了 CodeLlama、Mistral 和 StarCoder2 的性能。通过要求模型反思它刚刚编写的代码 (也许通过抽象化或替代实现) ,模型变成了一个更好的程序员。
这为何重要
这篇题为“Learn Beyond The Answer”的论文为当前 LLM 训练的轨迹提供了一个关键的修正。我们目前正处于“数据匮乏”时代——我们正在耗尽用于训练的高质量人类文本。
行业的下意识反应是利用 AI 生成海量的合成数据。但这篇论文警告我们, 仅仅有量是不够的 。 如果我们只是用 AI 生成数百万对浅显的问答,我们将创造出广而不深的模型——这些模型可以通过考试,但无法解释它们为什么正确,或者在错误时无法自我修正。
主要收获:
- RefAug 是互补的: 你不必在 RefAug 和其他方法之间做选择。论文表明,将答案增强与反思性增强结合使用,效果最好。
- 效率: 由于反思在推理过程中被剥离,你在部署时获得了一个更聪明的模型,而无需付出延迟代价。
- “教师”模型很重要: 本文中的反思部分是由 GPT-4 生成的。反思的质量至关重要。如果“老师”给出糟糕的类比,学生就会学到坏习惯。
通过将反思嵌入训练循环,我们正朝着模仿人类学习过程的模型迈进: 解题、反思、归纳,直至精通。