](https://deep-paper.org/en/paper/2406.12125/images/cover.png)
引言
在人工智能飞速发展的版图中,大型语言模型 (LLM) 已确立了其在知识和推理领域无可争议的王者地位。从编写代码到总结历史,它们的能力极其广泛。然而,在生成文本与在动态环境中采取最佳行动之间,仍存在显著的差距。
想象一下推荐系统、医疗分诊机器人或数字助手。这些都属于序贯决策 (sequential decision-making) 问题。智能体观察上下文,选择一个动作,并接收反馈 (奖励或损失) 。传统上,我们使用像上下文多臂老虎机 (Contextual Bandits) 这样的算法来解决这些问题。这些算法计算成本低廉且长期学习效果好,但它们深受“冷启动”问题的困扰——它们从零知识开始,必须通过随机尝试来学习哪些行为是有效的。
另一方面,LLM 一开始就拥有大量的“常识”知识。它们可以立即做出不错的决策。但有一个问题: 它们体积庞大、速度慢且是静态的。如果不进行复杂且昂贵的微调,它们无法自然地从用户反馈中“学习”。
因此,我们要面临一个两难的选择: 是选择起步笨拙但学习速度快的模型 (上下文多臂老虎机) ,还是选择极其昂贵且无法适应环境的天才模型 (LLM) ?
在这篇文章中,我们将详细解读一篇精彩的论文,题为 “Efficient Sequential Decision Making with Large Language Models” (利用大型语言模型进行高效序贯决策) ,该论文由南卡罗来纳大学和加州大学河滨分校的研究人员撰写。他们提出了一种混合框架,充当桥梁作用,利用 LLM 的初始智慧来“预热”标准的决策算法,然后无缝地将控制权移交给更便宜、更快的模型。结果如何?一个在统计上优于两者且计算高效的系统。
背景: 主要角色
在深入探讨解决方案之前,让我们简要定义一下研究人员试图协调的两个主要组件。
1. 序贯决策 (上下文多臂老虎机)
在上下文多臂老虎机问题中,智能体分轮次行动。在每一轮 \(t\) 中:
- 智能体看到一个上下文 \(x_t\) (例如,用户的个人资料和搜索历史) 。
- 智能体选择一个动作 \(a_t\) (例如,推荐特定产品) 。
- 智能体收到一个损失或奖励 (例如,用户点击了吗?) 。
目标是随时间推移最小化总损失。挑战在于探索-利用权衡 (exploration-exploitation tradeoff) 。 智能体必须探索新动作以发现更好的选择,同时利用已知的好动作来最大化奖励。标准算法 (如 SpannerGreedy) 最终能很好地做到这一点,但它们从零知识开始,导致初始表现不佳。
2. LLM 作为智能体
LLM 可以通过提示 (Prompt) 来做出决策。例如,你可以向 LLM 提供产品描述,并要求它预测正确的类别标签。
- 优点: 它们拥有巨大的先验知识。它们不需要“学习”智能手机属于“电子产品”——它们已经知道了。
- 缺点: 它们体量巨大。在高流量系统中为每次用户交互运行 GPT-4 甚至 Llama 3 通常成本过高且速度缓慢。此外,基于单次点击 (反馈) 更新它们需要梯度更新 (微调) ,这是极其昂贵的。
核心方法: 在线模型选择
研究人员提出了一个框架,不强迫我们非此即彼。相反,他们使用在线模型选择 (Online Model Selection) 。 可以将其视为位于 LLM 和上下文多臂老虎机 (CB) 之上的“管理者”算法。
在一开始,管理者知道 CB 尚未经过训练,因此它将大部分决策委托给 LLM。LLM 做出好的选择,关键在于, 由 LLM 生成的数据 (上下文、动作和奖励) 被用于训练 CB。
随着 CB 从这些高质量数据中学习,它开始进步。管理者观察到这种进步,并逐渐将工作负载从昂贵的 LLM 转移到便宜且现已具备能力的 CB 上。
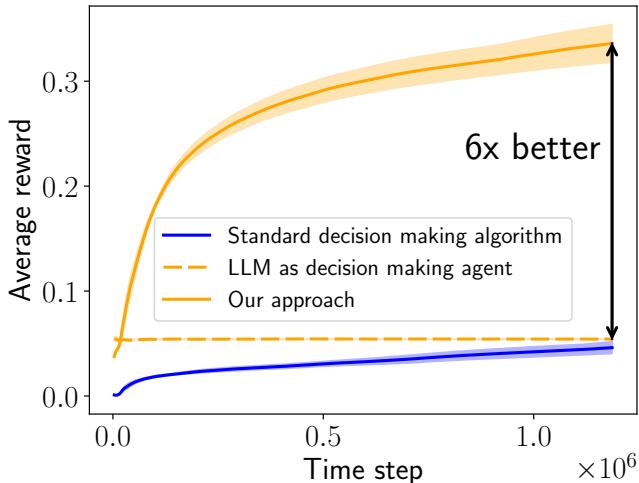
如上图 图 1 所示,这种方法 (橙色实线) 结合了双方的优势。它避免了标准算法 (蓝色线) 的低起步,并超越了独立 LLM (橙色虚线) 的平坦表现,最终实现了 6 倍的性能提升 。
第一步: 将 LLM 转化为策略
一个实际的障碍是 LLM 输出的是文本,而决策算法通常从一组离散的动作中进行选择 (如 ID #452 或 ID #901) 。
为了解决这个问题,作者使用了基于嵌入的方法 (论文中的算法 1) :
- 用上下文提示 LLM (例如,“预测物品标签…”) 。
- LLM 生成文本响应。
- 该响应被转换为向量嵌入。
- 系统计算此响应向量与所有可能的有效动作的嵌入向量之间的相似度。
- 选择相似度最高的动作。
这使得任何现成的 LLM 无需任何训练即可作为决策策略发挥作用。
第二步: 平衡之道
论文的核心是 算法 2 。 这是一个决定谁来采取行动的循环。
在每个时间步 \(t\):
- 框架持有一个概率分布 \(p_t\)。这代表选择 LLM 与上下文多臂老虎机的概率。
- 它根据 \(p_t\) 采样一个选择。
- 被选中的智能体采取行动,并观察到奖励。
- 关键点: 无论谁采取行动,上下文多臂老虎机都会利用该数据更新其内部模型。这意味着即使是 LLM 在工作,老虎机也在学习。
- 框架为下一轮更新 \(p_t\)。
第三步: 采样策略
我们如何更新 \(p_t\)?我们希望早期依赖 LLM,后期逐渐将其淡出。作者探索了几种策略。
简单衰减 (Simple Decay) : 最简单的方法是强制使用 LLM 的概率 (\(p_t^{LLM}\)) 随时间下降,无论是多项式衰减还是指数衰减。
多项式衰减如下所示:
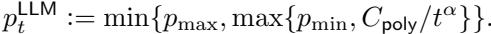
指数衰减下降得更快:
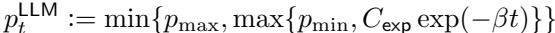
基于学习的策略 (对数障碍 OMD) : 虽然简单衰减有效,但作者更倾向于一种更智能的方法,称为对数障碍在线镜像下降 (Log-Barrier Online Mirror Descent, OMD) 。OMD 不会盲目减少 LLM 的使用,而是查看两个智能体的表现 (损失) 。它根据哪个智能体实际表现更好来动态调整概率。如果老虎机的学习速度比预期的慢,系统会让 LLM 参与更长时间。
预算约束: 现实世界的系统通常对 LLM 调用有硬性预算 (例如,“我们只能负担 10,000 次 API 调用”) 。作者引入了一项修改以严格限制 LLM 的使用:
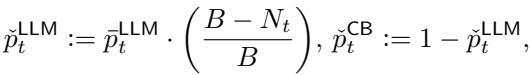
这里,\(N_t\) 是迄今为止进行的调用次数,\(B\) 是预算。随着预算耗尽,调用 LLM 的概率被强制归零。
实验与结果
为了验证这一框架,研究人员在两个涉及基于文本的决策的不同数据集上对其进行了测试。

表 1 概述了数据集:
- OneShotWikiLinks-311: 一个命名实体识别任务 (311 个可能的动作) 。
- AmazonCat-13K: 一个拥有超过 13,000 个可能动作 (标签) 的大规模多标签分类任务。
统计效率: 更高的奖励
主要指标是平均奖励 (越高越好) 。
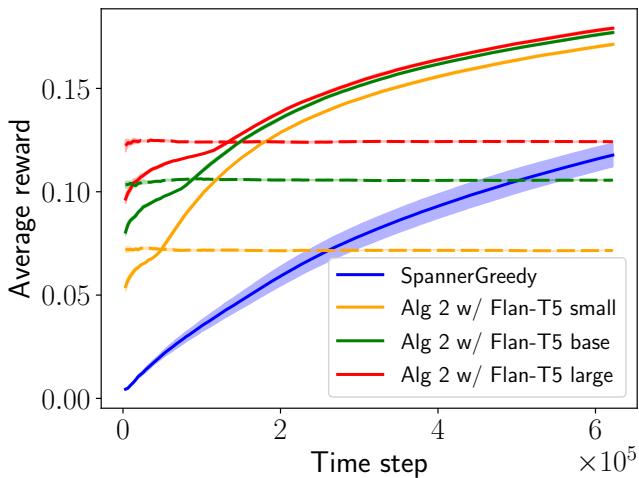
在 图 2 中,我们看到了在 WikiLinks 数据集上使用不同大小的 Flan-T5 模型 (Small, Base, Large) 的结果。
- 蓝线 (SpannerGreedy): 标准老虎机算法起步很差,学习缓慢。
- 虚线: 这些是纯 LLM。注意模型越大,静态性能越好,但它们从不进步。
- 实线/点线 (算法 2): 提出的方法立即飙升。值得注意的是, 使用 Flan-T5 Small 的算法 2 (黄线) 最终超越了纯粹的 Flan-T5 Large (红虚线) 。 这证明了由弱 LLM 辅助的智能学习算法可以击败单独行动的强 LLM。
计算效率: 成本因素
这是该论文对行业应用最有力的论证。运行 LLM 是昂贵的。

表 2 显示了执行时间的巨大差异。Flan-T5 Large 模型的一次决策比上下文多臂老虎机长近 160 倍 。
然而,由于提出的框架随着老虎机的学习将概率从 LLM 移走,从长远来看,它很少调用 LLM。

表 3 显示,在实验过程中,LLM 仅在 6% 到 14% 的时间里被调用。与“LLM 作为智能体”基线所需的 100% 相比,这是巨大的资源节省。
此外,当使用前面讨论的公式显式限制预算时,算法仍然表现出色:
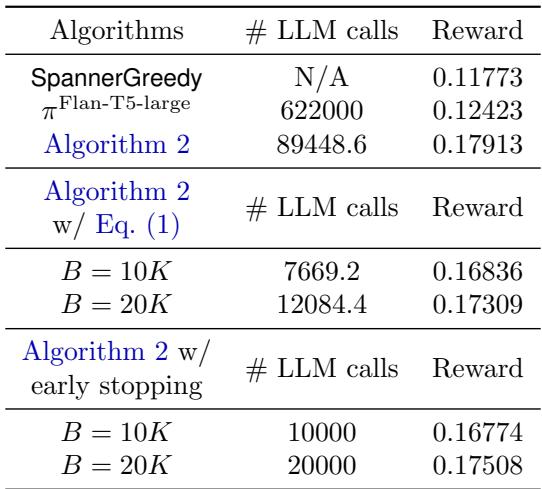
如 表 4 所示,即使将 LLM 调用限制在严格的预算内 (例如 60 万轮中仅 1 万次调用) ,奖励 (0.168) 仍显著高于标准老虎机 (0.117) 。
它适用于现代 LLM 吗?
研究人员并未止步于 T5。他们在困难的 AmazonCat 数据集上测试了带有 Gemma 2B 和 GPT-4o-mini 的框架。
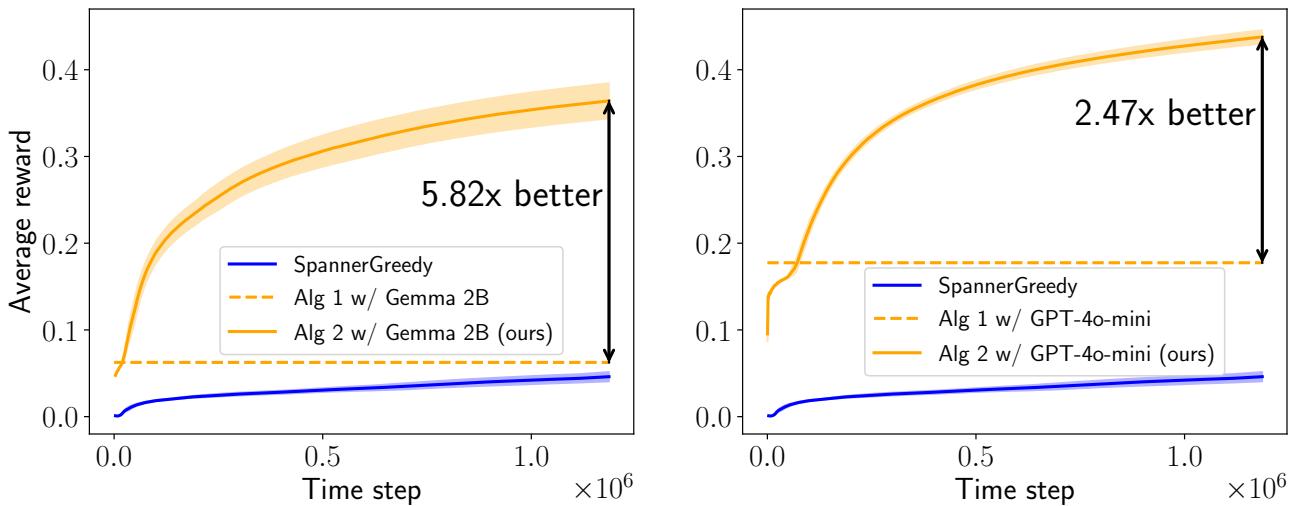
图 3 证实了这一趋势依然成立。
- 左图 (Gemma 2B): 混合方法 (橙色实线) 主导了基线,实现了 5.82 倍 的增益。
- 右图 (GPT-4o-mini): 混合方法实现了 2.47 倍 的增益。
在这两种情况下,系统都受益于高级模型的“推理”能力,以引导老虎机穿过包含 13,000 个项目的复杂动作空间。
为什么有效?分析
究竟为什么混合模型的表现能超越其两个父代?
假设是 LLM 充当了“老师”。在标准老虎机设置中,算法随机探索。在巨大的动作空间 (如 13,000 个标签) 中,随机探索是无效的——你几乎永远无法通过运气选中正确的标签。
然而,LLM 即使不完美,也能显著缩小搜索空间。它建议看似合理的动作。老虎机观察这些“聪明”的交互并更新其权重。
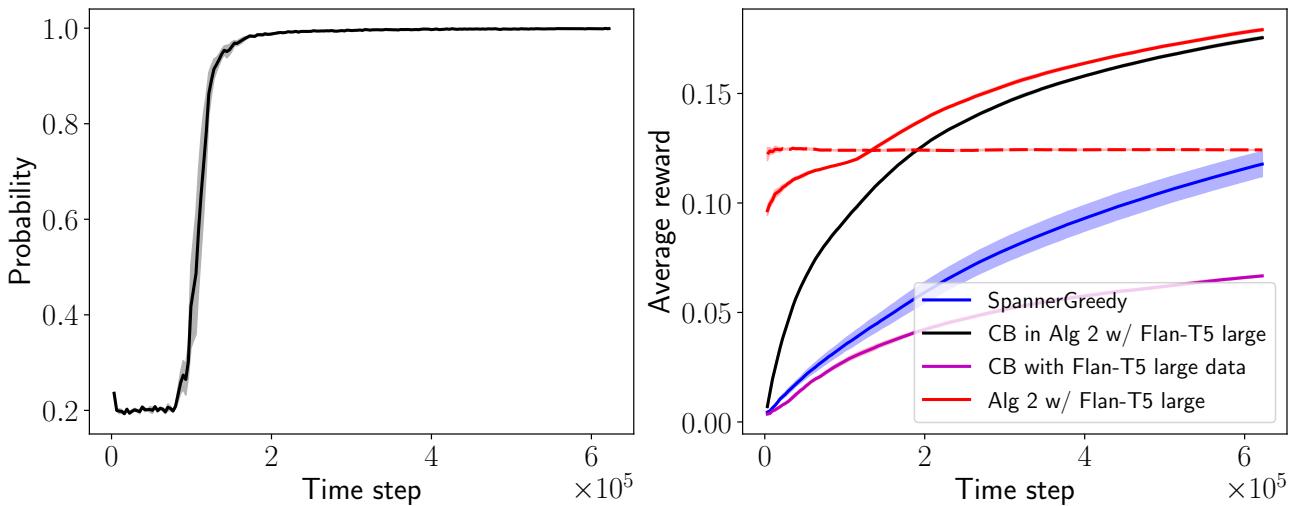
图 4 完美地展示了这一动态:
- 左图: 显示使用上下文多臂老虎机的概率 (\(p_t^{CB}\)) 。它开始时很低,但迅速接近 1.0。系统本质上是在“断奶”,摆脱对 LLM 的依赖。
- 右图: 黑线显示了老虎机组件如果单独运行但在混合循环内接受训练的假设性能。它学习得非常快。紫线显示了仅在 LLM 数据上训练的老虎机。黑线和紫线之间的差距表明交接至关重要。老虎机最终需要接管并进行其自己的精细探索,以超越老师。
结论与启示
这篇研究论文提出了一个引人注目的“即插即用”框架。它允许工程师利用现成的 LLM 和标准老虎机算法,结合创造出一个决策智能体,它:
- 比传统算法更聪明 (避免冷启动) 。
- 比纯 LLM 适应性更强 (从反馈中学习) 。
- 比纯 LLM 更便宜 (减少超过 85% 的推理调用) 。
对于学生和从业者来说,结论很明确: 我们并不总是需要微调庞大的模型来获得好结果。有时,最有效的解决方案是让大模型教导一个更小、更专业的算法,从而两全其美。
策略比较
最后,作者比较了不同的概率更新策略如何影响最终结果。

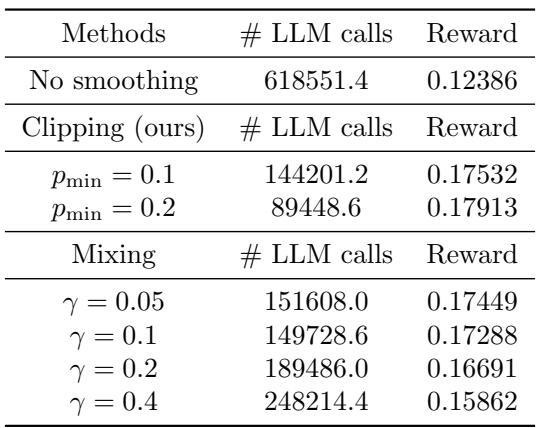
表 5 和 表 6 强调,虽然简单的衰减策略有效,但 对数障碍 OMD (自适应策略) 产生了最高的奖励,而使用“截断 (Clipping) ”平滑策略有助于防止老虎机在过程中过早被忽略。
这项工作为高效 AI 智能体铺平了道路,使其能够在实时环境中运行,而无需在推理成本上倾家荡产。