](https://deep-paper.org/en/paper/2406.12168/images/cover.png)
将大型语言模型 (LLM) 与人类价值观对齐是现代人工智能中最关键的挑战之一。我们希望模型能够乐于助人、无害且简洁。很长一段时间以来,实现这一目标的黄金标准是基于人类反馈的强化学习 (RLHF) 。 然而,如果你曾尝试过训练 RLHF 流程,就会知道其中的痛苦: 它涉及训练一个独立的奖励模型,处理复杂的强化学习不稳定性,并管理巨大的计算成本。
最近,一类被称为直接偏好对齐 (Direct Alignment from Preferences, DAP) 的新方法——其中最著名的是直接偏好优化 (DPO) ——承诺简化这一过程。通过消除对独立奖励模型的需求,DPO 使得对齐变得容易得多。
但这里有一个陷阱。大多数 DPO 的实现都是离线 (offline) 的。它们从一个静态的、预先收集的数据集中学习。随着模型的学习,它开始生成的文本与那个静态数据集看起来会大不相同,而由于它停止获取关于其新行为的反馈,学习就会停滞不前。
这就引出了我们今天要剖析的研究论文: “BPO: Staying Close to the Behavior LLM Creates Better Online LLM Alignment” (BPO: 紧贴行为 LLM 能创造更好的在线 LLM 对齐) 。研究人员提出了一种名为 BPO (Behavior Preference Optimization,行为偏好优化) 的新方法。他们认为,要真正修复对齐问题,我们不仅必须从离线学习转向在线学习,而且必须从根本上改变模型在训练过程中约束自身的方式。
在这篇文章中,我们将梳理当前对齐方法的局限性,BPO背后的数学直觉,以及这种新方法如何在仅使用一小部分标注预算的情况下,表现优于最先进的方法。
背景: RLHF 与 DAP 的兴起
要理解 BPO,我们首先需要理解 LLM 对齐中的“信任区域 (trust region) ”问题。
传统 RLHF
在标准的 RLHF (如 PPO) 中,我们训练模型以最大化奖励分数。然而,我们不能让模型仅仅为了获得高分而输出乱码来利用奖励函数的漏洞。我们需要一个约束。我们强制训练后的模型 (\(\pi_{\theta}\)) 保持在接近原始参考模型 (\(\pi_{ref}\)) 的状态,这个参考模型通常是监督微调 (SFT) 模型。
目标函数如下所示:
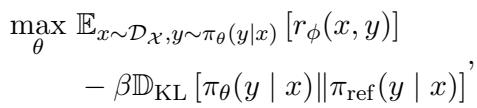
项 \(\beta \mathbb{D}_{\text{KL}}\) 是 KL 散度 。 可以把它想象成一根“绳索”或“皮带”。它防止新模型偏离参考模型太远。
直接偏好对齐 (DAP)
像 DPO、IPO 和 SLiC 这样的方法之所以聪明,是因为它们在数学上重新排列了 RLHF 的目标。它们允许我们直接在偏好对 (获胜回复 \(y_w\) vs. 失败回复 \(y_l\)) 上优化模型,而无需首先显式地训练奖励模型。
以下是这些流行 DAP 方法的损失函数:

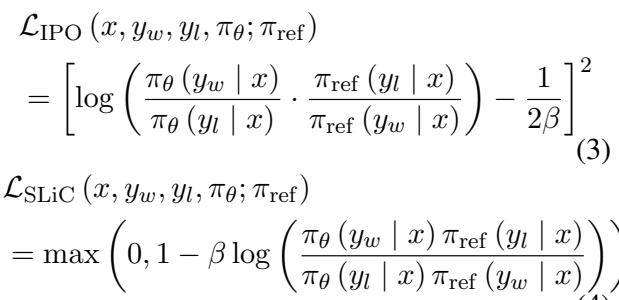
注意到所有这些方程中的一个共同模式了吗?它们都依赖于 \(\pi_{ref}\)。在几乎所有标准实现中,\(\pi_{ref}\) 都是固定的。它就是你开始时使用的那个静态 SFT 模型。
问题所在: 离线 vs. 在线
在离线 DAP 中,你收集一次数据集并在其上进行训练。问题在于分布偏移 (distribution shift) 。 随着模型的改进,它开始生成的回复与初始数据集非常不同。由于模型从未获得关于这些新的、独特的回复的反馈,它就无法有效地继续改进。
在线 DAP 试图通过在训练期间收集人类 (或 AI) 对模型当前输出的新反馈来解决这个问题。这听起来很棒,但这篇论文的作者发现了当前在线方法运作方式中的一个致命缺陷。
即使其他研究人员转向了在线 DAP,他们仍然将“绳索”拴在旧的、静态的 SFT 模型上 (\(\pi_{ref} = \pi_{SFT}\)) 。作者认为这是次优的。如果你的模型已经发生了显著进化,将其约束在一个几周前的模型上是没有意义的。
核心方法: BPO (行为偏好优化)
BPO 的核心洞察简单而深刻: 信任区域应当围绕行为 LLM (\(\pi_{\beta}\)) 构建,而不是静态的参考 LLM。
什么是行为 LLM?
行为 LLM (\(\pi_{\beta}\)) 是生成你当前正在训练的数据的那个特定版本的模型。
在离线设置中,行为 LLM 就是 SFT 模型,因为是它生成了数据集。但在在线设置中,每隔几步就会生成新数据,行为 LLM 就是那个时刻存在的模型。
BPO 算法
研究人员提出,我们不应将模型绑定到静态的过去,而应动态更新参考模型。
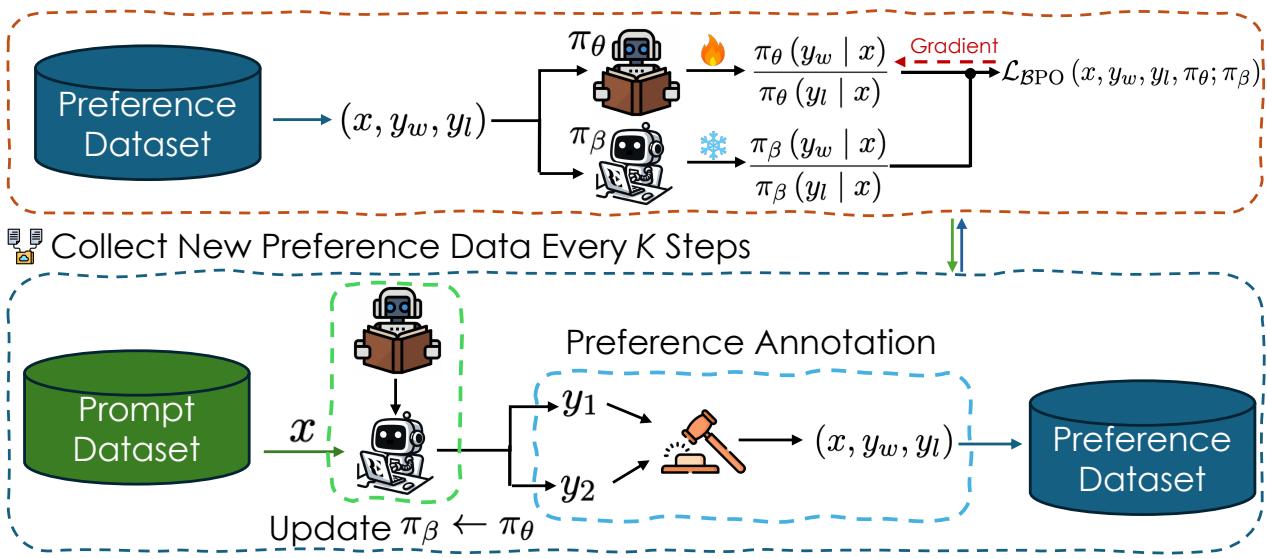
如上方的 Figure 2 所示,该流程如下:
- 提示词数据集 (Prompt Dataset) : 从一组提示词 (\(x\)) 开始。
- 生成 (Generation) : 当前策略生成成对的回复 (\(y_1, y_2\)) 。
- 标注 (Annotation) : 人类 (或 AI 裁判) 选出赢家 (\(y_w\)) 和输家 (\(y_l\)) 。
- 更新 \(\pi_{\beta}\): 关键在于,每隔 \(K\) 步,参考模型 \(\pi_{\beta}\) 会更新以匹配当前的学习者 \(\pi_{\theta}\)。
- 优化 (Optimization) : 训练模型以最小化 BPO 损失。
BPO 损失函数是对标准 DAP 损失的修改,但将参考模型换成了行为模型:
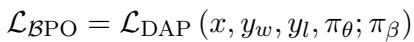
通过设置 \(\pi_{ref} = \pi_{\beta}\),“绳索”会随着模型一起移动。这确保了信任区域始终与模型探索的当前状态相关。
稳定训练
人们使用静态参考模型是有原因的: 移动的目标是不稳定的。如果你不断改变参考点,训练可能会崩溃或震荡。
作者发现,激进地更新参考模型在使用标准训练技术时会导致不稳定。为了解决这个问题,他们采用了集成 LoRA (Low-Rank Adaptation,低秩适应) 。
他们不再训练一组权重,而是优化 LoRA 适配器的集成。这作为一种正则化技术,平滑了学习过程。
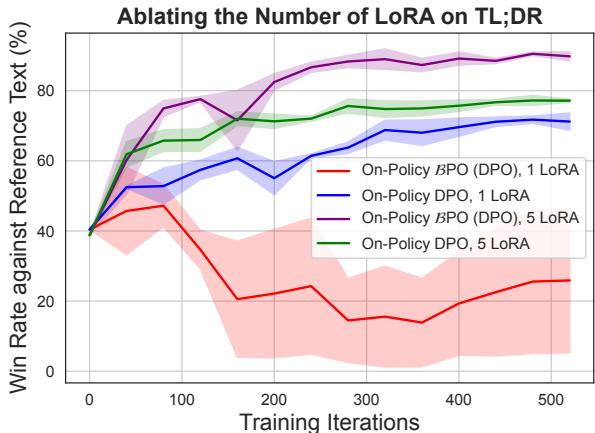
如 Figure 6 所示,使用单个 LoRA (红线) 训练会导致胜率低且无法提升。然而,利用 5 个 LoRA 权重的集成 (紫线) 稳定了训练,使 BPO 能够达到高性能。
实验与结果
研究人员将 BPO 与标准离线 DPO 和标准在线 DPO (参考模型保持静态) 进行了对比测试。他们使用了三个主要数据集:
- TL;DR: Reddit 帖子摘要。
- Anthropic Helpfulness: 回答用户问题。
- Anthropic Harmlessness: 拒绝有害指令。
1. BPO 击败基线
使用的主要指标是“相对于参考文本的胜率”。这衡量了模型的输出被判定优于人类编写的参考答案的频率。

Figure 3 展示了汇总结果。无论是看中位数、四分位均值 (IQM) 还是均值, 同策略 (On-Policy) BPO (绿色) 都一致地优于离线 DAP (蓝色) 和标准同策略 DAP (橙色) 。
这种提升并非微不足道。在 TL;DR 摘要任务上,BPO 将胜率从大约 77% (标准在线 DPO) 提高到了 89.5% 。
2. 效率: “预算”问题
对在线学习最大的批评之一是成本。每一步训练都将数据发送给人工标注员 (\(F=T\)) 既缓慢又昂贵。
研究人员问: 我们能否在不持续标注新数据的情况下获得 BPO 的好处?
他们对数据收集的频率 (\(F\)) 进行了实验。\(F=1\) 是离线 (收集一次) 。\(F=T\) 是完全同策略 (每一步都收集) 。

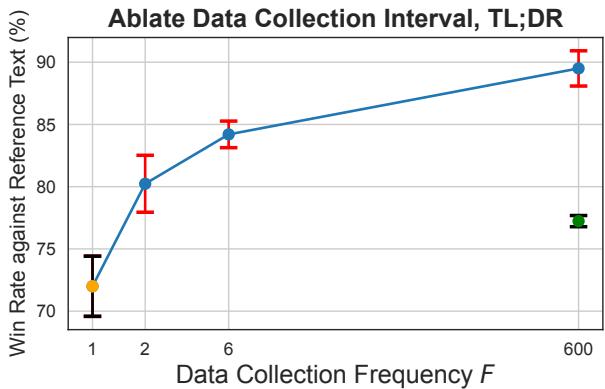
Figure 1 和 Figure 4 揭示了一个惊人的结果。看 Figure 1 中的蓝线。即使在 F=2 时——意味着在初始批次之后仅进行一次额外的数据收集和标注阶段——BPO 也显著优于离线基线。
事实上,BPO 在 \(F=2\) 时的表现与 \(F=T\) 时的标准同策略 DPO 相当。这意味着只需使用正确的参考模型 (行为模型) ,你就可以用传统在线方法所需标注成本的一小部分,获得最先进的对齐结果。
3. 仅仅是因为参考模型更好吗?
怀疑论者可能会问: “BPO 更好是否仅仅是因为参考模型 \(\pi_{\beta}\) 的质量比初始的 \(\pi_{SFT}\) 更高?”
为了测试这一点,作者进行了一项消融研究。他们采用了一个“黄金”模型 (一个完全训练好的、高质量的模型) ,并将其作为标准 DPO 的静态参考。
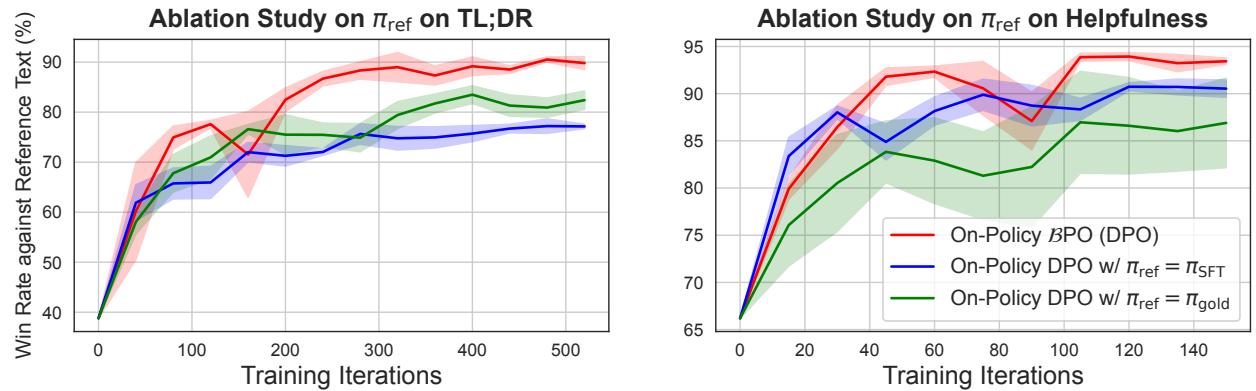
Figure 5 展示了结果。红线 (BPO) 仍然击败了绿线 (使用黄金参考的 DPO) 。
这证明了其中的魔力不仅仅在于拥有一个“好”的参考模型。魔力在于邻近约束 。 当模型被约束在生成其当前正在学习的数据的特定策略上时,它的学习效果最好。
结论
论文 “BPO: Staying Close to the Behavior LLM Creates Better Online LLM Alignment” 对我们思考如何对齐 AI 模型进行了重大修正。
长期以来,研究人员将参考模型视为一个静态锚点——一种防止模型遗忘其训练的安全机制。BPO 证明,在动态的在线学习世界中,这个锚点需要移动。通过将信任区域绑定到行为策略 (即模型此刻存在的状态) ,我们允许 LLM 更有效地从自身经验中学习。
关键要点:
- 在线 > 离线: 从模型生成的新鲜数据中学习优于静态数据集。
- 移动锚点: 在进行在线学习时,将你的参考模型设置为行为模型 (\(\pi_{ref} = \pi_{\beta}\)) 。
- 效率: 你不需要持续的标注。只需对行为模型进行一两次更新 (\(F=2\)) 就能产生巨大的收益。
- 稳定性至关重要: 像 LoRA 集成这样的技术对于保持这种动态训练过程的稳定是必要的。
随着我们迈向更多从交互中学习的自主 AI 智能体,像 BPO 这样的方法很可能会成为标准,取代过去的静态、离线流程。事实证明,要让 AI 变得更好,你必须让它紧贴自身的行为。