](https://deep-paper.org/en/paper/2406.12402/images/cover.png)
如果你曾在社交媒体的评论区花过时间,你很可能遇到过那种让你感觉不对劲的论点。这不一定是因为事实有误,而是因为连接这些事实的逻辑讲不通。
也许有人争辩说: “如果我们不立即禁止所有汽车,地球就完了。”你知道这是一个极端的立场,忽略了中间的解决方案,这是一种典型的虚假两难 (False Dilemma) 。 或者你读到: “我叔叔每天吃培根,活到了 90 岁,所以培根是健康的。”这就是以偏概全 (Faulty Generalization) ——拿单个数据点来套用整个群体。
在自然语言处理 (NLP) 和人工智能领域,我们在检测这些谬误方面已经做得相当不错。我们可以训练模型来审视一个句子并贴上标签: “人身攻击 (Ad Hominem) ”、“滑坡谬误 (Slippery Slope) ”或“转移话题 (Red Herring) ”。
但问题在于: 知道一个论点有缺陷,并不等于理解它为什么有缺陷。仅仅贴标签是有用的,但这无法帮助学生学会更好的写作,也无法帮助 AI 解释其推理过程。
在这篇深度文章中,我们将探讨一篇引人入胜的研究论文 《Flee the Flaw: Annotating the Underlying Logic of Fallacious Arguments Through Templates and Slot-filling》 (Flee the Flaw: 通过模板和槽位填充标注谬误论证的底层逻辑) 。研究人员提出了一种新颖的方法来审视糟糕论点的内部,超越简单的标签,转而绘制出断裂的逻辑本身。
问题所在: 谬误检测的“黑盒”
当前的计算论证研究主要集中在两件事上:
- 质量评分: 根据说服力给文章打分 (例如 7/10 分) 。
- 类型标签: 对谬误进行分类 (例如,识别出“稻草人”论证) 。
虽然有用,但这些方法将论证视为扁平的单词序列。它们并没有阐明推理错误的结构 。
想象一下老师批改论文。如果老师只是在空白处写上“不合逻辑”,学生什么也学不到。如果老师写道: “你假设因为事件 A 发生在事件 B 之前,所以 A 导致了 B,但这并没有得到证明”,学生就会获得顿悟。“Flee the Flaw” (简称 FtF) 背后的研究人员希望创建一个计算框架,来模仿这种更详细的解释。
背景知识: 论证图式
要理解研究人员是如何解决这个问题的,我们首先需要理解我们是如何构建好的论证的。在论证理论中,我们经常使用论证图式 (Argumentation Schemes) 。 其中最常见的一种是后果论证 (Argument from Consequence) 。
它看起来是这样的:
- 前提: 如果导致 [行动 A],将会发生 [后果 C]。
- 价值判断: [后果 C] 是坏的 (或好的) 。
- 结论: 因此,不应该 (或应该) 导致 [行动 A]。
这是大多数说服性写作的支柱。“你应该学习 (A) ,因为你会找到好工作 (C) 。”“你不应该吸烟 (A) ,因为它会导致癌症 (C) 。”
研究人员意识到,许多非形式谬误实际上是这种特定图式的腐败版本。它们表现得像有效的后果论证,但行动与后果之间的联系被破坏或篡改了。
核心方法: 可解释模板
这篇论文的核心是引入了谬误模板 (Fallacy Templates) 。 研究人员不只是想对论点进行分类;他们想通过填空 (槽位填充) 来揭示缺陷。
他们建立在现有的“论证模板”——推理的结构化表示——之上,并增加了一个关键的新组件: 前提 P’ (P-prime) 。
- P (标准前提) : 陈述的理由 (例如,“此行动导致此结果”) 。
- P’ (谬误前提) : 充当桥梁的隐含、错误的逻辑。这个前提解释了为什么该论证是失败的。
逻辑可视化
让我们看看这在实践中是如何运作的。考虑一个论点,某人建议不要参加高级课程,因为他们在一门特定的课上有过糟糕的经历。

在上面的 Figure 1 中,我们看到了分析的转变:
- (a) 谬误分类: 以前的系统只会将其标记为“以偏概全 (Faulty Generalization) ”。
- (b) 论证图式: 它识别出核心结构: “如果你参加高级课程 (A) ,它会损害你的 GPA (C) 。”
- (c) 谬误逻辑结构 (新贡献) : 这就是神奇之处。该模板识别出一个隐藏的前提 (\(P'\)) 。
- 作者暗示他们特定的“NLP 课程” (\(A'\)) 代表了所有“高级课程” (\(A\)) 。
- 谬误在于假设 \(A' = A\)。
通过明确标注这个 \(A'\) (子集) ,系统可以解释错误: “该论证是以偏概全,因为它将单门 NLP 课程视为所有高级课程的代表。”
模板清单
研究人员专注于四种常见的“有缺陷的归纳”谬误。在这些论证中,前提提供了一些支持,但不足以证明结论。
- 以偏概全 (Faulty Generalization) : 从小样本中得出广泛的结论。
- 虚假两难 (False Dilemma) : 将两个选项作为仅有的可能性提出。
- 错误因果 (False Causality) : 假设相关性意味着因果关系。
- 可信度谬误 (Fallacy of Credibility) : 诉诸不相关的权威。
针对每一种谬误,他们设计了特定的模板。
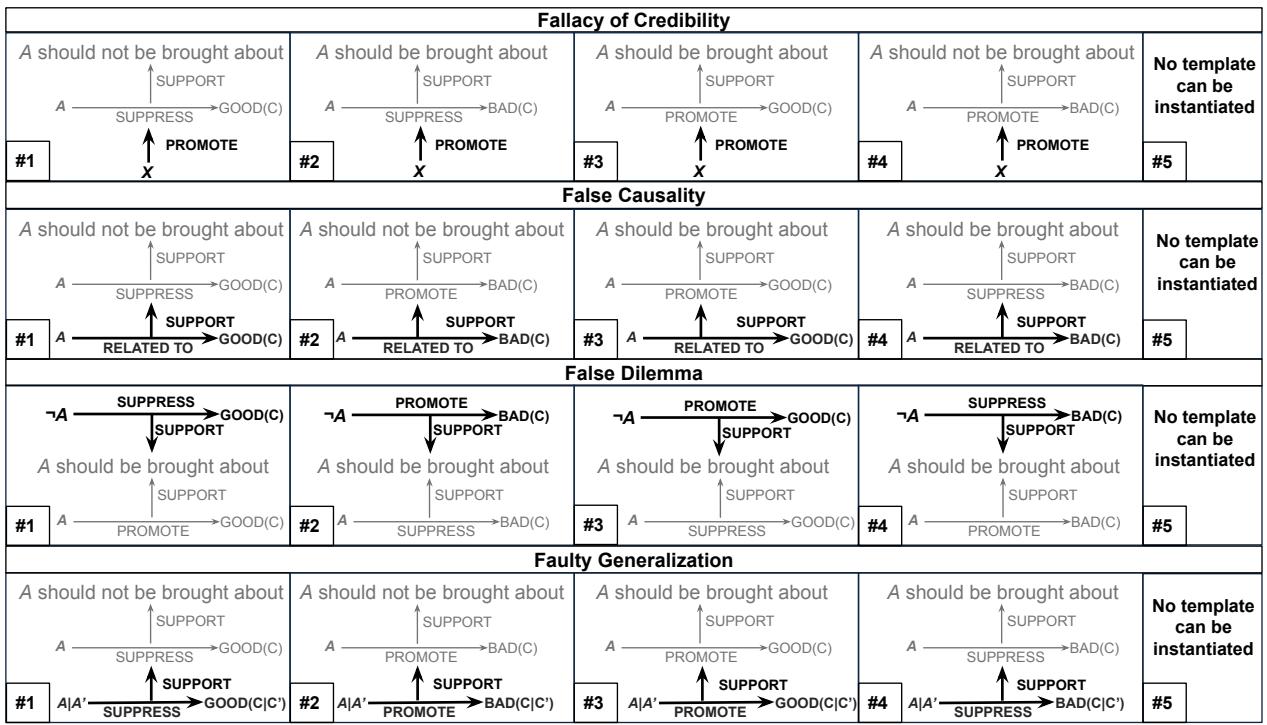
如 Figure 2 所示,这些模板非常灵活。它们可以处理正面论证 (“做这件事,因为它能促进好事”) 和负面论证 (“不要做这件事,因为它会抑制好事”) 。它们本质上为逻辑创造了一种“填词游戏”式的结构。
让我们使用论文中的特定模式来分解每种谬误类型。
1. 以偏概全 (Faulty Generalization)
这发生在用样本 (\(A'\)) 来代表整个群体 (\(A\)) 时。

在 Figure 3 中,论点是: “不要去那家修车厂 (\(A\)) ,因为那里的一名技工 (\(A'\)) 多收了我朋友的钱。”
- 缺陷: 模板捕捉到 \(A'\) (技工) 只是 \(A\) (修车厂) 的一个子集。
- 逻辑: \(A'\) 导致了一个坏的后果,但该论证错误地将这一属性转移到了整个修车厂 \(A\) 上。
2. 可信度谬误 (Fallacy of Credibility)
这通常被称为“诉诸权威”。当支持论点的人 (\(X\)) 实际上并不是该主题 (\(A\)) 的专家时,就会发生这种情况。
![可信度谬误图表。示例论点是“我最好的朋友发推文说披萨对健康有益……”。分析将“我最好的朋友”识别为 [X],“披萨”识别为 [A],“健康益处”识别为 [C]。该模板揭示了来源的权威性与主张之间的脱节。](/en/paper/2406.12402/images/009.jpg#center)
在 Figure 5 中,这个例子很搞笑但在结构上是合理的: “我最好的朋友 (\(X\)) 发推文说披萨 (\(A\)) 有健康益处 (\(C\)) ,所以我们应该吃它。”
- 缺陷: 模板突出显示了变量 \(X\) (最好的朋友) 。
- 逻辑: \(X\) 正在宣扬 \(A\) 导致 \(C\) 的观点。谬误模板将来源 (\(X\)) 分离出来,以便我们可以评估他们是否真的可信 (剧透: 最好的朋友通常不是营养学家) 。
3. 错误因果 (False Causality)
这是经典的“后此谬误 (Post Hoc Ergo Propter Hoc) ”。仅仅因为两件事是相关的 (\(RELATED\_TO\)) ,并不意味着一件事导致了另一件事 (\(SUPPRESS/PROMOTE\)) 。

在 Figure 6 中,论点声称因为吃酸奶 (\(A\)) 的人肠道健康,所以吃酸奶能确保你永不生病 (\(C\)) 。
- 缺陷: 模板将观察结果 (\(A\) 与 \(C\) 相关) 与因果主张 (\(A\) 抑制疾病) 分离开来。它凸显了逻辑上的跳跃。
4. 虚假两难 (False Dilemma)
这是“非此即彼”的谬误。它强迫在两个选项中做出选择,忽略了其他选项。
![虚假两难图表。示例论点是“我们要么减税,要么留下巨额债务……”。分析将“减税”识别为 [A],“留下债务”识别为 [C]。它描绘了论证所强加的有限“要么/要么”结构。](/en/paper/2406.12402/images/011.jpg#center)
在 Figure 7 中,论点是“我们要么减税 (\(A\)) ,要么留下债务 (\(C\)) 。”
- 缺陷: 模板描绘了前提: \(A\) 抑制 \(C\),而不做 \(A\) 会促进 \(C\)。这种结构暴露了作者制造的僵化依赖关系,让分析者可以问: “真的没有选项 D 吗?”
构建“Flee the Flaw”数据集
设计模板是一回事;将它们应用于现实世界的数据是另一回事。研究人员创建了 Flee the Flaw (FtF) 数据集。
他们从现有的名为 LOGIC 的数据集开始,该数据集包含关于气候变化和其他主题的谬误论证。他们选择了 400 个论证,并要求人类标注员应用新模板。
这不是一项简单的任务。逻辑是主观的。研究人员测量了标注者间一致性 (Inter-Annotator Agreement, IAA) ——本质上就是两个人独立选择相同模板和相同文本片段的频率。
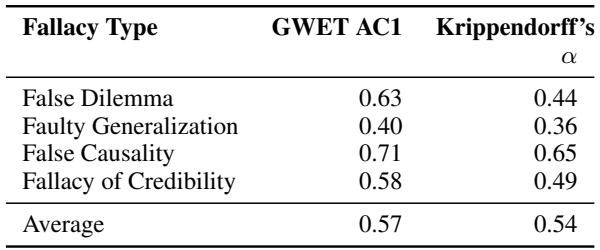
如 Table 1 所示,他们达到了 0.54 的 Krippendorff’s \(\alpha\) 值。在语言标注领域,对于如此复杂的高级认知任务,这被认为是“高一致性”。这证明了模板足够稳健,不同的人能以相同的方式理解它们。
然而,分布并不完全均匀。
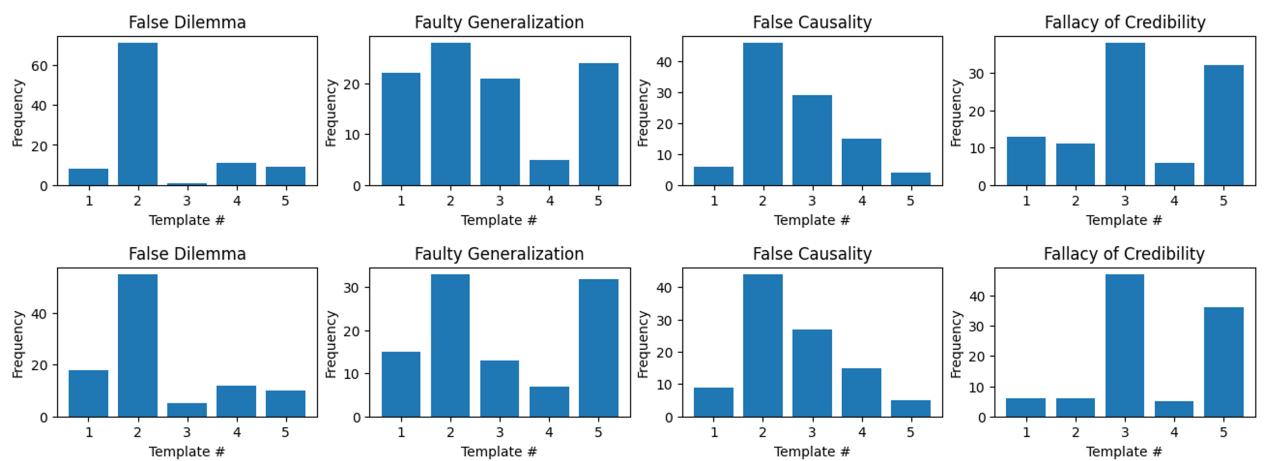
Figure 4 揭示了现实世界论证的一个有趣事实: 它们倾向于遵循特定的模式。对于“虚假两难”和“错误因果”,标注者强烈偏好模板 #2。这表明,虽然构建谬误的理论方法有很多,但人类倾向于重复使用少数几种修辞结构。
实验: AI 能“逃离缺陷”吗?
最终的测试是看当前最先进的大型语言模型 (LLM) 是否可以自动执行这种标注。
研究人员为 GPT-4、Llama-3 和 Mistral-7B 等模型设置了一个由两部分组成的任务:
- 模板选择: AI 能选出正确的逻辑图谱吗? (例如,模板 #1 vs #2) 。
- 槽位填充: AI 能识别出文本中对应于行动 (\(A\)) 、后果 (\(C\)) 和其他变量的确切词语吗?
他们使用了少样本提示 (Few-Shot Prompting) (给 AI 几个例子) ,甚至尝试了微调 (Fine-Tuning) (专门在这个数据上训练模型) 。
结果……令人感到谦卑。
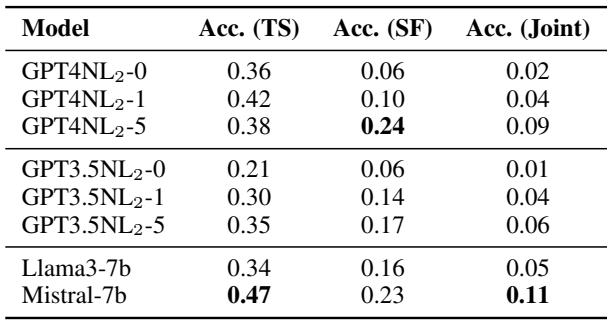
Table 4 展示了“联合准确率”——即 AI 同时正确完成模板选择和槽位填充的百分比。
- GPT-4 (5-shot): 9% 准确率。
- Mistral-7B: 11% 准确率。
- GPT-3.5: 6% 准确率。
这意味着什么? 这些低数字表明,虽然 LLM 擅长生成文本和回答一般性问题,但它们在结构化逻辑分析方面极其吃力。它们可以对一个论点进行“直觉检查”并说它很糟糕,但要求它们精确定位确切的逻辑变量 (\(A\), \(C\), \(P'\)) 会导致它们产生幻觉或误解文本。
错误分析显示模型经常:
- 选择“以上皆非”模板 (模板 #5) ,因为它们无法映射逻辑。
- 识别出了正确的模板,但在槽位中填入了错误的词语 (例如,混淆了原因与结果) 。
结论与启示
“Flee the Flaw”论文代表了计算论证领域向前迈出的重要一步。它试图将该领域从浅层检测推向深度阐释 。
关键要点:
- 逻辑是有形状的: 谬误不仅仅是抽象的错误;它们具有可以模板化的重复结构。
- 人类看得见: 有了正确的指导方针,人类可以在糟糕论点的底层逻辑上达成一致。
- 机器 (还) 做不到: 这项任务仍然是 AI 的一个“巨大挑战”。区分标准前提和谬误隐含前提所需的细微差别,目前超出了甚至像 GPT-4 这样模型的能力范围。
这为什么重要? 如果我们能解决这个问题,其应用将是强大的。想象一下,一个写作辅导工具不再只是在你的文章上打个红色的“X”,而是说: “你在这里使用了错误因果。你展示了 X 和 Y 相关,但你还没有证明 X 导致了 Y。”
或者考虑事实核查。系统不再仅仅将一条推文标记为“错误信息”,而是可以生成一份细分报告: “这篇帖子使用了虚假两难逻辑,只提出了两个可怕的选项,而忽略了来自 Z 的准确数据。”
通过迫使我们审视缺陷的结构 , 这项研究为不仅能阅读,而且能真正进行推理的 AI 铺平了道路。