](https://deep-paper.org/en/paper/2406.12606/images/cover.png)
自从 Transformer 架构凭借那篇著名的论文《Attention Is All You Need》横空出世以来,深度学习领域的理念往往倾向于“越多越好”。更多的数据、更多的层数、更多的参数。然而,当涉及到对齐 (alignment) ——即确保大型语言模型 (LLM) 有用、诚实且无害的过程时——事实证明,使用所有参数实际上可能才是问题所在。
在中国人民大学和北京航空航天大学的研究人员发表的一篇题为 “Not Everything is All You Need: Toward Low-Redundant Optimization for Large Language Model Alignment” 的精彩研究论文中,他们挑战了现状。他们提出了一个反直觉的观点: 通过识别并仅训练最相关的神经元 (而忽略其余部分) ,我们可以比更新每一个参数更好、更快、更有效地对齐模型。
在这篇文章中,我们将剖析他们的方法,即 ALLO (ALignment with Low-Redundant Optimization,低冗余优化对齐) 。我们将探讨为什么全参数微调通常会引入噪声,如何像外科手术一样精准识别“对齐神经元”,以及如何将训练分为“遗忘”和“学习”两个阶段。
问题所在: 全参数微调的噪声
为了对齐 LLM,我们通常使用基于人类反馈的强化学习 (RLHF) 或直接偏好优化 (DPO) 等方法。这些方法利用成对的“好” (正向) 和“坏” (负向) 回复对预训练模型进行微调。
标准做法是更新模型中所有可训练的参数,以最大化正向回复的可能性并最小化负向回复的可能性。但这正是问题所在: LLM 非常庞大。当你更新所有参数以与特定的偏好数据集对齐时,模型不可避免地会过拟合于该特定数据中的肤浅风格或意想不到的模式。
研究人员假设 LLM 中存在冗余 。 并非每个神经元都负责理解人类偏好。通过强制不相关的神经元进行更新,我们会引入噪声并降低性能。
冗余存在的证据
为了证明这一点,作者进行了一项实证研究。他们比较了两种模型的训练损失: 一种更新所有神经元 , 另一种仅更新前 10% 最相关的神经元 。
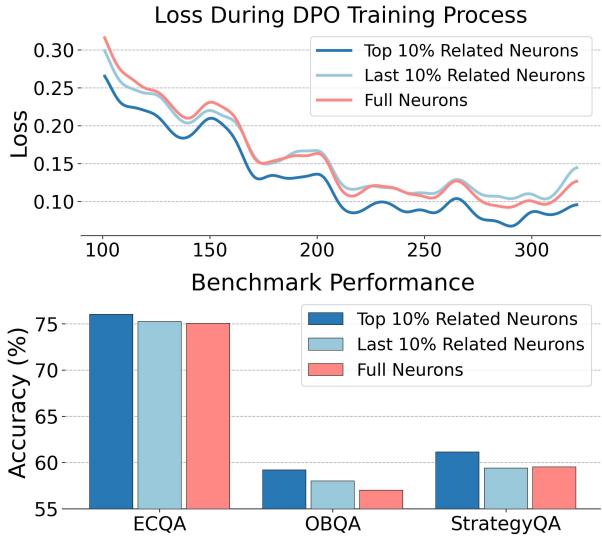
如上方的 图 1 所示,结果令人震惊。红线代表训练全部神经元时的损失。蓝线代表仅训练前 10% 相关神经元时的损失。
请注意,蓝线明显更低,表明收敛性更好。此外,柱状图显示,前 10% 的方法在 ECQA 和 QASC 等基准测试中实现了更高的准确率。这表明其他 90% 的神经元在对齐过程中本质上是累赘——甚至更糟,是破坏者。
解决方案: ALLO 框架
基于这一发现,作者提出了 ALLO 。 ALLO 的核心理念是低冗余优化 。 它不像霰弹枪那样漫无目的,而是像狙击步枪一样精准。它只关注那些重要的神经元和携带最强信号的 Token。
该框架分三个不同的步骤运行:
- 定位关键神经元: 确定大脑的哪些部分需要改变。
- 未对齐知识遗忘: 明确地去除坏习惯。
- 对齐提升: 增强良好行为并过滤噪声。
让我们看看高层架构:
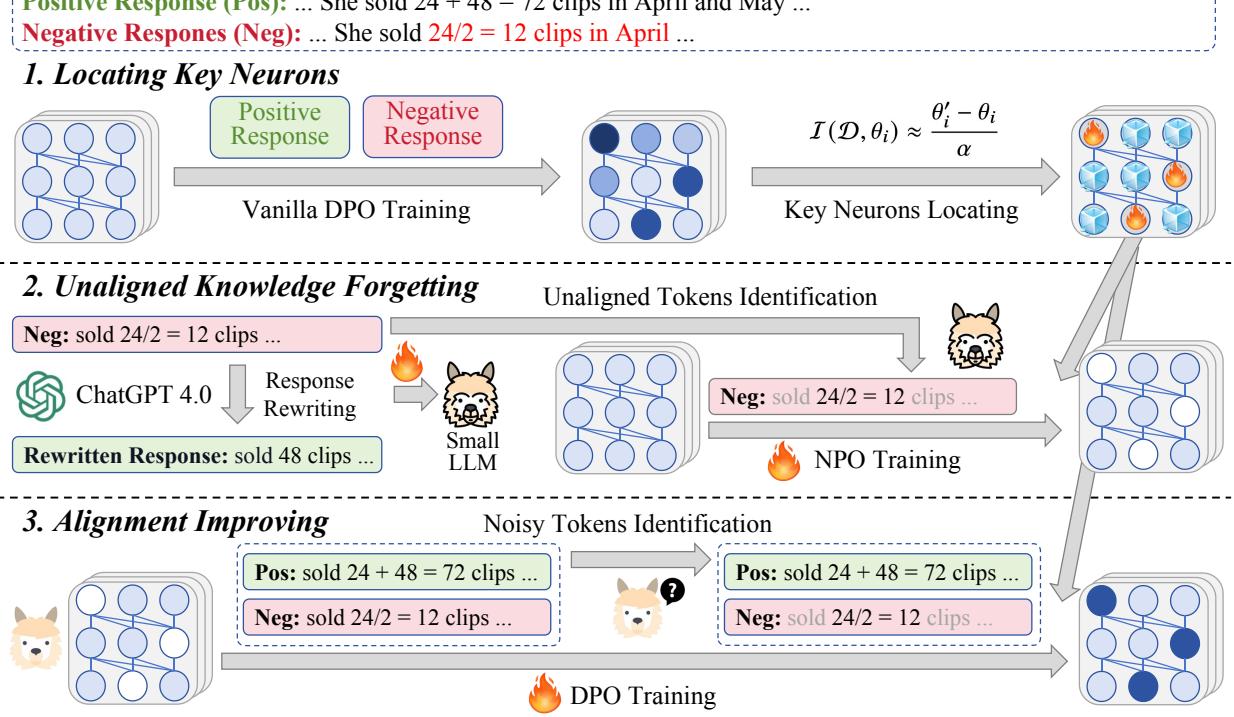
现在,让我们从数学和概念上分解每个阶段。
阶段 1: 定位关键神经元
如何知道哪个神经元对“对齐”是“重要”的?研究人员使用了一种基于梯度的策略。
首先,他们使用标准的 DPO 在人类偏好数据上训练一个“参考模型”一个 epoch。这本质上是一次演习。然后,他们观察模型的权重发生了多大变化。如果某个神经元的权重在这次演习中发生了显著变化,这意味着该神经元对对齐数据高度敏感且相关。
神经元 (\(\theta_i\)) 的重要性通过梯度的累积来估计,这可以近似为更新后的权重 (\(\theta'_i\)) 与原始权重 (\(\theta_i\)) 之间的差值,除以学习率 (\(\alpha\)):
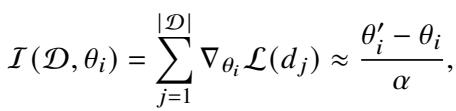
计算出重要性分数后,研究人员对其进行排序并选择前 \(k\)%。这些就是关键神经元 。 在 ALLO 流程的其余部分,优化仅应用于这些选定的神经元,而其余神经元则被冻结。
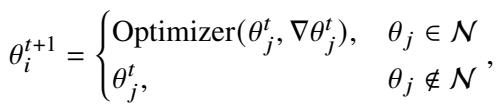
阶段 2: 未对齐知识遗忘
对齐不仅仅是学习该做什么;还要遗忘不该做什么。LLM 通常包含“未对齐知识”——预训练期间根深蒂固的偏见、幻觉或有害输出。
大多数方法试图同时学习正向内容并抑制负向内容。ALLO 将这些关注点分离开来。在这个阶段,目标纯粹是遗忘负面模式。
识别“坏”Token
并非“坏”回复中的每个词实际上都是坏的。如果模型生成了一个有毒的句子,语法可能是完美的 (我们不想遗忘语法) ,但有毒的形容词才是问题所在。
为了解决这个问题,ALLO 使用了一个Token 级奖励模型 。 他们利用教师模型 (如 GPT-4) 以最小的编辑将负面回复重写为正面回复。然后,他们训练一个小型的奖励模型来比较原始负面回复和修正后的版本。
如果负面回复中的某个 Token 导致生成修正版本的概率较低,它就会被标记为“未对齐 Token”。
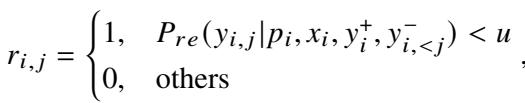
细粒度遗忘 (NPO)
识别出坏 Token 后,ALLO 应用负偏好优化 (NPO) 。 该算法专门致力于最小化生成那些特定负面 Token 的可能性。
标准的 NPO 损失函数如下所示:
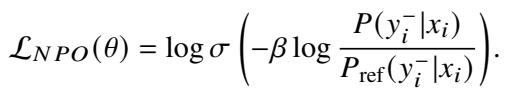
然而,ALLO 对其进行了修改以实现低冗余 。 它仅将损失应用于被识别为未对齐的特定 Token (使用奖励 \(r_{i,j}\) 作为权重) ,并仅更新在阶段 1 中识别出的关键神经元。
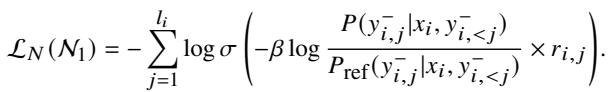
通过这种方式,模型在不损害其通用语言能力的情况下,通过“外科手术”移除了“坏”知识。
阶段 3: 对齐提升
现在模型已经“遗忘”了坏习惯,是时候强化好习惯了。为此,ALLO 使用直接偏好优化 (DPO) 。
过滤噪声 Token
正如负面回复中有中性 Token 一样,正面回复中也有“噪声”Token——这些词虽然可以接受,但对对齐信号贡献不大。如果一个 Token 具有异常高的奖励分数 (策略模型与参考模型之间的差距很大) ,它可能是导致训练不稳定的离群值或“噪声”。
ALLO 为 DPO 过程中的 Token 计算动态权重 (\(q_{i,j}\))。如果一个 Token 的奖励分数过高 (处于最高百分位) ,它将被掩盖 (权重 = 0) 。
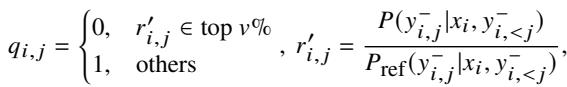
细粒度学习
最后,使用修改后的 DPO 目标函数对模型进行训练。该目标函数包含了“噪声 Token”掩码,并且至关重要的是,继续仅更新特定子集的关键神经元 (\(N_2\))。
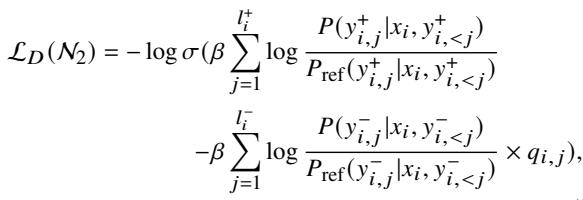
流程至此结束。模型已经清除了坏习惯并在好习惯上进行了微调,而这一切仅触及了其总参数的一小部分。
实验与结果
理论听起来很扎实,但它有效吗?研究人员在三大类任务中测试了 ALLO:
- 问答 (QA) : ECQA, QASC, OpenBookQA, StrategyQA。
- 数学推理: GSM8k, MATH 等。
- 指令遵循: AlpacaEval 2.0, Arena-Hard。
他们将 ALLO 与强大的基线进行了比较,包括标准的 SFT、DPO、PPO (ChatGPT 使用的方法) 以及最近的变体如 SimPO。
推理和数学方面的表现
在重推理的任务中,精度是关键。如下方的 表 2 所示,ALLO (最底行) 始终获得最高的平均分。
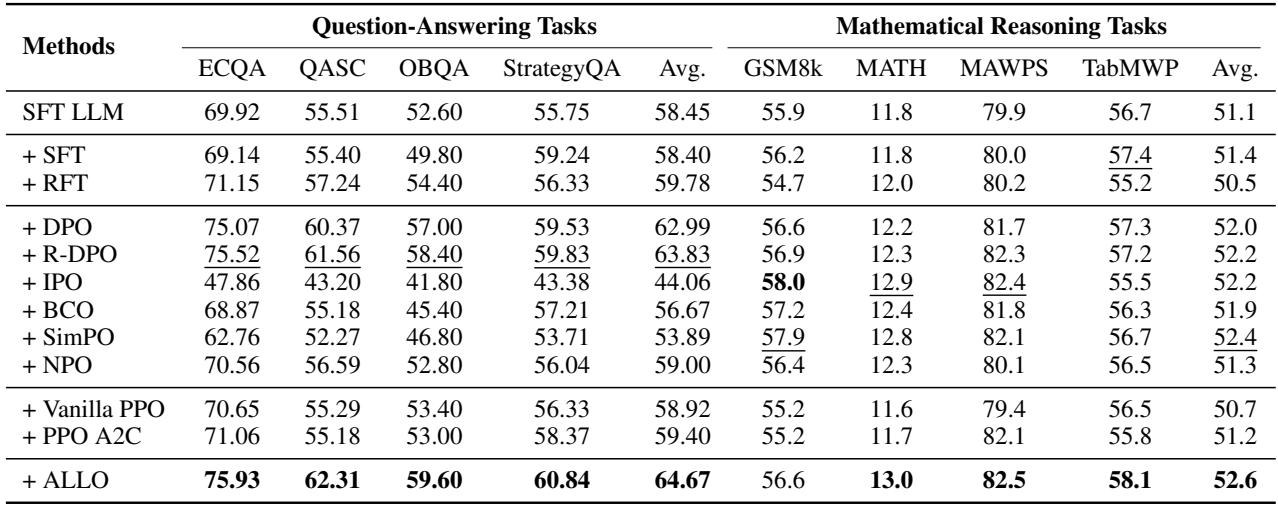
在 ECQA 数据集上,ALLO 达到了 75.93% , 击败了普通的 DPO (75.07%),并显著优于 SFT (69.14%)。在数学推理 (GSM8k, MATH) 中,ALLO 也占据了榜首。这表明,通过减少参数冗余,模型比全参数更新更好地保留了其推理逻辑,而全参数更新可能会覆盖关键的逻辑电路。
指令遵循方面的表现
指令遵循可能是对“对齐”最直接的测试。模型能成为一个有用的助手吗?
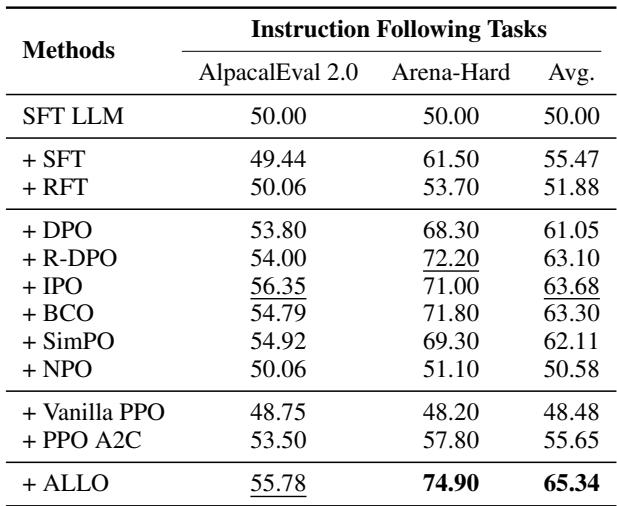
表 3 显示了 AlpacaEval 和 Arena-Hard 的胜率。ALLO 在 Arena-Hard 上达到了惊人的 74.90% , 显著优于 DPO (68.30%) 和 SimPO (69.30%)。平均提升幅度巨大,表明“先遗忘再学习”的策略结合神经元剪枝,能产生更有帮助的助手。
分析: 我们需要剪枝多少?
ALLO 中最关键的超参数之一是神经元掩码比例——我们实际上应该训练百分之多少的神经元?
作者改变了这个比例以寻找“最佳平衡点 (Sweet spot) ”。
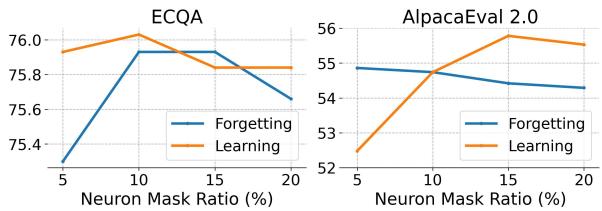
图 4 揭示了一个有趣的趋势 (倒 U 形) :
- 神经元太少 (5%): 模型缺乏适应新对齐数据的能力。
- 神经元太多 (20%+): 性能开始再次下降。
峰值性能位于 10% 到 15% 左右。这验证了论文的核心前提: 增加更多可训练参数超过某一点后收益递减,并最终因噪声和干扰而损害性能。
结论
“Not Everything is All You Need” 这篇论文为海量 LLM 时代的克制做法提供了令人信服的论据。它强调对齐是一个外科手术般的过程,而不是蛮力的改造。
通过识别负责任务对齐的特定神经元并隔离代表未对齐行为的特定 Token,ALLO 以更高的效率实现了最先进的结果。
主要结论:
- 冗余是真实存在的: 对于特定的对齐任务,90% 的神经元可能不需要更新。
- 先遗忘再学习: 明确地遗忘负面行为 (通过 NPO) 为更好的对齐扫清了障碍。
- 过滤噪声: 并非数据集中的所有数据点都是有用的;动态过滤 Token 可以防止过拟合。
随着模型规模持续增长,像 ALLO 这样专注于效率和低冗余的方法,很可能成为将原始计算能力转化为有用的、与人类对齐的智能的标准。