](https://deep-paper.org/en/paper/2406.12608/images/cover.png)
超越节点与边: GraphBridge 如何在图学习中统一文本与结构
在机器学习不断发展的格局中,我们经常发现自己将数据分类为不同的类型。我们有用于文本的自然语言处理 (NLP) 和用于网络化结构的图神经网络 (GNN) 。但现实世界很少如此泾渭分明。实际上,数据往往是这两者杂乱而美妙的结合。
以社交网络为例。你有用户 (节点) 和友谊 (边) 。但你也拥有这些用户生成的内容——他们的个人简介、帖子和自我介绍。要真正了解一个用户,你不能只看他们认识谁 (结构) ,也不能孤立地只看他们写了什么 (文本) 。你需要理解他们的文本与他们交往对象的文本是如何关联的。
这种特定的数据类型被称为文本属性图 (Text-Attributed Graph, TAG) 。 虽然我们有处理文本的方法和处理图的方法,但在文本的详细语义与图结构的宏观语境之间架起桥梁,一直是一个持久的挑战。
在这篇文章中,我们将深入探讨一篇引人入胜的论文,题为 “Bridging Local Details and Global Context in Text-Attributed Graphs” (在文本属性图中连接局部细节与全局语境) 。 研究人员推出了 GraphBridge , 这是一个旨在无缝融合这两个世界的框架。也许最令人印象深刻的是,他们解决了混合图与重文本数据通常带来的巨大计算难题: 可扩展性。
问题所在: 割裂的视角
要理解为什么需要 GraphBridge,我们首先需要看看目前我们是如何处理文本属性图的。
在标准的 TAG 中,每个节点都带有一组丰富的文本。如果你要在引文图中对研究论文进行分类,节点就是论文,文本就是摘要。
传统上,研究人员将其视为一个两步流水线:
- 局部编码 (Local-Level Encoding) : 我们获取节点的文本,并通过语言模型 (如 BERT) 将其转换为向量 (一串数字) 。这捕获了文本的语义含义。
- 全局聚合 (Global-Level Aggregating) : 我们获取这些向量并将它们输入图神经网络 (如 GCN) 。GNN 将节点的向量与其邻居的向量混合。这捕获了结构关系。
虽然这种方法行之有效,但它遗漏了一些至关重要的东西: 互联性 (Interconnection) 。
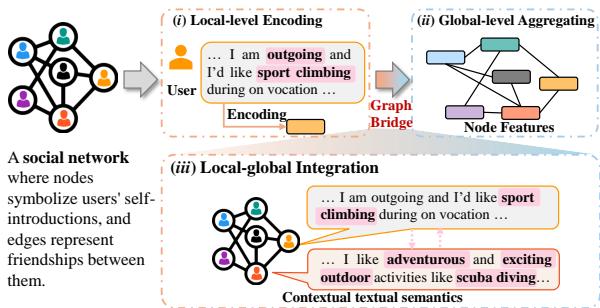
如上方的 图 1 所示,现有方法 (步骤 i 和 ii) 将文本编码和图结构视为两个分离的阶段。步骤 iii 展示了缺失的部分: 上下文文本信息 。
想象你在一个聚会上。如果你介绍自己说“我喜欢攀岩”,那是你的局部文本。如果你站在一群人中间,那是你的全局结构。现有的方法本质上是记录了你的“我喜欢攀岩”声明,然后注意到你站在 Bob 和 Alice 旁边。
但是,如果 Bob 的简介写着“我是一名外向的教练”,而 Alice 的简介写着“我组织户外探险活动”呢?你的“攀岩”与他们的“户外探险”之间的语义关系,是理解你们可能属于特定爱好者群体的关键。GraphBridge 旨在捕捉这种特定的细微差别——即相连节点之间的文本对文本关系。
挑战: 可扩展性瓶颈
这个问题的直观解决方案似乎很简单: 为什么不直接获取一个节点的文本,附加其所有邻居的文本,然后将那一大段话输入到一个强大的语言模型 (LLM) 中呢?
答案是计算成本 。
语言模型对它们能处理的文本量 (上下文长度) 有限制。如果一个节点有 50 个邻居,每个邻居有 200 个单词的简介,你突然间就需要为单一预测处理超过 10,000 个 Token。这会导致:
- 显存爆炸: 你的 GPU 显存会立即耗尽。
- 噪声: 邻居文本中的并非每个词都是相关的。
- 稀释: 目标节点自身的信息可能会被邻居的信息淹没。
这正是 GraphBridge 引入其核心创新的地方: 一种在保持图上下文的同时智能压缩文本的机制。
解决方案: GraphBridge
GraphBridge 框架基于“多粒度融合”的理念运作。它通过确保语言模型实际上能“看到”邻居的文本,来连接局部 (文本) 和全局 (图) 视角。
为了使这在计算上可行,作者设计了一个 图感知 Token 缩减 (Graph-Aware Token Reduction) 模块。
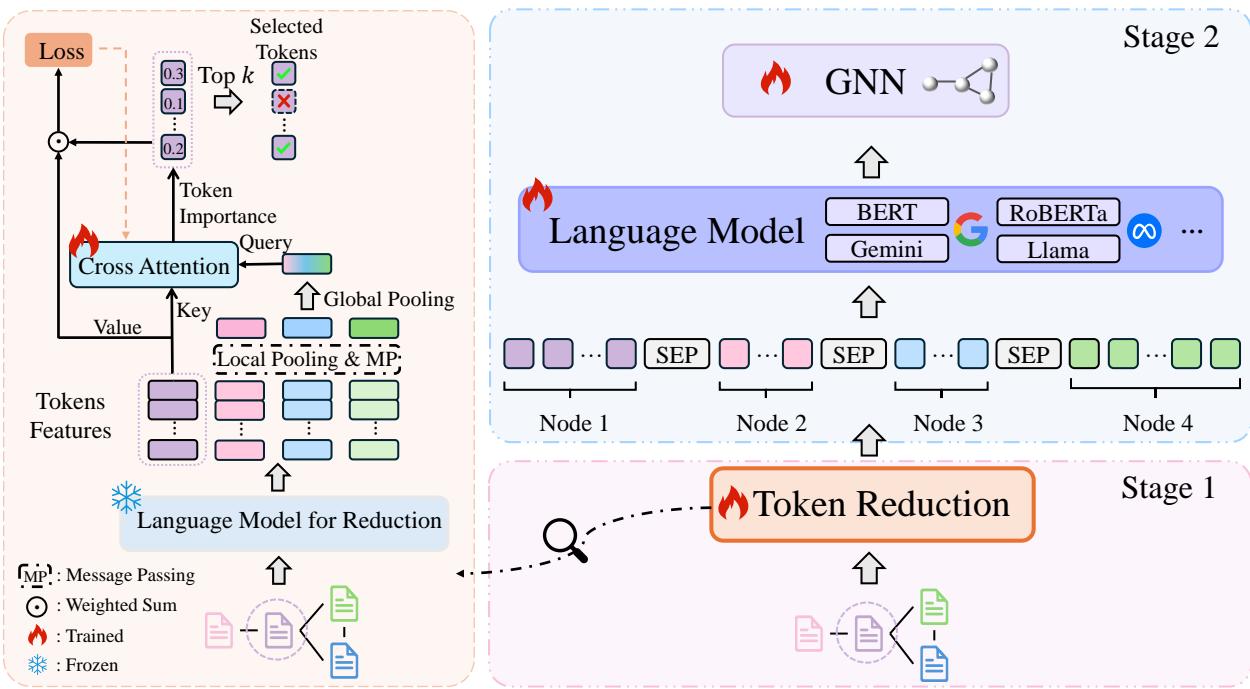
如 图 2 所示,该过程分为两个不同的阶段。让我们逐一分解。
第一阶段: 图感知 Token 缩减
这里的目标简单但困难: 保留重要的词,丢弃无关的词。 但“什么重要”取决于图结构。邻居文本中的一个词,只有在它有助于分类当前节点时才重要。
作者设计了一种可学习的注意力机制,根据语义含义和图结构为每个 Token (词/子词) 打分。
A 步: 获取表示
首先,他们使用一个预训练语言模型 (冻结状态,所以速度快) 来获取节点中每个 Token 的嵌入。他们对这些嵌入取平均值,得到节点的摘要向量,记为 \(z_i\)。
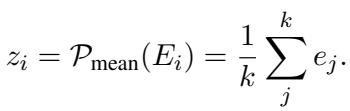
接下来,他们执行一个消息传递 (Message Passing) 步骤 (类似于 GCN 的工作方式) 。他们对节点邻居的摘要向量取平均值。这创建了一个代表邻域上下文的“查询 (Query) ”向量。
B 步: 交叉注意力分数
这是巧妙的部分。为了决定节点 \(i\) 中的哪些 Token 是重要的,模型会问: 这个特定的 Token 与邻域上下文的匹配程度如何?
他们使用交叉注意力机制计算重要性分数:
- 查询 (\(Q\)): 聚合的邻域特征 (上下文是什么?)
- 键 (\(K\)): 单个 Token 的嵌入 (内容是什么?)
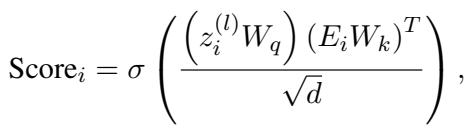
这个公式为每个 Token 输出一个概率分数。如果一个 Token 分数很高,意味着它与周围的图结构高度相关。
C 步: 优化与正则化
模型根据这些分数选择前 \(k\) 个 Token。但是我们如何训练这个选择器呢?我们要强迫它仅使用这些 Token 的加权和来解决下游分类任务。
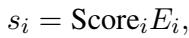
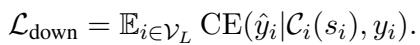
然而,研究人员在测试中发现了一个问题。如果没有制衡机制,模型会“过拟合”到特定的词上,给某一个 Token 打 0.99 的分,而忽略其余部分。这产生了一种“隧道视野”效应,即模型依赖单一关键词而不是理解句子。
为了解决这个问题,他们添加了一个使用 KL 散度的正则化项。这强迫重要性分数在一定程度上分布开来,防止模型将赌注全压在一个 Token 上。
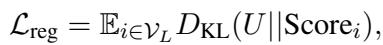
这种正则化的影响非常明显。请看下图:
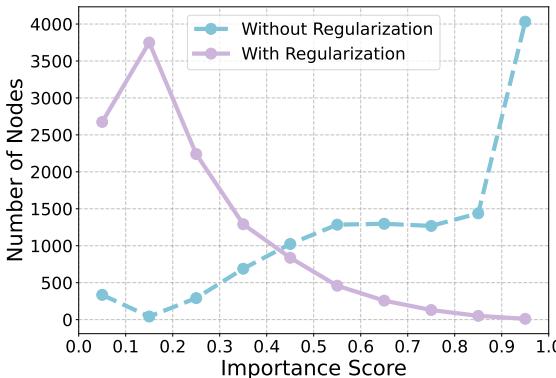
在 图 3 中,紫线 (有正则化) 显示最高分分布合理。蓝线 (无正则化) 显示对于几乎所有节点,模型都将单一 Token 的置信度推到了 1.0 (最右侧) ,忽略了其他所有内容。
最终的训练损失结合了任务准确率和这个正则化项:
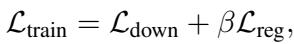
第二阶段: 多粒度融合
一旦 Token 缩减模块训练完成,我们可以显著压缩文本数据。一篇长摘要可能被压缩成仅剩 10-20 个最关键的关键词。
现在,我们终于可以做开始想做的事情了: 拼接 (Concatenate) 。
对于目标节点 \(i\),GraphBridge 构建了一个新序列 \(Q_i\)。该序列包含:
- 节点自身的缩减 Token。
- 一个分隔符 Token
[SEP]。 - 其邻居的缩减 Token (通过随机游走采样) 。
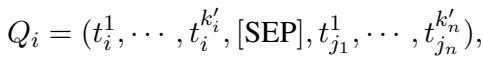
因为 Token 被缩减了,这个序列可以舒适地放入标准语言模型 (如 RoBERTa 甚至 LLaMA) 的上下文窗口中。
然后,语言模型在这个图增强的序列上进行微调:
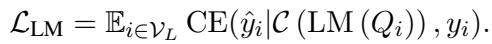
最后,由该 LM 生成的嵌入被传入一个标准的 GNN 进行最终分类。这种级联结构使得 GNN 能够受益于上游发生的丰富、具有上下文感知的文本处理。
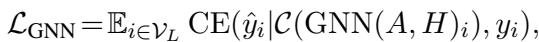
实验分析
这种复杂的桥接真的有效吗?作者在七个标准数据集上将 GraphBridge 与一系列基准模型进行了对比测试。
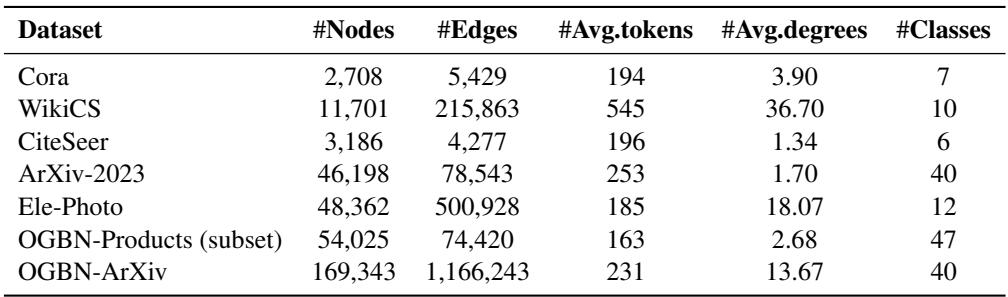
数据集
数据集范围从引文网络 (Cora, ArXiv) 到产品图 (OGBN-Products) 。
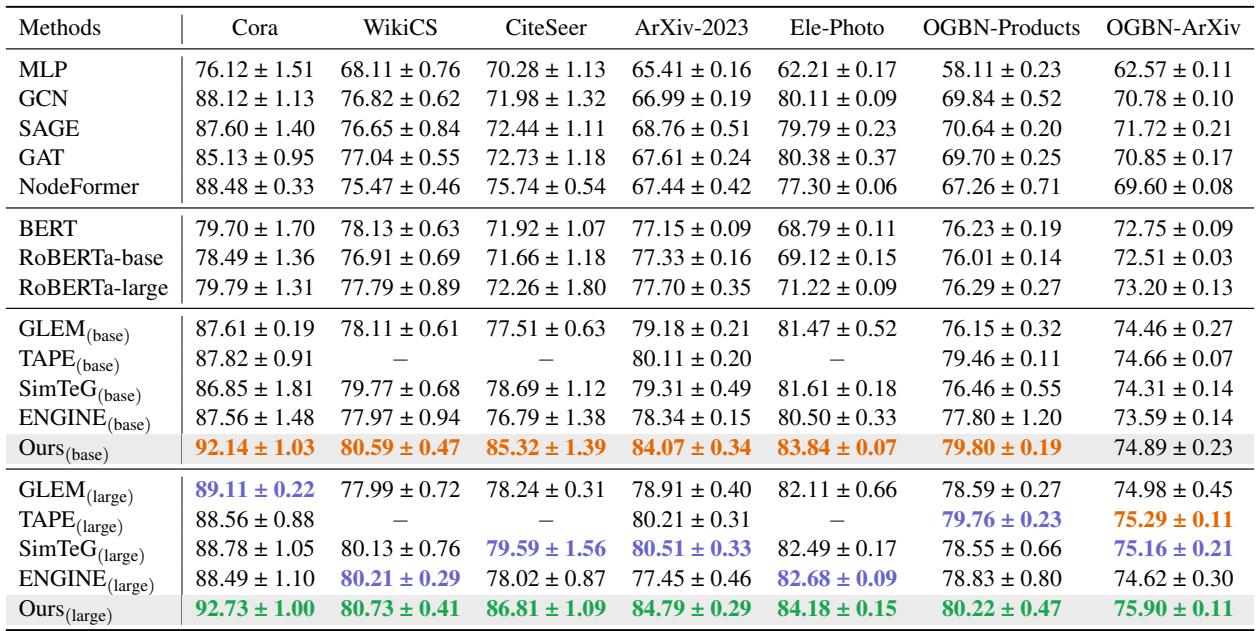
性能对比
结果如 表 2 所示,非常具有启示性。
数据告诉我们:
- GNN vs. LM: 传统的 GNN (GCN, SAGE) 与使用语言模型的方法 (GLEM, SimTeG) 相比通常表现挣扎,因为它们忽略了丰富的文本语义。
- GraphBridge 的优势: GraphBridge (Ours) 持续优于之前的最先进方法。例如,在 CiteSeer 上,GraphBridge (base) 达到了 85.32% 的准确率,显著领先于 SimTeG 的 78.69%。这表明“阅读”邻居的文本比仅仅聚合向量能让模型更准确地对节点进行分类。
LLM 集成
该框架与具体模型无关。作者将 RoBERTa 换成了 LLaMA2-7B , 一个更大的生成式 LLM。
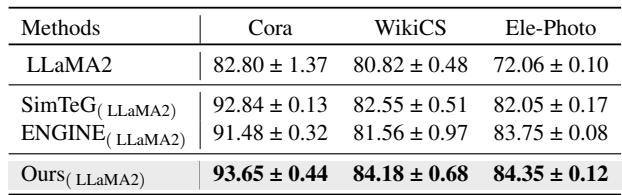
如 表 3 所示,搭载 LLaMA2 的 GraphBridge 在各项指标上均取得了最高分。这证明了该方法能够随着底层语言模型能力的提升而良好扩展。
可扩展性: 真正的赢家
这篇论文最实际的贡献可能在于效率。在图邻域上训练 LM 通常会导致显存溢出 (OOM) 错误。
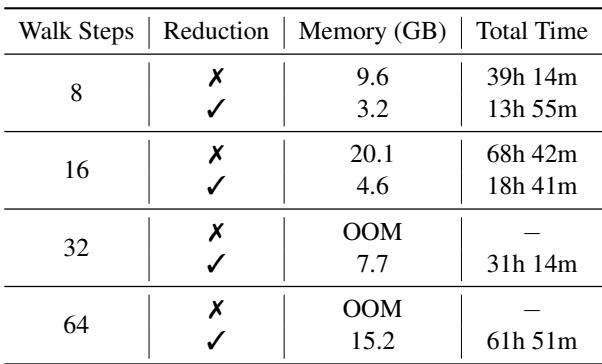
表 4 展示了鲜明的对比。
- 无缩减: 在 32 步游走 (邻居) 下,模型发生 OOM 。 即使在 16 步时,也需要 68 小时 和 20GB 的显存。
- 有缩减: 模型可以轻松处理 32 步,仅耗时 31 小时 并占用 7.7GB 显存。
这种缩减允许模型在不导致硬件崩溃的情况下“看”得更远 (更多邻居) 。
消融研究
我们怎么知道“智能”Token 缩减比随机选择或 TF-IDF 更好呢?
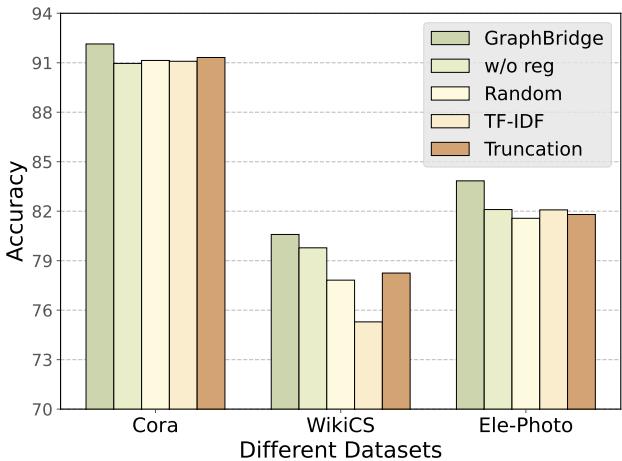
图 6 将 GraphBridge 的缩减方法 (最左侧柱状图) 与随机 (Random) 、TF-IDF 和简单截断 (Truncation) 进行了比较。GraphBridge 始终获胜。它还显示“w/o reg” (无正则化) 版本的表现较差,证实了 KL 散度损失对于稳定学习的必要性。
结论
GraphBridge 代表了图表示学习向前迈出的重要一步。通过承认图中的文本并非孤立存在,它有效地弥合了节点与其邻居之间的语义鸿沟。
它的双管齐下方法——首先通过 图感知 Token 缩减 智能地减少噪声,然后通过 多粒度融合 综合这些信息——为如何处理我们在现实世界中看到的日益复杂的数据提供了一个蓝图。
对于学生和从业者来说,关键要点是:
- 上下文为王: 在 TAG 中,邻居的文本与链接本身一样重要。
- 少即是多: 你不需要每个词。如果你能智能地选择与图结构对齐的 Token,你可以在提升性能的同时大幅削减计算成本。
- 正则化很重要: 在设计注意力机制时,始终确保你的模型不会将焦点坍缩到单一特征上。
随着我们迈向图基础模型 (Graph Foundation Models) ,像 GraphBridge 这样高效处理海量文本属性的技术,很可能成为处理网络互联数据的标准配置。