](https://deep-paper.org/en/paper/2406.12708/images/cover.png)
引言: 学术出版的黑箱
如果你是一名学生或研究人员,你很可能体会过点击会议论文“提交”按钮后的那种焦虑。在接下来的几个月里,你的工作进入了一个“黑箱”。在这个黑箱里,匿名的审稿人会评判你的方法,争论你的发现,并最终决定你研究的命运。
同行评审是科学诚信的基石,但它也因各种挑战而臭名昭著。它受高方差 (遇到什么样的审稿人全凭“运气”) 、对新手作者的潜在偏见以及审稿人本身不透明动机的困扰。我们知道这些问题存在,但要科学地研究它们却极其困难。出于隐私考虑,我们无法查看谁评审了什么,而从审稿人的心情到领域主席 (Area Chair) 的领导风格等海量变量,使得几乎不可能分离出导致拒稿的具体原因。
如果我们能模拟整个过程会怎样?如果我们能利用 AI 创建成千上万个“合成”同行评审,通过调整变量来确切地观察一个“懒惰”的审稿人或一位“有偏见”的领域主席如何改变结果,那会怎样?
这正是 AGENTREVIEW 的作者们所做的事情。利用大型语言模型 (LLM) ,他们构建了一个全面的框架来模拟同行评审的动态。他们的工作为科学社会学提供了一个迷人的、定量的视角,揭示了从众心理、疲劳和权威偏见如何极大地扭曲学术出版的结果。
背景: 为什么要模拟同行评审?
传统的同行评审研究依赖于事后分析。研究人员会在会议结束后查看数据以寻找规律。虽然有用,但这种方法有其局限性。你无法重新举办一次会议来看看如果“二号审稿人”不那么暴躁,论文是否会被接收。你无法轻易地将论文质量与审稿人的偏见区分开来。
AGENTREVIEW 框架提出了一种不同的方法: 基于智能体的建模 (Agent-Based Modeling, ABM) 。 在这种设置中,LLM (具体来说是 GPT-4) 扮演评审过程中的参与者。由于 LLM 已经展示了理解学术文本和模拟特定人设的惊人能力,它们可以被“分配”不同的角色。
这种模拟允许进行受控实验。研究人员可以选取过去会议 (如 ICLR) 的一篇真实论文输入系统,但改变 AI 审稿人的“个性”。这以一种现实世界中不可能的方式隔离了变量,在保护隐私的同时生成了具有统计意义的数据。
核心方法: AGENTREVIEW 机器内部
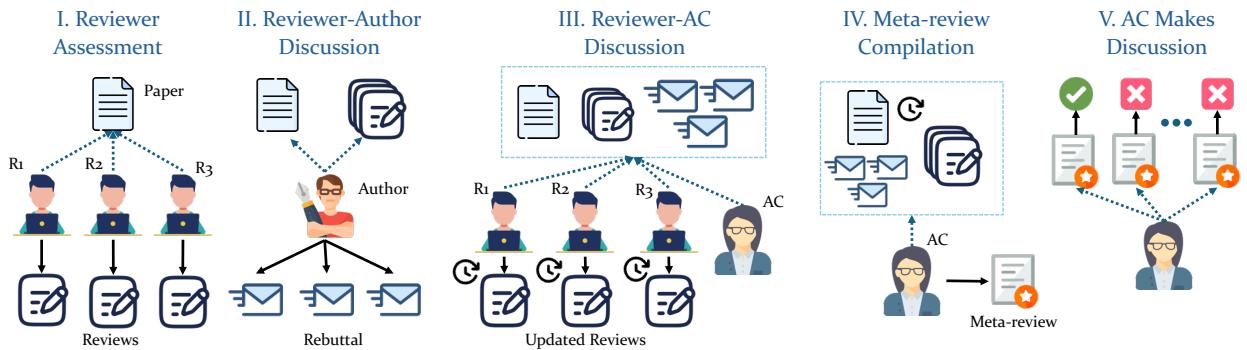
AGENTREVIEW 框架旨在通过镜像顶级机器学习和 NLP 会议的标准流程来运作。它不仅仅是生成摘要;它模拟了定义真实评审周期的社会互动和阶段。
5 阶段流程
如下图所示,该框架经历了五个不同的阶段:
- 审稿人评估 (Reviewer Assessment) : 三位 AI 审稿人独立阅读论文并撰写带有分数的初步评审意见。
- 作者-审稿人讨论 (Author-Reviewer Discussion) : “作者”智能体阅读评审意见并撰写反驳信 (Rebuttal) 以捍卫自己的工作。
- 审稿人-领域主席讨论 (Reviewer-AC Discussion) : 领域主席 (AC) 发起讨论。审稿人阅读反驳信和彼此的评论,并可能更新他们的分数。
- Meta-Review 汇总 (Meta-Review Compilation) : AC 将所有内容综合成一篇 Meta-Review (综合评审) 。
- 论文决策 (Paper Decision) : AC 做出最终的接收/拒绝决定。
角色阵容
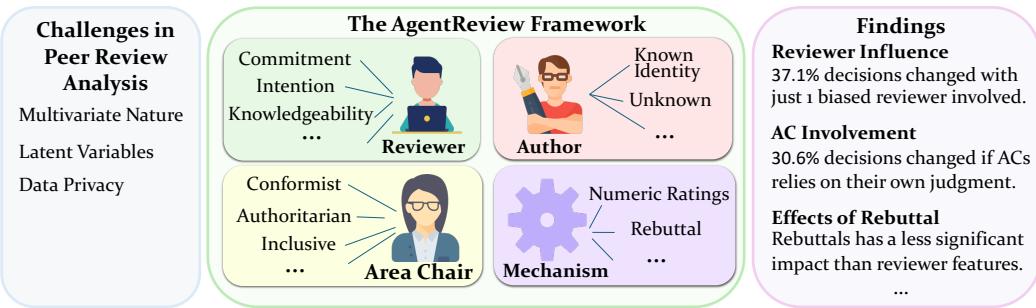
这个框架的真正力量在于如何定义这些智能体。研究人员不只是要求 ChatGPT“评审一篇论文”。他们为智能体分配了特定的特征来研究社会学现象。
1. 审稿人 (The Reviewers)
研究人员确定了决定审稿人输出质量的三个关键维度:
- 投入度 (Commitment) : 审稿人是 负责任的 (Responsible) (详尽、建设性) 还是 不负责任的 (Irresponsible) (草率、肤浅) ?
- 意图 (Intention) : 审稿人是 善意的 (Benign) (想要帮助改进论文) 还是 恶意的 (Malicious) (有偏见、严厉、旨在拒稿) ?
- 知识水平 (Knowledgeability) : 审稿人是该领域的专家 (Knowledgeable) 还是由外行指导内行 (Unknowledgeable) ?
2. 领域主席 (The Area Chairs, ACs)
AC 负责管理整个流程。该研究模拟了三种领导风格:
- 独裁型 (Authoritarian) : 根据自己的意见做决定,无视审稿人。
- 从众型 (Conformist) : 简单地平均审稿人的意见,没有独立的思考。
- 包容型 (Inclusive) : 将审稿人的反馈与自己的判断相平衡 (理想情况) 。
3. 作者 (The Authors)
模拟甚至考虑了作者的匿名性。在某些实验中,“作者”是匿名的 (双盲) ;在另一些实验中,他们的身份——以及声誉——被透露给了审稿人。
通过混合搭配这些智能体,研究人员基于 ICLR 2020-2023 年的论文生成了超过 53,800 份同行评审文档 。 这个庞大的数据集使他们能够测试特定的社会学理论。
实验与结果: 揭示系统中的缺陷
模拟的结果令人震惊。LLM 智能体表现出了复杂的社会行为,这些行为反映了现实学术界中观察到的问题。让我们分解一下主要发现。
1. 社会影响与从众心理
最一致的发现之一是“羊群效应”。在模拟中,审稿人在第 3 阶段 (审稿人-AC 讨论) 可以看到彼此的评论。
数据显示,讨论阶段后 评分的标准差下降了 27.2% 。 这意味着审稿人停止了分歧,并趋向于达成共识。虽然共识可能是好的,但这同时也表明,持异议的声音 (可能是正确的) 往往会屈服于多数人的观点或房间里最强势的声音。
2. “懒惰审稿人”传染 (利他主义疲劳)
同行评审是无偿工作,通常会导致“利他主义疲劳”。该研究测试了当在混合中引入 不负责任 (Irresponsible) 的审稿人——被提示投入度较低且草率的智能体——时会发生什么。
结果是典型的“一颗老鼠屎坏了一锅粥”。
- 当只有 一名 审稿人不负责任时,所有 审稿人的整体投入度都下降了。
- 在有不负责任成员的小组中,讨论后的平均评审字数下降了 18.7% 。
- 如下方左图所示,随着不负责任审稿人数量的增加 (x 轴) ,平均评分下降,且初始评分与最终评分之间的差距缩小。
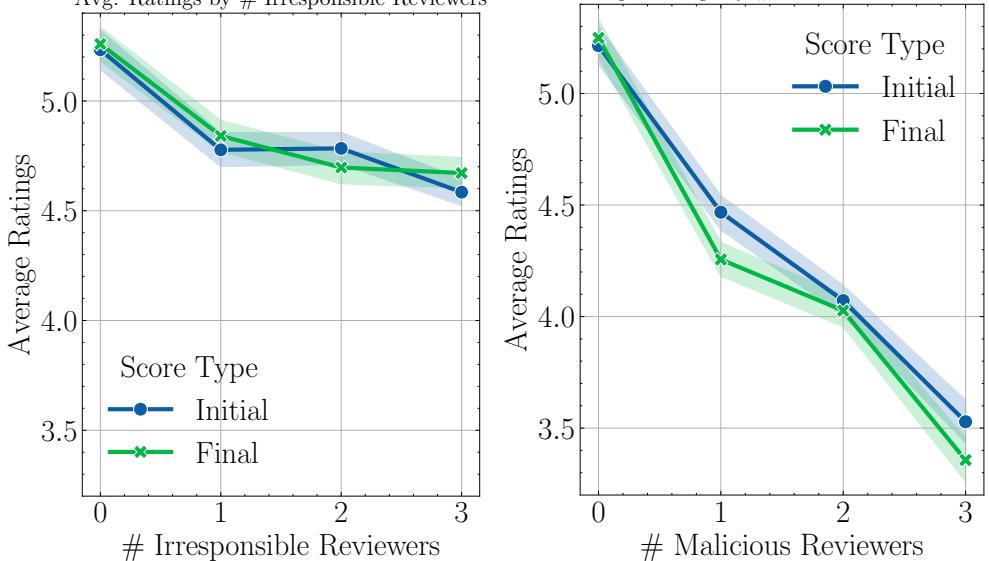
3. 回声室与恶意行为
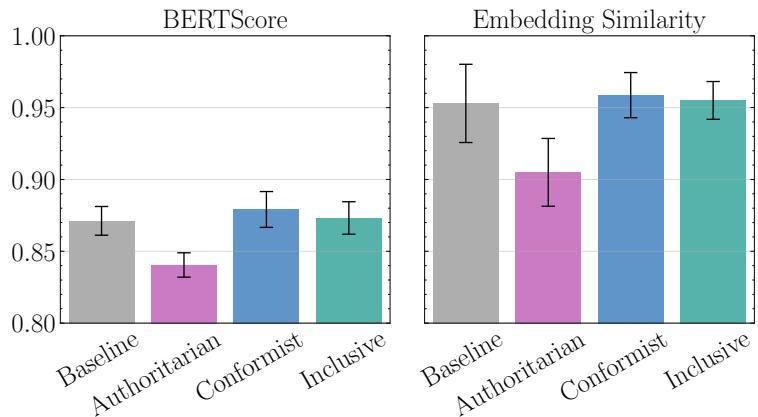
研究人员还模拟了 恶意 (Malicious) 审稿人——被提示带有偏见和严厉态度的智能体。
- 溢出效应 (Spillover Effect) : 恶意审稿人的存在不仅降低了他们自己的分数;它还拉低了小组中 正常 审稿人的分数。正常审稿人在与有偏见的同伴互动后,将评分降低了 0.25 分 。
- 回声室 (Echo Chambers) : 恶意审稿人放大了彼此的消极情绪。如上方右图所示,增加更多的恶意审稿人会导致论文得分急剧跳水。
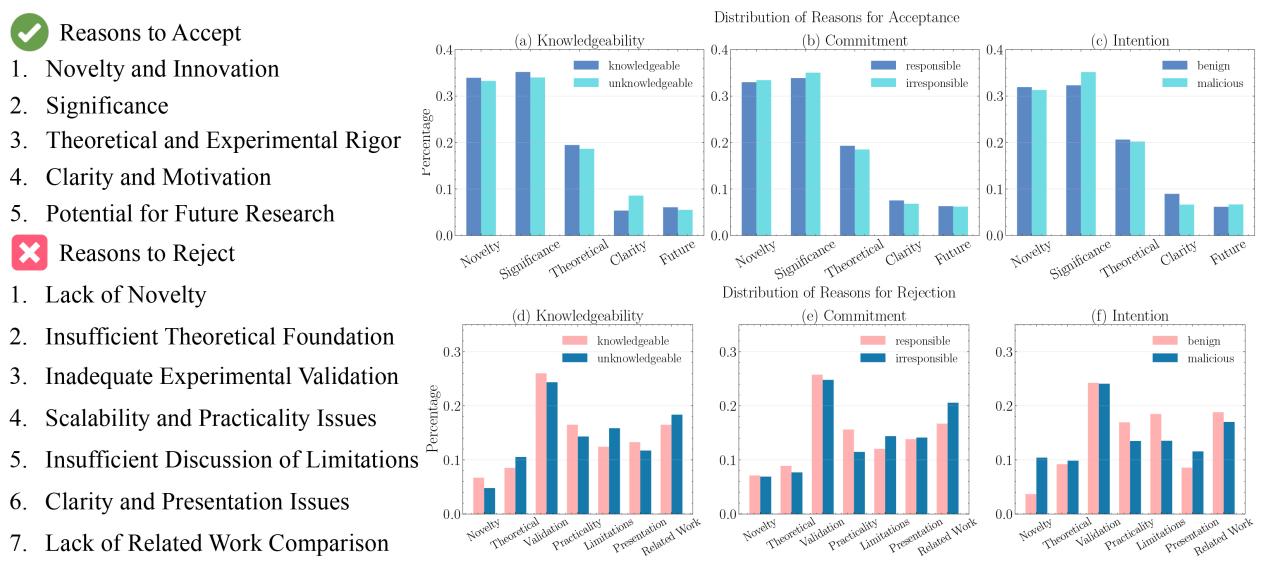
下方的内容分析揭示了他们 如何 拒绝论文。恶意审稿人 (图 c 中的粉色条) 绝大多数引用“缺乏新意 (Lack of Novelty) ”——这是一个模糊、懒惰的批评——而知识渊博的审稿人则关注“实验验证 (Experimental Validation) ” (图 d) 。
4. 权威偏见 (“光环效应”)
对于学生和早期职业研究人员来说,最令人担忧的发现可能是 权威偏见 的影响。
研究人员模拟了一种双盲流程被打破的场景 (例如通过预印本) ,审稿人知道作者是“著名的、享有声望的研究人员”。
- 结果: 当审稿人知道作者很有名时,论文的决定改变了 27.7% 。
- 即使是 质量较低的论文 , 知道作者很有名也极大地增加了被接收的机会。
- 如下图所示,随着知道作者声望的审稿人数量 (0 到 3) 增加,平均评分 (y 轴) 稳步攀升。
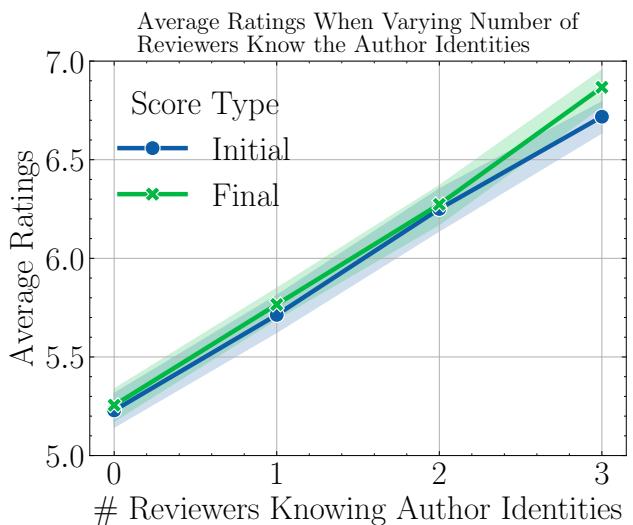
这定量地证实了“光环效应”: 如果你很有名,无论实际内容如何,你的工作都会被认为更准确、更重要。
5. 领域主席的权力
最后,研究考察了究竟是谁在做决定。他们将不同类型领域主席的最终决定与“基线 (Baseline) ” (中立/标准) 设置进行了比较。
- 包容型 AC (听取所有人意见) 与基线的一致性最高。
- 独裁型 AC (独自决定) 经常独断专行,基于个人偏见拒绝高质量论文或接收低质量论文。
- 从众型 AC 与审稿人分数的相似度很高 (如下图所示) ,但有放大审稿人偏见 (如前面提到的恶意审稿人) 的风险。
智能体的输出看起来像什么?
你可能会好奇: LLM 听起来真的像审稿人吗?定性分析表明是的。智能体产生了详尽的反馈,包括对方法论和新颖性的具体批评。
下面是一个生成的评审意见示例 (表 7) 以及随后的反驳信 (表 8) 。文本密集,针对论文主题 (“上下文聚类”、“点云输入”) 非常具体,并模仿了学术话语的专业 (有时是学究气) 的语气。


结论与启示
AGENTREVIEW 框架通过人工智能模拟,对科学中的“人为”因素进行了发人深省的审视。该研究成功解耦了同行评审中复杂的变量网络,为我们通常仅凭轶事怀疑的现象提供了确凿的数据。
主要结论:
- 审稿人容易受影响: 从众心理减少了方差,但也抑制了独特的观点。
- 懒惰是会传染的: 一个不投入的审稿人会降低整个讨论的质量。
- 匿名至关重要: “光环效应”是真实且强大的;取消匿名性会显著提升著名作者的优势,这可能以牺牲论文质量为代价。
- AC 很重要: 领域主席的领导风格可以完全扭转决定。
这项研究并不建议我们用 AI 取代人类。相反,它为设计更好的系统提供了一个“沙盒”。通过了解流程对特定变量 (如作者姓名的可见性或讨论的结构) 的敏感程度,会议组织者可以设计出减轻偏见并鼓励公平的机制。
对于有抱负的研究人员来说,这是一个验证: 虽然同行评审过程并不完美,有时甚至不公平,但了解这些动态是驾驭——并最终改进——该系统的第一步。