](https://deep-paper.org/en/paper/2406.13439/images/cover.png)
AI 法官的崛起
在人工智能飞速发展的格局中,我们面临着一个瓶颈: 评估。随着大型语言模型 (LLM) 的能力越来越强,评估它们的输出对人类来说已经变得极其昂贵且耗时。如果你正在开发一个新模型,你不可能为了给成千上万个回答打分而等待人工标注者数周时间。
业界的解决方案是采用“LLM 即法官” (LLM-as-a-Judge) 模式。我们现在依赖强大的模型 (如 GPT-4) 来给更小或更新的模型“批改作业”。这些“评估器 LLM”决定了排行榜上的名次,并影响着哪些模型能被部署。但这种依赖建立在一个巨大的假设之上: 即评估器 LLM 真的知道好 (或坏) 的回答长什么样。
如果法官对特定类型的错误视而不见怎么办?如果一个评估器给一个事实错误或数学逻辑不通的回答打了满分怎么办?
在论文《Finding Blind Spots in Evaluator LLMs with Interpretable Checklists》中,来自 AI4Bharat 和印度理工学院马德拉斯分校的研究人员提出了一个名为 FBI 的新颖框架。不,这不是联邦调查局——它代表 Finding Blind spots with Interpretable checklists (使用可解释清单查找盲点) 。他们的工作为 AI 法官创建了一个严格的压力测试,揭示了即使是我们最先进的模型,也经常无法察觉回答中存在的根本性缺陷。
当前评估存在的问题
在深入了解 FBI 框架之前,我们必须了解现状。目前,当研究人员想知道他们的模型是否优秀时,通常使用与人类判断相关联的指标。如果 GPT-4 给一个回答打了高分,而人类也给了高分,我们就假设 GPT-4 是一个可靠的裁判。
然而,仅有相关性是不够的。随着 LLM 被赋予复杂的任务——编写代码、进行数学推理或遵循多步骤指令——我们需要“细粒度”的评估。如果模型未能遵循否定约束 (例如,“不要使用‘快乐’这个词”) ,一个通用的“9/10”分是毫无用处的。
研究人员认为,我们需要像软件测试一样对待 LLM 评估。在软件工程中,我们使用“单元测试”来破坏代码,看它是否会出错。FBI 框架将这一逻辑应用于评估器 LLM。
FBI 框架: 对法官进行压力测试
FBI 框架背后的核心直觉简单而强大: 如果我拿一个完美的回答,并以特定方式故意破坏它,评估器 LLM 应该降低分数。 如果分数保持不变,评估器就存在“盲点”。
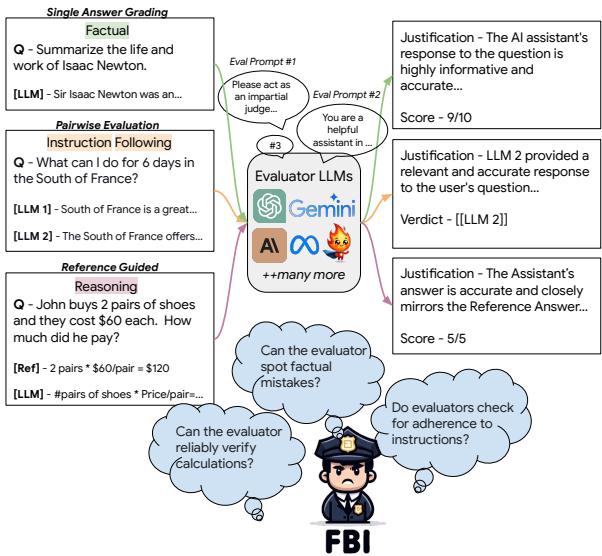
如上图 1 所示,该框架通过向评估器 LLM 展示问题和回答来运作。系统利用不同的提示策略 (如提供评分标准或要求推理过程) 来观察评估器是否能检测到质量下降。
为了使其系统化,研究人员重点关注了任何稳健 LLM 都应具备的四种关键能力:
- 事实准确性 (Factual Accuracy) : 回答是否包含真实信息?
- 指令遵循 (Instruction Following) : 模型是否遵循了所有约束?
- 长文写作 (Long-Form Writing) : 文本是否连贯、合乎语法且一致?
- 推理能力 (Reasoning Proficiency) : 数学和逻辑是否正确?
构建数据集: 扰动的艺术
为了测试这些能力,研究人员不仅仅是收集糟糕的回答;他们制造了这些回答。他们首先使用 GPT-4-Turbo 生成高质量的“金标回答” (Gold Answers) 。然后,他们引入“扰动” (perturbations) ——即有针对性的修改,旨在引入特定错误,同时保持回答的其余部分完好无损。
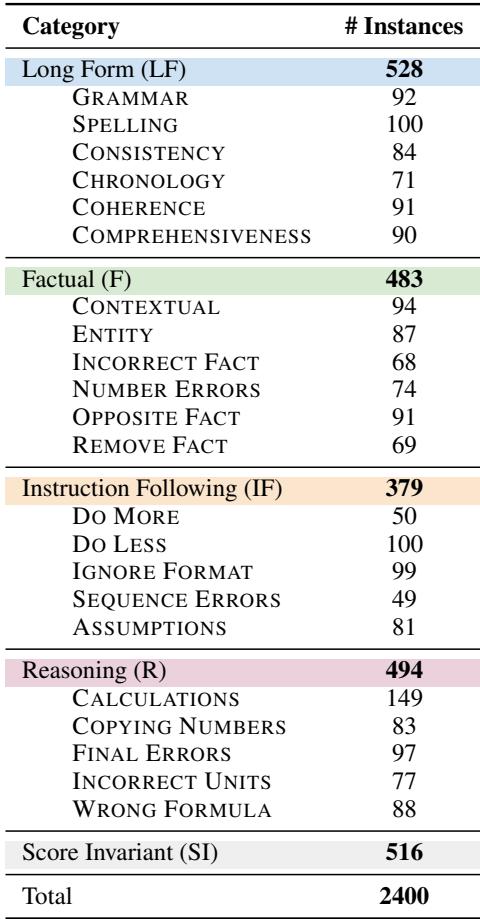
他们定义了 22 个不同的扰动类别 。 这种粒度使 FBI 框架具有“可解释性”。如果评估器失败,我们确切地知道原因 (例如,它无法发现计算错误,或者它忽略了拼写错误) 。

上表详细列出了这些类别。例如:
- 事实 (相反事实) : 更改句子以宣称完全相反的内容 (例如,将“will have”变为“won’t have”) 。
- 推理 (计算) : 更改数学步骤,如将 \(2+3=5\) 改为 \(2+3=6\)。
- 指令遵循 (少做) : 故意忽略提示的一部分。
- 长文 (连贯性) : 打乱段落的逻辑流。
研究人员生成了 2,400 个这样的扰动回答。至关重要的是,他们采用了人机回环 (Human-in-the-Loop) 流程。自动扰动并不完美,因此研究生手动验证了这些扰动回答,以确保它们确实是错误的,并且错误与类别相关。
他们还创建了“分数不变” (Score Invariant) 扰动——这些更改不应降低分数 (如转述) 。这作为一个对照组,以确保评估器不仅仅是因为有任何变化就进行惩罚。
如何审判法官
有了这 2,400 个有缺陷的回答数据集,研究人员测试了五个常被用作评估器的著名 LLM,包括 GPT-4-Turbo、Gemini-1.5-Pro、Claude-3-Opus 和 Llama-3-70B。
他们通过业界常用的三种不同评估范式对其进行了测试:
- 单回答评分 (Single-Answer Scoring) : 模型查看一个回答并给出一个分数 (例如 1-10) 。
- 成对比较 (Pairwise Comparison) : 模型查看“金标”回答和“扰动”回答,并决定哪个更好。
- 参考导向评分 (Reference-Guided Scoring) : 模型在查看“金标”参考答案的同时对回答进行评分。
他们还尝试了不同的提示策略,例如 Vanilla (仅要求评分) 、Rubric (提供评分指南) 和 Axis (告诉模型专注于“事实性”或“语法”等特定维度) 。
结果: 信任危机
结果是严峻的。研究发现,评估器 LLM 目前远不可靠。平均而言,即使是最好的模型也未能在超过 50% 的案例中识别出质量下降。
1. GPT-4-Turbo 在基础问题上挣扎
让我们看看被广泛认为是最先进评估器的 GPT-4-Turbo 的表现。
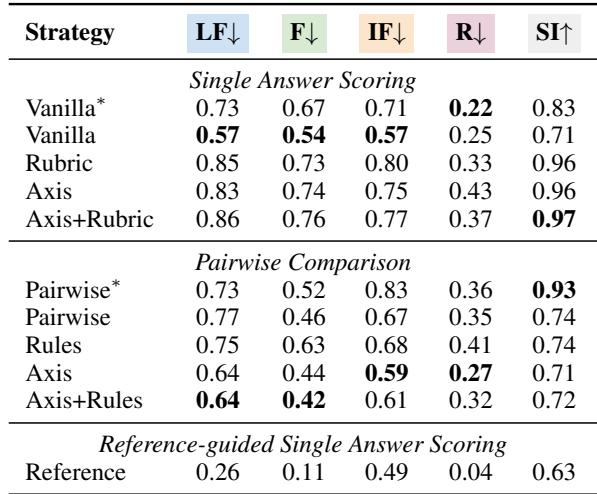
在上表中,数字代表评估器未能惩罚扰动回答的百分比 (越低越好) 。
- 事实准确性: 在单回答评分中,根据策略的不同,GPT-4 大约 67-76% 的时间未能惩罚事实错误。
- 指令遵循: 它错过了 57-80% 的违规指令。
- 推理: 它在这方面表现最好,但仍然错过了 22-43% 的错误。
这些不是细微的错误。这些是删除了“not”或故意破坏数学等式的回答。如果一位人类老师错过了学生文章中 70% 的事实错误,他们就会被解雇。
2. 复杂性并不总是有帮助
研究人员发现了一个关于提示策略的惊人趋势。你可能认为给模型提供详细的评分标准( Rubric 或 Axis+Rubric 策略) 会提高性能。
然而,查看上表中的“单回答评分”部分, Vanilla 策略 (简单地要求评分) 通常优于复杂的 Rubric 策略。添加更多指令有时似乎会让模型感到困惑或分散其注意力,使其对错误的敏感度降低。
但是,在 成对比较 (在两个回答中选择) 中,情况恰恰相反: 拥有详细的规则 (Rules) 有助于模型做出更好的决定。
3. 模型对比
这仅仅是 GPT-4 的问题吗?不幸的是,不是。研究人员将 GPT-4 与其他重量级模型进行了比较。
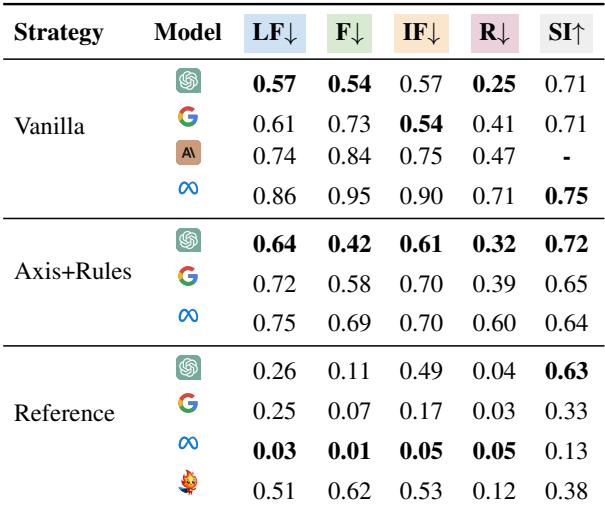
如表 4 所示,GPT-4-Turbo 在无参考评估中通常优于 Llama-3 和其他模型。然而, Llama-3-70B-Instruct 在 有参考评估 (即向法官提供正确答案) 中表现出令人惊讶的实力。
这里出现了一个有趣的现象: Llama-3 极其严格。虽然在有参考答案时它几乎捕捉到了所有错误,但它也严厉惩罚了“分数不变” (正确) 的回答。Llama-3 似乎很难区分错误的回答和与参考答案措辞不同但正确的回答。
4. “我看见了,但我不在乎”现象
最令人担忧的发现之一是评估器的解释与其分数之间的脱节。
大多数“LLM 即法官”的提示要求模型在打分之前解释其推理 (思维链) 。研究人员分析了这些解释,看看模型是否注意到了错误但拒绝扣分。
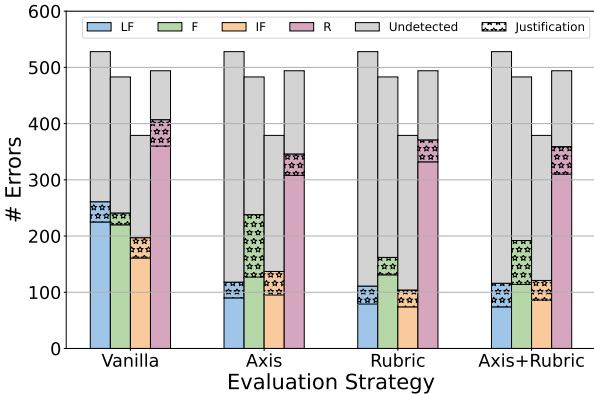
上图展示了这种差距。紫色条纹部分代表模型的解释明确提到了错误 (例如,“用户要求列出清单,但模型写了一段话”) ,但数字分数仍然是满分的情况。
虽然检查解释有助于发现更多错误,但绝大多数错误 (灰色条形) 仍然未被分数和文本生成检测到。
分类别的盲点
FBI 框架揭示了这些模型固有的具体弱点:
- 流畅性被高估: 评估器很容易被自信、流畅的写作所迷惑。一个语法通顺但事实错误的扰动回答经常被放过。
- 指令遵循: “否定约束” (例如,“不要使用要点”) 经常被评估器忽略。如果回答看起来很有帮助,评估器就会原谅格式违规。
- 数学盲: 虽然推理是表现最好的类别,但如果最终文本看起来很权威,模型仍然难以惩罚“错误公式”或“错误单位”。
结论: 对法官的裁决
FBI 论文为 AI 社区提供了一个清醒的现实检验。当我们竞相构建更强大的模型时,我们的标尺——评估器 LLM——却是扭曲的。
这项研究的关键结论是:
- 不要相信分数: 10/10 的自动评分并不能保证事实准确性或指令遵循。
- 成对比较存在缺陷: 即使直接比较正确回答和破坏后的回答,模型也经常无法准确选出赢家。
- 参考答案至关重要: 当提供金标参考答案时,评估器的表现会明显更好,尽管这在不存在单一“正确”答案的开放式生成任务中很难实现。
FBI 框架为“元评估”提供了必要的工具包。在使用 LLM 对数据集进行评分之前,你应该通过像 FBI 这样的清单运行它,以了解其偏见和盲点。在评估器 LLM 改进之前,我们必须保持谨慎,在关键决策中保持人工介入,并以适度的怀疑态度看待 AI 排行榜。