](https://deep-paper.org/en/paper/2406.13718/images/cover.png)
这一代的大型语言模型 (LLM) 往往给人一种魔法般的感觉。让 BLOOM 或 GPT-4 这样的模型将法语翻译成英语,结果通常完美无瑕。切换到印地语,它的表现依然令人钦佩。但是,当你稍微踏出这些“高资源语言” (High-Resource Languages, HRLs) 的聚光灯之外,会发生什么呢?
现今世界上大约有 7000 种语言,但 LLM 通常只在其中极小的一部分上进行训练——通常约为 100 种。世界上绝大多数语言,包括成千上万种方言和近缘变体,都被遗忘在黑暗中。
直觉告诉我们,如果一个 LLM 懂印地语,它应该也能懂一点迈蒂利语 (Maithili,一种在印度和尼泊尔使用的相关语言) 。如果它懂德语,它可能也能理解一些瑞士德语。这就是跨语言泛化 (cross-lingual generalization) 的承诺。但在实践中,性能往往会断崖式下跌。为什么?是因为拼写不同吗?是语法问题吗?还是仅仅因为词汇没有重叠?
在这篇文章中,我们将深入探讨约翰霍普金斯大学 Bafna、Murray 和 Yarowsky 的一篇引人入胜的论文。他们提出了一个新颖的框架来回答这些问题,该框架不将语言差异视为二元的“不同语言”,而是将其视为施加在已知语言上的噪声 (noise) 。
通过合成成千上万种“人造语言”,他们系统地查明了究竟是什么导致了 LLM 的崩溃。
问题: HRL 与 CRL 之间的差距
为了理解这一挑战,我们需要先看看高资源语言 (HRL) 与其近缘语言 (Closely-Related Languages, CRLs) 之间的关系。
HRL 是拥有海量可用训练数据的语言 (如英语、西班牙语、印地语) 。CRL 是语言上的邻居——它们拥有共同的祖先、词汇和语法,但有着明显的变异。
当从 HRL 转向 CRL 时,LLM 会遭受性能下降 (Performance Degradation, PD) 。 但衡量这一点很棘手,因为现实中的低资源语言通常缺乏测试模型所需的评估数据集 (如问答对或蕴含数据集) 。此外,我们很难知道某种“低资源”语言是否实际上潜伏在模型的训练数据中,这会混淆结果。
研究人员在图 1 中比较了印地语 (HRL) 和迈蒂利语 (CRL) ,说明了这些差异的复杂性。

如上所示,这些差异并非随机。它们归属于特定的语言学类别:
- 音系 (Phonological) : 导致拼写差异的声音变化 (例如,teksi 与 teksī) 。
- 形态 (Morphological) : 词尾或语法的变化 (例如,unhoni 与 o) 。
- 词汇 (Lexical) : 完全不同的词汇 (例如,kāma 与 karyakṃ) 。
这篇论文的核心洞察既简单又精彩: 如果我们缺乏真实方言的数据来测试这些维度,为什么不构建它们呢?
核心方法: 通过“加噪”合成语言
研究人员将语言之间的距离建模为贝叶斯噪声过程。他们选取一种源语言 (HRL) 并对其应用“加噪器 (noisers) ”。这些加噪器以符合语言学规律的方式破坏文本,从而创建出人造 CRL。
通过控制这种噪声的“音量” (由参数 \(\theta\) 表示) ,他们可以生成一系列从“几乎相同”到“远房表亲”的语言谱系。
1. 音系加噪器 (\(\phi^p\))
语言通过语音演变而进化。例如,拉丁语中的 ‘p’ 音 (pater) 在日耳曼语族中变成了 ‘f’ (father) 。这个加噪器模拟了这一过程。
它不仅仅是随机交换字母。研究人员使用国际音标 (IPA) 来确保变化在物理上是可能的。他们根据特征 (圆唇、发声、送气) 对声音进行分组。
如上面的 IPA 字符集所示,像 ‘p’ 这样的声音可能会变成 ‘b’ (发声变化) 或 ‘f’ (发音方式变化) ,但它不太可能自发地变成像 ‘a’ 这样的元音。
加噪器的工作原理是将文本转换为 IPA,根据周围的上下文 (左侧和右侧字符) 以概率 \(\theta_p\) 应用变化,然后将其映射回文字。这模拟了语音变化的规律性——如果 ’d’ 在词尾变成 ’t’,这往往会在整个语言中一致地发生。
2. 形态加噪器 (\(\phi^m\))
形态学涉及单词的结构——特别是后缀和前缀。在亲缘语言中,词根通常保持不变 (“同源词”) ,但语法结尾会发生变化。
形态加噪器 (\(\phi^m\)) 识别源语言中的常见后缀。它以概率 \(\theta_m\) 将后缀替换为生成的替代品。为了保持真实感,新后缀是通过对旧后缀应用重度音系噪声生成的。这创造了一个看起来和听起来都属于同一语系,但又截然不同的新结尾。
3. 词汇加噪器 (\(\phi^{f,c}\))
最后,有时单词会完全改变。这就是词汇变异。作者将其分为两类:
- 功能词 (\(\phi^f\)): 句子的粘合剂——介词、代词、限定词 (例如,“the”、“in”、“he”) 。这是一个封闭的集合,且频率极高。
- 实词 (\(\phi^c\)): 名词、动词、形容词。它们承载了大部分意义。
加噪器以概率 \(\theta_f\) 或 \(\theta_c\) 替换这些词。替换词不是同义词;它是一个“非同源词”——一个看起来与原词毫无相似之处的词。生成的替换词在正字法上是合理的 (看起来像真词的“无意义”词) 。
衡量损失: 性能下降 (PD)
一旦生成了人造语言,研究人员就会在其上测试 LLM。他们定义了一个名为性能下降 (Performance Degradation, PD) 的指标来量化模型的受损程度。
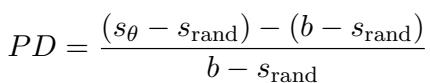
在这个公式中:
- \(s_{\theta}\) 是在加噪 (人造) 语言上的得分。
- \(b\) 是在原始干净语言上的基准得分。
- \(s_{\text{rand}}\) 是随机猜测的得分。
本质上,\(PD\) 代表了能力丧失的百分比。如果 \(PD\) 为 0%,模型完美处理了该方言。如果 \(PD\) 为 100%,模型已经退化为随机猜测。
连接现实: 后验计算
你可能会问: “人造语言很酷,但它们反映现实吗?”
为了弥合这一差距,作者开发了一种方法来计算真实语言对的噪声参数 (\(\theta\))。通过对齐真实的 HRL (如印地语) 和真实的 CRL (如阿瓦德语 Awadhi) 之间的单词,他们可以估计它们之间实际存在多少音系、形态和词汇距离。
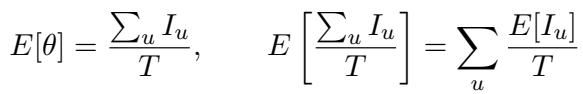
这个方程允许他们基于源语言和目标语言之间有多少单位 (单词、后缀或音素) 不同,来计算预期的噪声 \(\theta\)。
实验与结果
团队使用三个任务在 BLOOMZ-7b1 模型上测试了这些加噪器:
- 机器翻译 (X \(\rightarrow\) eng): 将 CRL 翻译成英语。
- XNLI: 自然语言推理 (判断一个句子是否暗示另一个句子) 。
- XStoryCloze: 故事填空。
他们对 7 个语系进行了实验,包括印地语、阿拉伯语、印度尼西亚语和德语。
结果 1: 不同的噪声以不同的方式造成伤害
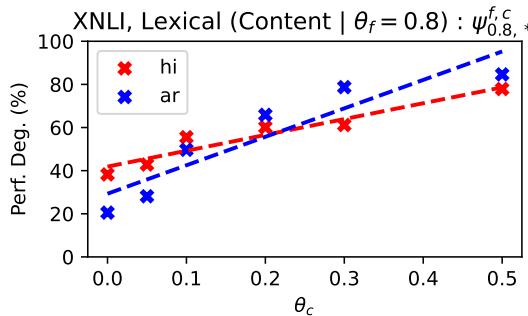
最引人注目的结果是性能随噪声增加而下降的可视化。
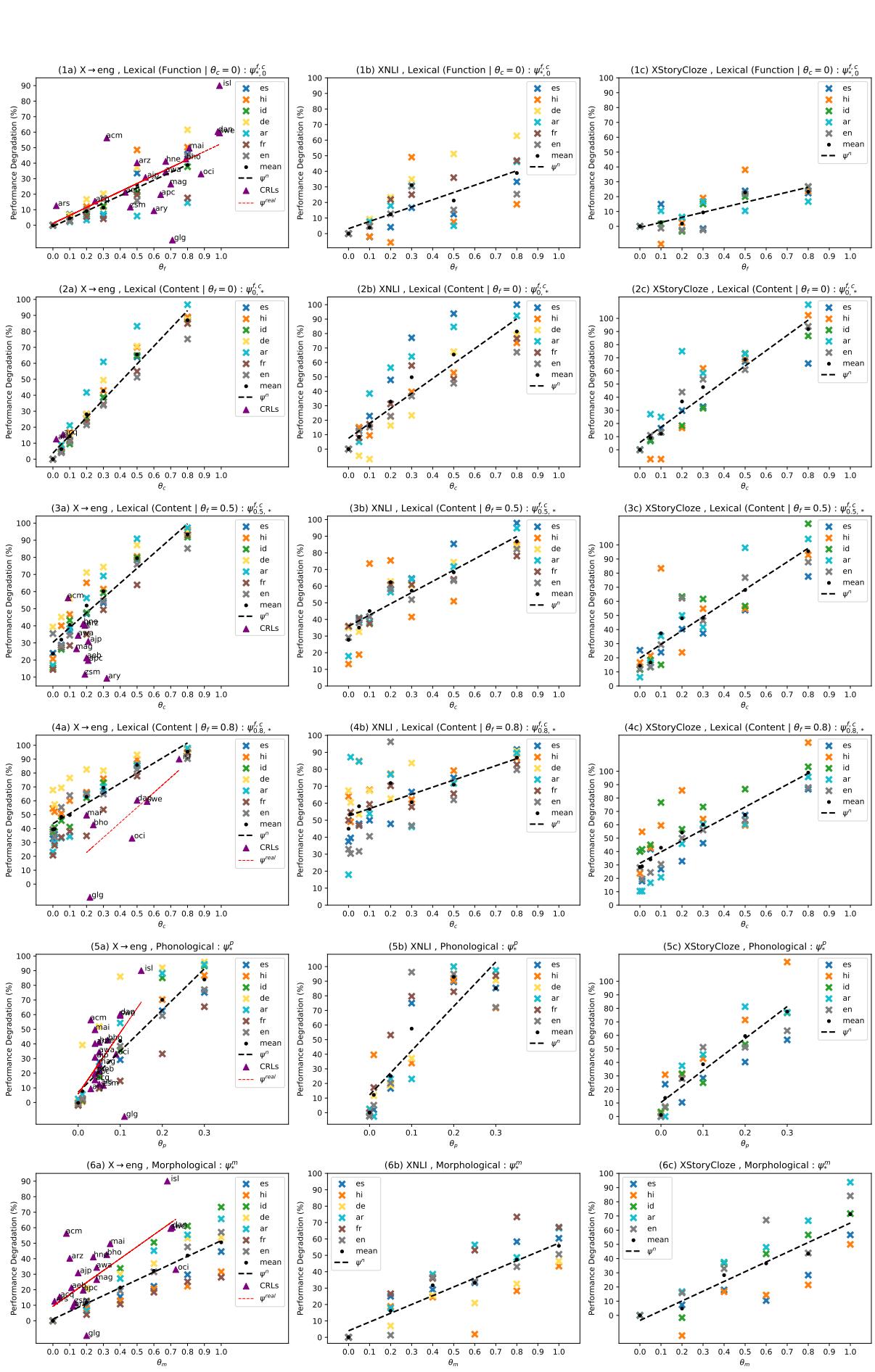
让我们分解一下图 2 中的见解:
- 音系噪声 (第 3 行 - \(\phi^p\)) : 看那些陡峭的斜率。模型对声音/拼写变化极其敏感。即使是少量的音系噪声 (\(\theta_p = 0.2\)) 也会导致巨大的性能下降。这表明 LLM 严重依赖精确的子词匹配。
- 形态噪声 (第 2 行 - \(\phi^m\)) : 这些线条要平坦得多。模型在这里表现出惊人的鲁棒性。即使你破坏了 50-80% 的后缀,模型仍然可以根据词干推断出含义。
- 词汇噪声 (第 1 行 - \(\phi^{f,c}\)) :
- 实词 vs. 功能词: 实线 (实词发生变化) 显示出陡峭的下降。丢失名词和动词会破坏理解。
- 功能词: 改变功能词 (如 “the” 或 “of”) 的影响低于改变实词。
结果 2: 真实语言遵循人造趋势
再仔细看看图 2 中的散点图。你会看到散布在这些线条周围的彩色点 (三角形和圆形) 。
这些点代表真实的 CRL-HRLN 对 (例如,西班牙语和加利西亚语,或德语和丹麦语之间的距离) 。
- x 轴位置由计算出的 \(\theta\) (真实语言距离) 确定。
- y 轴是 LLM 在该真实语言上的实际性能下降。
发现: 真实语言主要紧贴人造语言生成的趋势线。这验证了整个方法论。这意味着我们可以仅仅通过测量某种方言与训练语言的语言距离,就能准确预测 LLM 在该真实方言上的失败程度,而无需该方言的标记测试集。
结果 3: 比较语言和任务
并非所有语言的表现都相同。在下图 3 中,我们看到了不同语言的平均 PD。
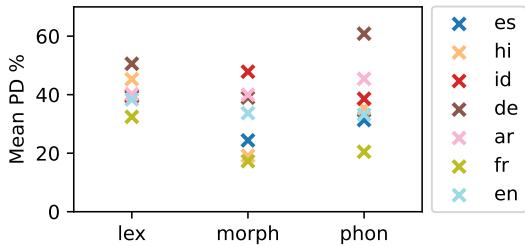
德语 (棕色 ‘x’) 始终遭受严重的性能下降,尤其是在词汇噪声方面。这可能是因为德语是复合词语言——改变一个组件就会破坏整个词。相反,西班牙语 (蓝色 ‘x’) 似乎更稳健。
作者还指出, 翻译 (X \(\rightarrow\) eng) 是比分类 (XNLI) 更稳定的任务。在翻译中,如果一个词被破坏,模型可能仍能翻译句子的其余部分。在分类中,破坏一个关键同可能翻转整个前提的逻辑,导致模型崩溃为随机猜测。
结果 4: 噪声的组合
真实语言不仅仅拥有一种类型的噪声;它们同时拥有所有类型的噪声。它们是如何相互作用的?
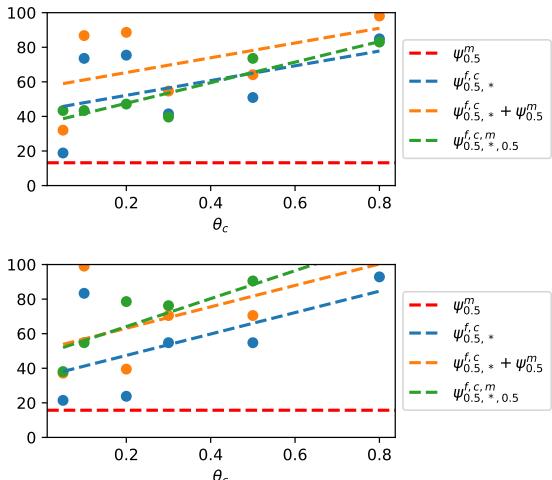
图 7 显示了组合词汇和形态噪声的效果。
- 橙色线 代表两种噪声的理论总和。
- 绿色/蓝色线 显示了实际的实验结果。
有趣的是,组合效应不是相加的 。 随着词汇噪声的增加 (x 轴) ,它主导了性能下降。如果一个词被完全替换 (词汇噪声) ,它的后缀是否也被改变 (形态噪声) 就无关紧要了。模型在这个词上已经失效。这种“覆盖”效应是建模现实世界语言变异的关键见解。
定性分析: 模型是如何崩溃的?
观察模型面对这些噪声时如何失败是很有帮助的。作者提供了错误类型的详细分类。
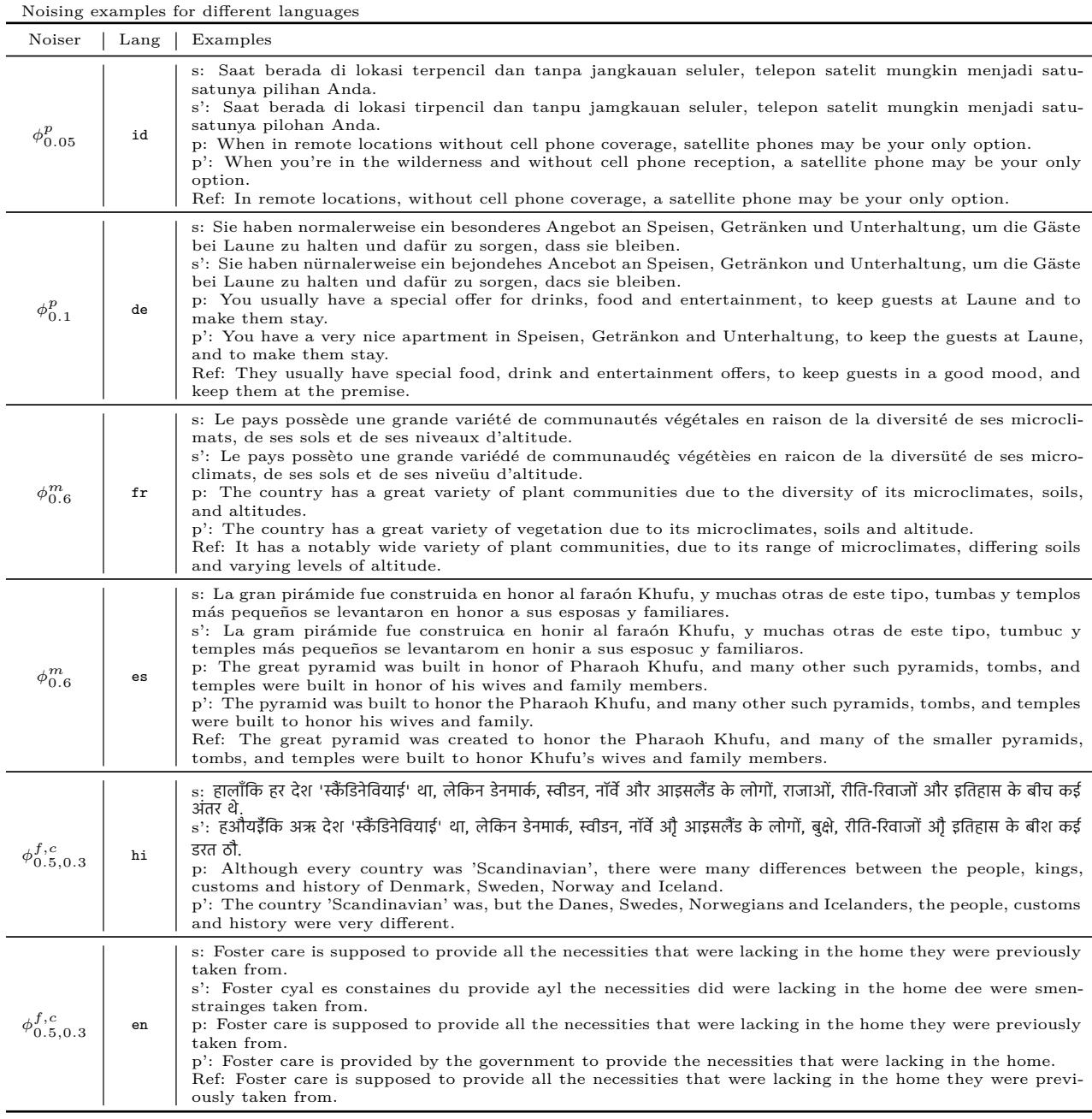
在表 6 中,我们可以看到具体的例子:
- 音系 (\(\phi^p\)): 在印度尼西亚语示例 (第一行) 中,几个元音变化导致模型输出了特定的英语翻译,但略有降级。
- 词汇 (\(\phi^{f,c}\)): 在印地语示例中,替换实词导致模型丢失了特定的主语 (丹麦人、瑞典人) ,退而使用通用术语或完全不同的含义。
表 7 (下文) 提供了针对西班牙语的这些错误的分类体系。
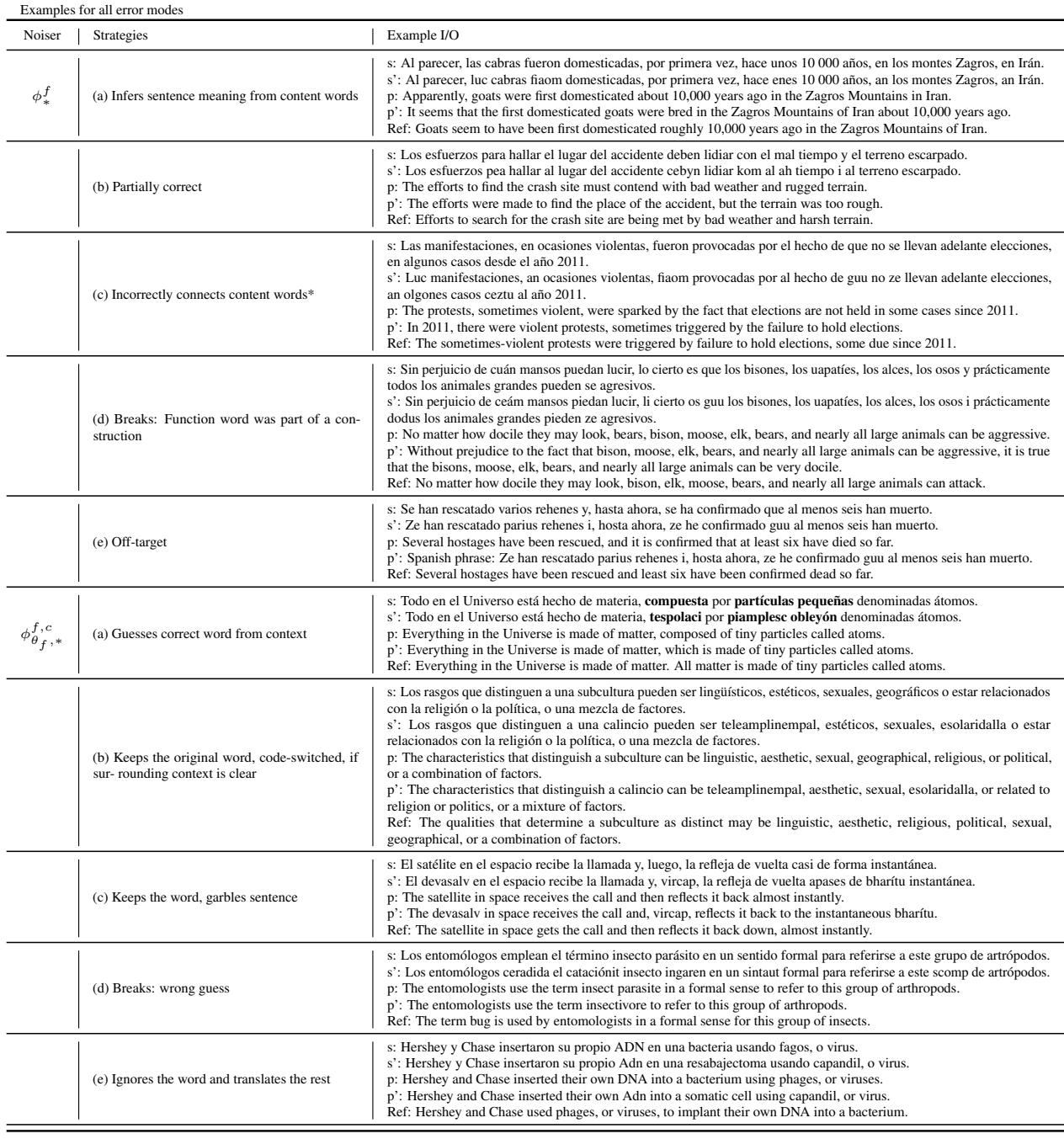
注意 \(\phi^f\) 下的 (d) 行: “崩溃: 功能词是结构的一部分。”当噪声击中语法上必要的功能词 (如 “sin perjuicio” 中的 “sin”) 时,即使实词完好无损,模型对句子结构的理解也会崩溃。
结论与启示
这项研究填补了自然语言处理领域的一个巨大空白。通过成功地将语言变异建模为噪声,作者为我们提供了一个工具来:
- 诊断故障: 我们现在可以说出为什么 LLM 在某种方言上失败。是拼写?是词汇?还是语法?
- 预测性能: 对于数千种没有测试集的低资源语言,我们只需计算它们与高资源邻居的距离 (\(\theta\)),然后在本文生成的曲线上查找预期性能即可。
- 设计更好的模型: 知道模型对音系噪声 (拼写/声音变化) 过度敏感,表明我们需要更好的分词器或对字符级变异具有鲁棒性的预训练目标。
“方言连续体”是巨大的,而 LLM 仅仅触及了皮毛。像这样的工作使我们从二元思维 (模型懂语言 X 吗?) 转向对语言能力的细微理解 (模型对变异 \(\theta\) 的鲁棒性如何?) 。
当我们展望真正多语言 AI 的未来时,模拟语言的演变可能正是理解它的关键。