](https://deep-paper.org/en/paper/2406.14760/images/cover.png)
你有没有读过互联网上的评论区,然后心想: “哇,这真是一场富有成效的对话”?这种情况很少见。大多数网络争论最终都会演变成互相叫嚷。但在自然语言处理 (NLP) 和社会科学领域的研究人员看来,理解是什么让一段对话具有“建设性”——即参与者能够敞开心扉、达成共识,或者仅仅是礼貌地表达不同意见——是一个巨大且复杂的谜题。
为了解决这个问题,我们通常有两个工具箱。一方面,我们有基于特征的模型 (feature-based models) 。 这些是“老牌可靠”的工具 (如逻辑回归) ,它们使用特定的人工规则。它们易于解释——你很清楚模型为什么会做出某个决定——但它们通常需要昂贵的人工标注来标记数据。
另一方面,我们有神经模型 (Neural Models) , 特别是像 BERT 或 GPT-4 这样的预训练语言模型 (PLM) 。它们是动力源。它们消化原始文本,通常能达到更高的准确率。但它们有一个缺点: 它们是“黑盒”。我们不知道它们如何得出结论。更糟糕的是,它们容易进行“捷径学习 (shortcut learning) ”,即记住肤浅的模式 (比如特定的关键词) ,而不是理解对话的实际动态。
在论文 《An LLM Feature-based Framework for Dialogue Constructiveness Assessment》 (一种用于对话建设性评估的 LLM 特征基框架) 中,来自剑桥大学和东芝公司的研究人员提出了一种打破这种二元对立的方法。他们引入了一个框架,结合了基于特征模型的可解释性和大语言模型 (LLM) 的强大能力。
在这篇文章中,我们将拆解他们的方法,探索他们如何将 LLM 用作“特征提取器”而不是最终预测器,并看看为什么这种混合方法可能比简单地把问题扔给巨大的神经网络要好得多。
当前方法的局限性
在深入解决方案之前,我们需要了解作者所解决的具体局限性。
1. 可解释性的代价
如果你想知道为什么一段对话失败了,你需要特征。用户是否使用了侮辱性语言?他们是否使用了模糊限制语 (例如,“我觉得也许……”) 来缓和观点?他们提问了吗?传统的基于特征的模型需要这些输入。历史上,获取高质量的特征意味着雇佣人类阅读数千条评论,并将它们标记为“敌对”或“合作”。这既缓慢又昂贵。
2. 捷径学习的陷阱
神经网络是懒惰的学习者。如果你训练一个模型来检测“建设性”辩论,而你的训练数据中有很多关于素食主义的礼貌讨论,模型可能只会学到“豆腐”这个词等于“建设性”。它忽略了论证的结构,而专注于主题。这就是所谓的捷径学习 。 当你在关于英国脱欧的辩论中测试同一个模型时,它会惨败,因为那里不存在“豆腐”这个捷径。
解决方案: LLM 特征基框架
作者提出了一种“集两者之长”的方法。他们不是使用 LLM 直接预测最终结果,而是使用 LLM 来提取特征 。 然后将这些特征输入到一个简单、可解释的模型 (如岭回归或逻辑回归) 中。
以下是该框架的高级工作流程:

如图 1 所示,该过程分为两个并行的特征提取流:
- 简单算法启发式 (Simple Algorithmic Heuristics) : 基于代码的规则,用于统计代词或礼貌标记等内容。
- 提示 LLM (Prompting an LLM) : 使用 GPT-4 分析复杂的语言行为,如争论策略或论证质量。
这两股数据流汇合后,生成对话的统计概况,然后将其输入到一个透明的分类器中。
第一步: 特征提取
这就论文的核心在于作者精心策划的一组丰富的语言特征 。 他们不只是把文本扔进模型;他们寻找已知会影响人类互动的特定信号。
他们将这些信号组织成六个与数据集无关的集合。

让我们分解这些特征集,因为它们是模型用来理解世界的“感官”。
启发式特征 (“老派”流)
这些特征可以使用像 Convokit 这样的代码库提取。它们快速且具有确定性。
- 礼貌标记 (Politeness Markers) : 说话者是否使用了“请”、“谢谢”或“对不起”?他们是否以问候开始?
- 协作标记 (Collaboration Markers) : 寻找合作的迹象。它统计诸如“模糊限制语” (表示谦逊/不确定性) 或参与者引用相同概念的频率。
LLM 生成的特征 (“新派”流)
这就是创新所在。有些概念对于简单的代码来说太微妙了。识别“居高临下”或“反驳”需要语义理解。作者提示 GPT-4 充当这些特征的标注员。
- 争论策略 (Dispute Tactics) : 参与者是如何争吵的?是在“谩骂”?是在“转移话题”?还是在提供基于证据的“反驳”?
- 论证质量 (Quality of Arguments, QoA) : 这是本文引入的一个新颖特征。LLM 被要求对论证质量进行 0-10 分的评分。
- 风格与语气 (Style and Tone) : 文本正式吗?情绪是负面的吗?是否存在“认知不确定性” (例如,“我相信这可能是真的” vs “这是真的”) ?
为了获取这些特征,研究人员设计了特定的提示词。例如,为了提取争论策略 , 他们将对话历史提供给 LLM,并要求其对最近的一句话进行分类。

通过要求 LLM 输出结构化列表 (每个类别为 0 或 1) ,他们将非结构化文本转换为回归模型可以使用的结构化数据。
第二步: 从语句到对话
对话是一系列的轮次。上面的特征是在语句 (utterance) 级别 (每个句子/评论) 提取的。为了对整个对话进行分类,该框架计算整个交流过程的统计数据:
- 平均值 (\(\bar{x}\)): 例如,“这次对话的平均礼貌程度是多少?”
- 梯度 (\(\nabla\)): 例如,“随着对话的进行,礼貌程度是增加了还是减少了?”
这不仅捕捉到了对话的状态,还捕捉到了它的轨迹。
实验设置
为了证明这个框架的有效性,作者在三个截然不同的数据集上进行了测试:
- 开放思维 (Opening-Up Minds, OUM): 关于争议性话题 (英国脱欧、素食主义、COVID-19) 的对话。目标是预测参与者在聊天后是否变得更加开放。
- 维基策略 (Wikitactics): 维基百科讨论页的纠纷。目标是预测纠纷是升级了 (坏) 还是解决了 (好) 。
- 条目删除 (Articles for Deletion, AFD): 关于是否应删除维基百科条目的辩论。目标是预测“保留”与“删除”的结果。
他们将自己的LLM 特征基模型与重量级选手进行了比较:
- 基线模型: 词袋模型 (Bag-of-Words) 、GloVe 嵌入。
- 神经模型: Longformer (专为长文本设计的 BERT 版本) 和 GPT-4o (零样本和少样本提示) 。
结果: 准确率与性能
结果令人惊讶。在深度学习占主导地位的时代,人们可能预期巨大的神经网络会碾压简单的回归模型。但事实并非如此。
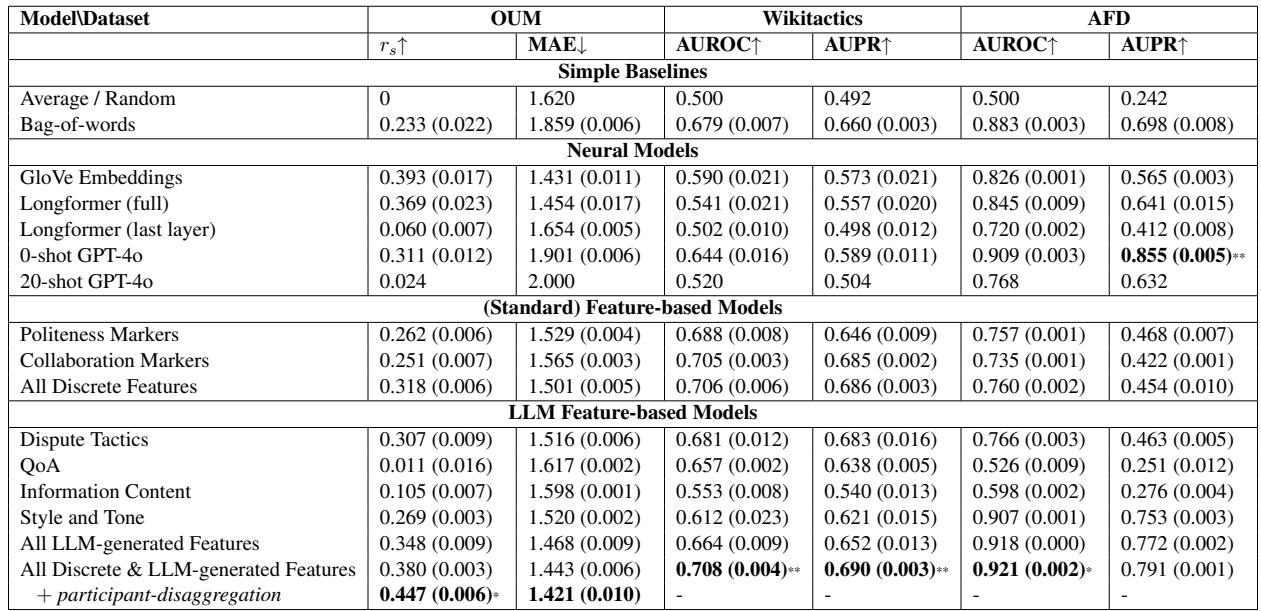
请看表 4 底部的 “LLM Feature-based Models” (LLM 特征基模型) 部分。
- Wikitactics: 组合模型 (所有离散及 LLM 生成特征) 达到了 0.708 的 AUROC,显著优于最佳神经模型 (GloVe 的 0.590) ,甚至超过了 GPT-4o (0.644) 。
- OUM: 基于特征的模型实现了 0.380 的相关系数 (\(r_s\)),这与最佳神经基线相当。当他们加入参与者级别的聚合时,这一数值跃升至 0.447 , 击败了所有其他模型。
- AFD: 该模型的表现与 GPT-4o 零样本相当。
关键结论: 你不需要黑盒来获得最先进的结果。一个简单的回归模型,只要输入高质量的、由 LLM 提取的特征,就能表现得和庞大的端到端神经网络一样好,甚至更好。
“捷径学习”测试
这是分析中最关键的部分。高准确率固然好,但鲁棒性更重要。
作者假设神经模型 (Longformer, GloVe) 在“作弊”——它们记住了特定主题的词汇,而不是学习论证是如何运作的。为了验证这一点,他们采用在 OUM 数据集上训练的模型,并在特定的子主题 (英国脱欧 vs 疫苗接种 vs 素食主义) 上进行了评估。
如果一个模型真正理解“建设性”,无论话题如何,它都应该有效。如果它只是在寻找关键词,它的表现将在不同主题之间剧烈波动。

表 5 揭示了神经模型的脆弱性:
- GloVe & Longformer: 它们在单个主题上的表现崩塌了。对于英国脱欧,GloVe 的相关系数为 -0.036 (基本等同于随机猜测) 。
- LLM 特征基模型: 它在所有主题上都保持了稳定的性能 (英国脱欧为 0.409,疫苗接种为 0.385,素食主义为 0.350) 。
这证明了神经模型确实学习了与主题相关的捷径 (偏差) 。而 LLM 特征基框架由于依赖语言特征 (如“礼貌”或“推理”) 而不是原始文本,因此学到了通用的鲁棒预测规则 。
可解释人工智能: 真正重要的是什么?
因为研究人员使用的是可解释的回归模型,他们可以查看系数 , 确切地看到哪些特征驱动了预测。这为我们提供了关于什么让对话具有建设性的心理学和语言学见解。
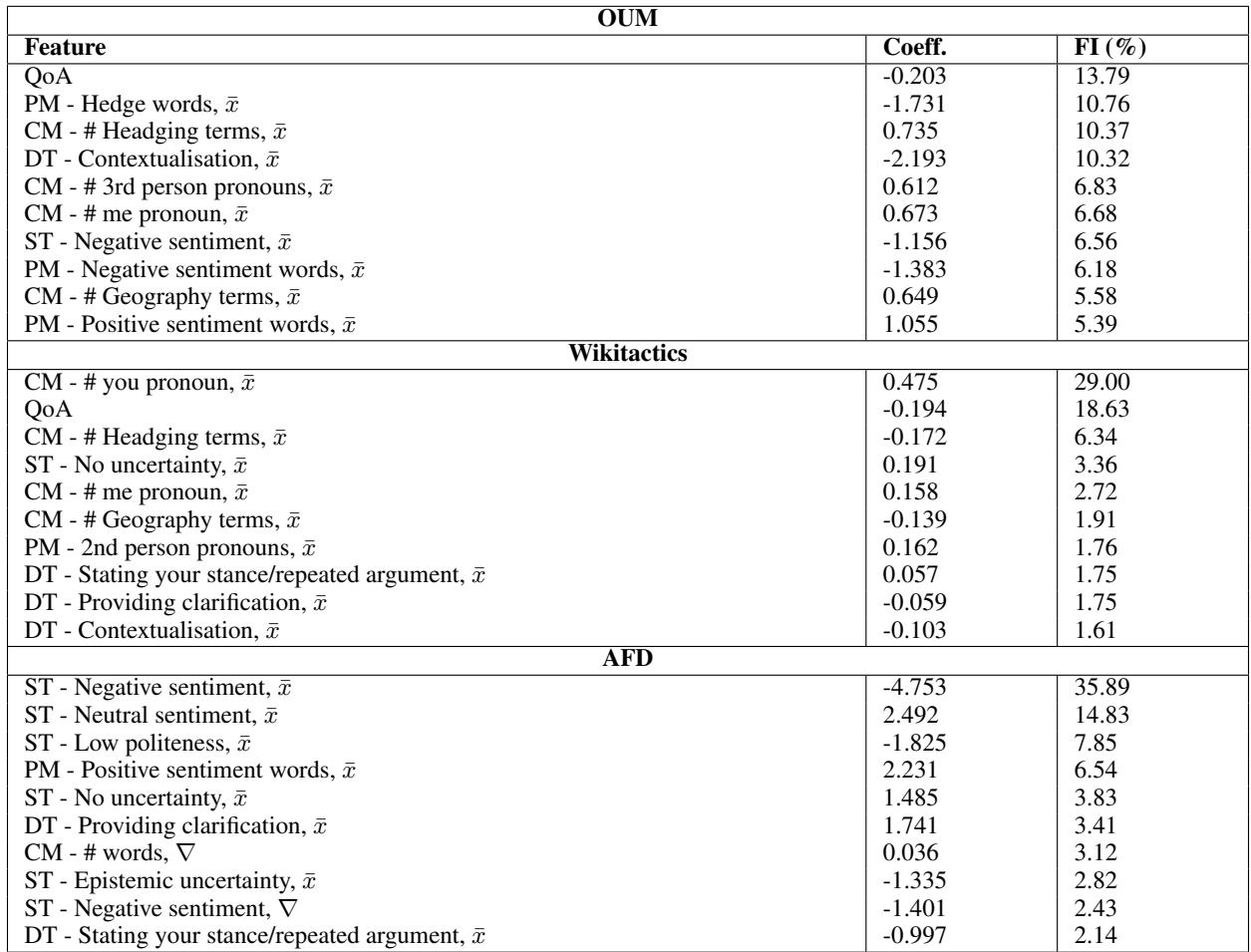
以下是表 18 中的一些有趣见解:
1. “你”的问题 (Wikitactics)
在维基百科的纠纷中,最重要的特征 (29% 重要性) 是第二人称代词 (“You”) 的使用。系数对于“升级”是正向的。这与心理学研究一致: 说“你是错的”感觉像是攻击或指责,会导致非建设性的结果。
2. 论证质量 (OUM)
对于“开放思维”数据集, 论证质量 (QoA) 是首要特征。令人惊讶的是,它有一个小的负系数。为什么? 分析表明,高 QoA 分数通常出现在参与者激烈反驳的辩论中。仅仅提问 (一种“建设性”行为) 的人 QoA 分数较低,因为他们没有进行论证——他们在倾听。这凸显了“建设性”的细微之处: 有时,高质量的辩论实际上比温和、轻松的对话更难改变某人的想法。
3. 模糊限制语减少升级
在各个数据集中,“模糊限制语” (使用诸如“可能”、“看起来”、“我假设”等词) 是积极结果的强预测因子。它表明说话者愿意接受纠正,从而缓解冲突。
4. 维基百科上的情绪 (AFD)
对于删除条目, 负面情绪是巨大的驱动因素 (FI = 35%) 。如果人们愤怒或消极,条目很可能会被删除。相反,正面情绪会保护条目。
结论
这篇论文为 NLP 中的“中间道路”提出了令人信服的论据。我们通常认为,要获得更好的结果,我们需要更大、更复杂的神经网络。但这项工作表明:
- 混合是健康的: 使用 LLM 提取结构化特征 (如“争论策略”) 比要求 LLM 进行最终预测更稳健。
- 可解释性并非免费,但现在更便宜了: 我们不再需要大量的人工标注员。LLM 可以为我们生成昂贵的特征。
- 鲁棒性很重要: 如果模型在对话话题改变的那一刻就崩溃了,“最先进”的准确率就毫无意义。基于特征的模型天然能够抵抗困扰神经网络的主题偏差。
对于学生和从业者来说,这个框架提供了一个实用的蓝图。如果你正在构建系统来分析社交媒体、客户支持或政治辩论,请考虑停止“端到端”的狂热。将问题分解为特征。使用 LLM 对这些特征进行分类。然后,使用简单的模型进行预测。你可能会得到一个不仅准确,而且实际上可以解释的系统。