](https://deep-paper.org/en/paper/2406.14883/images/cover.png)
社交媒体平台已成为 21 世纪事实上的城市广场。它们是公众舆论的宝库,为研究人员提供了社会如何看待关键问题的大量数据集。然而,对于社会科学家来说,这种规模也带来了一个悖论: 数据量虽然巨大,但要进行细粒度的理解却异常困难。
以美国的无家可归问题为例。这是一个复杂、敏感的话题,能引发广泛的情绪——从同情和呼吁援助,到愤怒和怨恨。传统的自然语言处理 (NLP) 工具,如情感分析 (正面与负面) 或毒性检测,往往过于生硬,无法胜任这项工作。一条批评政府住房政策的推文可能是“负面”的,但不一定是“有毒 (toxic) ”的。相反,一条对无家可归者 (PEH) 带有微妙、有害刻板印象的推文,可能会完全逃过毒性过滤器的检测。
在最近的一篇论文中,来自南加州大学的研究人员引入了一个名为 OATH-Frames (Online Attitudes Towards Homelessness,针对无家可归问题的网络态度) 的新框架。他们的工作做了两件重要的事情: 建立了一个复杂的分类体系来对这些态度进行分类,并提出了一种人类专家与大语言模型 (LLM) 协作的方法,以便大规模地标注数据。
现有工具的局限性
在深入探讨解决方案之前,我们必须先了解问题所在。为什么我们不能直接使用现有的工具来分析关于无家可归问题的推文?
研究人员发现,标准的毒性分类器 (如 Perspective API) 和情感分析模型经常会误判相关的讨论。例如,一篇帖子可能会说: “你看起像个流浪汉。”毒性分类器可能认为这是安全的,因为它没有使用明确的辱骂或威胁。然而,这是一种 有害概括 (Harmful Generalization) ——一种特定类型的污名化语言。
为了真正理解公众舆论,研究人员需要超越“正面/负面”的二元对立,并描绘出人们在讨论无家可归问题时使用的具体框架。
第一步: 发现与 OATH 分类体系
研究的第一阶段涉及 框架发现 (Frame Discovery) 。 团队收集了 310 万条包含关键字“homeless” (无家可归) 的推文,并使用了一种称为*扎根理论 (grounded theory) *的方法。这需要专家标注员通读数据样本,让类别自然浮现,而不是强加预定义的列表。
经过反复的讨论和细化,专家们确定了九个独特的“特定议题框架”。这些框架归属于三个更广泛的主题: 批评 (Critiques) 、认知 (Perceptions) 和回应 (Responses) 。

如上表所示,其中的细微差别非常重要:
- GovCrit (政府批评) : 归咎于机构或政策。
- NIMBY (邻避效应/不在我家后院) : 反对当地社区的住房项目。
- HarmGen (有害概括) : 对无家可归者 (PEH) 进行刻板印象化 (例如,将他们与犯罪或药物滥用联系起来) 。
- (Un)Deserv (应得与不应得) : 将问题定性为资源竞争 (例如,“既然我们还有无家可归的退伍军人,为什么要帮助移民?”) 。
这种分类体系提供了比简单的情感评分更丰富的词汇来分析社会话语。
第二步: 标注流水线
定义框架只是第一步。挑战在于将这些标签应用于数百万个帖子。人类专家准确但缓慢且昂贵。LLM 速度快,但容易产生“幻觉”或遗漏微妙的社交线索。
研究人员提出了一种混合流水线,利用了这两种方式的优势。
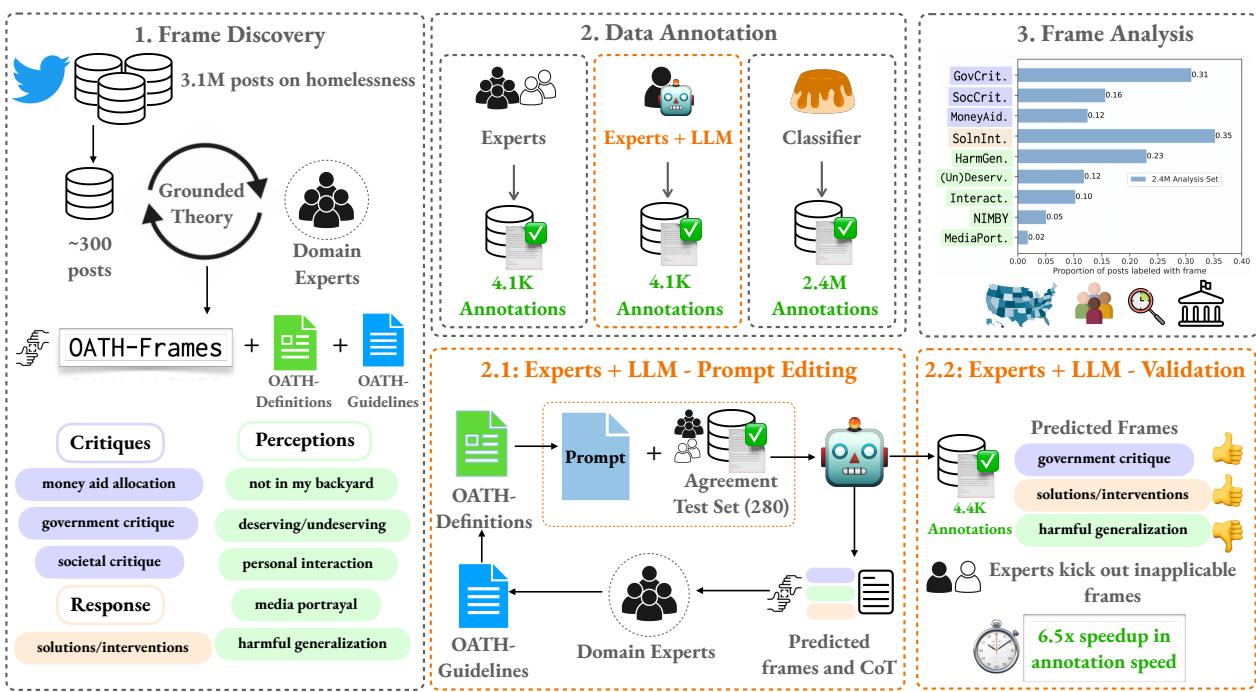
该过程如上图所示,遵循特定的流程:
- 框架发现: 专家定义 OATH 框架。
- 专家 + LLM 标注: 这是核心创新点。他们并没有简单地让 LLM 处理数据,或者完全依赖人类,而是创建了一个协作循环。
- 使用分类器进行扩展: “专家+LLM”阶段生成的高质量数据随后用于训练一个更小、更高效的模型 (Flan-T5-Large) ,以标注剩余的数百万个帖子。
LLM 辅助标注的艺术
研究人员并没有简单地要求 GPT-4“给这条推文打标签”。他们使用了一种迭代的提示工程策略,涉及 思维链 (Chain-of-Thought, CoT) 推理。
在这种设置中,LLM 被要求在给出最终标签之前提供其推理过程 (即“思维链”) 。然后由人类专家审查这些预测。如果 LLM 持续误解某个定义,专家们不会只修正标签;他们会根据 LLM 的推理错误来完善输入给它的提示词和指南。
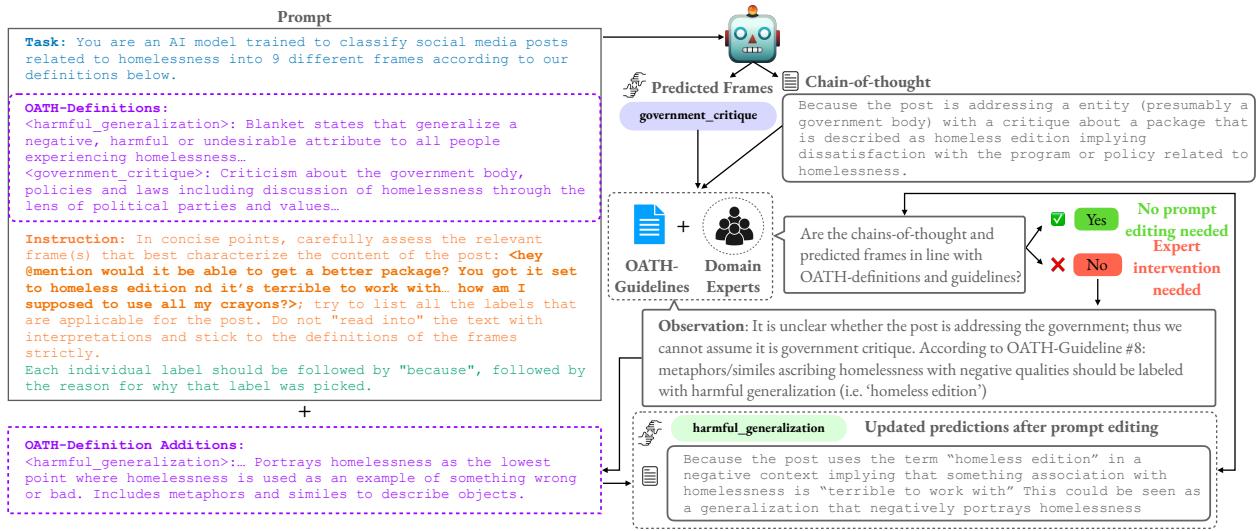
图 3 展示了这个反馈循环。通过分析模型为什么会犯错 (例如,混淆了隐喻和字面陈述) ,专家可以更新输入到提示词中的 OATH 定义和指南。
这种协作的结果令人印象深刻。与仅由人类标注相比,“专家+LLM”方法的标注时间缩短了 6.5 倍 。 虽然与纯人类标注相比,F1 分数 (一种准确度指标) 略有下降,但效率的提升使得处理如此规模的数据集成为可能。
第三步: 分析 240 万个帖子
随着训练好的模型就绪,研究人员将 OATH-Frames 应用于 2021 年至 2023 年间的 240 万条推文。分析揭示了标准分析工具无法看到的趋势。
毒性检测器的失效
最惊人的发现之一是 OATH-Frames 与标准毒性检测之间的脱节。
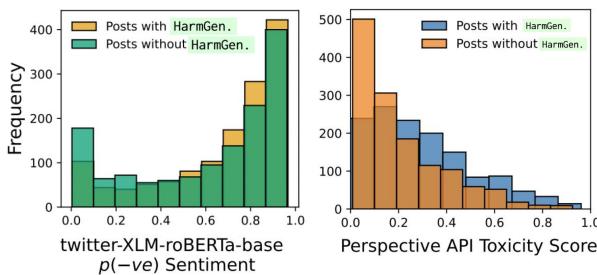
如上图 (右侧) 所示,大多数被标记为 HarmGen (有害概括) 的帖子毒性评分都很低 (低于 0.5) 。这证实了社交媒体平台上现有的安全工具可能无法捕捉针对弱势群体的污名化语言,因为这些语言往往比较隐晦,或者使用的是刻板印象而非公开的攻击。
政治事件驱动舆论
该研究还描绘了态度如何随着现实世界事件的发生而随时间变化。
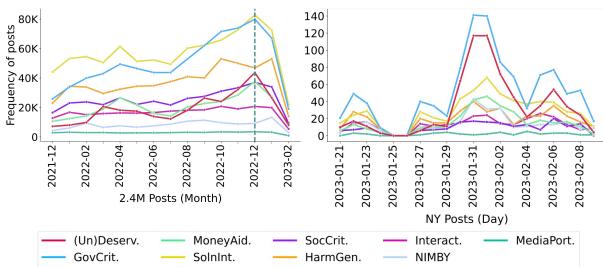
在图 6 (左侧) 中,我们看到 2022 年底出现了一个显著的峰值。研究人员将其与美国国会审议向乌克兰提供 449 亿美元援助计划联系起来。
这一地缘政治事件触发了特定的框架组合: GovCrit (批评开支) 和 (Un)Deserv (将“应得援助的”无家可归退伍军人与“不应得援助的”外国受援者进行比较) 。这强调了无家可归问题经常被用作讨论其他政治问题的修辞工具,而简单的“负面情感”标签会完全忽略这一细节。
态度的地理分布
最后,研究人员观察了态度如何随美国各州而异。他们发现,讨论内容会根据当地的社会经济背景发生变化。
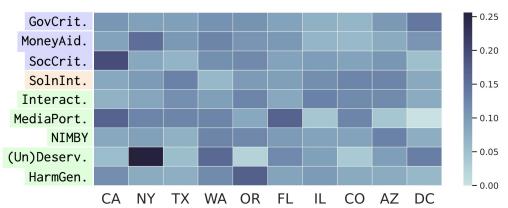
上面的热图揭示了明显的区域“指纹”:
- 加利福尼亚州 (CA): HarmGen 流行。由于有大量的露宿人口,讨论往往集中在无家可归现象的可见性和负面刻板印象上。
- 纽约州 (NY): (Un)Deserv 和 MoneyAid 流行。这与当地关于安置移民和寻求庇护者的政治冲突有关,导致舆论将不同的弱势群体对立起来。
研究人员通过回归分析进一步支持了这一点,表明一个州的“生活成本指数”高与 GovCrit 强相关——这表明当房租高昂时,人们会因无家可归问题而指责政府。
结论与启示
OATH-Frames 论文为计算社会科学的未来提供了一个蓝图。它表明我们不必在人类专家的深刻定性理解和 AI 的大规模能力之间做选择。通过设计专家指导和验证 LLM 的系统,研究人员可以创建反映社会问题复杂性的细致数据集。
对于 NLP 和社会工作领域的学生及从业者来说,这项研究强调了几个关键要点:
- 定义至关重要: 你无法分析你无法定义的事物。严谨地创建 9 个 OATH 框架与编码本身同样重要。
- 超越毒性检测: 我们需要更好的分类法来捕捉像刻板印象这样的微妙伤害。
- 人机回环 (Human-in-the-Loop) : 最有效的社会科学 AI 系统是那些将 LLM 视为人类专业知识助手,而非替代品的系统。
通过大规模地描述这些网络态度,倡导团体和政策制定者可以更深入地了解公众情绪,从而指导更有效的沟通策略和政策改革,以帮助那些经历无家可归的人们。