](https://deep-paper.org/en/paper/2406.14979/images/cover.png)
引言
想象一下,你被要求写一篇关于水母生物学的详细文章。你的手边有一堆教科书。新手的做法可能是打开一本书,读一个随机段落,写一个句子,再读另一个随机段落,再写一个句子。结果会怎样?内容支离破碎,一团混乱,可能上一句还在谈论水母的解剖结构,下一句就开始描述海洋学的历史,仅仅因为这些内容出现在同一页上。
遗憾的是,这正是许多大型语言模型 (LLM) 在使用标准检索增强生成 (RAG) 时的运作方式。它们检索与查询相关的文档,并试图根据找到的所有内容生成答案。问题在于,检索到的文档通常充满噪声;相关事实被埋没在不相关的细节中。这种噪声会导致 LLM 失去焦点,从而引发“焦点转移”,导致模型偏离主题或产生幻觉。
在这篇文章中,我们将深入探讨一种名为 Retrieve-Plan-Generation (RPG) 的新框架。这项研究提出了一种模仿人类专家写作的解决方案: 在开口之前先进行规划 。 我们将探讨 RPG 如何引入迭代式的“计划-然后-回答”循环,使 LLM 严格保持在主题上,以及研究人员如何利用多任务提示微调 (multi-task prompt tuning) 高效地实现这一点。
问题所在: 当 RAG 分心时
要理解 RPG 的创新之处,我们首先需要看看标准 RAG 的局限性。
在典型的 RAG 设置中,当用户提出问题时,系统会在数据库中搜索相关文档。它将这些文档与用户的查询拼接在一起,将整一大块文本输入给 LLM。然后,LLM 被期望忽略噪声并生成完美的答案。
然而,研究表明检索文档中离题的段落可能是有害的。因为 LLM 是基于概率逐个 token 地生成文本,“嘈杂”的输入增加了生成的不确定性。如果一篇关于水母的检索文档提到了一位特定的科学家,LLM 可能会开始讲述那位科学家的传记,而不是解释水母的神经系统。文本生成持续的时间越长,模型偏离原始问题的可能性就越大。
RPG 框架认为,LLM 容易受不相关内容影响的根本原因在于缺乏显式的预先规划 。
核心方法: RPG 框架
Retrieve-Plan-Generation (RPG) 框架从根本上改变了生成过程,将其分解为两个截然不同且交替进行的阶段: 计划阶段 (Plan Stage) 和回答阶段 (Answer Stage) 。
RPG 不是试图吞下文档并一口气写完一篇文章,而是通过这两个阶段进行迭代,直到回答完成。
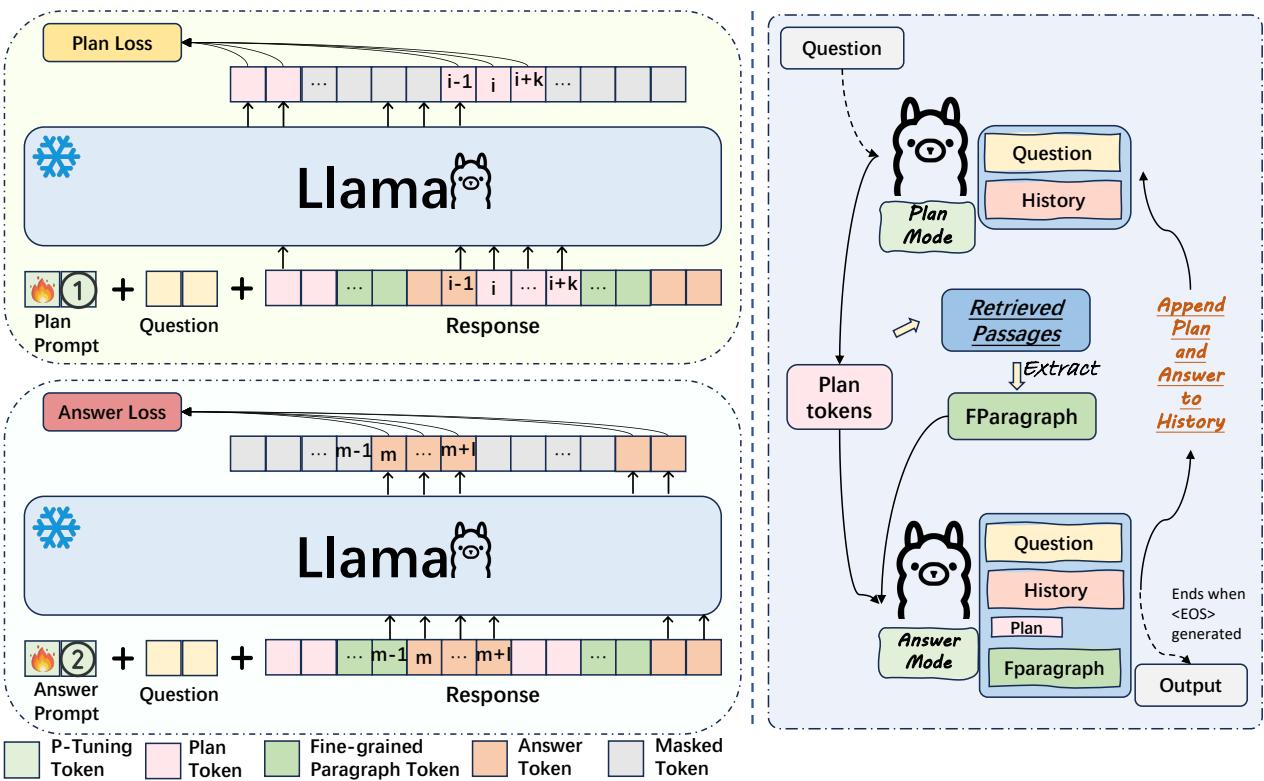
如上图 2 所示,推理过程 (图中右侧) 的工作原理如下:
- 计划阶段: 模型评估当前的上下文并生成“计划 token”。这些不是展示给用户的最终答案的一部分;它们是内部指引,代表模型接下来打算处理的特定子主题 (例如,“水母的身体组成”) 。
- 回答阶段:
- 细粒度筛选: 基于生成的计划,系统扫描检索到的文档。它过滤掉不相关的噪声,仅选择支持当前计划的特定段落或句子。
- 生成: 模型仅使用那些高度相关的证据生成一段回答。
- 迭代: 生成的文本被添加到历史记录中,模型循环回计划阶段以决定接下来写什么。
这个循环一直持续到模型确定回答已完成。通过不断用新计划重新确立基础,模型有效地“重置”了其焦点,防止了困扰标准 RAG 系统的长期漂移问题。
构建数据集: 教模型做计划
实施 RPG 的最大障碍之一是标准数据集并没有附带“计划”。它们通常只有问题 (Q) 和答案 (A) 。为了训练模型进行规划,研究人员必须逆向工程构建一个数据集。
他们利用 ChatGPT 处理现有的数据集,如 HotpotQA 和 Self-RAG。目标是将现有的长答案拆分为片段,并确定每个片段的“计划”或“意图”是什么。

图 3 展示了这个数据构建过程:
- 计划生成: 对于答案的一个特定片段,提示 ChatGPT 总结其意图。这个总结就变成了计划阶段的标签。
- 细粒度证据: 然后给 ChatGPT 提供该计划和原始的粗略文档。要求它仅选择与该计划相关的特定句子。这为回答阶段创建了训练数据。
最终,他们得到了包含 50,000 个样本的高质量数据集,其中每个答案片段都配有特定的计划和特定的证据。
高效训练: 多任务提示微调
从头开始训练一个巨大的 LLM (如 Llama-2 70B) 来处理这种复杂的工作流在计算上极其昂贵。研究人员需要一种方法来教模型两种截然不同的技能——规划和回答——而无需重新训练整个网络。
他们的解决方案是? 多任务提示微调 (Multi-Task Prompt Tuning) 。
他们不更新 LLM 本身的权重,而是冻结 LLM,仅训练一小组前置于输入的“提示向量”。可以将这些视为可学习的指令,告诉模型当前处于哪种“模式”。
他们利用一个包含通用知识的共享软提示 (\(P^*\)) ,以及两个特定任务的低秩矩阵 (\(W_{plan}\) 和 \(W_{ans}\)) ,将共享提示转换为专用提示。
生成特定任务提示 (\(P_{task}\)) 的数学公式为:
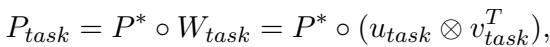
这里,\(task\) 要么是 “plan” (计划) ,要么是 “ans” (回答) 。通过学习这些轻量级矩阵,模型可以瞬间在“规划者”和“回答者”之间切换。
损失函数
在训练过程中,模型查看相同的数据样本,但根据所处的“模式”学习不同的东西。研究人员使用了一种掩码策略,使模型仅关注当前任务的相关 token。
计划损失: 在训练规划者时,模型忽略回答文本,仅计算生成计划 token 的损失。
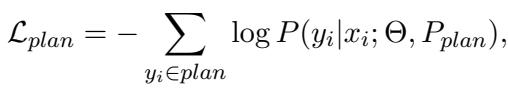
回答损失: 在训练回答者时,模型在给定计划和上下文的情况下,仅计算回答 token 的损失。
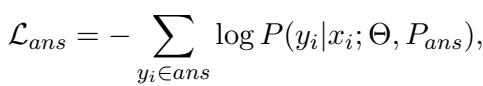
这种多任务方法使得模型能够使用同一个底层冻结的 LLM,同时精通这两项截然不同的任务。
实验与结果
研究人员在 5 个知识密集型任务上评估了 RPG,将其分类为长文本生成 (如撰写详细解释) 、多跳问答 (跨文档推理) 和短文本问答。
他们将 RPG 与几个强基线进行了比较:
- 标准 RAG: 基本的检索-生成方法。
- Self-RAG: 一种最先进的方法,使用反思 token 来评判自身的生成。
- ChatGPT: 包含带检索和不带检索的版本。
长文本生成表现
长文本生成是 RPG 的主战场,因为这是“焦点转移”和幻觉最为普遍的地方。结果令人印象深刻。
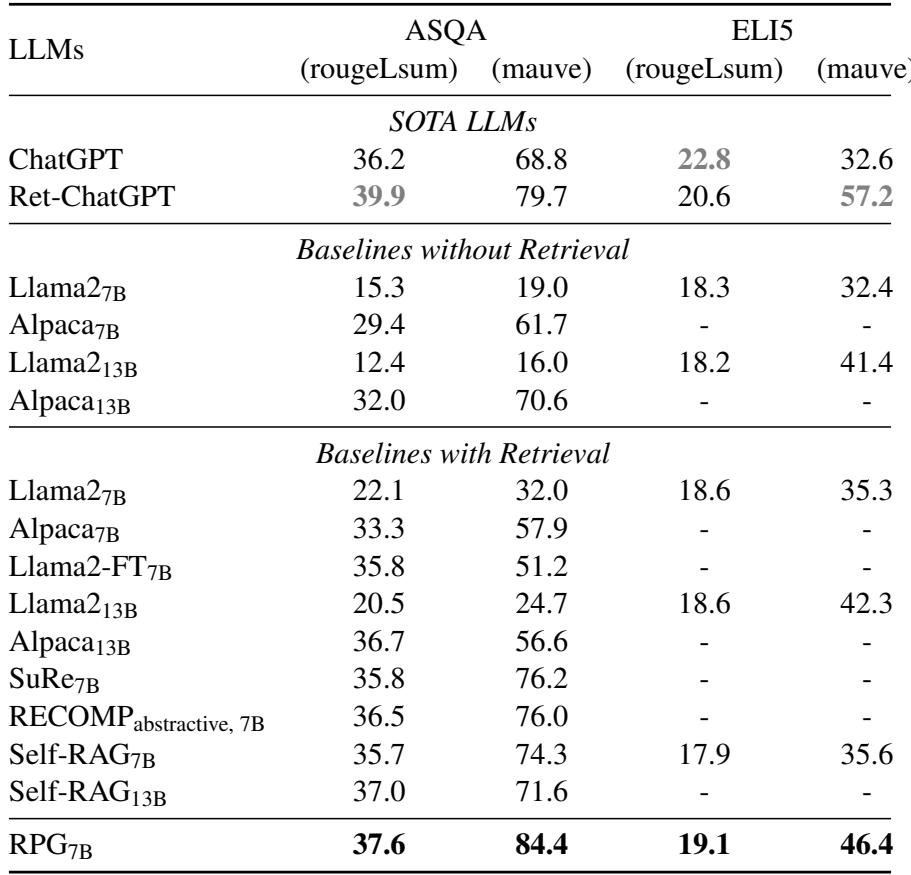
如表 1 所示,RPG 显著优于标准的 Llama-2 基线,甚至在 ASQA 和 ELI5 等数据集上超越了之前的 SOTA 模型 Self-RAG。
- ASQA (歧义问题) : RPG 在事实正确性 (RougeL) 和流畅度 (Mauve) 上均取得了胜利。
- 与摘要方法的比较: 像 “SuRe” 和 “RECOMP” 这样的基线试图在回答之前一次性总结检索到的文档。RPG 优于它们,证明了迭代式规划 (一步步地规划) 优于一次性完成所有规划。
多跳和短文本表现
虽然 RPG 是为长答案设计的,但研究人员想看看规划的额外负担是否有助于更简短、更精确的问题。
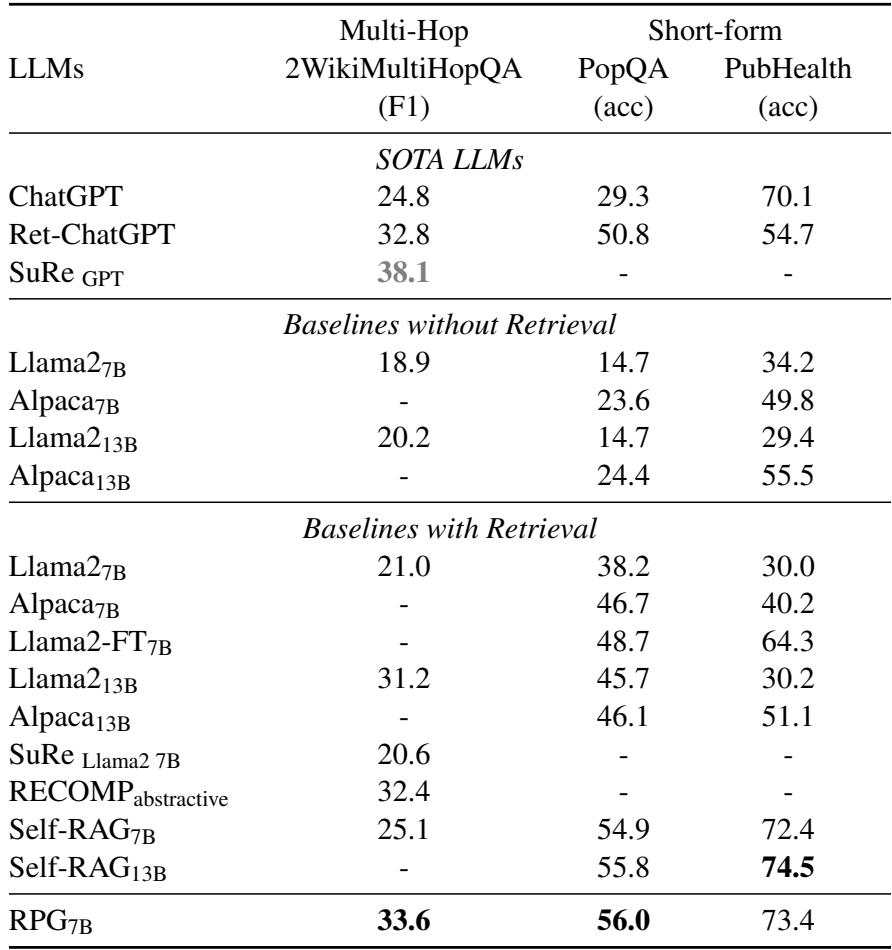
表 2 强调了 RPG 在多跳推理 (2WikiMultiHopQA) 方面也表现出色。这是合理的: 多跳问题需要将点 A 和点 B 连接起来。“计划”阶段有效地充当了桥梁,明确指出“首先我需要找到 X,然后我需要找到 Y”。
有趣的是,即使在短文本问答 (PopQA) 中,虽然答案很简短,RPG 通过有效地过滤掉检索文档中的不相关噪声,依然显示出了强大的性能。
为什么它有效? (消融实验)
为了确保这种性能不是侥幸,研究人员拆解了模型 (消融实验) ,以查看哪些组件最重要。
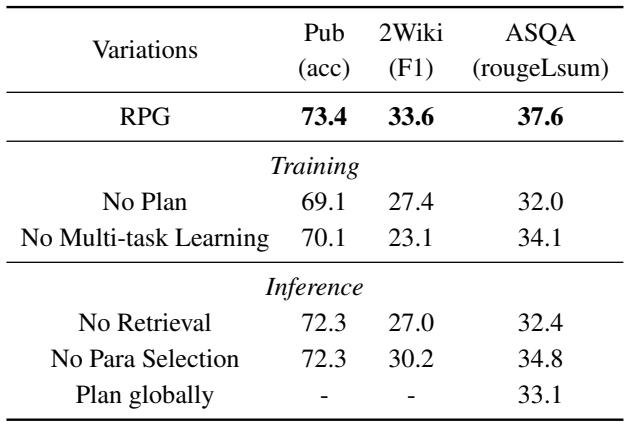
表 3 揭示了关键的见解:
- 无计划 (训练) : 如果从训练数据中移除规划阶段,性能会显著下降 (例如,ASQA 分数从 37.6 降至 32.0) 。这证实了显式的规划步骤是质量的主要驱动力。
- 无段落选择 (推理) : 如果模型生成了计划,但被迫阅读整个检索到的文档 (而不是选择细粒度的段落) ,性能也会下降。这验证了文档中的“噪声”会损害 LLM 性能的理论。
- 迭代式 vs. 全局规划: 研究人员还测试了“全局规划”,即模型在一开始就为整篇文章生成一个庞大的计划。结果表明,迭代式方法 (规划一点,写一点) 更优越。它允许模型在写作过程中进行调整。
扩大规模
最后,训练集的大小重要吗?
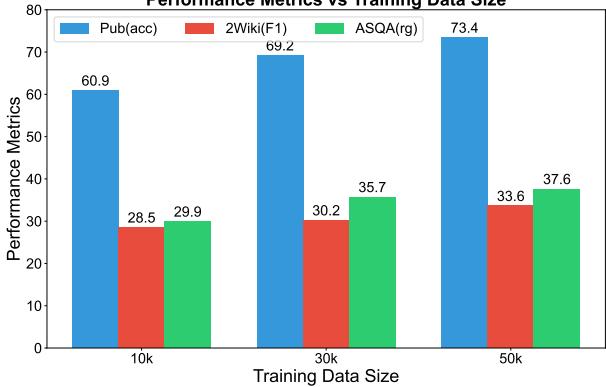
图 4 显示了明显的上升趋势。随着模型在更多数据上进行训练 (从 1 万到 5 万个样本) ,其在所有指标上的表现都在提高。这表明 RPG 框架尚未遇到瓶颈;有了更多数据,它可能会变得更加准确。
结论
Retrieve-Plan-Generation (RPG) 框架为解决大型语言模型“思维游离”的问题提供了一个引人注目的解决方案。通过强制模型在生成每一部分文本之前停下来、制定计划并选择特定证据,RPG 有效地减少了幻觉并使回答严格保持在主题上。
这项研究对学生和从业者特别有价值的一点在于其效率。它不需要重新训练庞大的基础模型。通过巧妙地使用多任务提示微调 , 现有的 LLM 可以经过改造具备这种规划能力,从而使高质量、值得信赖的生成变得更加触手可及。
关键要点是什么?在处理复杂知识时,不要只让 LLM “读和写”。教它去计划。清晰度和准确性的差异是巨大的。