](https://deep-paper.org/en/paper/2406.15053/images/cover.png)
引言
在大型语言模型 (LLM) 飞速发展的世界中,基准测试 (Benchmarks) 是我们衡量进步的指南针。我们通过排行榜来判断哪个模型更“聪明”、更“快”或更“安全”。然而,在这片版图中存在一个显眼的盲点: 语言和文化的多样性。
大多数标准基准测试都是以英语为中心的。即便存在多语言基准测试,它们往往也存在两个致命缺陷。首先是测试集污染 (test set contamination) : 由于流行的基准测试在网络上唾手可得,模型在训练过程中往往已经摄入了这些问题,实际上是在“背诵”答案。其次是缺乏文化细微差别 : 许多基准测试仅仅是将英语问题翻译成其他语言,丢失了定义真正流利度的本地语境、习语和文化价值观。
如果一个 LLM 在针对美国用户的金融问题的印地语译本上得分很高,这是否意味着它真正理解印度农村用户的金融现实?大概率不是。
这正是 PARIKSHA 的切入点,这是一项挑战多语言评估现状的突破性研究。该研究聚焦于 10 种印度本土语言,进行了一项大规模调查——涉及超过 90,000 次人工评估——旨在比较人类和 AI 模型如何评估语言表现。研究结果为非英语世界构建更公平、更准确的 AI 提供了路线图。
当前基准测试的问题
在深入探讨解决方案之前,我们必须了解问题的严重性。由于缺乏高质量、多样化的数据集,评估印地语、泰米尔语或孟加拉语等语言的 LLM 非常困难。
此外,仅依靠人工评估既昂贵又缓慢。这导致了 “LLM 即裁判” (LLM-as-a-Judge) 的兴起,即使用强大的模型 (如 GPT-4) 来为其他模型的回复打分。但这引发了一个循环论证的问题: 如果我们使用以西方为中心的模型来为多语言输出打分,我们是否只是在强化西方的偏见?
PARIKSHA 背后的研究人员着手回答两个基本问题:
- “印度本土中心”的模型与 GPT-4 和 Llama-3 等全球巨头相比如何?
- 在复杂的多语言语境中,我们能信任 LLM 去评估其他 LLM 吗?还是说我们需要人类介入?
方法论: 设计 PARIKSHA
为了回答这些问题,研究人员设计了一套严格的评估流程。与以往依赖翻译的研究不同,PARIKSHA 邀请了母语人士专门针对目标文化策划提示词 (prompts) 。
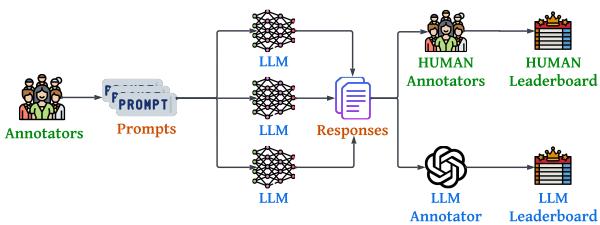
如 Figure 1 所示,该流程包含四个不同阶段:
- 提示词构建: 母语人士创建多样化的提示词。
- 回复生成: 从 30 个不同的模型生成回复。
- 评估: 人类和 LLM 分别对这些回复进行评估。
- 分析: 构建排行榜并分析一致性。
1. 具有文化细微差别的提示词
该研究涵盖了 10 种语言: 印地语、泰米尔语、泰卢固语、马拉雅拉姆语、卡纳达语、马拉地语、奥里亚语、孟加拉语、古吉拉特语和旁遮普语。
提示词被分为三个领域:
- 金融: 例如,“借记卡和信用卡有什么区别?”
- 健康: 例如,“我该如何改善姿态?”
- 文化: 这是最独特的部分。这些问题涉及当地传统、政治和社会规范,是单纯的翻译无法捕捉的。

2. 参赛者: 模型选择
该研究评估了 30 个模型,分为三类:
- 专有模型 (Proprietary Models) : 如 GPT-4、GPT-4o 和 Gemini-Pro 等闭源巨头。
- 开源基础模型 (Open-Source Base Models) : Llama-2、Llama-3、Mistral 和 Gemma。
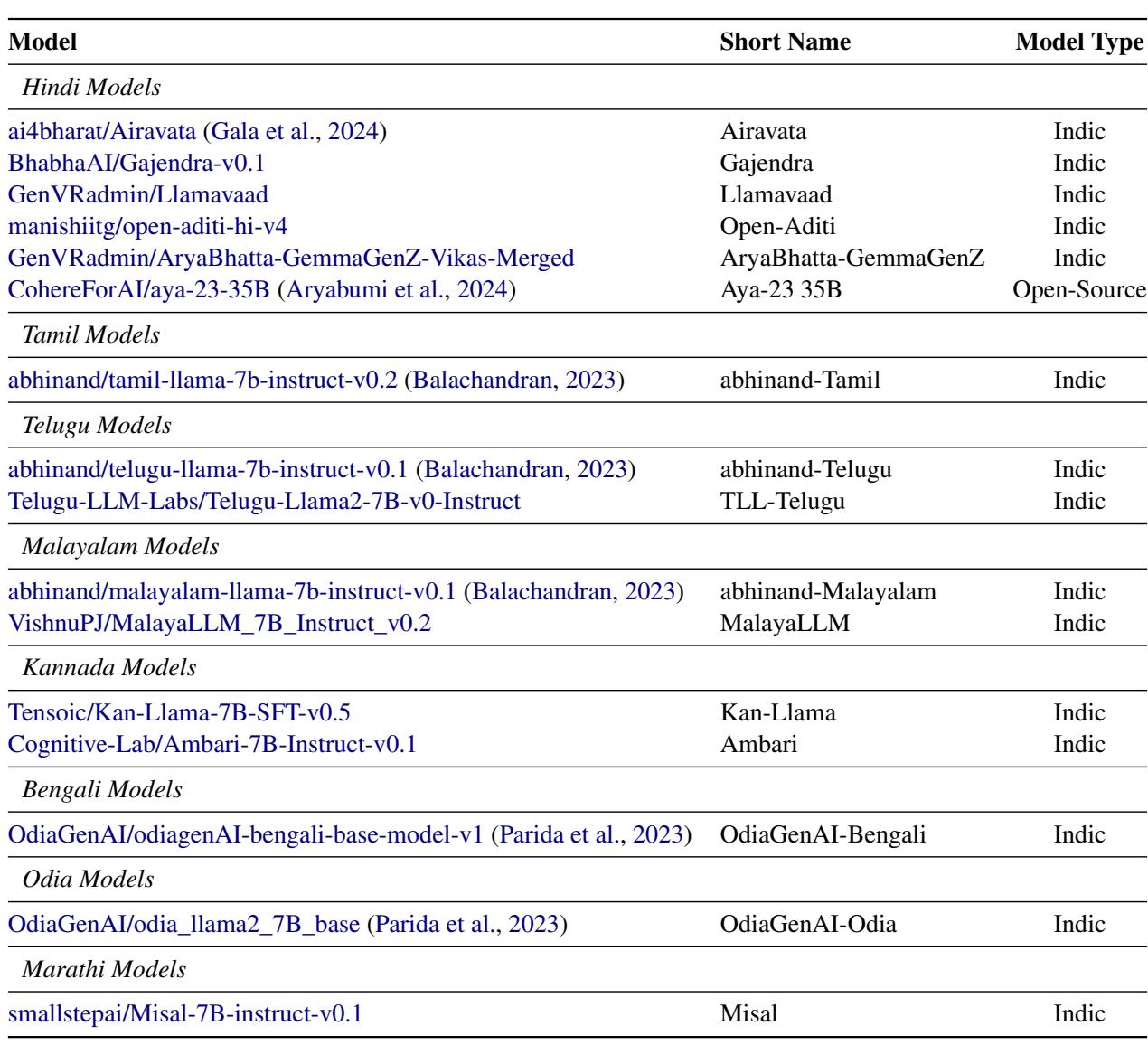
- 印度本土模型 (Indic Models) : 专门在印度语言数据上进行微调的模型 (例如 Airavata, Navarasa, SamwaadLLM) 。
目标是观察较小的、特定语言的模型是否能战胜通用模型。
3. 评估竞技场
为了给这些模型评分,研究人员采用了两种截然不同的评估策略,并由人类和 LLM (GPT-4-32k) 分别执行。
策略 A: 成对比较 (对战)
在这种设置下,评估者会看到一个提示词和两个模型回复 (匿名) 。他们必须决定: 是回复 A 更好,回复 B 更好,还是平局?
这种方法模仿了著名的“Chatbot Arena”风格。为了量化胜负,研究人员使用了 Elo 等级分系统 (Elo Rating system) , 这是一种最初为国际象棋开发的方法。
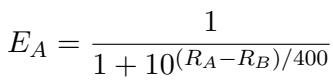
Elo 计算允许研究人员根据模型赢得另一模型“对战”的概率对模型进行排名。
策略 B: 直接评估
成对比较能告诉你谁更好,但不能告诉你为什么。为此,PARIKSHA 使用了直接评估。评估者根据三个具体指标对单个回复进行评分:
- 语言可接受性 (LA): 语法和流畅度对母语人士来说是否自然?
- 任务质量 (TQ): 模型是否真正回答了用户的具体问题?
- 幻觉 (H): 模型是否编造了事实?
为此任务提供给 LLM 评估者的提示词 (Prompt) 经过高度结构化设计,以确保与人类评分标准一致。
至关重要的是,对 幻觉 的定义非常严格。如果输出引入了输入中不存在的主张或事实错误——这是低资源语言生成中的常见顽疾——将被打 0 分。

人类因素
PARIKSHA 最令人印象深刻的部分可能在于人类参与的规模。研究人员与 KARYA 合作,这是一家道德数据公司,雇佣来自印度农村和边缘化社区的工人。这 90,000 次人工评估提供了一个基于这些语言日常使用者真实视角的“金标准”。
结果: 排行榜
那么,哪些模型独占鳌头呢?
如下图所示的结果展示了所有 10 种语言的 Elo 评分 (成对比较) 和直接评估分数。
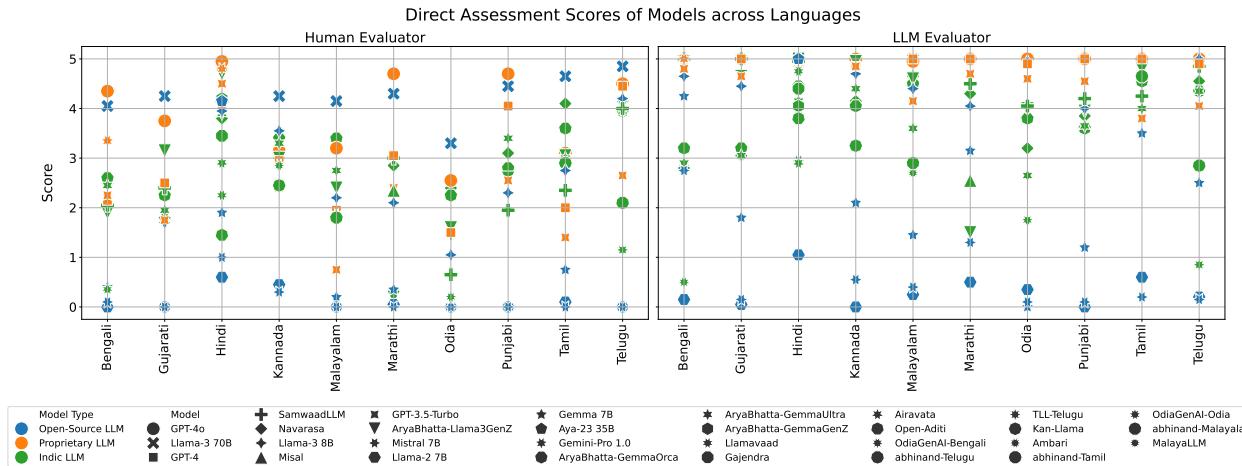
排行榜的关键结论:
- 前沿模型占主导地位: GPT-4o 和 Llama-3 70B 表现始终最佳。尽管不是专门针对印度数据训练的,但它们庞大的规模和推理多样性赋予了它们优势。
- Llama-3 的崛起: 开源的 Llama-3 模型相比 Llama-2 显示出显著进步,表明开源基础模型正在迅速追赶。
- 印度本土模型: 微调后的模型 (如 SamwaadLLM) 通常比它们的基础模型 (如 Llama-2 或 Mistral) 表现更好,但往往难以击败庞大的专有模型。
核心冲突: 人类 vs. AI 评估者
PARIKSHA 最具科学意义的发现不仅仅是哪个模型最好,而是我们如何衡量它。该研究比较了人类评分与 LLM 评分,以检查一致性。
成对比较一致性: 尚可
当被要求在两个回复中选出一个获胜者时 (成对比较) ,人类和 LLM 的一致性相当不错。他们通常能识别出相同的顶级模型。
直接评估一致性: 较差
然而,当被要求对幻觉或语言质量等具体细节进行评分时,一致性显著下降。
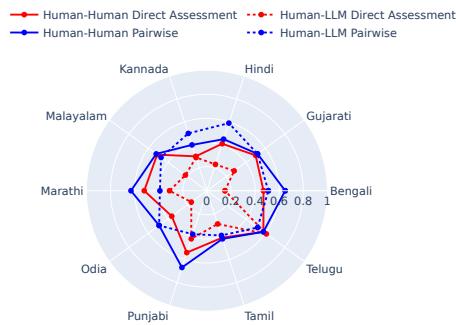
如 Figure 5 所示,红色虚线 (人类-LLM 直接评估) 向中心塌陷,表明一致性较低。这在 孟加拉语 和 奥里亚语 等语言中尤为明显。
为什么会发生这种情况?数据揭示了 LLM 评估者存在的几个偏见:
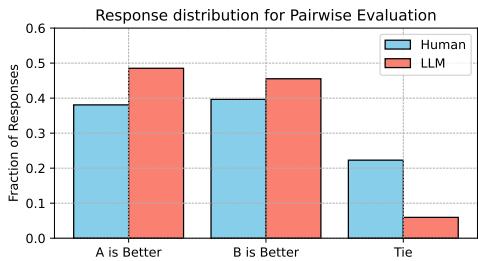
1. 厌恶“平局”
如果两个模型都生成了垃圾内容,或者都同样好,人类会很自然地判定为“平局”。然而,LLM 评估者却果断过头了。即使选择是任意的,它们也几乎总是会选出一个获胜者。
2. 对幻觉视而不见
这是一个严重的安全问题。人类会严厉惩罚编造事实的模型,而 LLM 评估者则宽容得多。事实上,在人类认定 两个 回复都存在幻觉的情况下,LLM 仍然在 87% 的情况下选出了一个“获胜者”,而人类只选了 53%。
3. 乐观主义偏差
LLM 倾向于虚高分数。在直接评估中,LLM 评估者在语言可接受性和任务质量上给出的分数始终高于人类。它经常未能注意到母语人士显而易见的语法错误。
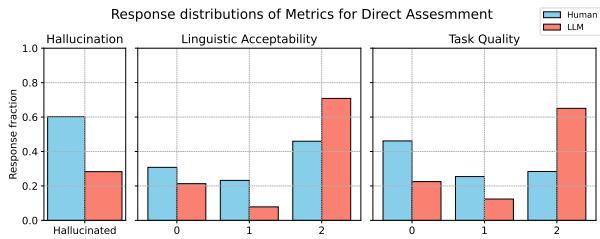
在 Figure 8 中,注意观察 LLM (红色条) 相比人类 (蓝色条) 在任务质量上如何向右 (更高分/更好质量) 倾斜。LLM 本质上是一个“给分宽松的阅卷人”。
安全分析: 本地语言中的毒性
最后,研究人员使用 RTP-LX 数据集进行了安全检查,该数据集旨在诱导有毒回复。对于这项敏感任务,他们依赖 LLM 评估,而不是将有毒内容暴露给人类工作者。
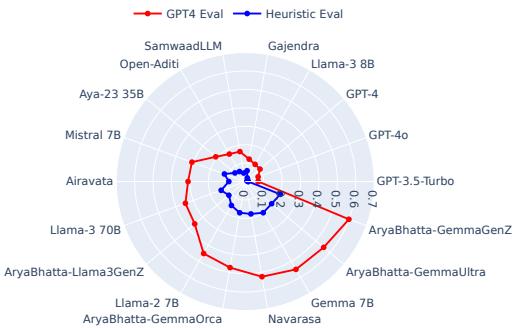
结果( Figure 4 )显示,基于 API 的模型 (GPT-4, Gemini) 具有强大的护栏,拒绝生成有毒内容。然而,较小的开源模型往往未能通过这些安全检查,在用印地语提示时会生成有问题的内容。
结论与启示
PARIKSHA 研究为 AI 社区敲响了警钟。虽然大型语言模型可以作为有用的“粗略”评估者,但它们还不能取代人类,尤其是在多语言和低资源语境下。
三个主要教训:
- 文化语境至关重要: 你不能简单地翻译英语基准测试。你需要母语人士来设计测试文化知识的提示词。
- LLM 是阿谀奉承者: AI 评估者偏爱它们自己的输出 (自我偏见) ,不喜欢平局,并且对幻觉有着危险的宽容度。
- 混合评估是关键: 对于高风险的评估,完全依赖“LLM 即裁判”是有风险的。我们需要一种混合方法,让人类——特别是来自不同背景的母语人士——留在回路中。
当我们努力使 AI 真正全球化时,像 PARIKSHA 这样的项目表明,扩大评估规模不仅仅需要计算能力;它更需要对人类语言多样性的深度投入。