](https://deep-paper.org/en/paper/2406.15657/images/cover.png)
引言
在信息检索 (IR) 飞速发展的领域,大型语言模型 (LLM) 的引入一直是一把双刃剑。一方面,LLM 拥有理解细微差别、上下文和意图的非凡能力,使其能够以前所未有的准确度对搜索结果进行排序。另一方面,它们计算昂贵且速度缓慢。
传统上,当我们要求 LLM 对文档列表进行排序 (这一过程称为列表级重排序 , Listwise Reranking) 时,模型就像一位作家。它阅读文档,然后生成一系列文本输出,例如“文档 A 优于文档 C,文档 C 优于文档 B”。这种生成过程是顺序的,且非常耗时。
但是,如果模型在开始生成的那一刻本质上就已经“知道”了排名呢?如果我们能从模型预测的第一个 Token 中提取出完整的排名,而不需要等待它写出整个列表呢?
这就是 FIRST (Faster Improved Re-ranking with a Single Token) 的前提,这是由伊利诺伊大学厄巴纳-香槟分校和 IBM Research 的研究人员提出的一种新颖方法。在这篇文章中,我们将剖析他们的研究论文,探讨他们如何在不牺牲——甚至往往能提高——排序性能的情况下,将推理延迟降低 50%。
背景: 神经搜索的瓶颈
要理解 FIRST 的重要性,我们首先需要看看神经搜索的现状。现代搜索系统通常采用两阶段的流水线:
- 检索器 (Retriever): 一个快速、轻量级的模型 (如 BM25 或像 Contriever 这样的密集检索器) 从数百万个文档中筛选出一小部分潜在相关的候选文档 (例如前 100 个) 。
- 重排序器 (Reranker): 一个更强大、计算更密集的模型会检查这些顶级候选文档,并重新排序,将最相关的文档推到顶部。
从交叉编码器到列表级 LLM
很长一段时间以来,“重排序器”阶段由交叉编码器 (Cross-Encoders) 主导。这些模型接收一个查询和一个单个文档,将它们一起处理,并输出一个相关性分数。虽然有效,但它们有局限性,因为它们是孤立地对文档进行评分。它们无法直接将文档 A 与文档 B 进行比较。
于是列表级 LLM 重排序 (Listwise LLM Reranking) 出现了。最近的方法,如 RankZephyr,将查询和一个包含多个文档的列表 (例如一次 20 个) 输入到 LLM 中。LLM 被指示按相关性递减的顺序输出文档标识符。
这允许模型进行全局比较,从而产生更好的排名。然而,它将问题视为一个文本生成任务 。 模型必须生成一系列代表文档 ID 的 Token (例如 [Doc1] > [Doc3] > [Doc2]) 。
问题在哪? 延迟。 LLM 的生成是自回归的——它一次生成一个 Token。文档越多,输出序列越长,系统就越慢。此外,这些模型的标准训练对每个错误一视同仁。如果模型交换了第 1 和第 2 个文档,其受到的惩罚通常与交换第 19 和第 20 个文档相同,尽管前者对搜索体验是灾难性的,而后者几乎可以忽略不计。
核心洞察: “顿悟”时刻
FIRST背后的研究人员从一个假设开始: LLM 重排序器在显式生成序列之前,就已经隐式地判断了相关性。
当 LLM 预测下一个 Token 时,它会计算其整个词汇表上的概率分布 (Logits) 。如果模型即将生成排名第一的文档的标识符,那么所有文档标识符的 Logits 理论上都应该反映它们的相对相关性。
为了验证这一点,研究人员将预训练的 LLM 与 RankZephyr (经过微调用于排序的 LLM) 进行了比较。他们检查了由第一个 Token 的 Logits 暗示的排名是否与完全生成的文本序列的排名相匹配。
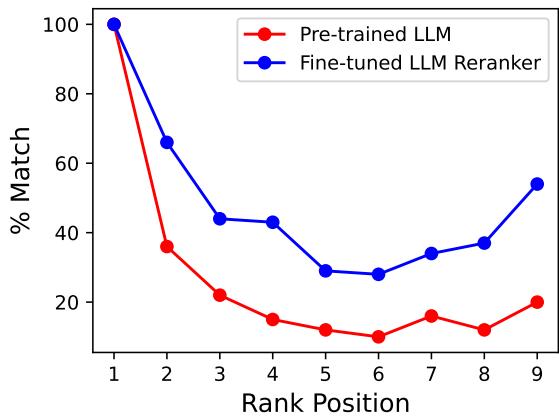
如图 2 所示,蓝线代表 RankZephyr。我们可以看到第一个 Token 的 Logits 所暗示的排名与最终生成的序列之间存在高度相似性。这证实了模型在生成的最初步骤本质上就已经“知道”了相关性的顺序。随后的序列生成可以说是多余的。
方法论: FIRST (Faster Improved Re-ranking with a Single Token)
基于这一洞察,作者提出了一种新的架构,从“生成方法”转变为“FIRST 方法”。
1. 单 Token 解码
该机制简单而优雅。FIRST 不要求模型生成像 “A > B > C” 这样的字符串,而是输入查询和文档,并仅查看生成步骤第一步中文档标识符 (A, B, C 等) 的输出 Logits。
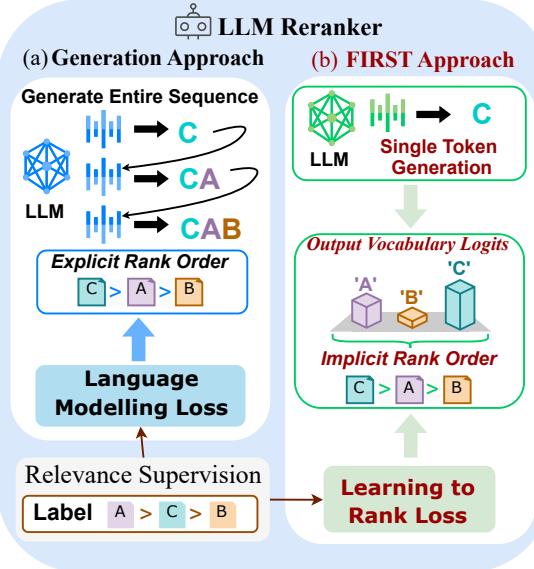
如图 1 所示, 生成方法 (a) 依赖于生成完整序列的缓慢过程。 FIRST 方法 (b) 在第一遍后立即停止。它提取对应于文档 ID (A, B, C) 的 Logits,并根据这些分数对文档进行排序。
关于标识符的说明: 研究人员使用字母标识符 (A, B, C…) 而不是数字。这是因为 LLM 分词器通常会将多位数字 (如 “10” 或 “100”) 分解为多个 Token,这会使单 Token 解码策略变得复杂。
2. 更好的训练目标
虽然标准的 LLM 可以用于 FIRST 推理,但它并没有为此进行优化。标准 LLM 是使用语言建模 (LM) 目标训练的,该目标旨在最小化预测下一个 Token 的误差。
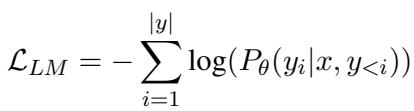
这种标准损失 (上面的公式 1) 对于排序有两个主要缺陷:
- 均匀性: 它平等地对待序列中的所有位置。
- 硬目标: 它通常强迫模型最大化唯一正确的下一个 Token 的概率,将所有其他概率推向零。这破坏了我们想要在 Logits 中捕获的丰富相对信息 (即,我们希望模型表达 A 是最好的,但 B 是第二好的,而不仅仅是“A 是 100%,其他都是 0%”) 。
为了解决这个问题,作者引入了专门为第一个 Token 的 Logits 设计的学习排序 (Learning-to-Rank, LTR) 目标。他们使用了 RankNet 的加权版本。
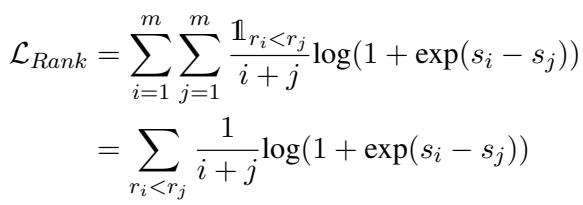
让我们拆解上面的公式:
- \(s_i\) 和 \(s_j\) : 这些是文档 \(i\) 和文档 \(j\) 的输出 Logits。
- Log-sigmoid 项 : 这鼓励模型给更相关的文档 (\(r_i < r_j\)) 更高的分数。
- \(\frac{1}{i+j}\) : 这是关键的加权项。它是该对文档平均排名的倒数。
为什么加权很重要: 如果模型混淆了第 1 个和第 2 个文档,\(i+j = 1+2 = 3\),所以权重是 \(1/3\)。如果它混淆了第 19 和第 20 个文档,权重是 \(1/39\)。这意味着损失函数对列表顶部的错误的惩罚要比底部的错误重得多 。 这与搜索引擎的目标完美契合: 用户很少查看前几个结果之后的内容。
最后,研究人员将标准语言建模损失 (以保持模型的语言能力) 与这个新的排序损失结合起来:
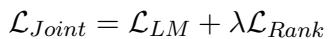
超参数 \(\lambda\) 控制两个目标之间的平衡。
实验与结果
研究人员使用这个新目标在 MS MARCO 数据集上微调了一个 Zephyr-7B 模型,并在综合性的 BEIR 基准测试上进行了评估。
这种训练策略有效吗?
第一个问题是新的损失函数是否真的有帮助。下表使用 nDCG@10 (排序质量的标准指标) 比较了不同的训练策略。
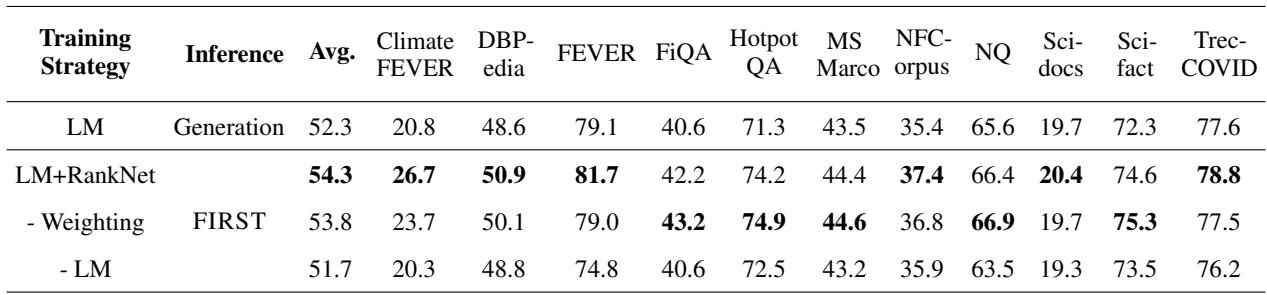
表 2 中的结果很明确:
- LM (标准生成): 平均 52.3%。
- FIRST (LM + RankNet): 平均 54.3%。
通过添加排序损失,模型不仅变得与单 Token 解码兼容,而且实际上优于序列生成基线。消融实验还表明, 加权机制 (优先考虑顶部排名) 是必不可少的;没有它,性能会下降。
它更快吗?
这是 FIRST背后的主要动力。由于模型只生成一个 Token 而不是长度为 \(N\) 的序列,延迟的减少应该是显著的。
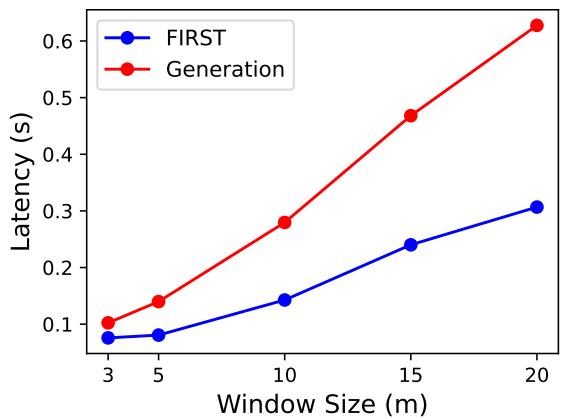
图 4 证实了这一点。随着窗口大小 (候选数量) 的增加,生成方法的延迟急剧上升,因为它必须写出更多的标识符。然而,FIRST 保持得非常平稳。FIRST 增加的唯一成本来自于处理更长的输入提示,而不是来自于生成。
延迟与准确性的权衡
在现实世界的系统中,我们通常有一个“延迟预算” (例如,“在 200ms 内返回结果”) 。更快的模型允许我们在相同的时间预算内重排序更多的文档。
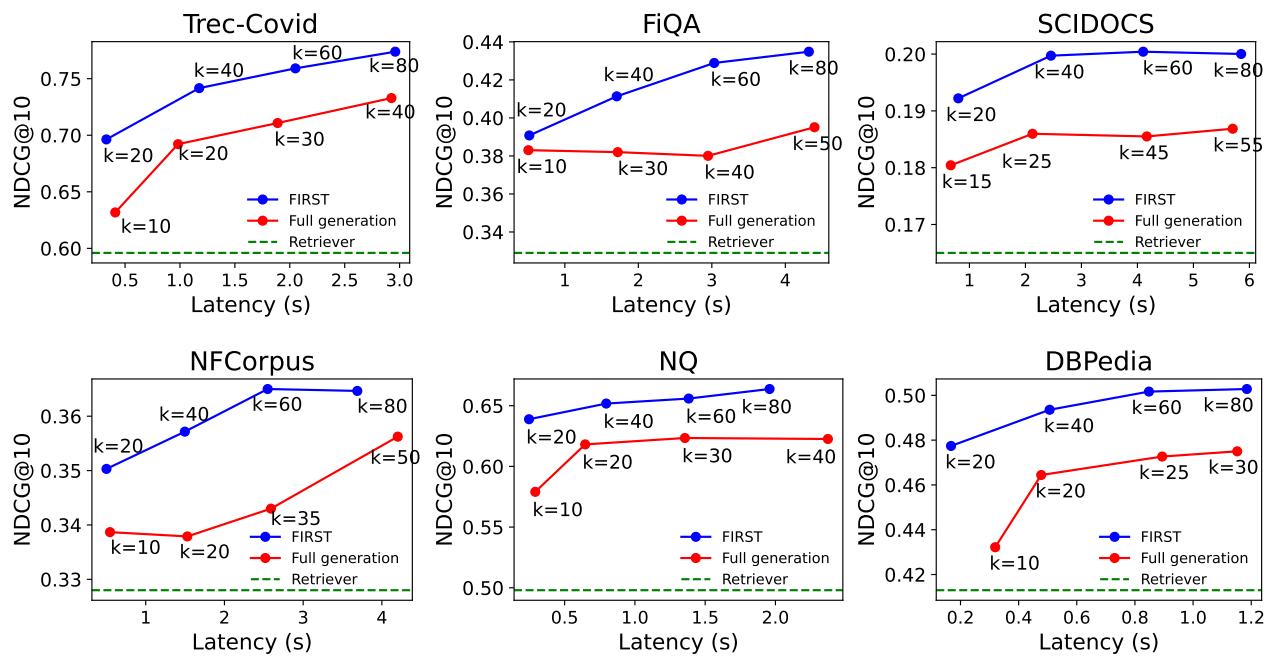
图 3 也许是论文中最令人信服的可视化。它绘制了准确性 (y 轴) 与延迟 (x 轴) 的关系。
- 蓝线 (FIRST): 陡峭上升并迅速达到高准确度。
- 红线 (完全生成): 上升缓慢。
因为 FIRST 非常高效,你可以在标准模型重排序一个小列表所需的相同时间内,重排序一个更大的候选列表 (增加 \(k\)) 。这导致在任何给定的延迟阈值下,准确性始终更高。
高级应用: 相关性反馈
作者探索了最后一个引人入胜的应用: 相关性反馈 (Relevance Feedback) 。
在这种设置中,重排序器的输出用于在推理期间“教导”或更新初始检索器 (如 Contriever) 的查询向量。其想法是将重型重排序器的智能蒸馏回快速检索器中,以找到在第一遍中可能被遗漏的文档。
标准方法使用交叉编码器 (CE) 的分数来做到这一点。然而,作者发现使用他们的列表级 LLM 的排名信号提供了更好的监督。
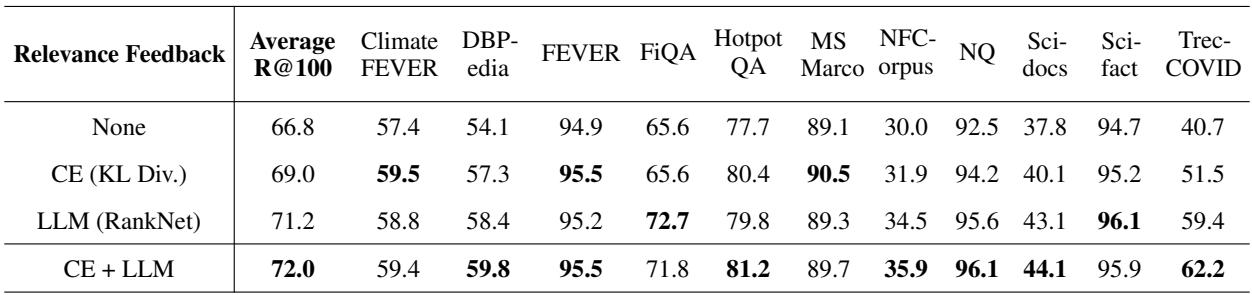
表 4 显示了 Recall@100 (找到了多少相关文档) 。
- None (原始检索器): 66.8%
- CE 反馈: 69.0%
- LLM (FIRST) 反馈: 71.2%
- CE + LLM: 72.0%
使用 FIRST 目标训练的 LLM 重排序器为优化搜索查询提供了比传统交叉编码器更强的信号,导致召回率大幅提升。
结论
“FIRST” 论文提出了一个令人信服的论点,让我们重新思考如何在搜索中使用大型语言模型。通过认识到模型的内部状态 (Logits) 在文本生成之前很久就包含了排名信息,作者解锁了 50% 的速度提升。
此外,通过摆脱通用的语言建模损失并采用学习排序 (Learning-to-Rank) 目标,他们证明了我们可以训练出关注搜索中真正重要事项的模型: 正确获取顶部结果。
对于 NLP 和信息检索领域的学生和从业者来说,FIRST 突显了一个重要趋势: 我们正在超越简单地将“开箱即用”的 LLM 应用于特定任务。我们现在正在打开黑盒,检查 Logits,并设计自定义损失函数,将这些强大的模型塑造成高效的、特定领域的工具。