](https://deep-paper.org/en/paper/2406.15718/images/cover.png)
你有没有尝试过打断语音助手?通常情况是这样的: 你问了一个问题,说到一半意识到自己说错了,但 AI 忽略了你的更正,继续处理你的第一个请求。你不得不等它说完长长的独白,或者疯狂地点击“停止”按钮,才能再次尝试。
这种尴尬的互动之所以发生,是因为目前几乎所有的大型语言模型 (LLM) 都是基于回合制机制运作的。你说话,模型等你把话说完,然后处理,最后它再说话。这就相当于使用对讲机进行数字交流 (“完毕”) 。
然而,人类的对话是一个全双工 (duplex) 的过程。我们在思考的同时倾听。我们在观察对方反应的同时说话。我们会打断、插话,并实时调整我们的想法。
在清华大学的一篇引人入胜的新论文中,研究人员提出了一种弥合这一差距的方法。他们介绍了全双工模型 (Duplex Models) , 这是一个允许 LLM 同时听和说的框架,能在不改变模型基本架构的情况下实现自然的实时交互。
在这篇文章中,我们将深入探讨他们是如何实现这一点的,“时间片”背后的巧妙工程,以及他们如何训练模型知道何时该闭嘴。
问题所在: 回合制的瓶颈
目前的聊天机器人的行为就像电子邮件往来: 它们需要一条完整的消息才能生成回复。用技术术语来说,模型在生成单个 token 之前,必须将用户的整个提示编码到键值缓存 (Key-Value Caches) 中。这就造成了一种僵化的结构,即一方活动时,另一方必须处于空闲状态。
在现实生活中,如果你向朋友寻求书籍推荐,然后立即说: “其实算了,我想看电影”,你的朋友会立刻停止思考书籍,转而思考电影。然而,标准的 LLM 已经被锁定在“书籍”的路径上,直到它完成这一回合。
为了解决这个问题,研究人员开发了一种时分复用 (Time-Division-Multiplexing, TDM) 策略。
核心方法: 时分复用
研究人员并没有发明一种新型的 Transformer,而是重新发明了数据输入的方式。他们不再等待完整的句子,而是将对话切分为时间片 (Time Slices) 。
切片如何工作
这个概念借鉴了电信领域。模型以微小、快速的增量处理输入并生成输出——具体来说,每 2 秒 (大约 4-6 个单词) 一次。
- 输入切片: 用户的语音/文本被切成一个小片。
- 处理: 模型立即处理这个切片。
- 输出决策: 模型决定是生成文本 (说话) 还是生成一个特殊的
<idle>token (保持沉默) 。
如果在模型生成过程中有新的输入到达,它不会等待。它会停止当前的生成,整合新的切片,并立即调整其输出。
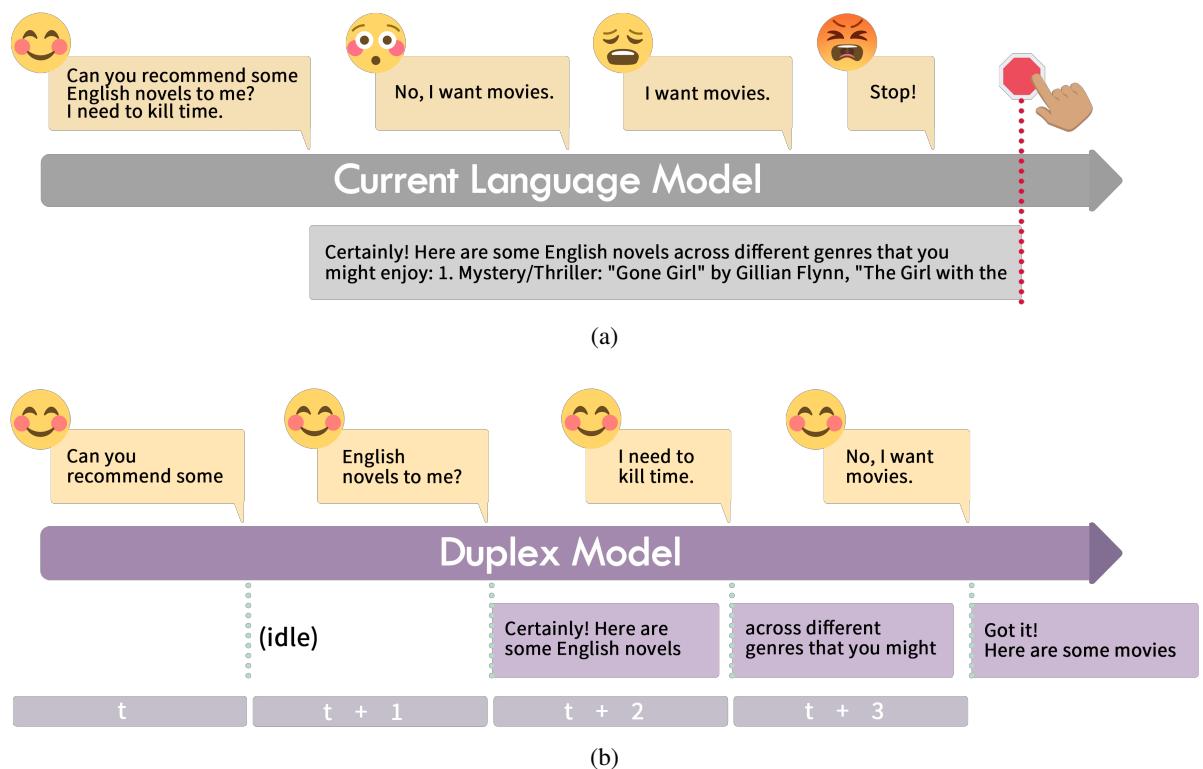
如上方的 图 1 所示,区别是显而易见的:
- 传统模型 (1a): 用户要求推荐小说。尽管他们后来更正为“电影”,但模型已经致力于推荐小说。用户不得不强制停止。
- 全双工模型 (1b): 在时间 \(t+2\),模型开始回答关于小说的问题。但在 \(t+3\),当它听到“不,我想要电影”时,它立即转向。它本质上是在“说话”的同时进行“倾听”。
挑战: LLM 讨厌碎片
你可能会想: 为什么我们不能直接把小块的文本喂给 GPT-4 呢?
问题在于,标准的 LLM 是在完整的文档上训练的。如果你给它们喂一个句子片段,它们会产生幻觉,或者试图在语法上补全句子,而不是充当一个有用的助手。
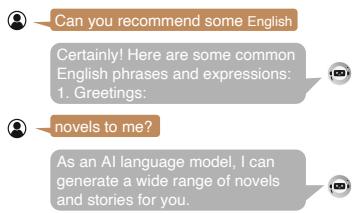
图 2 展示了这种失败模式。当一个标准模型 (MiniCPM) 被喂入像“你能推荐”这样的切片时,它不会等待剩下的部分。它开始生成随机的问候语或不相关的短语,因为它不理解“停顿”的语境。
为了解决这个问题,研究人员必须教模型一项新技能: 全双工对齐 (Duplex Alignment) 。
训练模型: Duplex-UltraChat 数据集
研究人员创建了一个名为 Duplex-UltraChat 的专用数据集来微调模型。这个数据集教会 LLM,有时候,正确的反应是什么都不做 (输出 <idle>) 。
他们采用了现有的对话数据集 (如 UltraChat) ,并对其进行了深度改造以模拟实时的混乱场景。他们将消息拆分为时间片,并注入了各种交互类型。
1. 沉默的艺术 (无打断对话)
全双工模型需要的最基本技能是耐心。如果用户的句子不完整,模型不应该猜测;它应该等待。
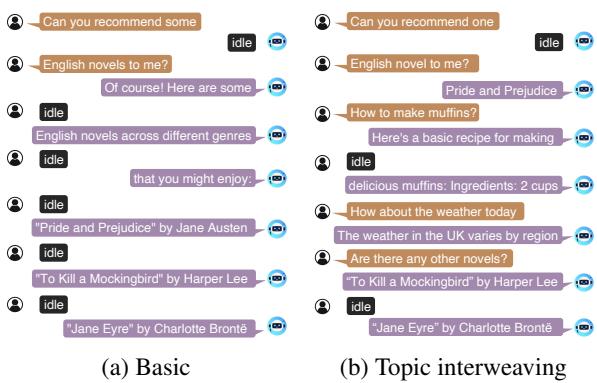
在 图 3 中,你可以看到“基础”结构。用户的输入被拆分到多个回合中。模型针对初始切片的目标输出是 <idle>。只有当用户的意图清晰时,它才会生成书籍推荐。
2. 处理打断
这是数据集变得有趣的地方。研究人员模拟了用户打断 AI 的场景。他们定义了几种打断类型:
- 生成终止 (Generation Termination) : 用户实际上是在说“闭嘴”。模型必须学会立即停止生成。
- 重新生成 (Regeneration) : 用户在句子中间更改了约束条件 (例如,“等一下,我是指科幻小说”) 。
- 对话重置 (Dialogue Reset) : 用户突然完全改变了话题 (例如,“其实,天气怎么样?”) 。
- 回归主题 (Back on Topic) : 用户打断以提出一个澄清性问题,模型回答该问题,然后无缝回归到原始主题。
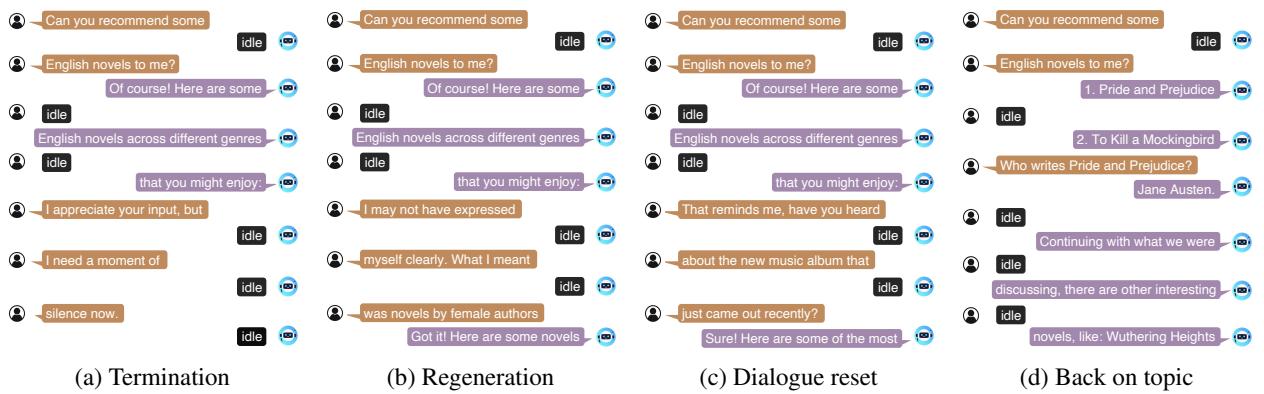
图 4 直观地展示了这些场景。请看图 (b) “重新生成”。用户打断了推荐列表,澄清他们想要女性作者的小说。模型捕捉到了这个打断切片,并立即调整了建议。这模仿了两个人交谈时的流畅动态。
实验与结果
团队使用这个新数据集训练了一个名为 MiniCPM-duplex 的模型 (基于轻量级的 MiniCPM-2.4B) 。然后,他们将其与原始模型进行对决,看看“全双工”能力是否真的改善了用户体验。
切片会损害智能吗?
一个主要的担忧是,将输入切成微小的碎片可能会使模型“变笨”或导致其丢失上下文。
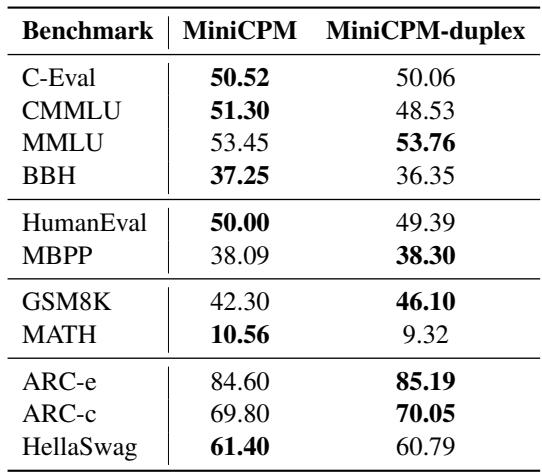
令人惊讶的是, 表 2 显示全双工微调对通用能力的影响微乎其微。在 MMLU (知识) 和 GSM8K (数学) 等基准测试中,分数几乎保持一致。模型获得了实时聊天的能力,而没有降低其智商。
人工评估: 真正的考验
由于“聊天流畅度”很难用数学来衡量,研究人员进行了一项用户研究,参与者通过语音与两个模型进行互动。
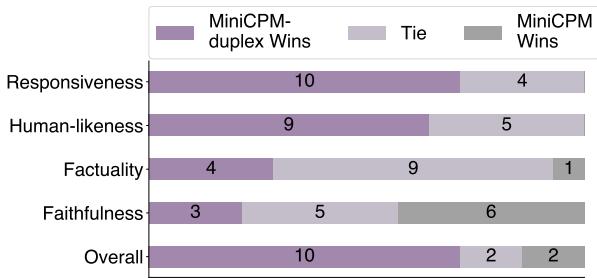
图 6 中的结果是戏剧性的。
- 响应性: 全双工模型获胜 10 次,而标准模型仅获胜 4 次。
- 拟人性: 全双工模型被压倒性地认为更像人类。
- 整体: 用户更频繁地偏好全双工体验。
分数的分布进一步突显了这种转变。
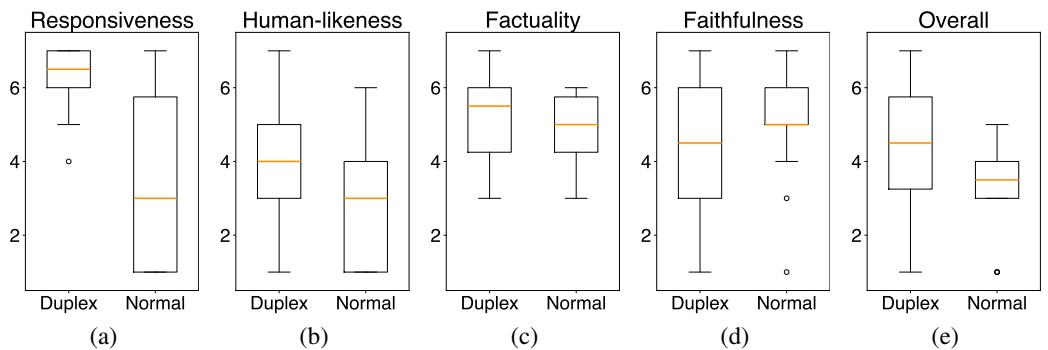
在 图 5 中,注意“响应性”(a) 和“拟人性”(b) 的箱线图。全双工模型的橙色中位线明显高于普通模型。用户感觉他们是在进行对话,而不是向终端下达指令。
案例研究
为了看到实际效果,我们来看看作者提供的案例研究。
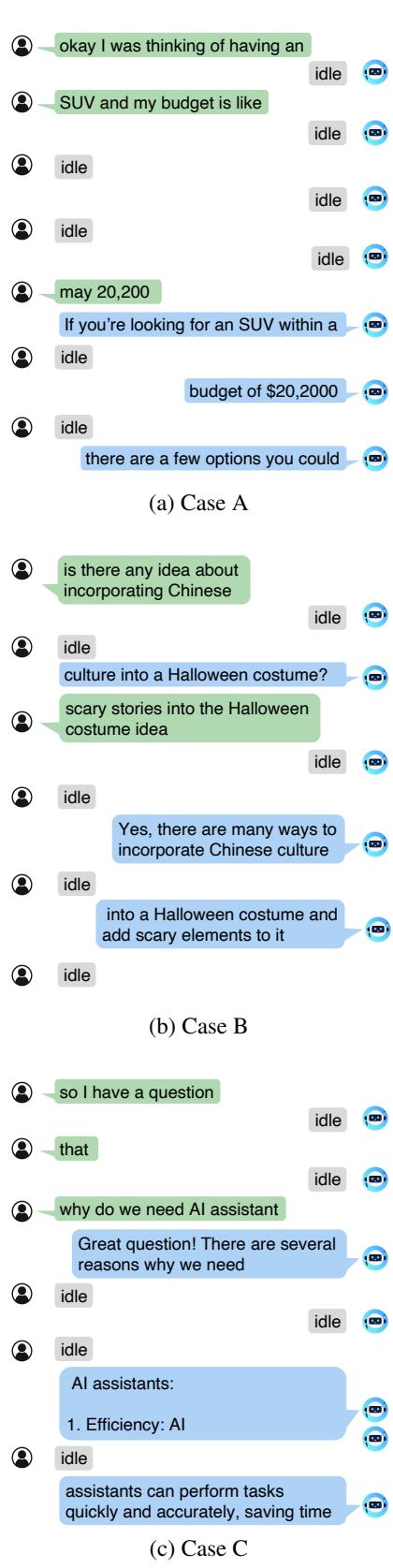
在 图 7 中,案例 B 展示了该系统的细微之处。用户询问关于万圣节服装的“中国文化”。当用户进行详细说明时,模型在倾听的同时立即将特定的文化约束整合到建议列表中。
结论与未来展望
聊天机器人的“回合制”性质长期以来一直被认为是 AI 的一个可接受的局限,但这篇论文证明了事实并非如此。通过将对话视为时间片流而不是完整段落的乒乓球比赛, MiniCPM-duplex 让我们离 AI 的圣杯更近了一步: 一个你可以像朋友一样自然交谈的智能体。
关键要点:
- 全双工 vs. 回合制: 实时交互需要模型能够伪同步地处理输入并生成输出。
- 空闲令牌 (The Idle Token) : “倾听” (输出沉默) 的能力与生成文本的能力同样重要。
- 数据为王: 标准数据集不适用于此。我们需要像 Duplex-UltraChat 这样包含打断、犹豫和话题转换的数据集。
虽然仍有挑战——特别是关于需要平滑处理断断续续输出流的文本转语音 (TTS) 系统——但这项研究为下一代语音助手奠定了基础。很快,你的 AI 界面上的那个“停止”按钮可能就会成为过去的遗物。