](https://deep-paper.org/en/paper/2406.16078/images/cover.png)
当你面对一个需要多步解决的复杂问题时,你会如何处理?
心理学研究表明,人类通常从“启发式 (heuristics) ”——即心理捷径或浅层联想——开始。如果你在找钥匙,你可能会先看厨房柜台,仅仅因为“钥匙经常放在那里”,而不是因为你记得把它们放在那里。然而,当你排除了选项并接近解决方案时,你的思维会发生转变。你会变得更加理性,推断出你最后一次出现在哪里。
大型语言模型 (LLM) 的行为方式是否相同?
我们通常认为 LLM 要么“聪明”,要么在“产生幻觉”,但最近的研究表明,它们的推理过程比这更具动态性。一篇题为 “First Heuristic Then Rational” 的引人入胜的论文,由来自东北大学 (Tohoku University) 、理化学研究所 (RIKEN) 和 MBZUAI 的研究人员撰写,调查了这一问题。
他们的发现揭示了 GPT-4 和 PaLM2 等模型在推理中的系统性策略: 它们在解决问题的早期阶段严重依赖懒惰的捷径,但随着接近答案,它们会转向理性的、基于逻辑的推理。
在这篇文章中,我们将剖析他们的方法论、“推理距离”的概念,以及这对 AI 的未来意味着什么。
多步推理的问题
多步推理是当前 AI 开发的圣杯。像“思维链” (Chain-of-Thought, CoT) 提示这样的技术——要求模型“一步步思考”——显著提高了性能。然而,模型在需要长逻辑链的任务上仍然经常失败。它们经常被不相关的信息或肤浅的模式分散注意力。
研究人员假设这种失败并非偶然。他们提出 LLM 的“前瞻 (lookahead) ”能力有限。当通往解决方案的路径很长且目标遥远时,模型无法有效地规划整个路线。因此,它会恐慌并抓住最近的启发式方法 (捷径) 。随着推理的进行,通往目标的距离缩短,模型“醒悟”过来并开始理性行事。
定义启发式方法
为了验证这一点,研究人员专注于三种特定类型的启发式方法——这些通常会欺骗模型的表面偏见:
- 词汇重叠 (OVERLAP) : 仅仅因为信息与问题共用单词就选择该信息的倾向。如果问题问的是“Judy”,模型可能会抓取包含“Judy’s mother”的句子,即使它是不相关的。
- 位置偏差 (POSITION) : 基于信息在文本中出现的位置 (例如第一句话) 来关注信息的倾向。
- 否定 (NEGATIVE) : 与模型如何处理 (或避免) 像“not”这样的否定词相关的偏差。
研究人员想看看模型在推理链的开始阶段是否比在结束阶段更容易掉进这些陷阱。
实验设置: 算术推理
为了严格衡量这一现象,团队使用了算术推理任务。这些是逻辑谜题,你需要跟踪多个陈述中的变量 (如人们拥有的苹果数量) 来回答最终问题。
他们使用了两个数据集:
- GSM8K: 一个标准的小学数学应用题数据集。
- 人工控制数据 (Artificial Controlled Data) : 一个自定义生成的数据集,允许对逻辑链进行精确控制。
理解“距离” (\(d\))
这篇论文的核心创新在于距离 (\(d\)) 这一概念。在分步解题中,\(d\) 代表到达答案所需的剩余步骤数。
- 高 \(d\) (例如 \(d=4\)) : 你处于问题的开始。答案很遥远。
- 低 \(d\) (例如 \(d=1\)) : 你快到了。再一步就能解决它。
研究人员将推理过程建模为图搜索。在每一步,模型查看可用的前提 (\(P\)) ,并将它们改写或组合以创建一个新事实 (\(z\)) 。
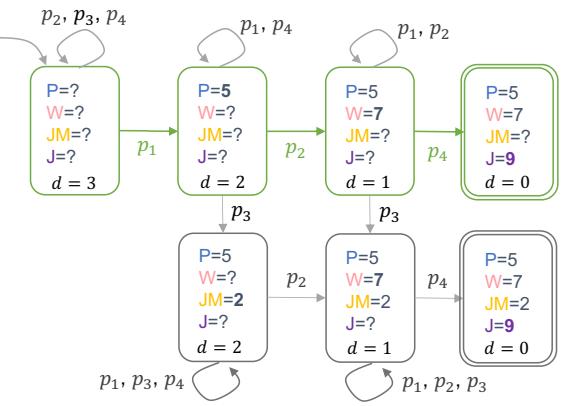
如上文 图 2 所示,模型从一组事实开始 (左侧) 。当它选择正确的前提 (绿色路径) 时,知识状态发生变化,到目标的距离 (\(d\)) 减小。研究人员想知道: 在 \(d\) 的哪个值,模型会偏离绿色路径并跟随红色的启发式路径?
陷阱: 干扰项
为了测试模型,研究人员在问题中注入了干扰项 (distractors) 。 干扰项是一个虚假的前提,基于启发式方法看起来是相关的,但实际上对解决问题毫无用处。
例如,他们可能会构建一个问题,其中正确的下一步涉及“Peggy”,但他们插入了一个关于“Peggy”的干扰句,该句子符合 词汇重叠 (Overlap) 启发式。

如果模型选择了干扰项,它就在“进行启发式思考”。如果尽管有干扰项,它还是选择了正确的前提,它就在“进行理性思考”。
第一阶段: 模型会使用启发式方法吗?
首先,研究人员只是确定模型是否完全容易受到这些干扰项的影响。他们测试了四个模型: PaLM2、Llama2-13B、GPT-3.5 和 GPT-4。
结果很明确: 是的,它们会。
当添加干扰项时,模型经常会选中它们。例如,在 词汇重叠 (Overlap) 条件下 (即无用的句子与问题共用一个名字) ,PaLM2 和 Llama2 等模型选择错误句子的频率明显高于基线随机控制。甚至 GPT-3.5 也表现出很高的易感性。
有趣的是, GPT-4 最为稳健,与其他模型相比,它对启发式方法的依赖非常低。看来随着模型变得更大、更先进,它们自然会变得更加理性。然而,这种偏差并非为零。
第二阶段: 动态转变 (核心发现)
这是研究中最关键的部分。研究人员分析了干扰项是在何时被选中的。他们绘制了选择干扰项的概率与到目标距离 (\(d\)) 的关系图。
假设: 曲线应该是向下倾斜的。在高 \(d\) 时错误率高,在低 \(d\) 时错误率低。
结果:
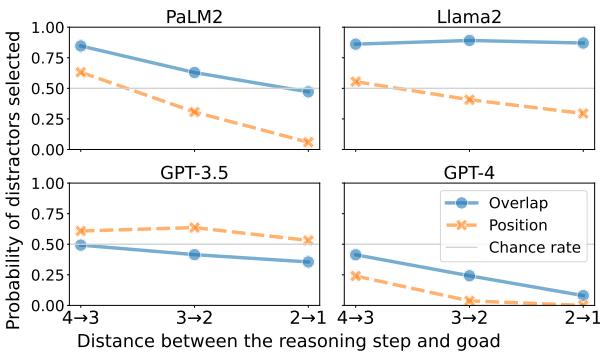
上文的 图 3 完美地讲述了这个故事。特别看看 PaLM2 和 GPT-4 的图表:
- X 轴 (\(d\)) : 代表推理进度。最左边 (\(4 \to 3\)) 是问题的开始。右边 (\(2 \to 1\)) 接近结束。
- Y 轴: 掉入陷阱 (选择干扰项) 的概率。
观察结果:
- PaLM2 (左上) : 看那条带有圆形标记的实线 (Overlap) 。在问题开始时 (\(d=4 \to 3\)) ,选择干扰项的概率接近 90% 。 模型几乎肯定会走捷径。但随着推理进展到最后几步 (\(d=2 \to 1\)) ,概率显著下降。
- GPT-4 (右下) : 虽然 GPT-4 总体上更聪明,但它表现出完全相同的形状。在开始时,它有中等的几率被干扰。到最后,错误率降至几乎为零。
这证实了“先启发,后理性”的理论。当模型审视一个问题并看到前方漫长的道路时,它无法计算出完整的路径。由于缺乏计划,它回退到简单的文本匹配 (启发式) 。一旦它跌跌撞撞地接近解决方案——也许是运气好,或者因为启发式方法指向了模糊的大致方向——剩余路径的“计算负荷”变得可控,模型就切换到严格的逻辑。
推理量的可视化
研究人员还通过统计前提被选中的原始次数来将此可视化。
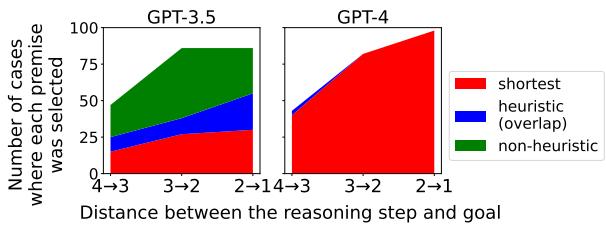
在 图 4 中,我们看到 词汇重叠 (Overlap) 启发式方法的细分:
- 红色区域: 模型选择了正确的、理性的步骤 (最短路径) 。
- 蓝色区域: 模型选择了启发式干扰项。
对于 GPT-3.5 (左) , 注意红色区域在开始时 (图表左侧) 很小,并向右变大。模型在接近答案时实际上变得更“正确”了。 对于 GPT-4 (右) , 红色区域占据主导地位,证明了其卓越的推理能力,但其他颜色的小细条仍然主要出现在开头。
为什么会发生这种情况?
论文认为,这种行为类似于搜索算法中的 有限前瞻 (bounded lookahead) 。
想象你在下国际象棋。如果你是特级大师,你可以看到 15 步以后。如果你是初学者,你可能只能看到 2 步以后。
- 当局面复杂时 (开局) ,初学者无法计算出胜利路径。他们只是走出“看起来不错”的棋 (控制中心,保护棋子) ——这些就是启发式方法。
- 当棋局快结束 (残局) 且只剩下几个棋子时,即使是初学者也能完美计算出“两步杀”。他们变得理性了。
LLM 的运作似乎就像初学者棋手。它们对未来规划有着有限的“上下文缓冲区”。当推理链超出该缓冲区时,它们会回退到训练数据中发现的表面模式 (比如“单词通常出现在相似单词附近”) 。
结论与启示
“先启发后理性”的策略凸显了当前大型语言模型的一个根本局限性。虽然它们能执行令人印象深刻的逻辑壮举,但它们在长范围内进行规划的能力是脆弱的。它们并非始终如一的理性智能体;它们是动态的智能体,根据当前步骤的复杂性在懒惰和逻辑之间摇摆。
主要要点:
- 动态策略: LLM 不使用单一策略。随着目标进入视野,它们会从启发式切换到理性模式。
- 距离很重要: 离解决方案越远,模型就越有可能产生幻觉或被不相关的关键词干扰。
- 模型进化: 更大、更强的模型 (如 GPT-4) 较少依赖启发式方法,这表明扩大模型规模能提高其“前瞻”能力。
对于使用 LLM 的学生和工程师来说,这表明分解问题的 提示工程 (prompt engineering) 技术 至关重要。通过迫使模型解决较小的子问题,我们有效地减少了每一步的“距离” \(d\),让模型保持在理性的“绿色区域”,防止它回退到懒惰的启发式方法。
从启发式思维到理性思维的转变是一种深刻的人类特征。事实证明,我们的 AI 模型可能比我们想象的更像我们——容易走捷径,直到截止日期就在眼前。